






系列文章目录
【网络编程】网络编程中的基本概念及Java实现UDP、TCP客户端服务器程序(万字博文)
【网络原理】UDP协议的报文结构 及 校验和字段的错误检测机制(CRC算法、MD5算法)
目录
一、数据链路层
认识以太网
- 以太网是一种计算机局域网(LAN)技术,用于在局域网中进行数据通信。
- 以太网技术横跨了数据链路层和物理层,在数据链路层,负责处理数据帧的传输、碰撞检测等功能;而以太网使用的物理传输介质,如双绞线、光纤等,以及物理信号传输介质则属于物理层的范畴。
- 以太网是当前最常见和最广泛使用的局域网技术之一。
以太网帧格式
以太网帧格式如下图所示:
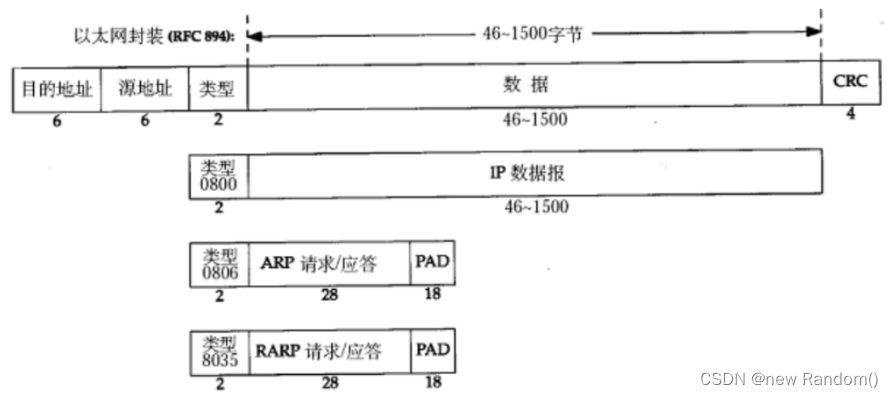
首先是目的地址和源地址两个字段,这两个字段和前面传输层和网络层协议,使用的IP地址就不一样了。数据链路层,引入了另外一套地址体系,即6个字节的“MAC地址”,也叫物理地址。
认识MAC地址:
- MAC地址是数据链路层的地址,长度为48位,即6个字节。一般使用16进制数字加上“:”或“ - ” 的形式来表示(例如:08:00:27:03:fb:19;00-FF-23-A9-D8-68)
- MAC地址是静态分配的,在网卡出厂时就已经确定了,不能修改。且MAC地址能表示的范围比IP地址大很多,因此MAC地址通常是唯一的(虚拟机中的MAC地址不是真实的)。
MAC地址和IP地址是两套独立的地址体系。对比理解MAC地址和IP地址:
- IP地址描述的是路途总体的 起点 和 终点;
- MAC地址描述的是路途上的每一个区间的 起点 和 终点。
举一个例子,假设我要从厦门到北京,我的路线是 厦门=>南京=>石家庄=>北京(不考虑NAT机制,即公网到公网的情况):
第一步:厦门=>南京
- 源IP:厦门;目的IP:北京
- 源MAC:厦门;目的MAC:南京
第二步:南京=>石家庄
- 源IP:厦门;目的IP:北京
- 源MAC:南京;目的MAC:石家庄
第三步:石家庄=>北京
- 源IP:厦门;目的IP:北京
- 源MAC:石家庄;目的MAC:北京
再到类型和数据这两个字段:
类型字段用于表示数据字段中所携带的数据的类型。如以下三种(IP,ARP,RARP):

数据字段则表示数据部分的长度范围在 46 ~ 1500 字节 之间。最短46字节,是因为ARP是46字节;最长1500字节,则是硬件的限制了,这个最大值1500称为以太网的最大传输单元(MTU),不同的网络类型有不同的MTU。
前面介绍,IP数据包的拆包是在数据链路层有限制,这往往就是因为这个MTU导致的,而不是达到了IP数据包自身的64KB的限制。
- 如果类型字段表示,数据是IPv4类型,此时意味着该以太网帧是一个能够携带业务数据的报文(即携带IP数据包)
- 如果类型字段表示,数据是ARP类型(ARP和RARP可以认为是两个横跨了网络层和数据链路层的协议),它会将目标IP地址解析为对应的MAC地址,即 IP=>MAC.
- 而 RARP 的请求和响应被包含在 ARP 类型的帧中,它与ARP正好相反,它用于将MAC地址解析为对应的IP地址,即MAC=>IP.
二、DNS 域名解析系统
DNS(Domain Name System)是一个重要的应用层协议,可以被称为域名解析系统。它的主要功能之一就是将人类可读的域名解析为计算机可理解的IP地址。通过DNS,用户可以使用易记的域名来访问互联网上的各种资源,而不需要记住复杂的IP地址。
DNS使用TCP和UDP端口53,并对域名长度进行了限制,每一级域名长度不能超过63个字符,而域名总长度不能超过253个字符
- 最早的时候,人们使用hosts文件来描述域名和IP地址的关系,即文件中存储域名和IP地址的映射关系(行文本,每一行都有IP和域名)。这样做的好处是可以在本地进行域名解析,加快访问速度并且可以防止访问特定网站。
- 随着主机和服务器越来越多了,此时维护hosts文件,就非常麻烦了。
- 于是,大佬们就搭建了一组服务器,来提供域名解析服务(hosts内容放到服务器了,同时删除hosts文件中的所有自定义映射。这样,计算机将不再依赖于Hosts文件进行域名解析,而是通过DNS服务器来获取域名解析信息)
- 当某个主机想要访问某个域名,就先查询一下,域名解析服务器(DNS服务器)。查到的结果,就是域名对应的IP,计算机就可以通过这个IP进行访问。
此时就有一个问题,全世界这么多人上网,大家都去访问这个DNS服务器,它扛得住这么大的请求量吗?
- 实际上,DNS服务器并非只有一个,虽然经常提到只有13个根DNS服务器(顶层服务器,管理互联网的顶级域名(如.com、.org、.net)),但这只是一个符号性的表示方式,用于方便表示这些根服务器的名称。
- 各个国家的网络运营商,还会根据根域名服务器的内容,搭建出“镜像服务器”。国民上网的时候,一般就会就近的访问到附近运行商的镜像DNS服务器。
- 同时,DNS服务器还有很多种类型。比如:
- 权威DNS服务器:这些服务器存储特定域名的DNS记录,管理域名的解析。每个域名都有至少一个权威DNS服务器,通常由域名注册商或域名持有者运营。这些服务器遍布全球,以确保互联网的稳定和可靠。
-
公共DNS服务器:这些服务器由一些大型技术公司或组织提供,旨在为全球用户提供免费和快速的DNS服务。著名的公共DNS服务器包括谷歌的8.8.8.8和8.8.4.4、Cloudflare的1.1.1.1和1.0.0.1、OpenDNS的208.67.222.222和208.67.220.220等。
-
递归DNS服务器:当用户设备需要访问某个域名时,递归DNS服务器会向权威DNS服务器发送查询请求,并将返回的IP地址解析结果返回给用户设备。
域名采用了分层次的结构,域名的级别没有固定的数量限制。具体的分级数量和命名规则可以因不同的域名注册机构和组织而有所不同。例如:域名可以包括顶级域名、二级域名、三级域名和四级域名。域名实际上也就是我们熟悉的网址中的一部分。
- 顶级域名:如 `.cn` 表示中国,`.uk` 表示英国,`.us` 表示美国等。此外,还有通用顶级域名,如 `.com`、`.net`、`.org` 等。还有一种特殊的顶级域名是 `arpa`,它用于反向域名解析,将IP地址反向解析为域名。
- 二级域名:通常用于表示网站所属的行业或组织类型,例如 `edu` 表示这个网站属于教育机构。
- 三级域名:通常用于表示组织或公司的名称,例如 `jxnu` 可能表示江西师大。
- 四级域名:通常用于表示特定的服务或应用,例如 `www` 通常表示万维网服务。
除了常见的域名级别外,实际上还存在更多级别的域名,如四级、五级域名等。这些更高级别的域名通常用于满足特定的需求或进行更细致的划分。















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









