







 本文介绍了一种新型的矢量量化自动解码器(VQAD),它在信号压缩中实现了端到端优化,优于传统方法。通过特征网格技术,该方法在保持高质量信号重建的同时,有效解决了内存和带宽约束。实验结果展示了学习向量量化在图像质量和压缩效率上的优势。
本文介绍了一种新型的矢量量化自动解码器(VQAD),它在信号压缩中实现了端到端优化,优于传统方法。通过特征网格技术,该方法在保持高质量信号重建的同时,有效解决了内存和带宽约束。实验结果展示了学习向量量化在图像质量和压缩效率上的优势。
1. 论文基本信息

发布于: SIGGRAP 2022
2. 创新点
- 提出了矢量量化自动解码器 (VQAD) 方法,以直接学习信号的压缩特征网格,而无需直接监督。
- 论文的方法能够实现端到端压缩感知优化,这导致了比离散信号压缩的典型矢量量化方法更好的结果。
3. 背景
特征网格方法是一类特殊的神经场,它使最先进的信号重建质量成为可能,同时能够渲染并以交互速率进行训练 。这些方法将坐标嵌入到高维空间中,并从参数嵌入(特征网格)中查找插值特征,与非特征网格方法相比,该方法嵌入了具有固定函数的坐标。这允许他们将信号表示的复杂性从 MLP 转移到特征网格中(空间数据结构,例如稀疏网格 或哈希表)。这些方法需要高分辨率特征网格才能获得良好的质量。这使得它们在严格的内存、存储和带宽预算内必须运行的图形系统不太实用。除了紧凑性之外,形状表示也需要动态适应数据的空间变化复杂性、可用带宽和所需细节级别。
之前的问题:
传统的矢量量化方法可能使用简单的分割和聚类技术来创建码书,然后将信号数据映射到最近的码书向量,以进行压缩。但是,这些方法通常不会在压缩过程中考虑到整个压缩编码的最终目标,例如带宽限制、视觉或听觉质量等。新方法具有端到端压缩感知优化,这意味着它在整个压缩流水线中都能考虑到压缩的目标和质量标准。
4. Pipeline
基于特征网格的隐式神经表示方法使用插值的方法重构特征:
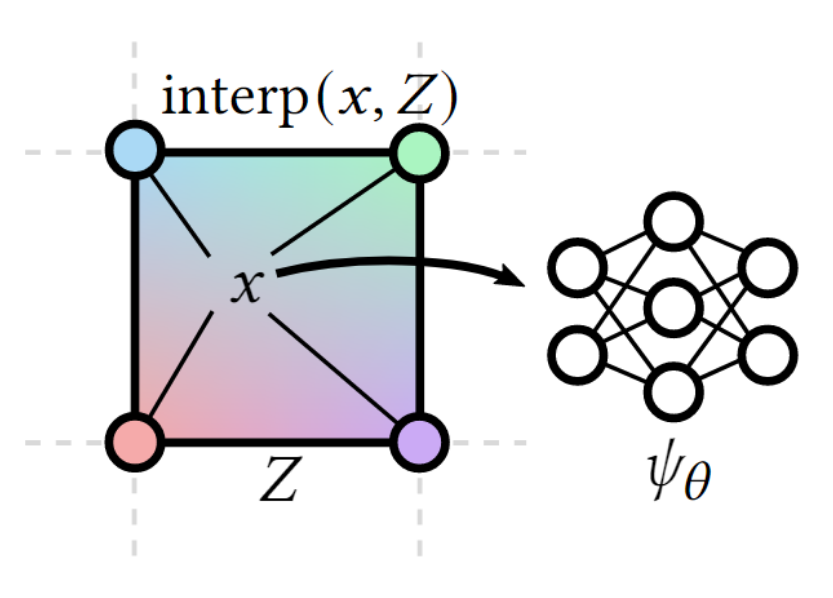
由于 𝜓𝜃(𝑥, interp(𝑥, 𝑍)) ≈ 𝑢(𝑥) 是一个非线性函数,这种方法有可能重构超过常规奈奎斯特限制的频率的信号(可以使用低频的采样得到相近的重构结果)。特征网格可以表示为一个矩阵 𝑍 ∈ R𝑚×𝑘,其中𝑚是网格点的数量,𝑘是每个网格点的特征向量的维度。由于 𝑚 × 𝑘 可能与 MLP 的大小相比相当大,特征向量远远是占用内存最多的组件。因此,论文想要压缩特征网格,并参考离散信号压缩的方法。
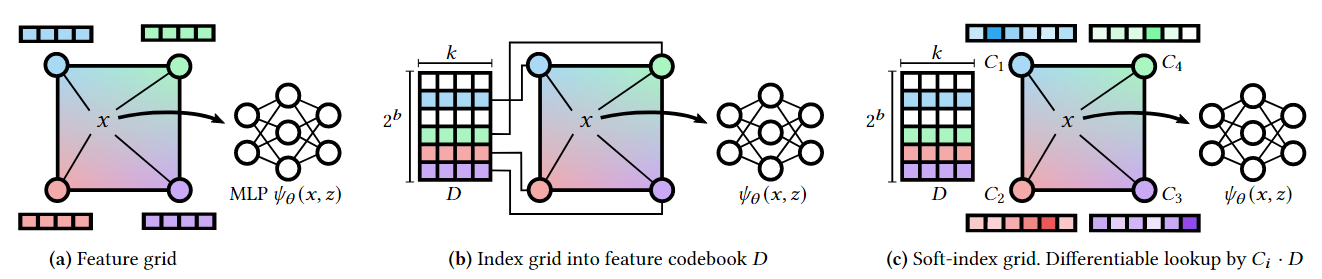
- 未压缩版本(a): 最初的数据结构是未经压缩的,即在每个网格顶点存储了笨重的特征向量,如果网格顶点数目很多,可能会有数百万个特征向量。
- 压缩版本(b): 为了减小存储大小,压缩版本将每个顶点存储为一个紧凑的 𝑏 位编码,这个编码作为索引指向一个小型的特征向量代码书(codebook)。这样做可以显著减小总体存储大小,并且在推理时可以直接使用这种表示。
- 软化索引(c): 索引操作是不可导的,因此在训练时,我们无法直接对其进行梯度下降优化。为了解决这个问题,在训练时我们将索引替换为宽度为 2𝑏 的向量 𝐶𝑖,对这些向量应用 softmax 函数 𝜎,然后再与整个代码书相乘。这种 "软化索引" 操作是可导的,并且可以通过 argmax 操作转换回在(b)中使用的 "硬" 索引。
4.1. Compressed Auto-decoder
为了有效地将离散信号压缩应用于特征网格,论文中利用了自编码器框架,其中只显式构建了解码器 𝑓−1𝛾,并且采用随机梯度下降解决以下优化问题 :
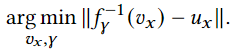
( 对于第一个公式:𝑣(𝑥) 是变换后的系数,𝑢(𝑥) 是原始信号,𝑓−1𝛾 是解码器函数,优化的目标是通过调整𝑣(𝑥) 和𝛾,使得解码器对变换后的系数𝑣(𝑥) 重构出与原始信号𝑢(𝑥) 尽可能接近的信号 )。论文中还引入了一个可微分的前向映射作为一个运算符 𝐹,它将一个信号映射到另一个领域:
![]()
(它在第一个优化问题的基础上引入了一个可微分的前向映射𝐹。这个优化问题的目标是通过调整 𝑣(𝑥) 和 𝛾,使得经过解码器解码后再经过前向映射的变换系数𝐹(𝑓−1𝛾(𝑣(𝑥))) 和原始信号经过前向映射的结果𝐹(𝑢(𝑥)) 尽可能接近)比如对于辐射场重构,感兴趣的信号 𝑢(𝑥) 是体积密度和光学色彩,而监督是关于二维图像的。在这种情况下,𝐹 表示一个可微分的渲染器。
4.2. Feature-Grid Compression
- 特征网格是一个矩阵 𝑍,其中 𝑚 是网格的大小,𝑘 是特征向量的维度。局部嵌入通过插值在坐标 𝑥 处从特征网格中查询,并通过一个 MLP 𝜓 进行重构,以重构连续信号。
- 特征网格的学习是通过优化以下方程来完成的:
![]()
其中 interp 表示对环绕 𝑥 的 8 个特征网格点进行三线性插值。前向映射 𝐹 应用于 MLP 𝜓 的输出;在实验中,它是一个可微分渲染器,𝑦 是训练图像的像素值。
- 特征网格 𝑍 可以被视为信号基于块的分解,其中每个大小为 𝑘 的行向量(块)控制局部空间区域。因此,我们考虑基于块的逆变换 𝑓−1𝛾 ,其中包含块系数 𝑉 (代码书(codebook)中的索引)。由于我们希望学习压缩特征 𝑍 = 𝑓−1𝛾 (V),我们将其替换为 𝑍:
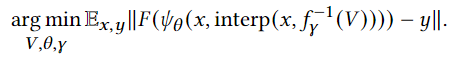
- 将 𝐹 (𝜓 (𝑥, 𝜃, interp(𝑥, 𝑍 ))) 视为一个将离散信号 𝑍 提升到连续信号的映射,其中施加监督(和其他操作),可以看到这等同于一个基于块的压缩自编码器。这使l论文中的方法能够仅使用离散信号 𝑍 来设计特征网格的压缩逆变换 𝑓−1𝛾,以论文中的方法的情况下是直接学习压缩表示的向量量化逆变换。
4.3. Vector-Quantization
- 定义压缩表示
压缩表示 𝑉 ∈ Z𝑚 ,范围在[0, 2𝑏 - 1]之间,其中𝑏是比特位数。这是对 codebook (𝐷 ∈ R2^𝑏 × 𝑘) 的索引, 其中 𝑚 是网格点的数量,𝑘 是特征向量的维度,具体来说,解码器函数被定义为𝑓−1D(𝑉) = 𝐷[𝑉],其中[·]是索引操作。优化问题为:
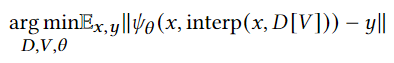
- 处理非可导索引操作
由于索引操作对整数索引 𝑉 不可导,因此解决这个优化问题是困难的。因此,在训练过程中,提出了用一个软化矩阵 𝐶 来表示整数索引。软化矩阵 𝐶 是一个 𝑚×2𝑏 的矩阵,通过在每行上进行 argmax 操作,可以得到索引向量 𝑉。然后可以用一个简单的矩阵乘法来替换索引查找,得到以下优化问题:
![]()
softmax 函数 𝜎 (代替argmax操作)被逐行应用于矩阵 𝐶。这个优化问题现在是可导的。
- 使用直通估计器
为了让损失函数在训练过程中考虑到硬索引,采用了直通估计器的方法。在前向传播中使用上述公式 1,而在反向传播中使用公式 2。
- 多分辨率稀疏八叉树
为了便于流式细节级别,将压缩表示𝑉排列成多分辨率稀疏八叉树。这样,在给定坐标时,可以获得多个特征向量 𝑧 - 每个来自树的不同级别。我们为每个树级别训练一个单独的代码书。与NGLOD类似,也联合训练多个细节级别。
5. 💎实验成果展示
这个表格比较了低秩近似(LRA)、向量量化(kmVQ)和学习向量量化(ours)在不同截断大小(对于LRA)和不同量化比特宽度(对于kmVQ和ours)下的性能。我们可以看到,学习向量量化在所有指标上都取得了显著的改进。由于比特率取决于数据,因此表中报告了平均比特率。
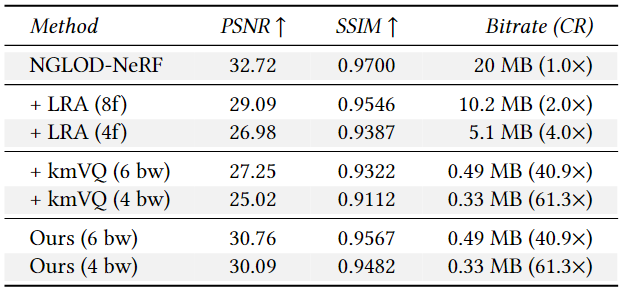
学习向量量化方法在图像质量指标(PSNR 和 SSIM)上都有较大的提升,并且能够以更高的压缩比率(较小的比特率)来实现相似的性能。
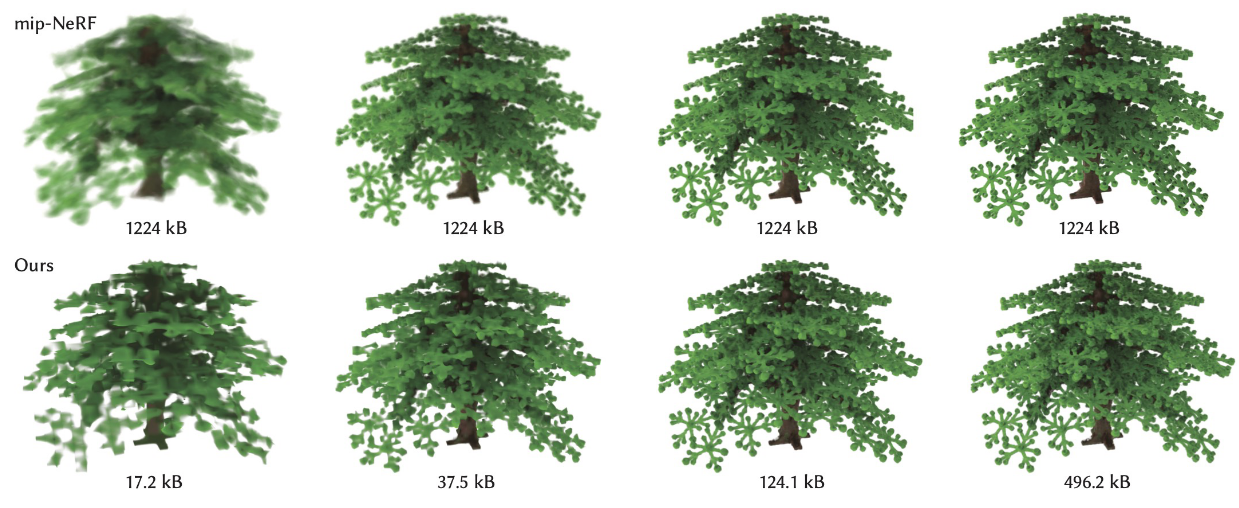
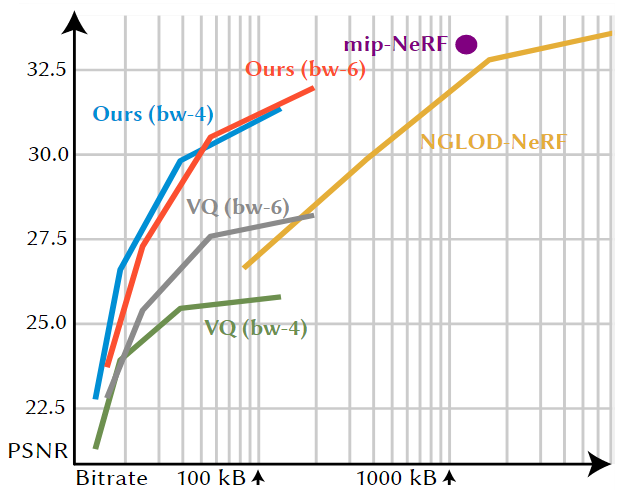
这个图显示了不同方法在“Night Fury” RTMV场景上的速率-失真(Rate-Distortion)权衡情况。图中的y轴表示PSNR(峰值信噪比),x轴表示比特率(以对数尺度表示)。单比特率架构用一个点表示。对于Mip-NeRF(紫色),过滤机制可以使点在垂直方向上移动,但不能在水平方向上移动。我们的压缩架构(红色和蓝色)具有可变比特率,能够动态调整比特率以适应不同级别的细节。我们的架构比特征网格方法(如NGLOD,黄色)更紧凑,并且比后处理方法(如k-means VQ,灰色和绿色)实现更好的质量。
6. 🔍问题分析
论文中的方法在 Instant-NGP 的基础上对特征网格做了一个自动编码的压缩工作,解决了特征网格过大不适用于现实中许多对内存网格有限制的问题。论文中的方法对原本的 grid 映射了一张 codebook 表,codebook 中的向量更加离散,适用于压缩场景,此外用于索引 codebook 的索引矩阵由于索引不是可微操作因此提出了使用软矩阵的方式,采用 softmax 的操作代替。
但是文中并没有进一步对 codebook 进行熵模型的压缩,可以尝试使用熵模型对 codebook 再次压缩,是否能的到更高效的压缩效果。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











