







早上还没进入工作状态,一个对接系统小伙伴发来消息,线上一直收不到队列消息,帮忙看看,瞬间一激灵,开始去查看具体问题。首先说下这个跟对接系统交互的流程,首先我们系统有一些业务数据状态发生变化时,会通过数据库触发器写入消息推送表,然后我们的消息推送服务(Quartz定时调度框架实现)定时检索这个消息推送表,有待处理数据就把数据做一些处理,生产消息发送到ActiveMQ的指定队列上,对接系统监听和消费该队列消息。
从根源入手,先查看消息推送表,确实有不少待处理数据,登录消息推送服务所在的服务器,jps和ps都能看到相应的进程,然后去看了看服务的日志,发现基本不滚动,偶尔出现一个Error信息,关于一个查询SQL的。用jstat -gcutil PID 3s 5,查看该进程GC情况,截图如下:
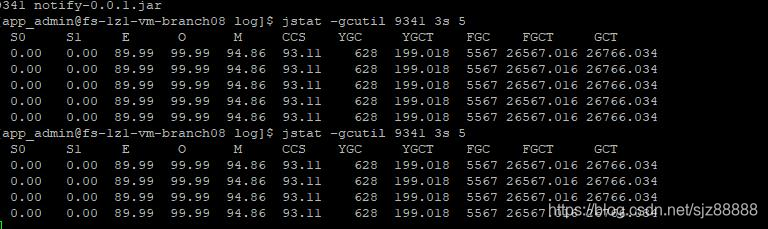
发现老年代(第四列O)占用率很高,并且经历FULL GC后,只回收了约0.1%,然后又很快进行又一次FULL GC,频繁FULL GC,用户线程阻塞就说得通了。回收效率这么低,应该是有内存泄漏导致GC Roots总是能关联到老年代中的对象,jmap -dump:live,format=b,file=heap.hprof PID命令先生成堆快照后,临时重启了服务。重启后服务暂时正常了,然后去拿堆快照,想去分析下,发现该堆快照大小为7.6G,反复下载了很多次没能下载成功,于是先跟相关同事沟通了下报错SQL的问题,发现确实程序逻辑是先执行一个查询,把结果集放入一个大的ArrayList中,再用这个集合作为另一个SQL的查询in的范围中,后面这个查询报错提示in的范围只能是1000以下,于是先跟同事确认了调整方案,第一次查询时就限制下数量,然后就让他去调整代码和自测去了。线上服务跑了几个小时之后,再看GC情况,又出现截图中的情况,同事那的程序自测通过,赶紧发布到了线上,再次重启后服务就没有出现阻塞情况,GC也恢复正常了。
(目前已拿下来堆快照,周末找时间用memory analyzer分析下内存泄漏是否确实是同事那块代码导致的)














04-07
 2570
2570
2570
12-18
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









