









前言
对于事务相信大家一定非常熟悉,很多项目场景都会用到事务的概念。一般来说事务有四大特性:原子性,隔离性,一致性,永久性。Mysql也不例外,本篇会从事务开始延展到Mysql中的事务是如何工作的。更多Mysql调优内容请点击【Mysql优化-深度讲解系列目录】。
事务
简单来说事务就是一个操作的最小单元,这个操作的最小单元有以下几个特点:
- 原子性 Atomicity:指该操作不可分割,只有成功和失败两种状态,不存在中间态。
比如一个转账的场景:张三向李四转账10元。这个转账的操作要么成功李四收到10元,要么不成功李四没有收到10元,不存在不确定的状态,这就是原子性。 - 隔离性 Isolation:指任意两个事务之间在任意状态下都互相不影响。
还是转账:张三向李四转10元,王五也给李四转10元,这两笔转账操作之间在任何情况下都应该是互不影响的,这就是隔离性。 - 一致性 Consistency:指事务操作的内容,应该保持统一。
继续转账:张三向李四转10元,张三的账户就要减少10元,李四的账户就要增加10元,总数据量应该保持和转账之前的状态一致。不能转账结束,总数多了10元,这样是不可接受的,这就是一致性。 - 持久性 Durability:指事务操作记录,应该永久保存。
最后一次转账:张三向李四转10元这个操作应该被永久记录下来,任何时候都可以追踪到这条操作,这个就是永久性。
一般来说我们把需要保证原子性、隔离性、一致性和持久性的一个或多个数据库操作称之为一个事务,这就是ACID原则。
事务的用法
说完事务是什么,接着就一起来看下Mysql中的事务是怎么用的。
开启事务
BEGIN [WORK]
语句BEGIN代表开启一个事务,后面[WORK]属于可选项,类似于事务的名字。执行完BEGIN命令以后,就可以继续写SQL了,SQL语句可以写多个,这些语句都属于刚刚开启的这个事务。
START TRANSACTION
语句START TRANSACTION和BEGIN语句有着相同的功效,都标志着开启一个事务。
提交事务
COMMIT 提交
语句COMMIT代表提交一个事务,当一个事务里的SQL命令执行完毕以后执行COMMIT就可以把这个事务提交。如果不进行提交那么所有执行的SQL都是临时的,只能在当前Session中查看,其他用户的Session是不可见的。只有经过提交的事务才是有效的事务,其他的Session就对这个事务里的改变可见了。比如一个事务的完整流程是:
BEGIN; -- 也可以使用START TRANSACTION;,下面都以BEGIN为例
Update account set balance = balance – 10 where name = ‘Zhang San’;
Update account set balance = balance + 10 where name = ‘Li Si’;
COMMIT;
Autocommit 自动提交
默认情况下Mysql中都是设置的默认开启事务。即便用户没有显示的执行BEGIN或者START TRANSACTION语句开启一个事务,Mysql也会把每一条修改数据的语句算作一个独立的事务执行并提交,这种特性被称为自动提交。查看参数命令如下:
show variables like 'autocommit';
| Variable_name | Value |
|---|---|
| autocommit | ON |
如果想要屏蔽自动提交也是可以的,Mysql提供了两种方法屏蔽自动提交:
- 使用
BEGIN或者START TRANSACTION语句显示开启一个事务,就可暂时屏蔽自动提交功能。但是显示开启事务以后,同样必须显示执行COMMIT,否则用户在这个事务中执行的语句都是临时的。因为一旦显示的开启事务,在本次事务提交或者回 滚前会暂时关闭掉自动提交的功能。 - 把系统变量
autocommit的值设置为OFF,执行语句set autocommit = OFF就可以关闭自动提交功能。那么写入的多条语句就算是属于同一个事务了,直到显式的写出COMMIT语句来把这个事务提交掉,或者显式的写出ROLLBACK语句来把这个事务回滚掉,这个事务才算结束。
隐式提交
当我们使用START TRANSACTION或者BEGIN语句开启了一个事务之后,或者把系统变量autocommit设置为 OFF时,事务就不会进行自动提交。但是如果我们输入了某些特定语句后,Mysql就会悄悄的提交这个事务。这种因为某些特殊的语句而导致事务提交的情况称为隐式提交,会导致事务隐式提交的语句包括:
- 定义或修改数据库对象的数据定义语言(
Data definition language,缩写为DDL)。所谓的数据库对象,指的就是数据库、表、视图、存储过程等等这些东西。当我们使用CREATE、ALTER、DROP等语句去修改这些数据库对象时,就会隐式的提交前边语句所属于的事务。 - 隐式使用或修改mysql数据库中的表:当我们使用
ALTER USER、CREATE USER、DROP USER、GRANT、RENAME USER、SET PASSWORD等语句时也会隐式的提交前边语句所属于的事务。 - 事务控制或关于锁定的语句:当我们在一个事务还没提交或者回滚时就又使用
START TRANSACTION或者BEGIN语句开启了另一个事务时,会隐式的提交上一个事务。或者当前的autocommit系统变量的值为OFF,我们手动把它调为ON时,也会隐式的提交前边语句所属的事 务。或者使用LOCK TABLES、UNLOCK TABLES等关于锁定的语句也会隐式的提交前边语句所属 的事务。 - 加载数据的语句:比如我们使用
LOAD DATA语句来批量往数据库中导入数据时,也会隐式的提交 前边语句所属的事务。 - 其它的一些语句:使用
ANALYZE TABLE、CACHE INDEX、CHECK TABLE、FLUSH、LOAD INDEX INTO CACHE、OPTIMIZE TABLE、REPAIR TABLE、RESET等语句也会隐式的提交前边语 句所属的事务。
回滚事务
ROLLBACK 回滚
当事务执行遇到异常,或者程序出现问题的时候,事务中已经进行的操作需要回滚,当前事务也需要被终止时,可以使用这个命令让正在进行的事务终止并回滚到事务BEGIN之前的状态,比如:
BEGIN;
Update account set balance = balance – 10 where name = ‘Zhang San’;
Update account set balance = balance + 10 where name = ‘Li Si’;
ROLLBACK;
需要强调的是:ROLLBACK语句是程序员手动的去回滚事务时才去使用的,如果事务在执行过程中遇到了某些异常而无法继续执行的话,事务自身会自动回滚。
SAVEPOINT保存点
当我们开启一个事务,又进行了多条操作以后,却发现上面有数条语句有问题,全部修改会十分的麻烦,而ROLLBACK无疑会导致之前的工作付之一炬。为了避免这样的情况发生可以使用SAVEPOINT。保存点(SavePoint)语句是Mysql支持的类似存档或者断点的概念,就是在事务对应的SQL语句中设置一个或者多个标签,在调用 ROLLBACK语句时可以指定会滚到某个标签,不至于从头再来,其语法如下:
-- 创建一个保存点
SAVEPOINT SavePoint_name;
-- 当需要回滚到某个保存点的时候,其中[WORK]和[SAVEPOINT]为可选项。
ROLLBACK [WORK] TO [SAVEPOINT] SavePoint_name;
-- 当想要删除某个保存点的时候,可以执行下面的语句。
RELEASE ROLLBACK SavePoint_name;
隔离性详解
刚才已经说过事务有隔离性,隔离性也是有级别的,SQL的标准定义一共有四个级别:
未提交读 (Read Uncommit)
是指一个事务可以读到其他事务还没有提交的数据,但是可能会发生脏读。
已提交读 (Read Commit)
一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值,会出现不可重复读、幻读。
可重复读 (Repeatable Read)
一个事务第一次读过某条记录后,即使其他事务修改了该记录的值并且提交,该事务之后再读该条记录时,读到的仍是第一次读到的值,而不是每次都读到不同的数据,这就是可重复读,这种隔离级别解决了不可重复,但是还是会出现幻读。但是MySQL在这一级别的情况下帮助用户解决了幻读问题。
串行化 (Serializable)
以上3种隔离级别都允许对同一条记录同时进行读 - 读、读 - 写、写 - 读的并发操作。如果我们不允许读 - 写、写 - 读的并发操作,可以使用SERIALIZABLE隔离级别,这种隔离基金因为对同一条记录的操作都是串行的,所以不会出现脏读、幻读等现象。这也是最严谨的操作,因为对于写 - 读操作来说,在写操作的时候会被锁住,只有写操作提交了,读操作才会拿到锁。同理读 - 写操作也会被锁住,等待对应的事务提交,后续的才不会被阻塞,可以说这个级别是一个最严谨的级别,但效率会很低。
隔离性名词解释
脏读:一个事务读到了另一个未提交事务修改过的数据,因此可以说未提交读很有可能发生脏读。
幻读:如果一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来,这就是幻读。简单来说,幻读指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行,或者结果集变少了。
总之,简单来说各个级别的优缺点如下:
READ UNCOMMITTED隔离级别下,可能发生脏读、不可重复读和和幻读问题。READ COMMITTED隔离级别下,可能发生不可重复读和幻读问题,但是不会发生脏读问题。REPEATABLE READ隔离级别下,可能发生幻读问题,不会发生脏读和不可重复读的问题。SERIALIZABLE隔离级别下,各种问题都不可以发生,但是效率低。
注意:这四种隔离级别是SQL的标准定义,不同的数据库会有不同的实现。特别需要注意的是 MySQL在REPEATABLE READ隔离级别下,做了处理,可以防止幻读问题的发生,属于禁止幻读问题的发生的隔离级别。
Mysql中查看和修改隔离性:
select @@transaction_isolation; -- 查看
set session transaction isolation level read uncommitted; --修改为read uncommitted
set session transaction isolation level read committed; --修改为read committed
set session transaction isolation level repeatable read; --修改为repeatable read
set session transaction isolation level serializable; --修改为serializable
对于READ UNCOMMITTED和SERIALIZABLE来说,都比较好实现。比如READ UNCOMMITTED级别只需要一个数据库Session读取表中的数据即可获取到最新的值,就是一个正常的更新逻辑。对于SERIALIZABLE也比较好实现,类似Java中的并发,只要在获取资源的语句上加上锁,让后续的资源都等待就可以了。也就是说使用READ UNCOMMITTED隔离级别的事务,可以直接读取记录的最新版本即可,而使用SERIALIZABLE隔离级别的事务,只要使用加锁的方式来访问记录就可以了。但是READ COMMITTED和REPEATABLE READ两个级别,就有值得探究的地方了。比如Session1读取到某个数据为1,紧接着Session2修改了这个数据为5,那么Session1下次再去读这个数据的时候要读1还是要读5呢?这个问题Mysql中又是怎么实现的呢?下面就要详细的说下这个问题。
版本链
所谓的版本链其实就是网上大家所说的MVCC的原理,也叫做多版本并发控制(Multi-Version Concurrency Control)。之前笔者在【InnoDB引擎与Index索引(一)】里面提到过InnoDB中的Compact行格式除了正常的数据列以外还有三个隐藏列,如下:
| 列名 | 强制 | 说明 | 大小 |
|---|---|---|---|
| row_id | 否 | 行id,当没有指定主键的时候,作为默认主键存在,自增 | 6 Byte |
| transaction_id | 是 | 事务id | 6 Byte |
| roll_pointer | 是 | 回滚指针 | 7 Byte |
当时只是一笔带过,本次就要用上了。其中transaction_id和roll_pointer就是本次讲解的重点了:
- transaction_id:事务id代表着一行数据最新的那次改动所对应的事务。不管是插入、更新、删除这行数据都会有新的事务去影响这行数据,这里存得就是最新的事务id。
- roll_pointer:回滚指针代表一行数据的历史版本。
以上两个指针带入到InnoDB里面就形成了下图的结构:
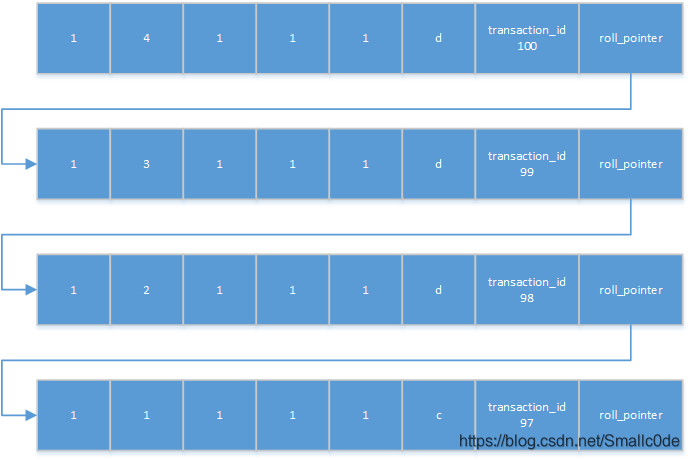
在这结构里,代表着表里的同一行数据的不同版本。最下一行的事务id说明这一行数据经过第97次事务被修改为了11111c,往上一行第98次事务就又修改为12111d,在往上这条数据又被第99次事务修改为13111d。而每次的回滚指针都指向上一次的记录,这个结构就是版本链。
ReadView
对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,就需要用到上边所说的版本链。所以核心问题就是:如何判断版本链中的哪个版本是当前事务可见的。比如基于版本链的结构,如果Session1某条消息更新到第100次事务,但是还没有提交。此时Session1可以一直读到最新的事务,因为其本身的事务id就是100。如果此时Session2在READ COMMITTED隔离级别下,必然只能读第99次事务,那么如何判断第100次事务有没有提交呢?这里就要提到另外一个名字ReadView。
ReadView
简称读视图对象,只有在Select语句中生成并使用,其中主要包含4个比较重要的内容:
- m_ids:表示在生成
ReadView时当前系统中活跃的读写事务的事务id列表,说白了就是已经开启还没有提交或者回滚的事务id列表。 - min_trx_id:表示在生成
ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。 - max_trx_id:表示生成
ReadView时系统中应该分配给下一个事务的id值。 - creator_trx_id:表示生成该
ReadView的事务的事务id。
有了这部分知识,上面Session1在生成查询语句的时候就会附带生成一个ReadView{ m_ids[100]}对象,当查询的时候就把最新的事务id拿去和m_ids里面的内容对比,如果发现存在100,那么就跟随这roll_pointer走到第99次事务继续对比,发现99号事务已经不是活跃的,说明99号已经提交,那么就读取99号的数据显示出来。
max_trx_id
值得一说的是max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比如现有m_ids里面有1、2、3三个事务,然后id=3的事务提交了,m_ids里面剩余1、2。那么一个新的读事务在生成ReadView时,m_ids就包括1、2,所以min_trx_id的值就是1,而max_trx_id的值就变为了5。这是因为生成ReadView这个操作也会生成事务id,叫做creator_trx_id,在这个例子里它就是4。
ReadView判断步骤
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的
transaction_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 - 如果被访问版本的
transaction_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事 务生成ReadView前已经提交,所以该版本可以被当前事务访问。 - 如果被访问版本的
transaction_id属性值大于ReadView中的max_trx_id值,表明生成该版本的事务在当前事 务生成ReadView后才开启,所以该版本不可以被当前事务访问。 - 如果被访问版本的
transaction_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下transaction_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃 的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版 本可以被访问。
READ COMMITTED的实现
基于上面的知识这两个级别如何实现就比较好理解了。READ COMMITTED级别在每次读取数据前都生成一个ReadView[99,100],两个都是未提交,于是去读最近的一条98号事务返回出去。但是下次在读的时候,假设100号已经被提交了,而Select又生成了一个ReadView,由于100号已经提交,于是生成了ReadView[99],那么最新一次的事务提交就是100号,这样读出来的就是100号而不是之前的98号,因此导致了幻读。
REPEATABLE READ的实现
而REPEATABLE READ级别则至少要做两次Select语句,两次查询的结果需要一致。那么只要ReadView只需要在第一次读取数据时生成一个ReadView,后面的查询不在生成ReadView就可以了。比如第一次生成了ReadView[99,100],于是去读了98号。后续的Select都使用这一个ReadView[99,100]就可以解决幻读问题,因为即便100号被提交了,由于ReadView[99,100]记录的99号和100号都不是可读的,因此仍然会读到98号事务,这就是可重复读,而且避免了幻读。但是我们还是要说一句,这一切都是在同一个事务里的,也就是在creator_trx_id这个事务id里面的select才有效,如果换了一个事务ReadView就改变了,也就无所谓可重复读了。
Multi-Version Concurrency Control 多版本并发控制
所谓的多版本并发控制Multi-Version Concurrency Control (MVCC),就是指的上所说的在使用READ COMMITTD、 REPEATABLE READ这两种隔离级别的事务在执行普通的SEELCT操作时访问记录的版本链的过程。可以使不同 事务的读 - 写、写 - 读操作并发执行,从而提升系统性能。READ COMMITTD、REPEATABLE READ这两个隔离级别的最大不同就是上面所说的:生成ReadView的时机不同,READ COMMITTD在每一次进行普通SELECT操作前都会 生成一个ReadView,而REPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了。
总结
本篇详细的讲解了什么是事务、事务的四大特性,以及Mysql中事务的操作开启、提交、回滚等等。然后针对隔离性做了一个详细的讲解,阐明了四种隔离级别的实现方法,以及特性优缺点。最后针对已提交读 (Read Commit)和可重复读 (Repeatable Read)引出Mysql中版本链的实现,以及ReadView的作用。下一篇【Mysqls深度讲解 – 锁】将会针对Mysql的锁做一个详细的讲解。














 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









