






最近读到了吴军老师的数学之美,现对其中的期望最大化算法进行了整理;
一、算法描述:
K均值的算法其实很简单,简单来说如下:
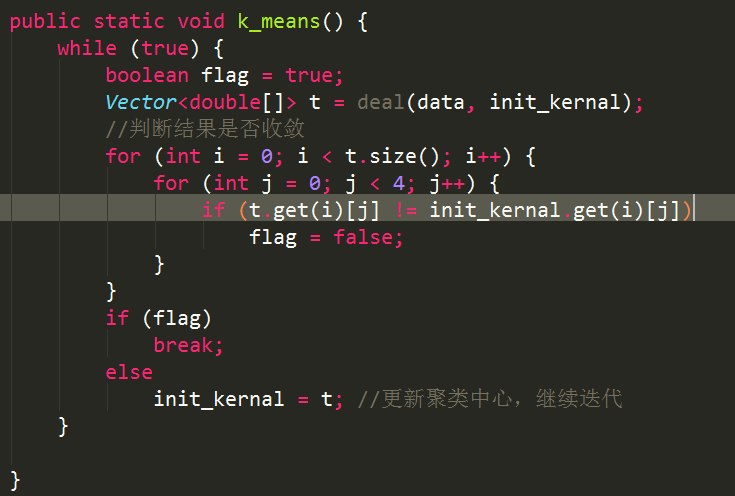
1、首先假设要分的类型种类为N,则算法开始的时候随机选择N个聚类中心;
2、进行迭代;对于训练数据中的每一个样本分别计算其到N个聚类中心的距离,该样本的分类结果就是距离其最近的聚类中心所属的分类;
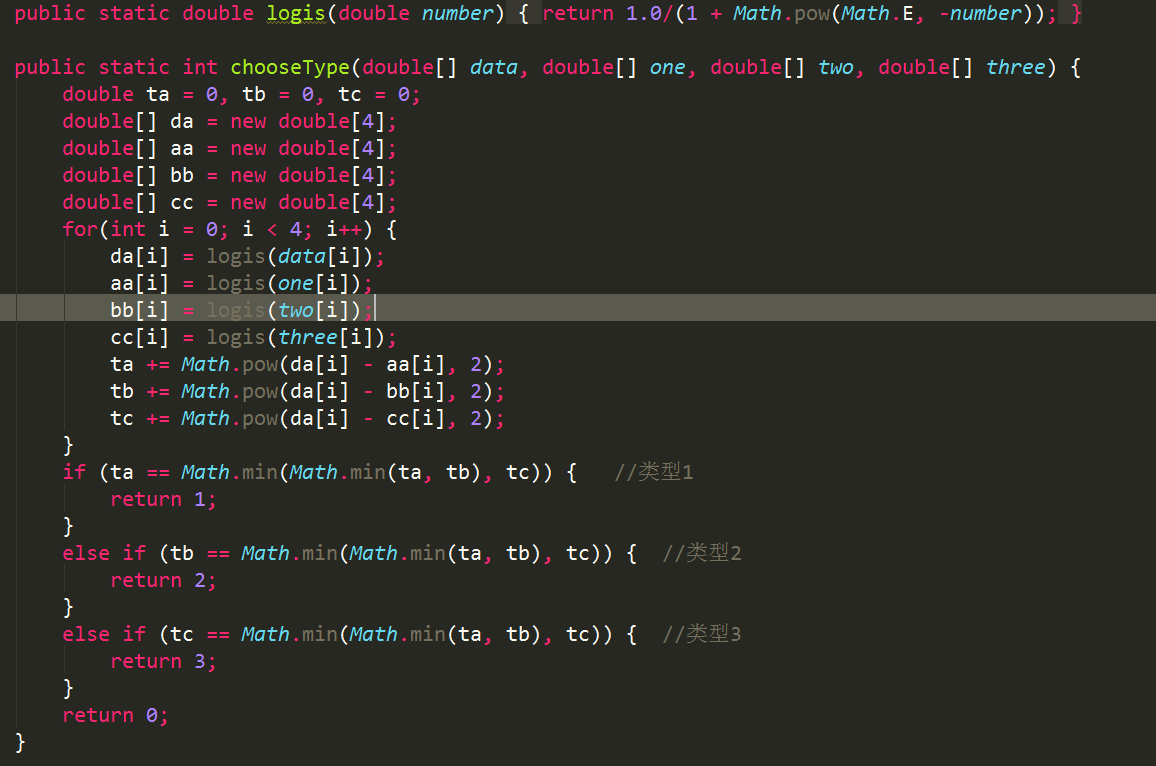
注意:计算样本到聚类中心的距离时可以使用逻辑回归函数,把每一个训练数据的各个属性值映射到[0,1]之间,然后再计算属性值之间的距离,这样可以提高聚类的效果;
3、更新聚类中心;可以使用求平均值的方法来计算每次迭代后的新的聚类中心;
4、每次迭代后判断新的聚类中心是否发生变化(中心是否收敛),如果没有变化则停止迭代,已经达到了聚类效果;否则以上述步骤3产生的新的聚类中心作为中心继续进行步骤2和3;
二、聚类效果图
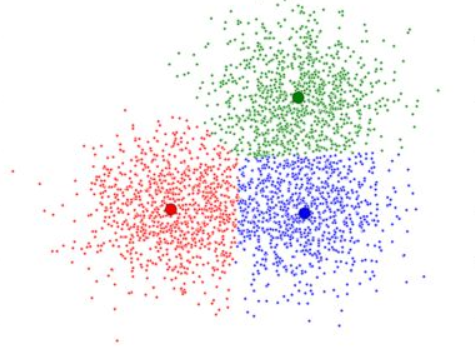
三、核心代码分析
1、K均值算法
2、判断每一个样本所属的分类
四、测试结果
使用了上述方法之后在IRIS数据集上进行测试,聚类的效果达到96%,当然结果还与初始的聚类中心的选择有关;

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









