







实验二:进程的创建与可执行程序的加载
学号:SA***424 姓名:**明
实验环境:VMware,ubuntu11.04
一.进程的创建
在Linux操作系统中,用户创建一个新进程的一个方法是调用系统调用fork。在系统中调用fork返回时,子进程是父进程的一个拷贝,两个进程除了返回PID(Process ID)不同外,具有完全一样的变量值,它们打开的文件都相同。fork创造的子进程复制了父进程的资源,包括内存的task_struct,新旧进程使用同一段代码,复制数据段和堆栈段,这里采用了copy_on_write技术,即一旦子进程开始运行,则新旧的进程地址空间已经分开,二者独立运行。
二.ELF可执行文件加载到进程实体中
进程创建后,和父进程具有相同的地址空间,如果不让子进程具有自己的地址空间,则子进程的创建没有任何意义。子进程私有地址空间的建立是通过调用系统调用do_execve实现的。execve()是操作系统提供的非常重要的一个系统调用,其实在Linux中并没有exec()这个系统调用,exec只是用来描述一组函数,它们都以exec开头,分别是:
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
这几个都是都是libc中经过包装的的库函数,最后通过系统调用execve()实现。exec 函数的作用是在当前进程里执行可执行文件,也就是根据指定的文件名找到可执行文件,用它来取代当前进程的内容,并且这个取代是不可逆的,即被替换掉的内容不再保存,当可执行文件结束,整个进程也随之僵死。因为当前进程的代码段,数据段和堆栈等都已经被新的内容取代,所以exec函数族的函数执行成功后不会返回,失败是返回-1。可执行文件既可以是二进制文件,也可以是可执行的脚本文件,两者在加载时略有差别,这里主要分析二进制文件的运行。
sys_execve()是execve()系统调用的入口,系统调用的时候,把参数依次在:ebx,ecx,edx,esi,edi,ebp,eax寄存器,第一个参数为可执行文件路径,第二个参数为参数的个数,第三个参数为可执行文件对应的参数,参考代码见附录(附录中分析)。
在用户态下调用execve(),引发系统中断后,在内核态执行的相应函数是do_sys_execve(),而do_sys_execve()会调用 do_execve()函数。do_execve()首先会读入可执行文件,如果可执行文件不存在,会报错。然后对可执行文件的权限进行检查。如果文件不是当前用户是可执行的,则execve()会返回-1,报permission denied的错误。否则继续读入运行可执行文件时所需的信息(见struct linux_binprm )。
接着系统调用search_binary_handler(),根据可执行文件的类型(如shell,a.out,ELF等),查找到相应的处理函数(系统为每种文件类型创建了一个struct linux_binfmt,并把其串在一个链表上,执行时遍历这个链表,找到相应类型的结构。如果要自己定义一种可执行文件格式,也需要实现这么一个 handler()。然后执行相应的load_binary()函数开始加载可执行文件。
在调用特定的load_binary函数加载一定格式的可执行文件后,程式将返回到sys_execve函数中继续执行。该函数在完成最后几步的清理工作后,将会结束处理并返回到用户态中,最后,系统将会将CPU分配给新加载的elf文件。
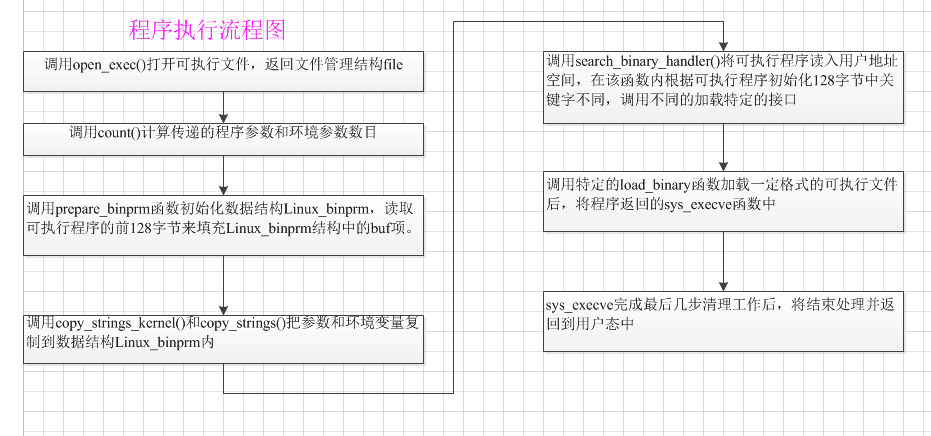
返回到用户态后EIP寄存器直接跳转到ELF程序的入口地址,于是新的程序开始执行,ELF可执行文件装载完成。
三.实验结果
附录1 :shell.c源码
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<unistd.h>
#include<string.h>
int main(){
pid_t pid;
pid=fork();
if(pid==0){ printf("this is Children process!\n");
sleep(1);
execl("/bin/ls","ls",NULL);
}
else if(pid>0){
wait(NULL);
printf("this is Parent process!\n");
execl("/bin/ps","ps",NULL);
}
else printf("fork faliure");
exit(0);
}
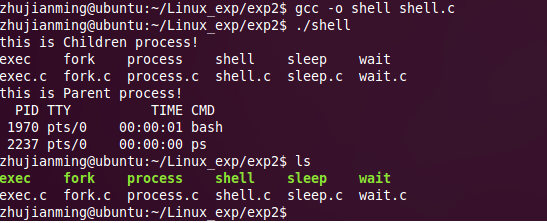
shell.c程序使用了fork(),可以看到fork出来了一个子进程,执行了pid=0的情况,父子进程都调用了execl()函数,分别执行在当前目录下使用“ls”,“ps”命令来查看当前目录下的所有目录以及当前运行的进程情况。用wait(NULL)使得父进程在子进程结束后才执行。
附录2:fork系统调用在内核中的执行过程
Starting program: /home/zhujianming/Linux_exp/exp2/fork 8
Breakpoint 1, main () at fork.c:8
8 pid=fork();
(gdb) disassemble fork
Dump of assembler code for function fork:
0x001c8020 <+0>: push %ebp
0x001c8021 <+1>: mov %esp,%ebp
0x001c8023 <+3>: push %edi
0x001c8024 <+4>: push %esi
0x001c8025 <+5>: push %ebx
0x001c8026 <+6>: call 0x145c6f
0x001c802b <+11>: add $0xc3fc9,%ebx
0x001c8031 <+17>: sub $0x20,%esp
0x001c8034 <+20>: lea 0x0(%esi,%eiz,1),%esi
0x001c8038 <+24>: mov 0x3744(%ebx),%esi
0x001c803e <+30>: test %esi,%esi
0x001c8040 <+32>: je 0x1c8278 <fork+600>
0x001c8046 <+38>: mov 0x14(%esi),%eax
0x001c8049 <+41>: test %eax,%eax
0x001c804b <+43>: je 0x1c8038 <fork+24>
0x001c804d <+45>: mov 0x3744(%ebx),%edx
0x001c8053 <+51>: lea 0x1(%eax),%ecx
0x001c8056 <+54>: lock cmpxchg %ecx,0x14(%edx)
0x001c805b <+59>: jne 0x1c8038 <fork+24>
0x001c805d <+61>: xor %edi,%edi
0x001c805f <+63>: jmp 0x1c806e <fork+78>
0x001c8061 <+65>: lea 0x0(%esi,%eiz,1),%esi附录3:可执行文件加载进程实体中代码导读(按照流程图分析源码)
asmlinkage int sys_execve(struct pt_regs regs)
//该系统调用所需要的参数pt_regs在include/asm-i386/ptrace.h文件中定义:
//struct pt_regs {
//long ebx;
//long ecx;
//long edx;
//long esi;
//long edi;
//long ebp;
//long eax;
//int xds;
//int xes;
//long orig_eax;
//long eip;
//int xcs;
//long eflags;
//long esp;
//int xss;}
{
int error;
char * filename;
//将用户空间的第一个参数(也就是可执行文件的路径)复制到内核
filename = getname((char __user *) regs.ebx);
error = PTR_ERR(filename);
if (IS_ERR(filename))
goto out;
//执行可执行文件
error = do_execve(filename,
(char __user * __user *) regs.ecx,
(char __user * __user *) regs.edx,
®s);
if (error == 0) {
task_lock(current);
current->ptrace &= ~PT_DTRACE;
task_unlock(current);
//确定没有返回正在使用的系统调用
set_thread_flag(TIF_IRET);
}
//释放内存
putname(filename);
out:
return error;
}
int do_execve(char * filename, char ** argv, char ** envp, struct pt_regs * regs)
{
//linux_binprm:保存可执行文件的一些参数
struct linux_binprm bprm;
struct file *file;
int retval;
int i;
file = open_exec(filename);//在内核中打开这个可执行文件
retval = PTR_ERR(file);
if (IS_ERR(file))//如果打开失败
return retval;
bprm.p = PAGE_SIZE*MAX_ARG_PAGES-sizeof(void *);
//保留堆栈最顶部的一个字,bprm.p是bprm.page上的相对堆栈指针,同时反映了参 数页可用内存的大小
memset(bprm.page, 0, MAX_ARG_PAGES*sizeof(bprm.page[0]));
//清除参数页面指针表
bprm.file = file;
bprm.filename = filename;
bprm.sh_bang = 0;
bprm.loader = 0;
bprm.exec = 0;
if ((bprm.argc = count(argv, bprm.p / sizeof(void *))) < 0) {
//扫描用户参数数组,计算参数个数
allow_write_access(file);
fput(file);
return bprm.argc;
}
if ((bprm.envc = count(envp, bprm.p / sizeof(void *))) < 0) {
//扫描用户环境数组,计算环境变量的个数
allow_write_access(file);
fput(file);
return bprm.envc;
}
//检查文件能否被执行,并使用可执行文件的前128个字节来填充Linux_binprm结构中的buf项
retval = prepare_binprm(&bprm);
if (retval < 0)
goto out;
//将文件名,环境变量和命令行参数拷贝到新分配到页面中
retval = copy_strings_kernel(1, &bprm.filename, &bprm);
if (retval < 0)
goto out;
//在参数堆栈顶部首先压入可执行文件名
bprm.exec = bprm.p;
retval = copy_strings(bprm.envc, envp, &bprm);
if (retval < 0)
goto out;
//接着压入环境字符串表
retval = copy_strings(bprm.argc, argv, &bprm);
if (retval < 0)
goto out;
//再压入命令行参数字符串
retval = search_binary_handler(&bprm,regs);
//查询能够处理该可执行文件的处理函数,并调用相应的load_library方法
if (retval >= 0)
//执行成功
return retval;
out:
//发生错误,返回inode,并释放资源
allow_write_access(bprm.file);
if (bprm.file)
fput(bprm.file);
for (i = 0 ; i < MAX_ARG_PAGES ; i++) {
struct page * page = bprm.page[i];
if (page)
__free_page(page);
}
return retval;
}
1.struct linux_binprm
struct linux_binprm
{
char buf[BINPRM_BUF_SIZE]; // 保存可执行文件的头128字节
struct page *page[MAX_ARG_PAGES];
struct m_struct *mm;
unsigned long p; // 当前内存页最高地址
int sh_bang;
struct file * file; // 要执行的文件
int e_uid, e_gid; // 要执行的进程的有效用户ID和有效组ID
kernel_cap_t cap_inheritable, cap_permitted, cap_effective;
void *security;
int argc, envc; // 命令行参数和环境变量数目
char * filename; // 要执行的文件的名称
char * interp; // 要执行的文件的真实名称,通常和filename相同
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
};
2.struct linux_binfmt
在search_binary_handler函数内,根据读入数据结构linux_binprm内的二进制文件128字节头中的关键字,决定调用哪种加载函数,该加载函数定义在数据结构linux_binfmt中:
struct linux_binfmt
{
struct linux_binfmt * next;
struct module *module;
// 加载一个新的进程
int (*load_binary)(struct linux_binprm *, struct pt_regs * regs);
// 动态加载共享库
int (*load_shlib)(struct file *);
// 将当前进程的上下文保存在一个名为core的文件中
int (*core_dump)(long signr, struct pt_regs * regs, struct file * file);
unsigned long min_coredump;
};
附录4:task_struct进程控制块,ELF文件格式与进程地址空间的联系,Exec系统调用返回到用户态时EIP指向的位置
在linux 中每一个进程都由task_struct 数据结构来定义。task_struct就是我们通常所说的PCB.她是对进程控制的唯一手段也是最有效的手段. 当我们调用fork() 时, 系统会为我们产生一个task_struct结构。然后从父进程,那里继承一些数据, 并把新的进程插入到进程树中, 以待进行进程管理。
struct task_struct {
long state; /*任务的运行状态(-1 不可运行,0 可运行(就绪),>0 已停止)*/
long counter;/*运行时间片计数器(递减)*/
long priority;/*优先级*/
long signal;/*信号*/
struct sigaction sigaction[32];/*信号执行属性结构,对应信号将要执行的操作和标志信息*/
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;/*任务执行停止的退出码*/
unsigned long start_code,end_code,end_data,brk,start_stack;/*代码段地址 代码长度(字节数)
代码长度 + 数据长度(字节数)总长度 堆栈段地址*/
long pid,father,pgrp,session,leader;/*进程标识号(进程号) 父进程号 父进程组号 会话号 会话首领*/
unsigned short uid,euid,suid;/*用户标识号(用户id) 有效用户id 保存的用户id*/
unsigned short gid,egid,sgid; /*组标识号(组id) 有效组id 保存的组id*/
long alarm;/*报警定时值*/
long utime,stime,cutime,cstime,start_time;/*用户态运行时间 内核态运行时间 子进程用户态运行时间
子进程内核态运行时间 进程开始运行时刻*/
unsigned short used_math;/*标志:是否使用协处理器*/
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;/*文件创建属性屏蔽位*/
struct m_inode * pwd;/*当前工作目录i 节点结构*/
struct m_inode * root;/*根目录i节点结构*/
struct m_inode * executable;/*执行文件i节点结构*/
unsigned long close_on_exec;/*执行时关闭文件句柄位图标志*/
struct file * filp[NR_OPEN];/*进程使用的文件表结构*/
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];/*本任务的局部描述符表。0-空,1-代码段cs,2-数据和堆栈段ds&ss*/
/* tss for this task */
struct tss_struct tss;/*本进程的任务状态段信息结构*/
};
ELF文件里面,每一个 sections 内都装载了性质属性都一样的内容,比方:
1) .text section 里装载了可执行代码;
2) .data section 里面装载了被初始化的数据;
3) .bss section 里面装载了未被初始化的数据;
4) 以 .rec 打头的 sections 里面装载了重定位条目;
5) .symtab 或者 .dynsym section 里面装载了符号信息;
6) .strtab 或者 .dynstr section 里面装载了字符串信息;
7) 其他还有为满足不同目的所设置的section,比方满足调试的目的、满足动态链接与加载的目的等等。

操作系统装载ELF可执行文件时,最主要关心的是段的权限(可读、可写、可执行)。
为了减小页内的内部碎片,一个简单的方案就是:对于相同权限的段,把它们合并到一起当作一个段进行映射。基于这种方法,ELF可执行文件引入了一个概念叫做“Segment”,一个“Segment”包含一个或多个属性类似的“Section”(段)。 如把“.text”段和“.init”段合并在一起看作一个“Segment”,那么装载时就可以将它们看作一个整体一起映射,也就是说映射以后进程虚拟空间只有一个对应的VMA(虚拟地址空间),从而减少内存碎片,节省内存空间。
“segment”概念实际上是从装载的角度重新划分了ELF的各个段。在将目标文件链接成可执行文件的时候,链接器会尽量把相同权限属性的段分配在同一空间。比如可读可执行的段都放在一起,这种段的典型是代码段;可读可写的段都放在一起,这种段的典型是数据段。在ELF中把这些属性相似的、又连接在一起的段叫做一个“Segment”,而系统正式按照“Segment”而不是“Section”来映射可执行文件。
附录5:动态链接库在ELF文件格式中与进程地址空间中的表现形式
链接可以再编译时由静态编译器来完成,也可以在加载时和运行时由动态链接器来完成。链接器处理称为目标文件的二进制文件。它有三种不同的形式:可重定位的、可执行的、可加载和共享的。
链接器的两个主要任务是符号解析和重定位,符号解析将目标文件中的每个全局符号都绑定到一个唯一的定义,而重定位确定每个符号的最终存储器地址,并修改对那些目标的引用。
加载器将可执行文件的内容映射到存储器,并运行这个程序。链接器还可能生成部分链接的可执行目标文件,这样的文件有对定义在共享库中的程序和数据的未解析的引用。在加载时,加载器将部分链接的可执行映射到存储器,然后调用动态链接器,它通过加载共享库和重定位程序中的引用来完成链接任务。















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









