







前言
本文是接着上一文多层感知机所写的。上一文说的了如何初始化一个MLP。本文简单介绍一下前向传播的概念以及代码实现。
上文:http://blog.csdn.net/skullfang/article/details/78609851
回顾
还是从一个简单的多层感知器入手,这个感知器只有两层(输入层不算)。输入层——隐藏层——输出层
模型:
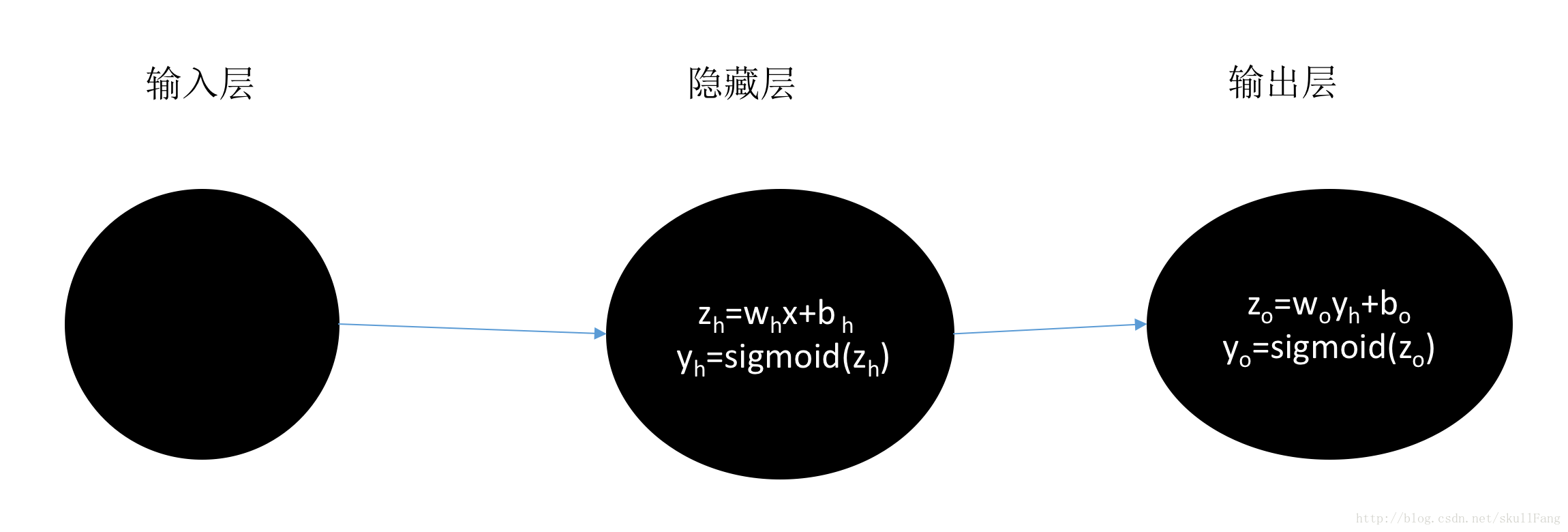
其中w是 权重。b 是偏置。(注意隐藏层和输出层中w和b各不相同)
前向传播
每个神经元有两部分组成一部分是根据权重w和偏置b计算出值z。通过激励函数sigmoid刺激之后产生一个输出y。而这个y就是下一层的输入,然后下一层又产生一个输出作为下下一层的输入,一直到最后一层。
由模型可以看出隐藏层的输出yh就是输出层的输入。
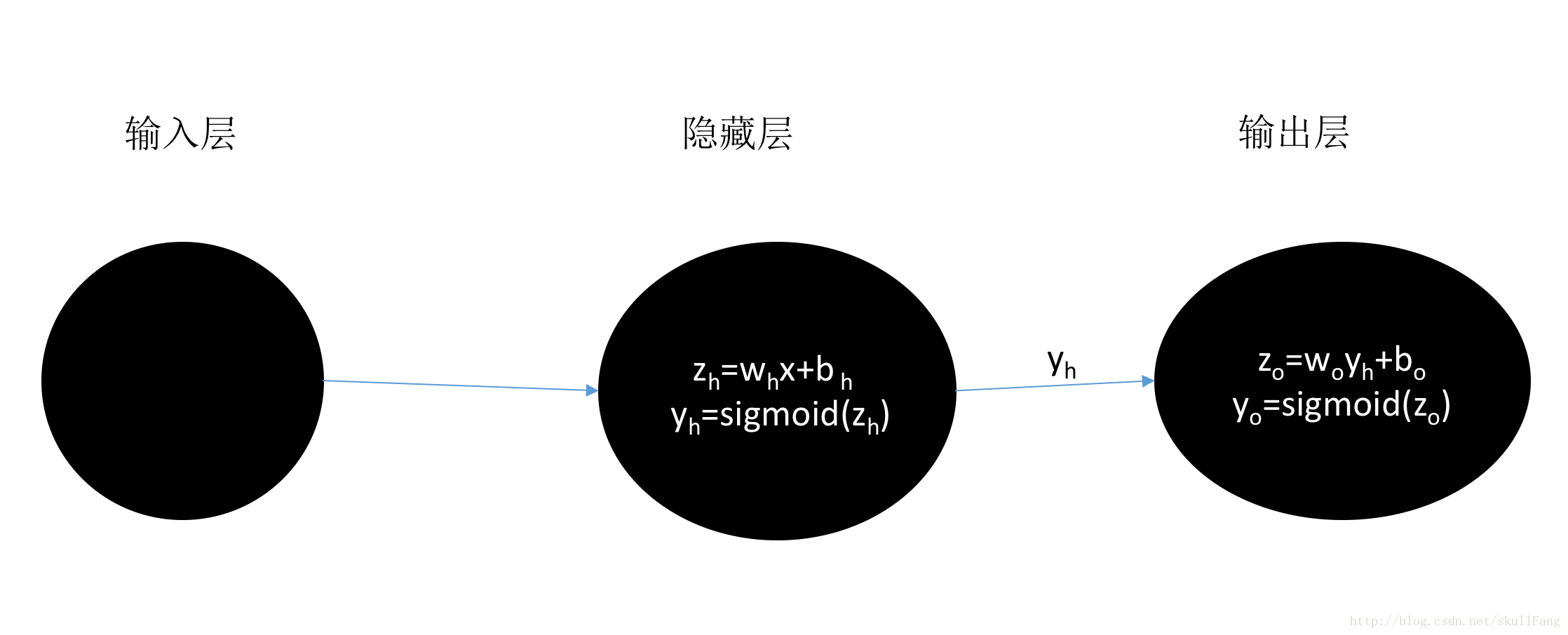
每一层的输出 作为 下一层的输入。从而一层一层的传播下去就叫做前向传播。
同样有个概念叫反向传播(更新)。就是我们输出层产生输出之后yo要与y的真实值进行比较学习之后。反向一层一层的更新w和b。详细的紧接着一篇博文会说到。
回到前向传播
概念很简单
直接就看代码部分了。
# -*- coding: utf-8 -*-
# @Time : 2017/11/23 上午10:21
# @Author : SkullFang
# @Email : yzhang.private@gmail.com
# @File : TwoDemo.py
# @Software: PyCharm
import numpy as np
class Network(object):
def __init__(self,sizes):
"""
sizes表示 网络的结构
:param sizes:
"""
#网络层数
self.num_layers=len(sizes) #层数
#神经元的个数
self.sizes=sizes
#初始化每一层的偏置 z=wx+b 就是b的值
self.baises=[np.random.randn(y,1) for y in sizes[1:]]
#等同与
"""
baises=[]
#意思就是生成一个符合正态分布的 y*1的数组
for y in sizes[1:]:
biases.append(np.random.randn(y, 1))
结果
[array([[ 1.05154644],
[-0.02986238]]), array([[-0.88098138]])]
"""
#初始化权重W
self.weights=[np.random.randn(y,x) for x,y in zip(sizes[:-1],sizes[1:])]
"""
产生一个y*x 符合正态的
weights=[]
for x,y in zip(sizes[:-1],sizes[1:]):
weights.appenf(np.random.randn(y,x))
pass
>>> weights
[array([[-0.22826557, -0.54427902, 0.19502928],
[ 0.21433594, 0.72849057, 0.12851307]]), array([[ 0.27181857, -0.55032853]])]
"""
#梯度下降
def GD(self,training_data,epochs):
"""
这个是梯度下降
:param training_data: 训练数据
:param epochs: 训练次数
:return:
"""
for j in xrange(epochs):
#洗牌 就是打乱训练数据
random.shuffle(training_data)
#训练每一个数据
for x,y in training_data:
self.update(x,y)
print "Epoch {0} complete".format(j)
#前向传播
def update(self,x,y):
"""
:param x:
:param y:
:return:
"""
# 保存每一层的偏导
nabla_b = [np.zeros(b.shape) for b in self.baises]
nabla_w = [np.zeros(b.shape) for b in self.weights]
#保存输入数据
#第一层的activation
activation=x
#保存每一层的激励值a=sigmoid(z)
activations=[x]
#zs保存每一层的z=wx+b
zs=[]
#要做前向传播
for b,w in zip(self.baises,self.weights):
#计算每一层的z,
# 这里的activation就是上一层的输出。
# 从而达到传播的效果
z=np.dot(w,activation)+b
#保存每一层的z
zs.append(z)
#计算每一层的a(其实就是y)
activation=sigmoid(z)
#保存每一层的a
#做个记录反向传播有用
activations.append(activation)
#sigmoid
def sigmoid(z):
"""
激活函数
:param z:
:return:
sigmoid(z)=1/(1+e^-z)
"""
return 1.0/(1.0+np.exp(-z))













 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









