







 本文详细介绍了码云Gitee的架构演进过程,从最初的单机架构,到分布式存储、NFS、自研分片和Rime读写分离架构。在面临存储和并发压力时,Gitee通过不断迭代解决了各种挑战,如Ceph的性能瓶颈、NFS的稳定性问题,最终实现读写分离,提升了系统的稳定性和扩展性。
本文详细介绍了码云Gitee的架构演进过程,从最初的单机架构,到分布式存储、NFS、自研分片和Rime读写分离架构。在面临存储和并发压力时,Gitee通过不断迭代解决了各种挑战,如Ceph的性能瓶颈、NFS的稳定性问题,最终实现读写分离,提升了系统的稳定性和扩展性。
作为国内发展最快的代码托管平台,Gitee 每天数据都在飞速的增长中,而且随着 DevOps 概念的普及,持续构建也给平台带来更多的请求和更大的并发量,每天需要处理上千万的 Git 操作,Gitee 架构也是在这个过程中逐步迭代发展起来的,回望 Gitee 架构的发展,主要分为5个阶段:
- 单机架构
- 分布式存储架构
- NFS 架构
- 自研分片架构
- Rime 读写分离架构
接下来就分享下 Gitee 整个架构的演进史。
单机架构
Gitee 上线于2013年5月份,上线之初就是一个单纯的单体 Rails 应用,所有的请求都是通过这个 Rails 应用进行负载的。
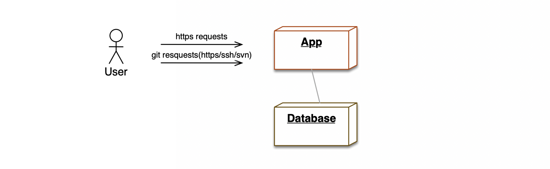
除了把 Mysql 和 Redis 单独一台机器进行部署之外,跟绝大多数 Web 应用不一样的是 Gitee 需要存储大量的 Git 仓库,无论是 Web 读写仓库还是通过 Git 的方式操作仓库,都是需要应用直接操作服务器上的裸仓库的。这种单体架构在访问量不大的时候还算可以,比如团队或者企业内部使用,但是如果把他作为一个公有云的 SaaS 服务提供出去的话,随着访问量和使用量的增长,压力也会越来越明显,主要就是以下两个:
- 存储空间的压力
- 计算资源的压力
由于开源中国社区的影响力,Gitee 在刚上线之处就涌入了大部分用户,完全不需要担心种子用户的来源。相反,随着社区用户越来越多的使用,首先遭遇的问题就是存储的压力,由于当时使用的是阿里云的云主机,最大的磁盘只能选择2T,虽然后面通过一些渠道实现了扩容,但是云主机后的物理机器也只是一个1U的机器,最多只能有4块硬盘,所以当存储达到接近8T之后,除了外挂存储设备,没有什么更好的直接扩容的方式了。
而且随着使用量的增加,每到工作日的高峰期,比如早上9点左右,下午5点左右,是推拉代码的高峰期,机器的IO几乎是满负载的,所以每到这个时候整个系统都会非常缓慢,所以系统扩容的事情刻不容缓。经过讨论,团队决定选择使用分布式存储系统 Ceph,在经过了一系列不算特别严谨的「验证」后(这也是后面出问题的根本原因),我们就采购机器开始进行系统的扩容了。
分布式存储架构
Ceph 是一个分布式文件系统,它的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,能够轻松的扩展到数PB级别的容量,所以当时的想法是借助于 Ceph 的横向扩容能力以及高可靠性,实现对存储系统的扩容,并且在存储系统上层提供多组无状态的应用,使这些应用共享 Ceph 存储,从而进一步实现了计算资源扩容的目的。
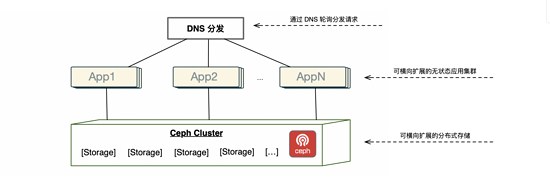
于是在2014年7月份的时候我们采购了一批机器,开始进行系统的搭建和验证,然后挑选了一个周末开始进行系统的迁移与上线。迁移完成后的功能验证一切正常,但是到了工作日,随着访问量的增加,一切开始往不好的方向发展了,整个系统开始变得非常缓慢,经过排查,发现系统的瓶颈在 Ceph 的 IO 上,于是紧急调用了一台 ISCSI 存储设备,将数据进行迁移进行压力的分担。本以为一切稳定了下来,但是更可怕的事情发生了,Ceph RBD 设备突然间被卸载,所有的仓库数据都没了,瞬间整个群和社区都炸开了锅,经过14个小时的分析和研究,终于把设备重新挂载上,然后全速将数据迁往 ISCSI 存储设备,才逐步平息了这场风波。
- 海量小文件的读写性能瓶颈
- RBD 块设备意外卸载
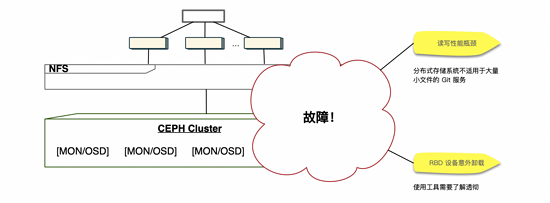
后来经过研究,才发现分布式存储系统并不适合用在 Git 这种海量小文件的场景下,因为 Git 每一次的操作都需要遍历大量的引用和对象,导致每一次操作整体耗时非常多,Github 之前发过一篇博客,也有提到分布式存储系统不适用于 Git 这种场景。而且在块设备被卸载掉的时候,我们花费了长达14个小时的时间去进行恢复,这也是对工具没有一个深入了解就去贸然使用的后果。经过这次血与泪的教训,我们更加谨慎,更加细心的去做后续所
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









