







hadoop集群的搭建与学习
-
工具的使用
1、vmare15.0连接Xshell使用
2、FZ文件上传 -
前期准备
1、VMnet1与Linux主机处在同一网段192.168.8.X 2、关闭防火墙(win、linux),以保证能够相互ping 3、修改/etc/profile文件配置jdk -
修改Linux修改/etc/hosts(所有虚拟机)重启虚拟机
192.168.8.201 yangxi1
192.168.8.202 yangxi2
192.168.8.203 yangxi3
- 修改windows下C:\Windows\System32\drivers\etc/hosts
192.168.8.201 yangxi1
192.168.8.202 yangxi2
192.168.8.203 yangxi3
- 搭建ZK集群
1、上传安装包(/usr/)
2、解压安装
3、将配置文件重命名
两种方法:- cp zoo_sample.cfg zoo.cfg
- mv zoo_sample.cfg zoo.cfg
4、配置zoo.cfg
dataDir=/usr/zookeeper/datatmp
dataLogDir=/usr/zookeeper/logs
server.1=192.168.8.201:2888:3888
server.2=192.168.8.202:2888:3888
server.3=192.168.8.203:2888:3888
-
、创建data目录、在该目录下创建myid文件
myid文件中需要写入与当前主机id对应 -
ssh免密登录
1、生成公匙、密匙
2、配置自己的登录(生成一个文件:认证的钥匙串)
3、在其他主机重复步骤1、2
4、主机间相互发送公匙 -
将配置好的ZK ,分布发送给其他主机
scp [-r] 文件(夹) 属主@hostname : 目录
scp -r /usr/zookeeper/ root@yangxi2:/ -
将ZK配置到每台主机的系统环境中(方便使用ZK命令)
-
搭建hadoop集群
1、上传安装包(/usr/)
2、解压安装
3、配置文件的修改
依次配置如下文件:- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- slaves
-
修改hadoop-env.sh、在27行添加Java路径
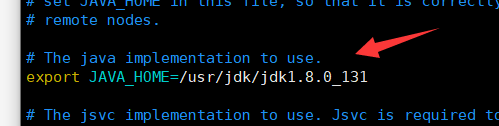
-
修改core-site.xml

3.修改hdfs-site.xml



-
修改mapred-site.xml
- 先修改配置文件名
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
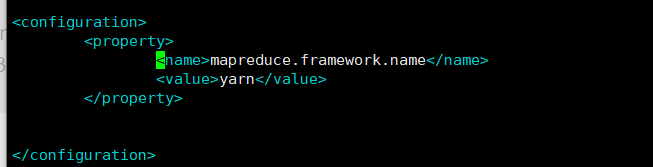
5. 修改yarn-site.xml

6.修改slaves文件
:
注:集群中的所有主机的主机名都需要添加到该文件中。
- 向其他主机分发hadoop文件
scp [-r] 文件(夹) 属主@hostname : 目录
scp -r /usr/hadoop root@yangxi2:/usr/ 分发文件到第二台主机
scp -r /usr/hadoop root@yangxi3:/usr/ 分发文件到第三台主机
- 启动服务
1、启动zookeeper集群并查看节点状态
zkServer.sh start 启动服务
zkServer.sh status 查看状态
2、在第一台主机上启动journalnode集群并查看是否出现三个进程
hadoop-daemons.sh start journalnode 启动服务
jps 查看进程
进程如下:
journalnode
jps
QuorumPeerMain
3、在第一台主机上格式化HDFS,格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,存在 /usr/hadoop/hadoop-2.0.0/tmp 的目录下,并拷贝到第二台主机 /usr/hadoop/hadoop-2.2.0/下
hdfs namenode -format 格式化
scp -r tmp/ root@yangxi2:/usr/hadoop/hadoop-2.0.0/
4、在第一台主机上格式化ZK、启动HDFS
hdfs zkfc -formatZK 格式化
start-dfs.sh 启动HDFS
5、在第三台主机上启动yarn
start-yarn.sh 启动yarn
6、查看jps进程
主机1和主机2分布有如下进程:
15297 NodeManager
14340 JournalNode
741 Jps
14119 DataNode
14538 DFSZKFailoverController
15884 NameNode
13773 QuorumPeerMain
主机3有如下进程:
9937 QuorumPeerMain
11107 ResourceManager
10836 DataNode
28037 Jps
10957 JournalNode
10637 NodeManager
- Hbase 集群
1、上传安装包(/usr/)
2、解压安装
3、配置文件的修改(详细在附件)
依次配置如下文件:- hbase-env.sh
- hbase-site.xml
- regionservers
①修改hbase-env.sh文件

②修改hbase-site.xml文件

③修改regionservers文件

4、将配置好的hbase 发给其他主机
scp -r /hbase root@yangxi2:/usr/
scp -r /hbase root@yangxi3:/usr/
5、将hadoop中的core-site.xml ,hdfs-site.xml 发到 hbase/conf/
scp [-r] 文件(夹) 属主@hostname : 目录
scp core-site.xml hdfs-site.xml root@yangxi2:/usr/hbase/hbase-0.96.2-hadoop2/conf
scp core-site.xml hdfs-site.xml root@yangxi3:/usr/hbase/hbase-0.96.2-hadoop2/conf
- 启动服务
在第一台主机上启动集群:
start-hbase.sh 启动服务
- 查看所有进程:
yangxi1:
yangxi2:
yangxi3:

















 4982
4982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









