







昨天周五临下班了,心想加了一周班,今天如果不出意外的话...咳咳,不能说不能说(flag不能乱立),测试人员说系统很卡,然后去找运维,运维说机器cpu直接拉满,我方了,因为最后他测的功能是我写的,果然准时下班是不存在的,登上服务器,因为在docker里面,所以这java进程无疑就是我们的的项目,证据确凿
然后火速排查解决,原因是一个参数传漏了,导致一张几十万的表join另一张几十万的表全查,boom...敲

今天分享一下排查思路。
假如生产出现CPU占用过高,谈谈分析思路和问题定位?(结合linux命令和jdk命令)
[0].我们先模拟出一个生产CPU高占用的问题,将其放在服务器上运行
javac -d . ProduceProblemPosition.java
java com.w4xj.problemposition.ProduceProblemPositionjava代码如下,这里只是写一个简单的示例
package com.w4xj.problemposition
import java.util.Random;
import java.util.UUID;
/**
* @Author by w4xj
* @Classname ProduceProblemPosition
* @Description 模拟生产问题定位
* @Date
* @Created by IDEA
*/
public class ProduceProblemPosition {
public static void main(String[] args) {
while(true){
System.out.println(UUID.randomUUID().toString().substring(0,8) + " *^_^* " + new Random().nextInt(99999));
}
}
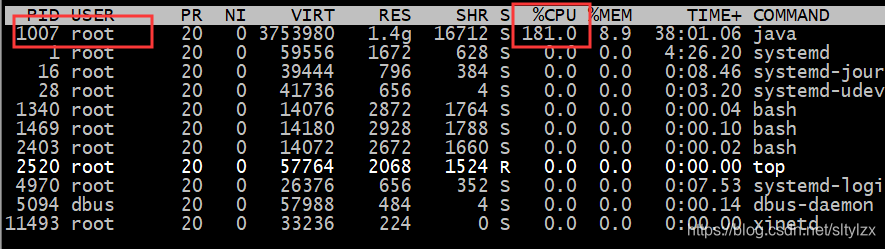
}[1].先用top命令找出CPU占用最高的程序,得知其是一个java程序,并知道其pid

[2].ps -ef 或者 jps进一步定位,得知是一个怎样后台程序占用CPU

[3].定位到具体线程或者代码
①.ps -mp 进程 -o THREAD,tid,time

②.参数
-m 显示所有的线程
-p pid进程使用cpu的时间
-o 用户自定义输出格式
[4].将需要的线程id转换为16进制格式(英文小写格式)
2376 -> 948
方式①.printf "%x\n" 2376
![]()
方式②.计算器

[5].jstack 进程id | grep tid(16进制小写英文) -A60

①.找到本公司的包名的类,定位到java类的行数
②.查看源文件

另外分享一些常用的服务器排查命令
1.生产服务器变慢,诊断思路和不同的纬度
[1].整机:top
①.load average:系统负载,三个数值若平均值大于60%,则表示系统压力过大

②.精简版:uptime

[2].CPU:vmstat
①.查看cpu(包含但不限于),vmstat -n 2 4表示每2秒采样一次,共采样4次

②.详解
i.vmstat -n x y:表示采样间隔x(单位:秒),总计采样y次
ii.-procs
r:运行和等待CPU时间片的进程数,原则上1核CPU的运行队列不要超过2,整个系统的运行队列不能超过总核数的2倍,否则代表压力过大
b:等待资源的进程数,比如正在等待磁盘I/O、网络I/O等
iii.-cpu
us:用户进程消耗CPU时间比,us值高,用户进程消耗CPU时间多,如果长期大于50%,优化程序
sy:内核进程消耗的CPU时间百分比
us + sy参考值为80%,如果us + sy大于80%,说明可能存在CPU不足
id:处于空闲的CPU百分比
wa:系统等待IO的CPU时间百分比
st:从虚拟机中偷走的百分比(如果正在使用虚拟机话,有此列,虚拟机想运行但是系统管理程序转而运行其的对象的时间,如果虚拟机不希望运行任何对象,但是系统管理员运行了其他对象,这不算被偷走的cpu时间)
iv.-memory
swpd:虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free:空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff:Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache:直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
v.-swap
si:每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so:每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
vi.-io
bi:块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo:块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
vii.-system
in:每秒CPU的中断次数,包括时间中断
cs:每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
③.额外查看
i.mpstat -P ALL 2:查看所有cpu核信息

pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
-u:默认的参数,显示各个进程的cpu使用统计
-r:显示各个进程的内存使用统计
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下文切换情况
-t:显示选择任务的线程的统计信息外的额外信息
-T { TASK | CHILD | ALL }
这个选项指定了pidstat监控的。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。ALL表示报告独立的task和task下面的所有线程。
注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。
-V:版本号
-h:在一行上显示了所有活动,这样其他程序可以容易解析。
-I:在SMP环境,表示任务的CPU使用率/内核数量
-l:显示命令名和所有参数
ii.pidstat -u 1 -p 进程编号:查看单个进程使用cpu的用量分解信息

pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
-u:默认的参数,显示各个进程的cpu使用统计
-r:显示各个进程的内存使用统计
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下文切换情况
-t:显示选择任务的线程的统计信息外的额外信息
-T { TASK | CHILD | ALL }
这个选项指定了pidstat监控的。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。ALL表示报告独立的task和task下面的所有线程。
注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。
-V:版本号
-h:在一行上显示了所有活动,这样其他程序可以容易解析。
-I:在SMP环境,表示任务的CPU使用率/内核数量
-l:显示命令名和所有参数
[3].内存:free
①.默认以kb为单位,可通过参数来调节单位
-b (B), -k (KB), -m (MB), -g (GB) and –tera (TB)

②.经验:
i.应用程序可用内存/系统物理内存>70%内存充足
ii.应用程序可用内存/系统物理内存<20%内存不足,需要增加内存
iii.20%-70%内存基本够用
③.相关:pidstat -p 进程号 -r 间隔描述

[4].硬盘:df
df -h:查看磁盘剩余空间数

[5].磁盘IO:iostat
①.命令iostat [ 选项 ] [ <时间间隔> [ <次数> ]]
②.常用参数
-c:只显示系统CPU统计信息,即单独输出avg-cpu结果,不包括device结果
-d:单独输出Device结果,不包括cpu结果
-k/-m:输出结果以kB/mB为单位,而不是以扇区数为单位
-x:输出更详细的io设备统计信息
interval/count:每次输出间隔时间,count表示输出次数,不带count表示循环输出
说明:更多选项使用使用man iostat查看
③.iostat 从系统开机到当前执行时刻的统计信息

输出含义:
avg-cpu: 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值。重点关注iowait值,表示CPU用于等待io请求的完成时间。
Device: 各磁盘设备的IO统计信息。各列含义如下:
Device: 以sdX形式显示的设备名称
tps: 每秒进程下发的IO读、写请求数量
KB_read/s: 每秒从驱动器读入的数据量,单位为K。
KB_wrtn/s: 每秒从驱动器写入的数据量,单位为K。
KB_read: 读入数据总量,单位为K。
KB_wrtn: 写入数据总量,单位为K。
④.iostat -xdk 2 3 每隔2S输出磁盘IO的详细详细,总共采样3次

以上各列的含义如下:
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
wrqm/s: 每秒对该设备的写请求被合并次数
r/s: 每秒完成的读次数
w/s: 每秒完成的写次数
rkB/s: 每秒读数据量(kB为单位)
wkB/s: 每秒写数据量(kB为单位)
avgrq-sz:平均每次IO操作的数据量(扇区数为单位)
avgqu-sz: 平均等待处理的IO请求队列长度
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
svctm: 平均每次IO请求的处理时间(毫秒为单位)
%util: 周期内用于IO操作的时间比率,即IO队列非空的时间比率,若接近100%说明磁盘带宽跑满,需要优化程序或者增加磁盘
⑤.重点关注参数
iowait% 表示CPU等待IO时间占整个CPU周期的百分比,如果iowait值超过50%,或者明显大于%system、%user以及%idle,表示IO可能存在问题。
avgqu-sz 表示磁盘IO队列长度,即IO等待个数。若长期大队列,也说明IO新能不佳
rkB/s、wkB/s、r/s、w/s若这些值一直处于很高,说明程序一直处于高IO状态,需要排查分析是否程序需要优化
await若和svctm越接近,表示磁盘IO性能好,反之,若await远大于svctm则说明IO队列等待时间过长,需要优化程序或者更换磁盘
%util 表示磁盘忙碌情况,一般该值超过80%表示该磁盘可能处于繁忙状态。
⑥.相关:pidstat -d 采样间隔秒数 -p 进程号

[6].网络IO:ifstat
①.若本地需要安装
wget http://distfiles.macports.org/ifstat/ifstat-1.1.tar.gz
tar xzvf ifstat-1.1.tar.gz
cd ifstat-1.1
./configure
make
make install
②.命令,ifstat,注意要用安装的ifstat

③.参数:
-l 监测环路网络接口。缺省情况下ifstat监测活动的所有非环路网络接口
-a 监测能检测到的所有网络接口的状态信息。
-z 隐藏流量是无的接口,如接口启动了但是未使用的。
-i <interface> 指定要监测的接口。
-s 通过SNMP查询一个远程主机。
-h 显示帮助信息
-n 关闭周期性显示头部信息。
-t 在每一行的开头加一个时间戳
-T 报告所有检测接口的全部带宽
-w 指定间隔时间(与官方的文档说明并不同,不知道是不是写文档的人写错,反正我测试后是间隔时间)
-W 如果显示内容超出终端窗口的宽度,就换行
-S 在同一行更新显示内容
-b 用kbits/s显示带宽
-q 按键模式
-v 显示版本信息
-d 指定一个驱动来收集状态信息














 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









