










 本文深入浅出地解析了Twitter的SnowFlake算法,一种用于生成唯一ID的高效算法,具有有序性和可扩展性特点。通过详细阐述算法的组成结构,包括时间戳、数据中心ID、机器ID及自增序列的作用,以及其在解决数据库自增ID和UUID生成中的问题,为读者提供了清晰的理解。
本文深入浅出地解析了Twitter的SnowFlake算法,一种用于生成唯一ID的高效算法,具有有序性和可扩展性特点。通过详细阐述算法的组成结构,包括时间戳、数据中心ID、机器ID及自增序列的作用,以及其在解决数据库自增ID和UUID生成中的问题,为读者提供了清晰的理解。
雪花算法(SnowFlake)由Twitter创造的,是一个唯一ID生成算法,且具备有序性和可扩展性.
雪花算法难吗?其实并不难,甚至说简单。思路远比技术和代码重要得多。我一直都尽量将文章写的通俗易懂,说最简单的话,看最明白的原理。
组成结构
生成出的ID是一个64bits的整数,其中时间戳占41位,数据中心ID占5位,机器ID占5位,自增序列占12位,还有1位是符号位。
这个符号位可以是无符号,这样就可以扩大使用时间或其他地方的bit位数,但在JAVA中无法忽略符号位,因为JAVA中没有unsigned这么个玩意。
上面只是设计者当初设计bit占用位数,事实上可以随便改,如果你的机器id不是很多,那么可以扩大自增序列ID
解决了什么问题
使用数据库自增ID有什么问题?
- 如果数据库使用
AUTO_INCREMENT配合replace into自增ID,那么每当数据插入都会占用自增锁和插入锁。 - 尝试爆破就可以大概了解此公司业务量
- 使用
redis String进行increment生成有序UUID,redis如果为了高可用,你还要设置redis集群中的服务器对应的自增序列步长。 - UUID库生成字符串唯一ID,
没有有序性,查找数据性能较差(在数据库中的索引如果没有有序性,插入时索引就要不停的调平衡,哪怕是B+Tree也扛不住你随机字符串的UUID)。 - 单机情况下有些人用时间戳+几位随机数做ID,分布式肯定凉凉,并且单机情况下也会有几率重复。你无法确定同一时间内是否会出现相同的随机数。
各个BIT位作用
- 41位时间戳,用来根据时间变化做递增,并且可以和最后一次生成时间做对比,如果处于同一毫秒。该如何处理
- 数据中心ID,相同的代码,相同的时间,但数据中心ID不同,就不会生成出相同的UUID。
- 机器ID,相同的代码,相同的时间,相同数据中心,但机器ID不同,就不会生成出相同的UUID。
- 递增序列,如果处于同一毫秒内,递增序列则可以自增,保证ID的不唯一,自增ID最大12字节也就是2^12-1(4095),也就是说,
一台机器,可以在同1毫秒内生成4096个ID(为0时也算一个),一秒就可以生成4,096,000个ID。
小白文理解雪花算法
知道了ID的组成结构,那么利用雪花算法手写生成唯一ID就很简单了。
我们先不考虑多线程和基于时间戳时钟回拨的问题 ,单线程的逻辑是如何的呢?

- 计算时间戳,然后向左移 数据中心ID+机器ID+自增序列号的 BIT位数
- 拿到数据中心ID 向左移机器ID+自增序列号的 BIT位数
- 拿到机器ID 向左移自增序列号的 BIT位数
- 拿到自增序列ID,和上面3个做或运算即可。
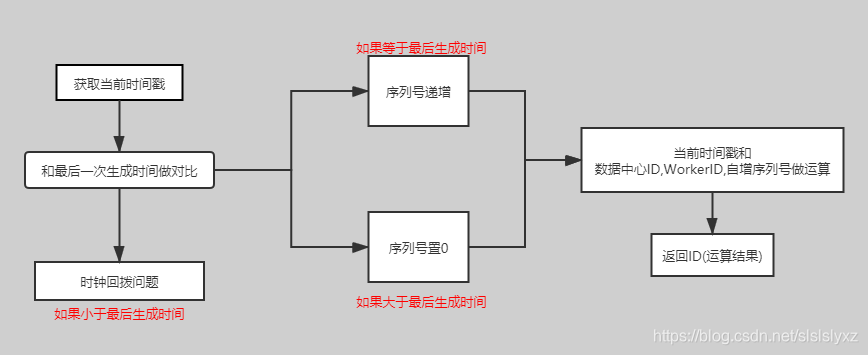
单线程下的简单栗子
private static final long EPOCH = 1577808000000L; //起始时间,固定为常量
private long sequence = 0L; //起始序列号
private long lastTimeStamp; // 最后一次生成的时间戳
private int dataCenterId; // 数据中心id 构造函数中定义
private int workerID; // 服务器id 构造函数中定义
private static final byte WORKER_ID_BITS= 5; //workerID 位数
private static final byte DATA_CENTER_ID_BITS = 5; //数据中心位数
private static final byte SEQUENCE_BITS = 12; //序列号位数
public long getID(){
long currentTimeMillis;
currentTimeMillis = System.currentTimeMillis();
if (currentTimeMillis > lastTimeStamp){
sequence = 0L;
}else if (currentTimeMillis == lastTimeStamp){
if (sequence==0xfff){ //如果12位bit占满 阻塞到下一毫秒
while(System.currentTimeMillis()==currentTimeMillis){}
currentTimeMillis = System.currentTimeMillis();
sequence = 0L;
}else{
sequence += 1L;
}
}//如果小于肯定是时钟回拨,可以尝试加锁等待或其他方式处理。
else{
LockSupport.parkNanos(TimeUnit.MILLISECONDS.toNanos(lastTimeStamp-currentTimeMillis));
currentTimeMillis = System.currentTimeMillis();
if (sequence==0xfff){ //如果12位bit占满 阻塞到下一毫秒
while(System.currentTimeMillis()==currentTimeMillis){}
currentTimeMillis = System.currentTimeMillis();
sequence = 0L;
}else{
sequence += 1L;
}
}
//记录最后一次生成时间
lastTimeStamp = currentTimeMillis;
//算出time左移22位
final long time = (currentTimeMillis - EPOCH) << SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
//数据中心 左移17位
final long dataCenter = this.dataCenterId << SEQUENCE_BITS + WORKER_ID_BITS;
//workerID 左移12位
final long worker = this.workerID << SEQUENCE_BITS;
//位或运算
return time | dataCenter | worker | sequence;
}
多线程例子不写了,上面的代码足够简单吧?
这里简单说一下时钟回拨的解决思路:
第一种: 发现时钟回拨可以进行上锁等待差值后重试。
第二种: 借用未来时间
发现时钟回拨后利用redis或本地文件映射至内存存储差值,进行增加currentTimeMillis变量的值。如果一段时间内没有申请ID,那么currentTimeMillis就会变得>lastTimeStamp,此时清除差值即可。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











