







 本文是Spark调研笔记的最后一篇,以代码实例说明如何借助Spark平台高效地实现推荐系统CF算法中的物品相似度计算。在推荐系统中,最经典的推荐算法无疑是协同过滤(Collaborative Filtering, CF),而item-cf又是CF算法中一个实现简单且效果不错的算法。在item-cf算法中,最关键的步骤是计算物品之间的相似度。本文以代码实例来说明如何利用Spark平台快速计算
本文是Spark调研笔记的最后一篇,以代码实例说明如何借助Spark平台高效地实现推荐系统CF算法中的物品相似度计算。在推荐系统中,最经典的推荐算法无疑是协同过滤(Collaborative Filtering, CF),而item-cf又是CF算法中一个实现简单且效果不错的算法。在item-cf算法中,最关键的步骤是计算物品之间的相似度。本文以代码实例来说明如何利用Spark平台快速计算
本文是Spark调研笔记的最后一篇,以代码实例说明如何借助Spark平台高效地实现推荐系统CF算法中的物品相似度计算。
在推荐系统中,最经典的推荐算法无疑是协同过滤(Collaborative Filtering, CF),而item-cf又是CF算法中一个实现简单且效果不错的算法。
在item-cf算法中,最关键的步骤是计算物品之间的相似度。本文以代码实例来说明如何利用Spark平台快速计算物品间的余弦相似度。
Cosine Similarity是相似度的一种常用度量,根据《推荐系统实践》一书第2.4.2节关于Item-CF算法部分的说明,其计算公式如下:
举个例子,若对item1有过行为的用户集合为{u1, u2, u3},对item2有过行为的用户集合为{u1, u3, u4, u5},则根据上面的式子,item1和item2间的相似度为2/(3*4),其中分子的2是因为item1的user_list与item2的user_list的交集长度为2,即item1和item2的共现(co-occurence)次数是2。
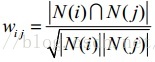
在工程实现上,根据论文"Empirical Analysis of Predictive Algorithms for Collaborative Filtering"的分析,为对活跃用户做惩罚,引入了IUF (Inverse User Frequency)的概念(与TF-IDF算法引入IDF的思路类似:活跃用户对物品相似度的贡献应该小于不活跃的用户),因此,对余弦相似度做改进后相似度计算公式如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









