






Python爬虫是否合法的问题颇具争议,主要涉及到使用爬虫的目的、操作方式以及是否侵犯了其他人的权益。本文将介绍Python爬虫的合法性问题,并提供一些相关的法律指导和最佳实践。
1. 什么是Python爬虫?
Python爬虫是一种自动化程序,可以从互联网上获取信息并提取数据。通过模拟网页浏览器的行为,爬虫可以访问网页、抓取数据、解析内容,并将其保存到本地或用于进一步分析
2. 爬虫的合法性问题
使用Python爬虫的合法性问题主要涉及到以下几个方面:
2.1 网站的使用政策
大多数网站都有使用政策或使用条款,这些政策规定了用户在访问网站时的行为规范。在使用爬虫之前,你应该先仔细阅读网站的使用政策,了解是否允许使用爬虫程序来访问和抓取数据。
2.2 网络伦理和道德问题
使用爬虫可能会侵犯其他人的隐私和权益。如果你的爬虫程序用于获取个人信息、盗取敏感数据或滥用访问权限,那么它就是非法的。要遵循网络伦理和道德规范,确保你的爬虫程序不会侵犯他人的合法权益。
2.3 法律法规
不同国家和地区对爬虫的合法性问题有不同的法律法规。一些国家对爬虫有详细的法律规定,而另一些国家则缺乏明确的法律指导。在使用爬虫之前,你应该了解当地的法律法规,确保你的行为合法。
3. Python爬虫的合法使用指导
为了确保你使用Python爬虫的合法性,以下是一些指导原则:
3.1 确定你的使用目的
在确定使用爬虫之前,明确你的使用目的非常重要。如果你的目的是为了学习和研究,获取公开可用的信息,那么你的行为可能是合法的。例如,爬取公开的新闻网站上的新闻文章以进行文本分析是合法的。然而,如果你的目的是商业化利用他人的数据,如未经许可地收集用户个人信息用于广告推送,那么你的行为可能是非法的。
3.2 尊重网站的使用政策和使用条款
使用爬虫之前,务必仔细阅读网站的使用政策和使用条款。这些政策规定了用户在访问网站时的行为规范。有些网站可能明确禁止使用爬虫程序来访问和抓取数据,而另一些网站可能允许使用爬虫,但有一些限制。尊重网站的规定非常重要,如果网站明确禁止使用爬虫,你应该遵守这些规定。
3.2 尊重网站的使用政策和使用条款
使用爬虫之前,务必仔细阅读网站的使用政策和使用条款。这些政策规定了用户在访问网站时的行为规范。有些网站可能明确禁止使用爬虫程序来访问和抓取数据,而另一些网站可能允许使用爬虫,但有一些限制。尊重网站的规定非常重要,如果网站明确禁止使用爬虫,你应该遵守这些规定。
3.3 控制爬虫的频率和访问深度
为了减少对网站的负担,避免对其正常运行造成干扰,你应该控制爬虫的访问频率和访问深度。过于频繁的访问会给网站带来过大的负担,可能会导致网站的崩溃或服务中断。合理设置爬虫的延迟时间和访问间隔,以避免对网站造成不必要的压力。
3.4 不侵犯他人的隐私和权益
在使用爬虫时,要确保不侵犯他人的隐私和权益。不要获取个人信息、敏感数据或滥用访问权限。尊重网站的隐私政策和用户协议,遵循网络伦理和道德规范。如果你要爬取的网页包含用户个人信息,你需要获得用户的明确同意,遵守相关法律法规。
3.5 遵守当地法律法规
不同国家和地区对于爬虫的合法性问题有不同的法律法规。在使用爬虫之前,你应该了解当地的法律法规,确保你的行为合法。有些国家可能对爬虫有详细的法律规定,而另一些国家可能缺乏明确的法律指导。如果你对当地的法律法规不确定,可以咨询专业律师或相关机构的意见。
通过遵循以上指导原则,你可以确保你的Python爬虫程序的合法性。同时,要记住合法使用爬虫可以为你提供许多便利,但不当使用可能会带来法律和伦理问题。要始终保持诚信和合法性,确保你的行为不会侵犯他人的权益。
4.爬虫学习大纲
当学习Python爬虫时,以下是一个入门学习大纲供参考:
4.1. 基础知识:
-
Python基础语法:学习Python的基本语法、变量、数据类型、流程控制、函数等基础知识。
-
HTML基础:了解HTML标签的基本结构和常见标签的使用。
-
HTTP协议:熟悉HTTP请求和响应的基本结构,了解HTTP的GET、POST等常用方法
4.2. 网络请求:
-
requests库:学习如何使用Python中的requests库发送HTTP请求,并获取响应数据。
-
网络爬虫框架:了解Scrapy等常用的网络爬虫框架,学习如何使用框架进行数据爬取
4.3. 数据解析和提取:
-
正则表达式:学习正则表达式的基本语法和用法,用于从HTML文本中提取所需信息。
-
BeautifulSoup库:掌握BeautifulSoup库的使用,用于解析HTML文档,并提供简单的数据提取方法。
-
XPath:了解XPath语法,学习使用XPath从HTML文档中提取数据。
4.4. 数据存储:
-
文件存储:学习将爬取到的数据存储到本地文件中,如CSV、JSON等格式。
-
数据库存储:了解如何将爬取到的数据存储到数据库中,如MySQL、MongoDB等。
4.5. 反爬虫和数据清洗:
-
反爬虫机制:学习常见的反爬虫机制,如User-Agent检测、验证码处理等。
-
数据清洗:了解数据清洗的基本方法,如去除HTML标签、去除重复数据等。
4.6. 进阶技巧:
-
并发爬虫:学习如何使用多线程、协程等技术提高爬虫的效率。
-
动态网页爬取:了解如何处理使用JavaScript动态生成内容的网页。
-
IP代理和登录验证:了解如何使用IP代理和处理登录验证等问题。
4.7. 伦理和法律问题:
-
合法使用:学习爬虫的合法使用原则,遵守网站的使用条款和隐私政策。
-
遵守法律法规:了解当地的法律法规,确保爬虫行为合法。
以上是一个大致的学习大纲,你可以按照顺序逐步学习每个模块,逐渐掌握Python爬虫的技能。同时,可以结合实际项目和练习来提升自己的能力。记住,不断实践和探索是学习爬虫的关键。
5.爬虫使用场景:
假设你正在研究某个特定领域的产品价格走势,并希望通过爬取相关网站上的商品价格数据来进行分析和比较。
5.1. 数据采集:
使用爬虫技术,你可以编写程序来自动访问目标网站,获取商品页面的HTML内容。
5.2. 数据解析:
利用解析库(如BeautifulSoup或XPath),你可以从HTML中提取出商品名称、价格、评价等关键信息。
5.3. 数据存储:
将爬取到的数据存储到本地文件或数据库中,以备后续的分析和处理。
5.4. 数据分析:
通过对爬取到的数据进行统计、可视化等操作,你可以对不同商品的价格走势进行比较和分析。
通过这个场景,你可以了解到如何使用爬虫来获取所需的数据,然后进行后续的数据处理和分析。这种爬虫应用可以帮助你快速、准确地获取大量数据,并提供数据支持来进行定量分析和决策。
6. 结论
Python爬虫的合法性问题是一个复杂而有争议的话题。在使用爬虫之前,你应该了解网站的使用政策、遵循网络伦理和道德规范,并遵守当地的法律法规。合法使用爬虫可以为你提供许多便利,但不当使用可能会带来法律和伦理问题。要始终保持诚信和合法性,确保你的行为不会侵犯他人的权益。
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python书籍和视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
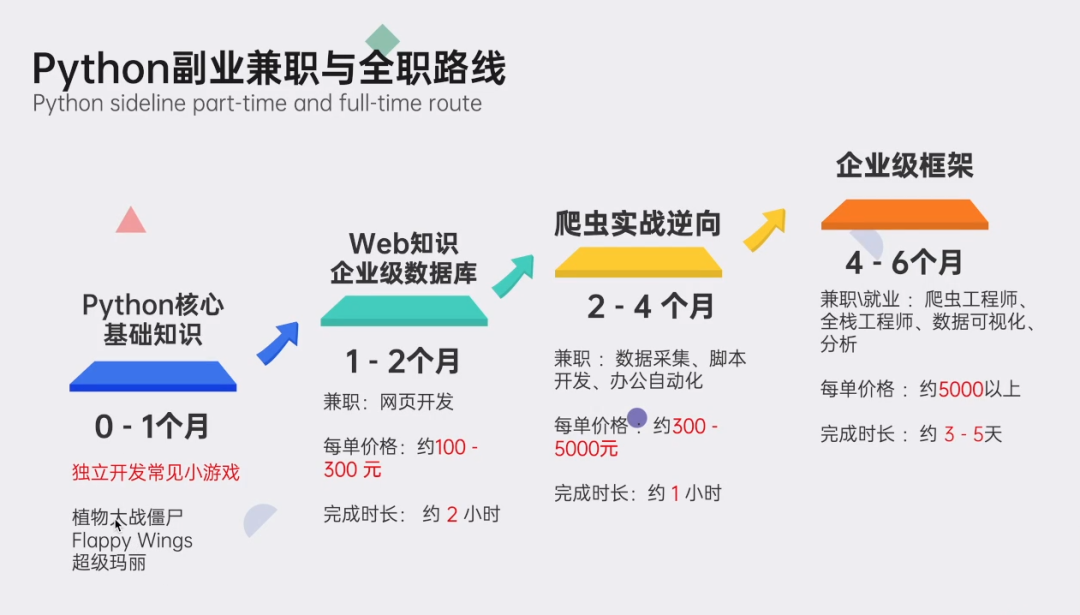
👉Python副业创收路线👈
这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
本文转自网络,如有侵权,请联系删除。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









