







前言:学习了java中io流,总想干个什么,于是想到了网络爬虫。在实际的coding中,才发现io流真的很不错。
功能:爬取页面图片
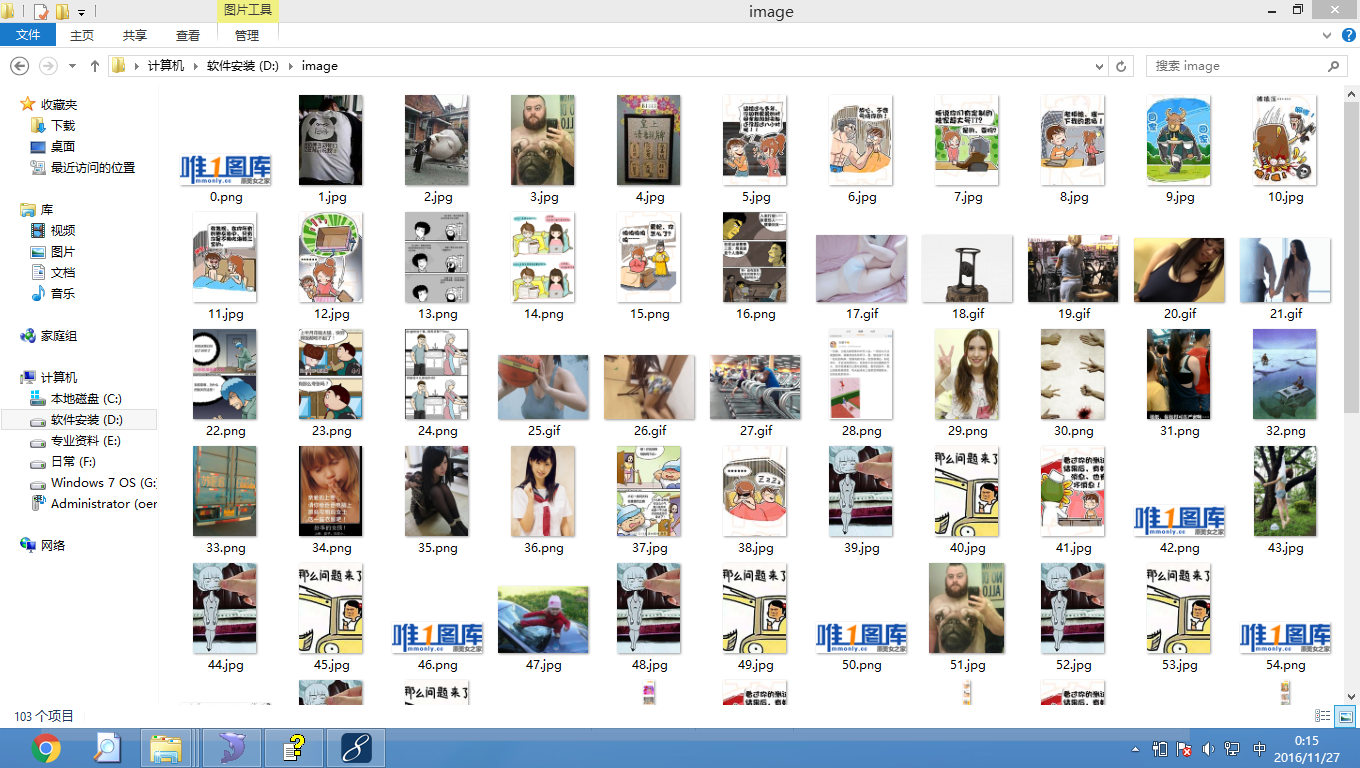
图片展示:
代码部分:(1)PaChongMain.java
package my.first;
import java.util.ArrayList;
import java.util.List;
public class PaChongMain {
/**
* 传入一个网址
*/
public static void main(String[] args) {
long startTime=System.currentTimeMillis();
//String url="http://588ku.com/";
String url="http://www.mmonly.cc/gxtp/"; //输入网址
//String url="http://image.baidu.com/"; //百度获取不到全部的html
GetHtml getHtml=new GetHtml();
String html=getHtml.getUrl(url);//获取html字符串
//System.out.println(html);
GetImgSrc getImgSrc=new GetImgSrc(); //
List<String> out=new ArrayList<String>();//储存爬取的图片的网络地址
out=getImgSrc.getSrc(html); //html与img的正则匹配
SaveImage saveImage=new SaveImage(); //根据图片的地址保存图片
saveImage.save(out); //保存的方法
long endTime=System.currentTimeMillis();
System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
}
}
代码部分:(2)GetHtml.java
package my.first;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtml {
public String getUrl(String web){
URL url=null;
InputStream input=null;
FileOutputStream out=null;
StringBuffer string=new StringBuffer();
List<String> result=new ArrayList<String>();
int aa=0;
for (int j = 0; j < 20; j++) {
try{
//string=new StringBuffer();
url=new URL(web);
URLConnection connection=url.openConnection();//打开url连接
input=connection.getInputStream();//得到输入流
//input=new FileInputStream("D:\\bai.txt"); //文本输入流,从文本导入html
System.out.println(input.toString());
out=new FileOutputStream("D:\\img.txt",true);//对应的输出流
int len=0;//能读到字节个数
byte[] a=new byte[1024];
while((len=input.read(a))!=-1){
out.write(a,0,len); //输出到本地
char[] b=new char[1024];
for(int i=0;i<len;i++){
b[i]=(char)a[i];
}
string.append(b); //输入数据到可变字符串数组
}
}
catch (Exception e) {
// TODO: handle exception
}
//找出此html中的其他的链接地址
while(aa<1){
String OtherHrefRegx="href=\"([\\d\\s\\w./:]+(\\.html))\"";
String OtherHref=string.toString();
Pattern p=Pattern.compile(OtherHrefRegx);
Matcher m=p.matcher(OtherHref);
while(m.find()){
String s=m.group(1);
if(s.indexOf("http")==-1){
s="http://bpic.588ku.com"+s;//增加一些不是完整的html
}
result.add(s);
}
for(String str:result){
System.out.println(str);
}
aa=1;
} //while语句的结束
web=result.get(j);
} //循环语句的结束
try {
input.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
out.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return string.toString();
}
}
代码部分:(3)GetImgSrc.java
package my.first;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetImgSrc {
public List<String> getSrc(String html){
//匹配图片的地址
String regx="src=\"([\\d\\s\\w./:]+(\\.jpg|\\.png|\\.gif))\"";
List<String> result=new ArrayList<String>();
Pattern p=Pattern.compile(regx);
Matcher m=p.matcher(html);
while(m.find()){
String s=m.group(1);
if(s.indexOf("http")==-1){
s="http://www.mmonly.cc"+s;//增加一些不是完整的html
}
result.add(s);
}
int i=0;
for(String str:result){
i++;
System.out.println(str);
}
System.out.println(i);
return result;
}
}
代码部分:(4)SaveImage.java
package my.first;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.util.List;
public class SaveImage {
public void save(List<String> out) {
File file=new File("D:\\image");//存放的文件夹
if(!file.exists()){
file.mkdir();
}
InputStream input=null;
FileOutputStream os=null;
for (int i= 0; i <200; i++) {
String string=out.get(i);
String st=string.substring(string.length()-4,string.length());
File file2=new File(file,i+st);
try {
//file2.createNewFile();
URL url=new URL(string);
input=url.openStream();
os=new FileOutputStream(file2);
int len=0;
byte[] b=new byte[1024];
while((len=input.read(b))!=-1){
os.write(b,0,len);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
try {
input.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
os.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
尾声:实践是检验真理的唯一标准。别人写好的代码,你去用心思考并敲一遍代码,效果杠杆的。如果有不懂
或者建议,欢迎指 出。















 2256
2256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









