







1.报错信息
pyspark脚本在自动调度过程中,报错内存溢出。beyond the ‘PHYSICAL’ memory limit. Current usage: 11.0 GB of 11 GB physical memory used。
CONSOLE# 2023-05-06 06:13:05,368 | ERROR | main | Application diagnostics message: Application application_1682198688166_1065397 failed 2 times due to AM Container for appattempt_1682198688166_1065397_000002 exited with exitCode: -104
CONSOLE# Failing this attempt.Diagnostics: [2023-05-06 06:13:02.276]Container [pid=8224,containerID=container_e21_1682198688166_1065397_02_000001] is running 19828736B beyond the 'PHYSICAL' memory limit. Current usage: 11.0 GB of 11 GB physical memory used; 18.1 GB of 165 GB virtual memory used. Killing container.
2.问题分析
2.1 增加资源
从报错信息可以初步定位是数据大小超出了内存限制,可以通过加大资源(eg: driver memory)解决,但是盲目加大资源并不是很好的解决方案,过一段时间可能又会超出内存限制。
2.2 增大并行度
除了加大资源外,数据倾斜也会引起的某一分区数据量过大,导致OOM。因此,通过加大spark并行度也可以解决此问题。
首先,观察spark数据各个分区的数据量并画直方图:
from pyspark.sql import functions as fn
# 输出分区数量
print(df.rdd.getNumPartitions())
# fn.spark_partition_id():pyspark内置函数,可以获取各个分区id
pdf = df.groupBy(fn.spark_partition_id()).count().toPandas()
pdf[['count']].plot(kind='hist')
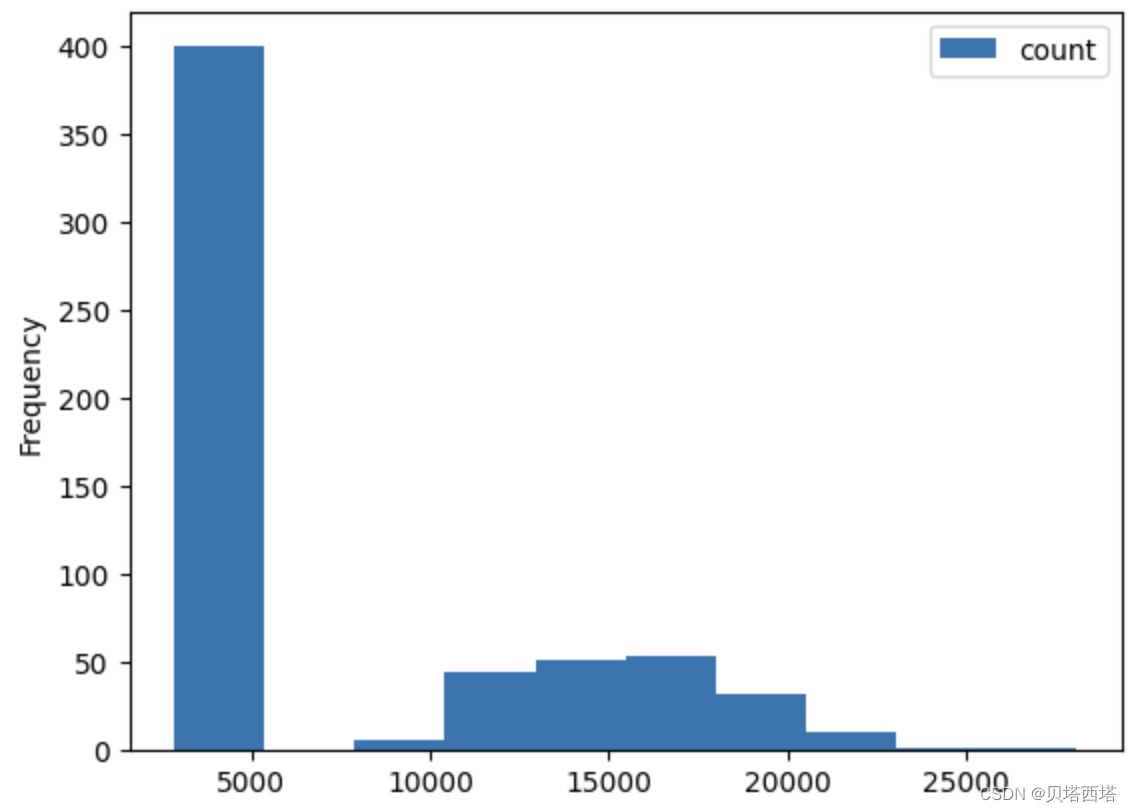
可以看到各个分区的数据量呈长尾分布,大部分分区数据量在5000条记录左右,有少部分分区记录数超过2万,因此数据量较大的分区容易出现OOM问题。
然后增大并行度:
df=df.repartition(800)
再次观察各个分区数据量的直方图:
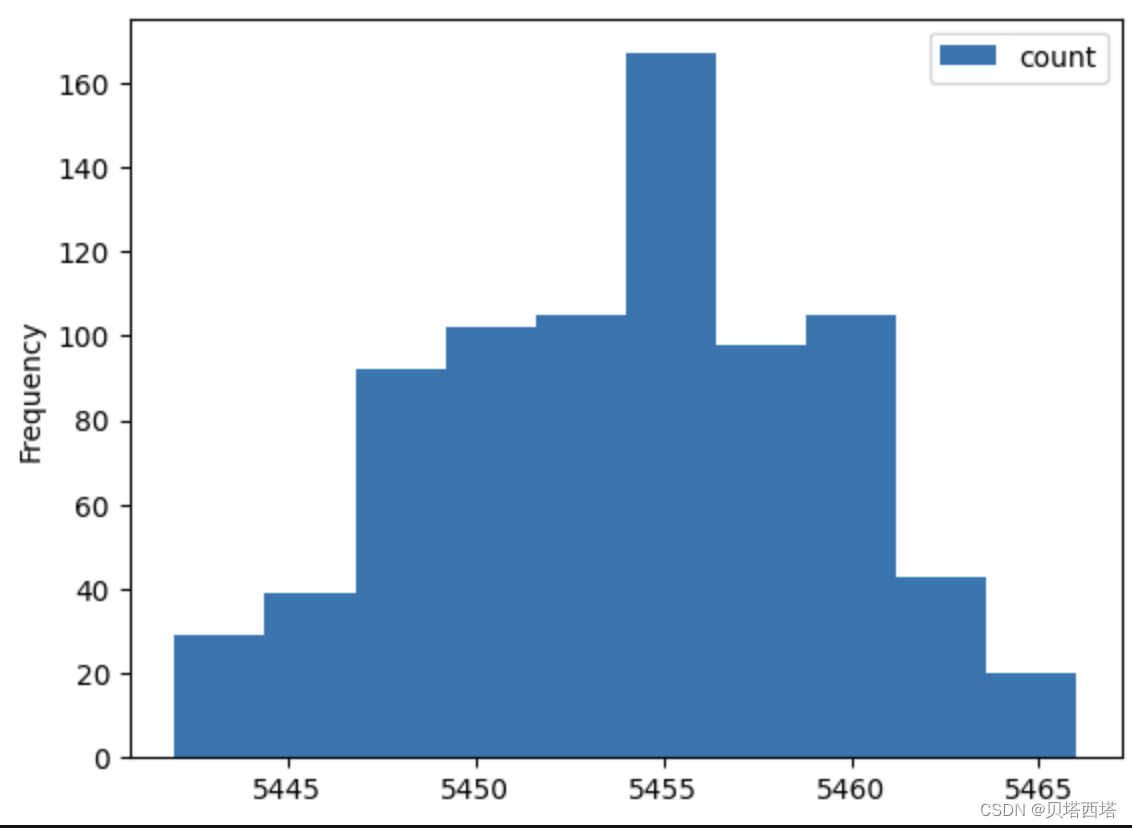
可以看到各个分区数据量呈正态分布,且不存在数据量很大的分区。
再次运行pyspark程序也能正常运行,不会出现OOM问题。
3. 数据倾斜解决方案总结
网上有资料推荐使用spark.default.parallelism=800参数增加spark的默认并行度,但是实测并没有效果。经过查阅,发现spark官网关于spark.default.parallelism参数有以下说明:
1、对于reduceByKey和join这些分布式shuffle算子操作,取决于它的父RDD中分区数的最大值
2、对于没有父RDD的的算子,比如parallelize,依赖于集群管理器
且spark.default.parallelism是针对rdd的shuffle操作的默认并行度。因此更推荐使用repartition操作增加并行度。
除了增加并行度外,还有其他方式解决或缓解数据倾斜问题,如hive ETL分区分桶、两阶段聚合、map join等操作,但是repartition通常是是最简单且有效的方案,推荐第一时间尝试。
值得注意的是,并行度也不可盲目增大, 并行度增加也会带来启动task的资源消耗,带来性能下降。

















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











