








目录
一、链表分割
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置
链接:https://leetcode-cn.com/problems/partition-list

思路: 将小于X的节点划分为一组,大于等于X的节点划分为一组,最后进行组合;
接下来看动图解析:


struct ListNode* partition(struct ListNode* head, int x){
struct ListNode* lessHead,*lessTail,*greaterHead,*greaterTail;
//申请动态空间
lessHead = lessTail = (struct ListNode*)malloc(sizeof(struct ListNode));
lessTail->next = NULL;
greaterHead = greaterTail = (struct ListNode*)malloc(sizeof(struct ListNode));
greaterTail->next = NULL;
struct ListNode* cur = head;
while(cur)
{
//存放小于X的节点
if(cur->val < x)
{
lessTail->next = cur;
lessTail = cur;
}
//存放大于等于X的节点
else
{
greaterTail->next = cur;
greaterTail = cur;
}
cur = cur->next;
}
//小节点的尾结点链接到大结点的头结点
lessTail->next = greaterHead->next;
greaterTail->next = NULL;
struct ListNode* newHead = lessHead->next;
free(lessHead);
free(greaterHead);
return newHead;
}
二、链表的回文结构

什么是回文结构:
回文结构序列是一种旋转对称结构,在轴的两侧序列相同而反向。当然这两个反向重复序列不一定是连续的。
思路:
1.先找链表的中间结点;
2.对中间结点向后的链表进行反转;
3.通过两个指针对两个链表进行遍历比较判断;
1和2动图解析链接:https://blog.csdn.net/sjsjnsjnn/article/details/123966038?spm=1001.2014.3001.5501

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
//1.找出链表中间结点
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* slow,* fast;
slow = fast = head;
while(fast && fast -> next)
{
fast = fast -> next -> next;
slow = slow -> next;
}
return slow;
}
//2.反转链表
struct ListNode* reverseList(struct ListNode* head){
if(head == NULL)
return NULL;
struct ListNode* cur,*prev,*next;
cur = NULL;
prev = head;
next = head->next;
while(prev)
{
prev->next = cur;
cur = prev;
prev = next;
if(next)
next = next->next;
}
return cur;
}
bool isPalindrome(struct ListNode* head){
struct ListNode* mid = middleNode(head);
struct ListNode* rhead = reverseList(mid);
struct ListNode* curA = head;
struct ListNode* curR = rhead;
//3.遍历两个链表比较
while(curA && curR)
{
if(curA->val != curR->val)
{
return false;
}
else
{
curA = curA->next;
curR = curR->next;
}
}
return true;
}
三、相交链表


思路:
1.先把两个链表遍历一边,求出每个链表的长度;
2.让长度最长的链表先走两者的差距步(如:A链表长度为5,B链表长度为6,那么B链表就先走1步,让A B链表同时去找相同的节点)
动图解析:

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct ListNode *tailA = headA;
struct ListNode *tailB = headB;
int lenA = 1;
while(tailA->next)
{
++lenA;
tailA = tailA->next;
}
int lenB = 1;
while(tailB->next)
{
++lenB;
tailB= tailB->next;
}
//不相交
if(tailA != tailB)
{
return NULL;
}
int gap = abs(lenA - lenB);
//长的先走差距步,再同时找交点
struct ListNode* longList = headA;
struct ListNode* shortList = headB;
if(lenA < lenB)
{
shortList = headA;
longList = headB;
}
while(gap--)
{
longList = longList->next;
}
while(longList != shortList)
{
longList = longList->next;
shortList = shortList->next;
}
return shortList;
}
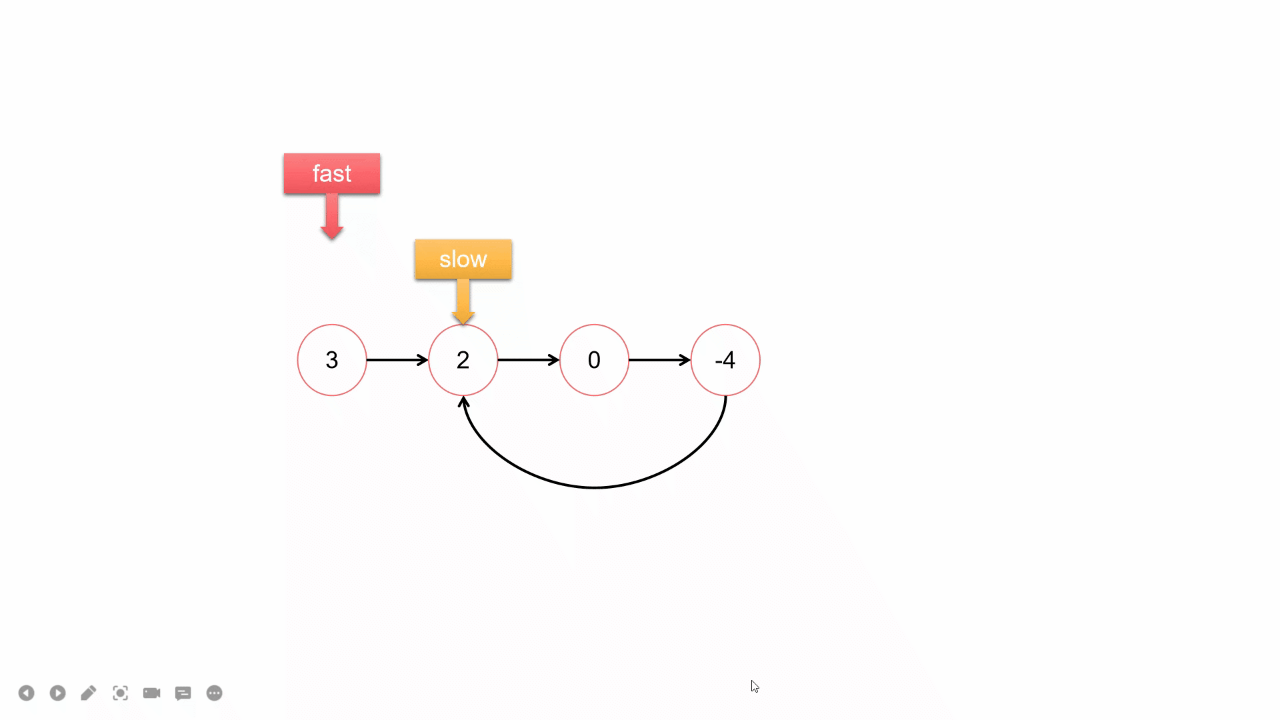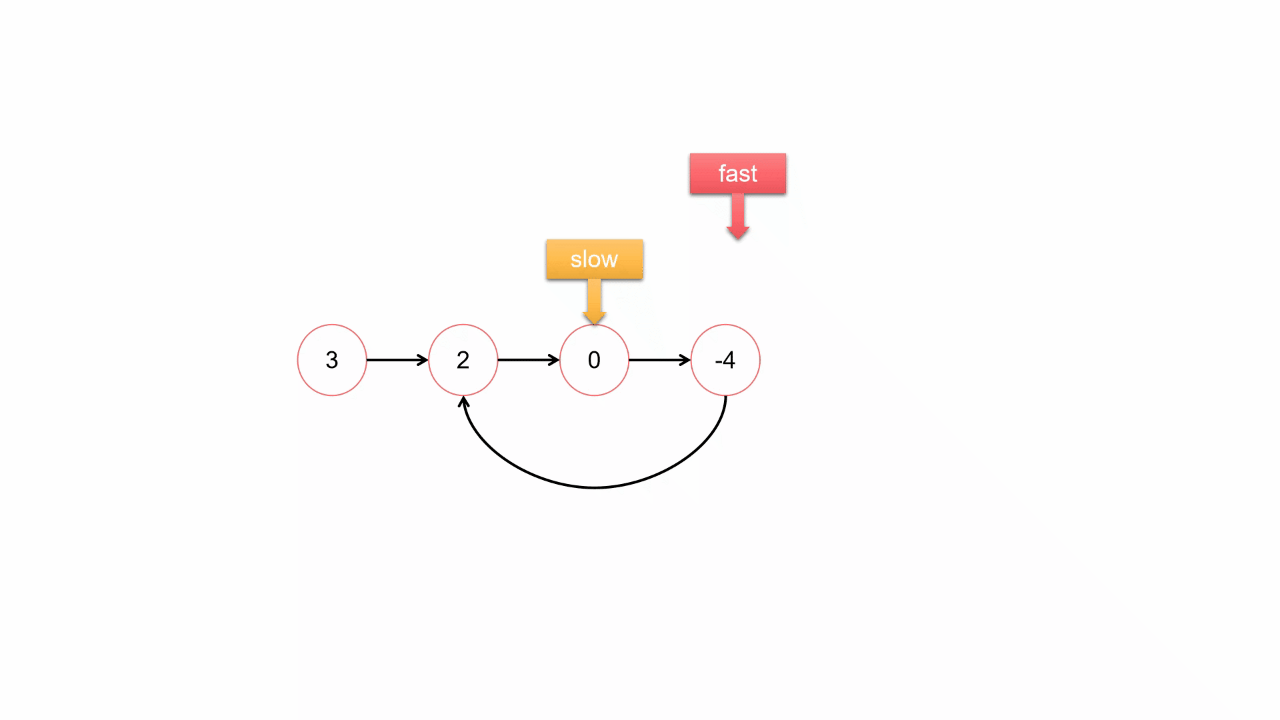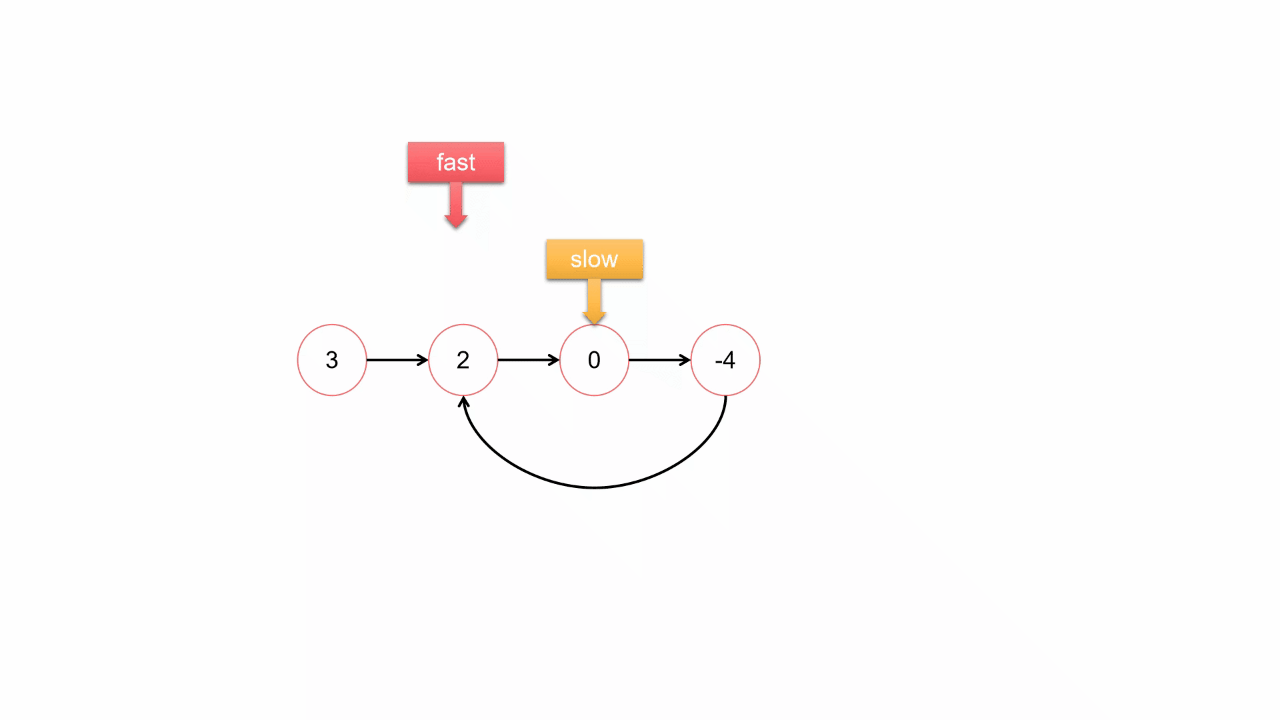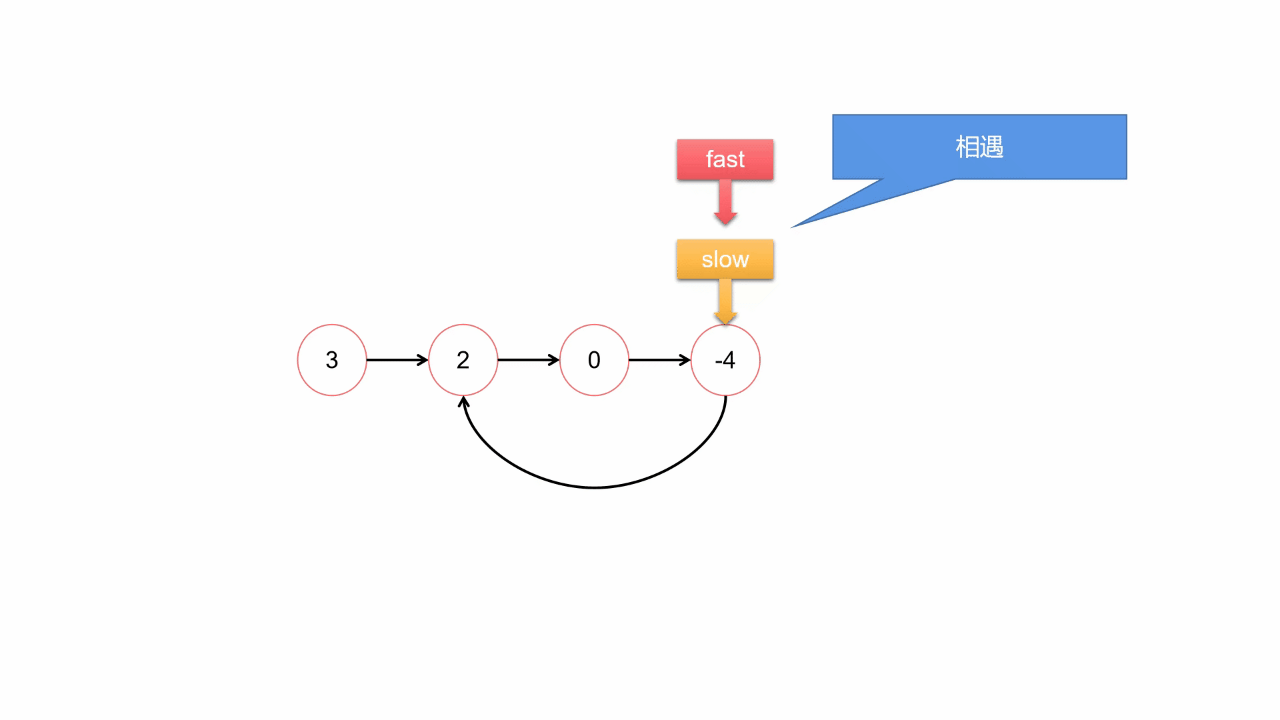
四、环形链表

思路1:暴力求解O(N^2)
依次取A链表中的每个节点与B链表中的所有结点相比较,如果有地址相同的结点,就是相交;
思路2:快慢指针法O(N)
1.尾结点相同就是相交,否则就不相交;
2.求交点:长的链表先走(长度差)步,再同时走,第一个相同的就是交点;
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
struct ListNode *slow = head,*fast = head;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
{
return true;
}
}
return false;
}
思考两个问题:
①为什么slow和fast一定会在环中相遇?有没有错过的情况,永远遇不上?
②为什么slow走一步,fast一次走两步?可不可以fast一次走N(N>2)步?
-------------------------------------------------------------------------------------------------------------------------
解答:
slow一次走一步,fast一次走两步;一定会相遇
1.slow和fast相比较,fast一定是先进入环的,此时slow走了入环前的一半;
2.随着slow进环,fast已经在环里面走了一段了,走了多和环的大小有关;
slow一次走一步,fast一次走三步;不一定会相遇
如果N是4、5、6......,其推到过程也是一样的;


五、环形链表 II

思路: 快慢指针

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode* slow = head,*fast = head;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
{
struct ListNode* meet = slow;
while(head != meet)
{
meet = meet->next;
head = head->next;
}
return meet;
}
}
return NULL;
}
六、复制带随机指针的链表
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
链接:https://leetcode-cn.com/problems/copy-list-with-random-pointer

思路:
1.拷贝节点并插入原节点的后面;
2.根据原节点,处理copy节点的random;
3.把拷贝节点解下来,链接成新链表。同时恢复原链表;

/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head) {
//1.拷贝节点并插入原节点的后面
struct Node* cur = head;
while(cur)
{
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val = cur->val;
//插入copy节点
copy->next = cur->next;
cur->next = copy;
cur = copy->next;
}
//2.根据原节点,处理copy节点的random
cur = head;
while(cur)
{
struct Node* copy = cur->next;
if(cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;
}
cur = copy->next;
}
//3.把拷贝节点解下来,链接成新链表。同时恢复原链表;
struct Node* copyHead = NULL, *copyTail = NULL;
cur = head;
while(cur)
{
struct Node* copy = cur->next;
struct Node* next = copy->next;
if(copyTail == NULL)
{
copyHead = copyTail = copy;
}
else
{
copyTail->next = copy;
copyTail = copy;
}
cur->next = next;
cur = next;
}
return copyHead;
} 以上是链表相关练习的总结;动图如有错误,请联系博主;
以上是链表相关练习的总结;动图如有错误,请联系博主;
















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











