







 本文介绍了使用爬虫技术获取京东空气净化器数据后,如何导入、合并、去重、清洗和提取商品参数(如品牌、重量等)的过程,以及后续的数据清洗步骤和数据分析准备。
本文介绍了使用爬虫技术获取京东空气净化器数据后,如何导入、合并、去重、清洗和提取商品参数(如品牌、重量等)的过程,以及后续的数据清洗步骤和数据分析准备。
爬虫方法在本文不介绍,从爬虫数据储存成了excel格式后开始,假设已经连续爬虫了24个月,每月都爬相同的关键词和页数,达到连续分析的要求。
爬虫数据样式大概如下图:
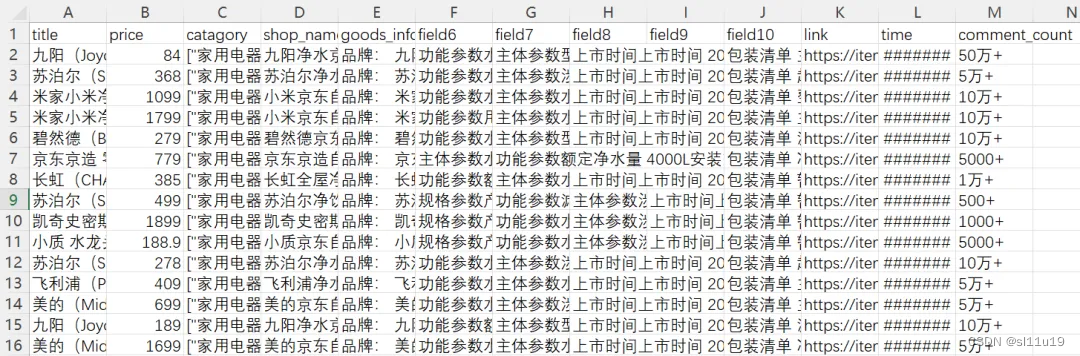
第一步:正确导入及合并24个月的数据,去除重复值,去除回车及空格键
setwd("C:/Users/Desktop/JD_DATA")
check<-read.csv(temp,fileEncoding = "gbk") #确认数据导入所需的参数,encoding可能是其它,如utf-8
temp<-list.files(pattern = "*.csv") #将24个月的数据存在同一个路径下面
data<-data.frame()
for (i in 1:length(temp){
test<-read.csv(temp[i])
data<-rbind(data,test)
}
data<-data[,c(1:5,11,6:10,12:13)] #调整列顺序
names(data)<-c("标题","价格","类别","店铺名称","商品介绍","页面网址",
"字段6","字段7","字段8","字段9","字段10","当前时间","文本")
library(stringr)
data<-unique(data) #去重
data$标题<-gsub('[\n\r]', '', data$标题)
data$标题<-gsub(' ', '', data$标题,fixed = T)
data<-subset(data,data$标题!="")
data$商品介绍<-gsub(' ', '', data$商品介绍,fixed = T)第二步:提取净水器参数字段,分别从商品介绍和合并字段中提取
#商品介绍中提取
data$品牌<-str_extract_all(data$商品介绍,"(?<=品牌:).+(?=\\n)")
data$商品毛重<-str_extract_all(data$商品介绍,"(?<=商品毛重:).+(?=\\n)")
data$商品产地<-str_extract_all(data$商品介绍,"(?<=商品产地:).+(?=\\n)")
data$出水速度<-str_extract_all(data$商品介绍,"(?<=出水速度:).+(?=\\n)")
data$适用场景<-str_extract_all(data$商品介绍,"(?<=适用场景:).+(?=\\n)")
data$类型<-str_extract_all(data$商品介绍,"(?<=类型:).+(?=\\n)")
#从字段合并中提取
data$字段6<-gsub(' ', '', data$字段6,fixed = T)
data$字段7<-gsub(' ', '', data$字段7,fixed = T)
data$字段8<-gsub(' ', '', data$字段8,fixed = T)
data$字段9<-gsub(' ', '', data$字段9,fixed = T)
data$字段10<-gsub(' ', '', data$字段10,fixed = T)
data$字段合并<-paste(data$字段6,data$字段7,data$字段8,data$字段9,data$字段10,sep="\n")
data$产品净重<-str_extract_all(data$字段合并,"(?<=产品净重).+(?=\\n)")
data$额定功率<-str_extract_all(data$字段合并,"(?<=额定功率).+(?=\\n)")
data$产品尺寸<-str_extract_all(data$字段合并,"(?<=产品尺寸).+(?=\\n)")
data$水质要求<-str_extract_all(data$字段合并,"(?<=水质要求).+(?=\\n)")
data$废水比<-str_extract_all(data$字段合并,"(?<=回收率/废水比).+(?=\\n)")
data$过滤原理<-str_extract_all(data$字段合并,"(?<=过滤原理).+(?=\\n)")
data$滤芯级数<-str_extract_all(data$字段合并,"(?<=滤芯级数).+(?=\\n)")
data$安装方式<-str_extract_all(data$字段合并,"(?<=安装方式).+(?=\\n)")
data$膜规格<-str_extract_all(data$字段合并,"(?<=膜规格).+(?=\\n)")
data$国产进口<-str_extract_all(data$字段合并,"(?<=国产/进口).+(?=\\n)")
data$膜品牌<-str_extract_all(data$字段合并,"(?<=膜品牌).+(?=\\n)")
data$流量<-str_extract_all(data$字段合并,"(?<=流量).+(?=\\n)")
data$额定净水量<-str_extract_all(data$字段合并,"(?<=额定净水量).+(?=\\n)")
data$上市时间<-str_extract_all(data$字段合并,"(?<=\n\n\n上市时间).+(?=\\n)")
colnames(data)
data1<-data[,c(6,1,2,4,5,20,12:19,21:34)] #提取完成后,可去除无用的列第三步:清洗数据,去除不符合范围的产品、品牌、单位等,将品牌统一写法(中英文及大小写)
#去除无关商品
title_delete<-c("空气净化","工业","洗碗机","水槽")
data1$temp<-grepl(paste(title_delete, collapse = "|"),data1$标题)
data1<-subset(data1,data1$temp==F)
#去除无关品牌
brand_delete<-c("华芙妮","凤焰","糖蚁","箭思洁","幻派(HUANPAT)",
"杰利普(Jielipu)","乾越(qianyue)","奥蒂罗",
"利瑞芬","隆长安","康润莱","颁荣","宓蝶",
"帝琴仕","脉秀","狸小七","洛蒂欧","澜奎",
"猪大福","紫微希阳","猪小耙(ZHUXIAOPA)",
"荏苒光阴","架悦","魔淘鑫","法奇仕",
"卡曼丹(Kamandan)","黑桃A")
data1$temp<-grepl(paste(brand_delete, collapse = "|"),data1$商品介绍)
data1<-subset(data1,data1$temp==F)
data1[,29]<-NULL #删除temp列
#统一品牌名称写法
data1$品牌<- ifelse(data1$品牌 %in% c("PHILIPS","飞利浦"), "飞利浦(PHILIPS)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("米家","米家(MIJIA)","小米","米家(xiaomi)"), "小米(MI)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("松下电器(panasonic)","松下电器","松下","Panasonic"), "松下(Panasonic)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("霍尼韦尔","HONEYWELL"), "霍尼韦尔(Honeywell)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("奥克斯"), "奥克斯(AUX)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("美的","Midea"), "美的(Midea)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("海尔","Haier"), "海尔(Haier)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("格力"), "格力(GREE)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("碧云泉"), "碧云泉(bewinch)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("西屋","Westinghouse"), "西屋(Westinghouse)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("西门子"), "西门子(SIEMENS)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("惠而浦","惠而浦(whirpool)"), "惠而浦(whirlpool)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("東芝","東芝(TOSHIBA)","东芝"), "东芝(TOSHIBA)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("摩飞","摩飞电器(MFHZPOK)"), "摩飞电器(Morphyrichards)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("华为智选","华为"), "华为(HUAWEI)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("苏泊尔"), "苏泊尔(SUPOR)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("碧然德","BRITA"), "碧然德(brita)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("华菱"), "华菱(WAHIN)", data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("沁园","沁园云之星"), "沁园(TRULIVA)",data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("碧水源"), "碧水源(Originwater)",data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("BWT"), "倍世(BWT)",data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("九阳"), "九阳(Joyoung)",data1$品牌)
data1$品牌<- ifelse(data1$品牌 %in% c("美菱(MeiLing)","美菱","美菱(MeLng)"), "美菱(MELING)",data1$品牌)
#去除单位
data1$商品毛重<-str_replace_all(as.character(data1$商品毛重),"kg","")
data1$商品毛重[grep("g",data1$商品毛重)]<-""
data1$产品净重<-str_replace_all(as.character(data1$产品净重),"kg","")
data1$产品净重[grep("g",data1$产品净重)]<-""完成后可导出数据查看数据质量,并进行可视化分析。下一篇笔记介绍空气净化器品类的分析思路及代码。


















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









