







1.spark0.9.1安装
(1)首先安装对应版本的hive(在这里是0.11)
(2)安装包安装spark0.9.1
解压缩
修改目录用户权限,用户hadoop登录
修改配置文件
//slaves
hadoop1
hadoop2
hadoop3
//spark-env.sh
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=3g
scp到个节点
(3)源码安装shark
源码下载,解压缩
源码编译
SHARK_HADOOP_VERSION=2.2.0 SHARK_YARN=true sbt/sbt assembly
修改配置文件
//shark-env.sh
export SPARK_MEM=2g
# (Required) Set the master program's memory
export SHARK_MASTER_MEM=1g
# (Optional) Specify the location of Hive's configuration directory. By default,
# Shark run scripts will point it to $SHARK_HOME/conf
export HIVE_CONF_DIR="/app/hadoop/hive013/conf"
# For running Shark in distributed mode, set the following:
export HADOOP_HOME="/app/hadoop/hadoop220"
export SPARK_HOME="/app/hadoop/spark091"
export MASTER="spark://hadoop1:7077"
scp到个节点
(4)启动
启动hive metasotre service
nohup bin/hive --service metastore > metastore.log 2>&1 &
启动shark
bin/shark
./bin/shark –service sharkserver <port>
./bin/shark -h <server-host> -p <server-port>
2.shark演示
演示的数据来自搜狗实验室数据(
http://www.sogou.com/labs/dl/q.html
)
//查询有多少行数据
Select count(*) from SOGOUQ1;
//显示前10行数据
select * from SOGOUQ1 limit 10;
//session查询次数排行榜
select WEBSESSION,count(WEBSESSION) as cw from sogouQ1 group by WEBSESSION order by cw desc limit 10;
//建立cache表
create table sogouQ1_cached as select * from sogouq1;
//搜索结果排名第1,但是点击次序排在第2的数据有多少?
select count(*) from sogouQ1_cached where S_SEQ=1 and C_SEQ=2;
//搜索用户点击的URL含baidu的数据有多少?
select count(*) from sogouQ1_cached where WEBSITE like '%baidu%';
//搜索结果排名第1,但是点击次序排在第2,URL含baidu的数据有多少?
select count(*) from sogouQ1_cached where S_SEQ=1 and C_SEQ=2 and WEBSITE like '%baidu%';
//session查询次数排行榜
select WEBSESSION,count(WEBSESSION) as cw from sogouQ1_cached group by WEBSESSION order by cw desc limit 10;
3.性能比较
(1)
select WEBSESSION,count(WEBSESSION) as cw from sogouQ1 group by WEBSESSION order by cw desc limit 10;
从
sogouQ1
中查询数据,
sogouQ1
没有进行缓存,用时间大概7秒左右。
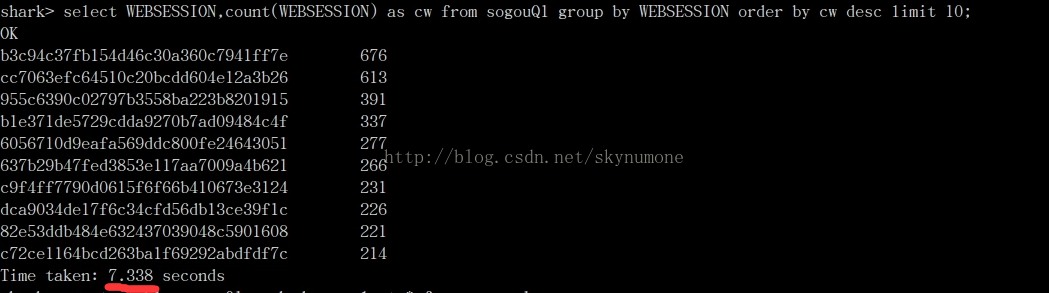
(2)将sogouQ1 进行缓存为sogouQ1_cached,再进行相同的查询,用时间大概3秒左右,性能有明显的提升。
首先进行缓存


用时间大概3秒左右,性能有明显的提升。
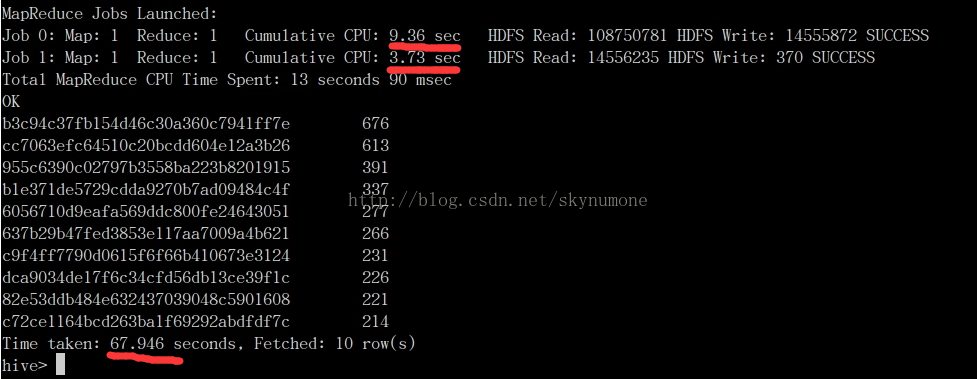
(3)用hive进行相同的查询,用时大概67秒左右,与shark的性能相差甚远。















 3015
3015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









