






前两期小Mi带大家学习了支持向量机的优化问题、如何得到大间距分类器以及其背后的数学原理,今天小Mi最后一讲让我们快速果断地结束支持向量机的学习哈。小Mi废话不多说!
4 Kernel(一)
之前小Mi曾经提过,如果遇到无法用直线进行分隔的分类问题时,可以适当采用高级数的多项式模型来解决:
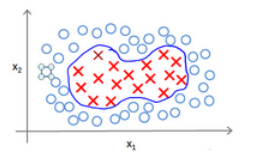
为了获得上图所示的判定边界,我们的模型可能是
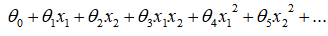
这样的形式。
用一系列的新的特征来替换模型中的每一项。例如,令:
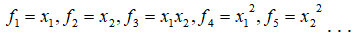
得到
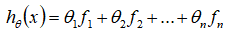
。然而,除了对原有的特征进行组合以外,有没有更好的方法来构造
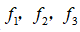
呢?
这时候小Mi就要隆重介绍下核函数这个新的定义啦。
给定一个训练样本
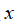
,利用各个特征与预先选定的地标(landmarks)
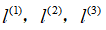
的近似程度来选取新的特征
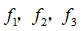
。
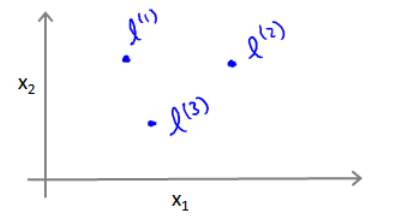
例如:
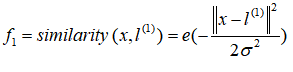
其中:
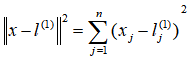
,为实例中所有特征
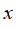
与地标
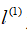
之间的距离的和。上例中的
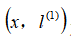
就是核函数,更详细地说,这是一个高斯核函数(Gaussian Kernel)。 注:这个函数与正态分布没什么关系,只是看上去像而已。
这样一来地标的作用又是什么呢?如果一个训练样本
与地标
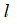
之间的距离近似于0,那么新特征
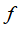
近似于
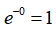
;如果训练样本
与地标
之间距离较远,则
近似于

。
假设训练样本含有两个特征
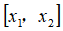
,给定地标
与不同的
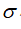
值,见下图:
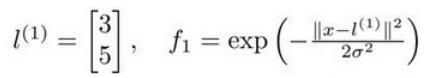
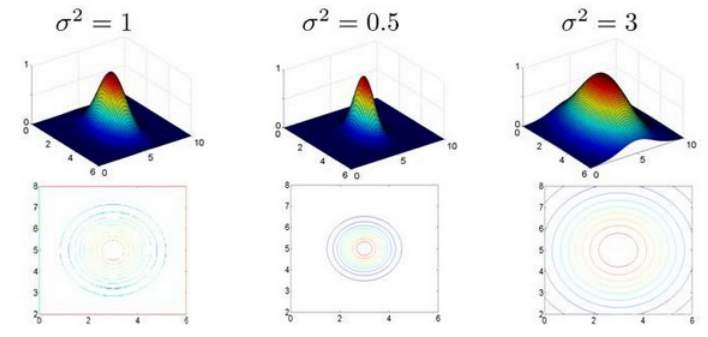
图中水平面的坐标为
,而垂直坐标轴代表
。可以看出,只有当
与
重合时
才具有最大值。随着
的改变,
值改变的速率受到
的控制。
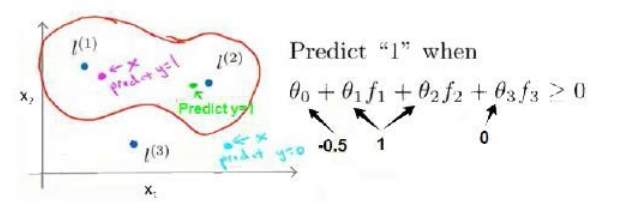
在上图中,当样本处于分红色的点位置处,因为其离
更近,但是离
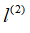
和
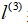
较远,因此
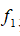
接近1,而
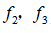
接近0。从而
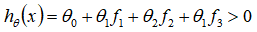
,预测
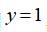
。同理可以求出,对于离较近的绿色点,也预测,但是对于蓝绿色的点,因为其离三个地标都较远,预测
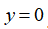
。
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练样本和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练样本本身的特征,而是通过核函数计算出的新特征
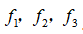
。
5 Kernel(二)
既然我们已经提出了核函数这个概念,那么如何利用它去实现支持向量机的一些新特性,并且怎么在实际中应用呢?
首先,我们需要解决的是如何选择地标的问题。
通常根据训练集的数量选择地标的数量,即如果训练集中有
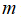
个样本,则选取
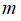
个地标,并且令:
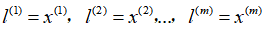
。这样做的好处在于:现在我们得到的新特征是建立在原有特征与训练集中所有其他特征之间距离的基础之上的,即:
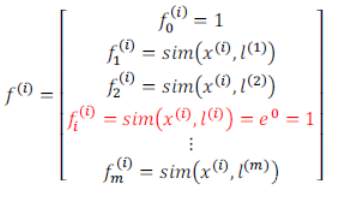

下面我们将核函数运用到支持向量机中,修改支持向量机的假设为:
给定
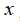
,计算新特征
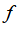
,当
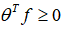
时,预测
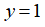
,否则反之。
相应地修改代价函数为:
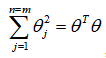
,
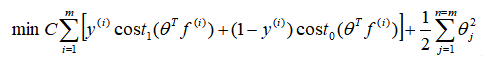
在具体运行过程中,还需要对最后的正则化项进行些微调整,在计算
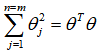
时,用
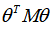
代替

,其中
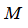
是根据我们选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。
理论上讲,我们也可以在逻辑回归中使用核函数,但是上面使用
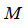
来简化计算的方法不适用于逻辑回归,因为计算将非常耗费时间。
在使用现有的软件包(如liblinear,libsvm等)最小化代价函数之前,我们通常需要编写核函数,并且如果使用高斯核函数的话,那么在使用之前进行特征缩放是非常必要的。
另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),当我们不采用非常复杂的函数,或者训练集特征非常多而样本非常少的时候,可以采用这种不带核函数的支持向量机。
下面是支持向量机中两个参数
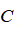
和
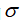
大小产生的影响:
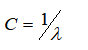
较大时,相当于
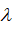
较小,可能会导致过拟合,高方差;
较小时,相当于
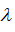
较大,可能会导致低拟合,高偏差;
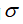
较大时,可能会导致低方差,高偏差;
较小时,可能会导致低偏差,高方差。
这就是利用核函数的支持向量机算法,希望可以帮助大家对于算法结果预期有一个直观的印象。
6 支持向量机的使用
目前为止,我们已经讨论了支持向量机比较抽象的层面,本节会涉及到如何运用支持向量机。实际上,支持向量机算法提出了一个最优化的问题。不建议大家自己写代码求解参数
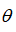
,只需要知道如何去调用库函数来实现这些功能。强烈建议使用高优化软件库中的一个(比如liblinear和libsvm)。当然除了高斯核函数之外我们还有其他一些选择,如:
多项式核函数(Polynomial Kernel)
字符串核函数(String kernel)
卡方核函数( chi-square kernel)
直方图交集核函数(histogram intersection kernel)
等等...
这些核函数的目标也都是根据训练集和地标之间的距离来构建新特征,核函数需要满足Mercer's定理,才能被支持向量机的优化软件正确处理。
多类分类问题
假设利用一对多方法来解决一个多类分类问题。如果一共有
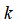
个类,则我们需要
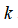
个模型,以及
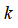
个参数向量
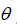
。同样,也可以训练
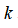
个支持向量机来解决多类分类问题。但是大多数支持向量机软件包都有内置的多类分类功能,我们只要直接使用即可。
除此之外,支持向量机还需要我们提供如下内容:
1、
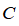
参数的选择。在之前的学习中已经讨论过误差/方差在这方面的性质。
2、需要选择内核参数或想要使用的相似函数,(如果选择不需要任何内核参数的函数,即选择线性核函数;具体来说,如果有人说他使用了线性核的支持向量机,这就意味这他使用了不带有核函数的支持向量机
同时,逻辑回归模型和支持向量机模型两者之间,我们应该如何选择呢?
下面是一些通常会使用到的准则:
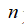
为特征数,
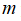
为训练样本数。
(1)如果相较于
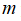
而言,
要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果
较小,而且
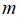
大小中等,例如
在1-1000 之间,而
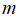
在10-10000之间,使用高斯核函数的支持向量机。
(3)如果
较小,而
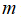
较大,例如
在1-1000之间,而
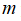
大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。
现在的支持向量机有时候仍然会存在速度较慢的问题,当我们有非常非常大的训练集,且用高斯核函数时,可以尝试手动创建更多的特征变量,然后用逻辑回归或者不带核函数的支持向量机。逻辑回归和不带核函数的支持向量机它们都是非常相似的算法,不管是逻辑回归还是不带核函数的支持向量机,通常都会做相似的工作,并给出相似的结果。但是根据实现的情况,其中一个可能会比另一个更加有效。随着支持向量机的复杂度增加,当使用不同的内核函数来学习复杂的非线性函数时,假如有上万的样本,那么特征变量的数量将是相当大的。这时不带核函数的支持向量机就会表现得相当突出。
而对于许多问题,神经网络训练起来可能会特别慢,但是如果有一个非常好的支持向量机的实现包,它可能会运行得比神经网络快很多,因为支持向量机具有优化的功能,是一种凸优化问题。因此,好的支持向量机优化软件包总是会找到全局最小值,或者接近它的值。对于支持向量机而言,并不需要担心局部最优。在实际应用中,局部最优不是神经网络所需要解决的一个重大问题,所以在使用支持向量机的时候并不需要担心这个问题。通常更加重要的是:你有多少数据,是否擅长做误差分析和排除学习算法,指出如何设定新的特征变量和找出其他能决定学习算法的变量等等,通常这些方面会比决定是使用逻辑回归还是支持向量机更重要。
当然,支持向量机仍然被广泛认为是一种最强大的学习算法,包含了什么时候一个有效的方法去学习复杂的非线性函数。因此,实际上逻辑回归、神经网络、支持向量机可以综合使用来提高学习算法。
好啦,关于支持向量机的介绍就到这里结束啦~下周小Mi给大家来点不一样的,期待不?!我们,下周再见呦(挥手十分钟!)















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









