







目录:
1、爬虫原理
2、本地文件数据提取及分析
3、单网页数据的读取
4、运用正则表达式完成超连接的连接匹配和提取
5、广度优先遍历,多网页的数据爬取
6、多线程的网页爬取
7、总结
爬虫实现原理
网络爬虫基本技术处理
网络爬虫是数据采集的一种方法,实际项目开发中,通过爬虫做数据采集一般只有以下几种情况:
1) 搜索引擎
2) 竞品调研
3) 舆情监控
4) 市场分析
网络爬虫的整体执行流程:
1) 确定一个(多个)种子网页
2) 进行数据的内容提取
3) 将网页中的关联网页连接提取出来
4) 将尚未爬取的关联网页内容放到一个队列中
5) 从队列中取出一个待爬取的页面,判断之前是否爬过。
6) 把没有爬过的进行爬取,并进行之前的重复操作。
7) 直到队列中没有新的内容,爬虫执行结束。
这样完成爬虫时,会有一些概念必须知道的:
1) 深度(depth):一般来说,表示从种子页到当前页的打开连接数,一般建议不要超过5层。
2) 广度(宽度)优先和深度优先:表示爬取时的优先级。建议使用广度优先,按深度的层级来顺序爬取。
Ⅰ 在进行网页爬虫前,我们先针对一个飞机事故失事的文档进行数据提取的练习,主要是温习一下上一篇的java知识,也是为了下面爬虫实现作一个热身准备。
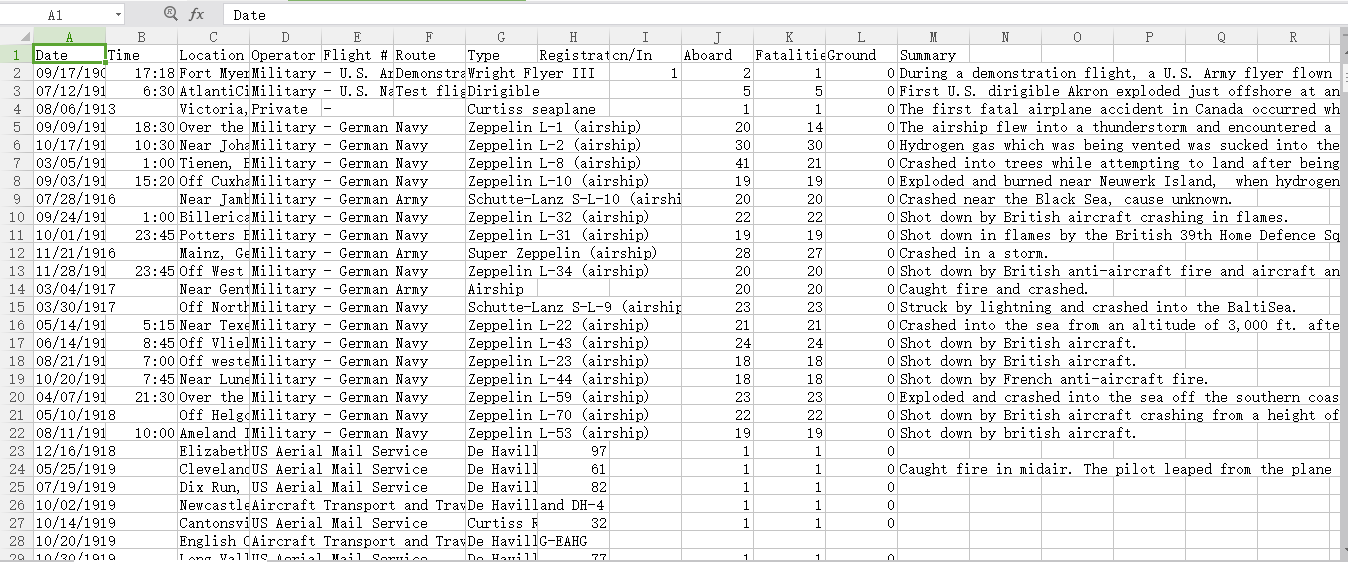
首先分析这个文档,

,关于美国历来每次飞机失事的数据,包含时间地点、驾驶员、死亡人数、总人数、事件描述,一共有12列,第一列是标题,下面一共有5268条数据。
现在我要对这个文件进行数据提取,并实现一下分析:
根据飞机事故的数据文档来进行简单数据统计。
1) 哪年出事故次数最多
2) 哪个时间段(上午 8 – 12,下午 12 – 18,晚上 18 – 24,凌晨 0 – 8 )事故出现次数最多。
3) 哪年死亡人数最多
4)哪条数据的幸存率最高。

代码实现:(一切知识从源码获取!)

1 package com.plane;
2
3 import java.io.*;
4 import java.text.ParseException;
5 import java.text.SimpleDateFormat;
6 import java.util.*;
7 /**
8 * 飞机事故统计
9 * @author k04
10 *sunwengang
11 *2017-08-11
12 */
13 public class planeaccident {
14 //数据获取存取链表
15 private static List<String> alldata=new ArrayList<>();
16
17 public static void main(String args[]){
18 getData("飞行事故数据统计_Since_1908.csv");
19 alldata.remove(0);
20 //System.out.println(alldata.size());
21 //死亡人数最多的年份
22 MaxDeadYear();
23 //事故发生次数最多的年份
24 MaxAccidentsYear();
25 //事故各个时间段发生的次数
26 FrequencyPeriod();
27 //幸村率最高的一条数据
28 MaximumSurvival();
29 }
30
31 /**
32 * 从源文件爬取数据
33 * getData(String filepath)
34 * @param filepath
35 */
36 public static void getData(String filepath){
37 File f=new File(filepath);
38 //行读取数据
39 try{
40 BufferedReader br=new BufferedReader(new FileReader(f));
41 String line=null;
42 while((line=(br.readLine()))!=null){
43 alldata.add(line);
44 }
45 br.close();
46 }catch(Exception e){
47 e.printStackTrace();
48 }
49 }
50 /**
51 * 记录每年对应的死亡人数
52 * @throws
53 * 并输出死亡人数最多的年份,及该年死亡人数
54 */
55 public static void MaxDeadYear(){
56 //记录年份对应死亡人数
57 Map<Integer,Integer> map=new HashMap<>();
58 //时间用date显示
59 SimpleDateFormat sdf=new SimpleDateFormat("MM/dd/YYYY");
60 //循环所有数据
61 for(String data:alldata){
62 //用逗号将数据分离,第一个是年份,第11个是死亡人数
63 String[] strs=data.split(",");
64 if(strs[0]!=null){
65 //获取年份
66 try {
67 Date date=sdf.parse(strs[0]);
68 int year=date.getYear();
69 //判断map中是否记录过这个数据
70 if(map.containsKey(year)){
71 //已存在,则记录数+该年死亡人数
72 map.put(year, map.get(year)+Integer.parseInt(strs[10]));
73 }else{
74 map.put(year, Integer.parseInt(strs[10]));
75 }
76
77 } catch (Exception e) {
78 // TODO Auto-generated catch block
79
80 }
81
82 }
83 }
84 //System.out.println(map);
85
86 //记录死亡人数最多的年份
87 int max_year=-1;
88 //记录死亡人数
89 int dead_count=0;
90 //用set无序获取map中的key值,即年份
91 Set<Integer> keyset=map.keySet();
92 //
93 for(int year:keyset){
94 //当前年事故死亡最多的年份,记录年和次数
95 if(map.get(year)>dead_count&&map.get(year)<10000){
96 max_year=year;
97 dead_count=map.get(year);
98 }
99 }
100
101 System.out.println("死亡人数最多的年份:"+(max_year+1901)+" 死亡人数:"+dead_count);
102 }
103 /**
104 * 记录事故次数最多的年份
105 * 输出该年及事故次数
106 */
107 public static void MaxAccidentsYear(){
108 //存放年份,该年的事故次数
109 Map<Integer,Integer> map=new HashMap<>();
110 SimpleDateFormat sdf =new SimpleDateFormat("MM/dd/YYYY");
111 //循环所有数据
112 for(String data:alldata){
113 String[] strs=data.split(",");
114 if(strs[0]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









