








Python,速成心法
敲代码,查资料**,问度娘**
练习,探索,总结,优化


本期将介绍,必应词典翻译的解析数据的3种方法
必应官网:https://cn.bing.com/dict/search?q=great

BeautifulSoup4:是一个用于解析HTML和XML文档的Python库。它可以帮助我们从HTML和XML文档中提取数据,是Python中最流行的数据解析库之一。它可以从网页中提取数据,可以对XML和HTML格式的数据进行解析,可以轻松地从网页中提取所需的信息。BeautifulSoup4能够自动转换编码,方便我们应对各种编码格式的网站,还能自动格式化输出,方便日常开发和调试。目前很少再用bs4解析了,因为它模块已经停止更新了。
↓ 01使用beautifulsoup4解析数据 ↓
#本期掌握内容:学会用抓包工具/开发者工具+find找到标签下,从而得到自己需要的数据``#https://cn.bing.com/dict/search?q=great``import requests``from bs4 import BeautifulSoup``print('\n','在线必应词典'.center(50,'—'))``#去空格``word=input('请输入你要查询的单词:').strip()``#1.网址传参数的两种写法``#url='https://cn.bing.com/dict/search?q={}'.format(word)``url=f'https://cn.bing.com/dict/search?q={word}'``res=requests.get(url)``#如果得到的源码不是乱码,就不需要编码``#2.解析数据``soup=BeautifulSoup(res.text,'lxml')``#print(soup)``#<div class="qdef">查找一个与查找多个findAll``data=soup.find('div',class_='qdef').find('ul').findAll('li')`` ``#3.打印得到的数据``for i in data:` `print(i.text.strip())`` ``print('\n查询完毕!!')`` ``#总结:利用网页开发者工具,逐级找标签,得到列表数据,遍历循环

Parsel是一个基于XPath和CSS选择器的Scrapy选择器库,它提供了与lxml库类似的接口,具有简单易用,扩展性强的特点。它可以用于在HTML和XML文档中提取和处理数据,是Scrapy框架中的一个重要组件。
↓ 02使用parsel中的xpath解析数据↓
#使用parsel模块中xpath解析数据``#https://cn.bing.com/dict/search?q=great``import requests``import parsel`` ``headers = {` `"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"``}`` ``print('\n','在线必应词典'.center(50,'—'))``#去空格``word=input('请输入你要查询的单词:').strip()``#1.网址传参数的两种写法``#url='https://cn.bing.com/dict/search?q={}'.format(word)``url=f'https://cn.bing.com/dict/search?q={word}'``html=requests.get(url).text`` ``#2.解析数据``selector = parsel.Selector(html)``data= selector.xpath(".//div[@class='qdef']/ul/li")``#print(data)``#3.打印得到的数据``for i in data:` `print(i.xpath('string(.)').getall()[0])`` ``print('\n查询完毕!!')``
lxml是Python中一个用于处理XML和HTML文档的库,它基于C语言库libxml2和libxslt实现。lxml提供了简单的API,使得处理XML和HTML文档变得简单而高效。lxml提供了许多有用的功能,包括XPath选择器、HTML和XML的解析器、解析HTML文档时的自动修正、文档序列化、内置支持Unicode和字符编码转换等等。
↓ 03使用etree中的xpath解析数据↓
#使用etree模块中xpath解析数据``#https://cn.bing.com/dict/search?q=great``import requests``from lxml import etree`` ``headers = {` `"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"``}`` ``print('\n','在线必应词典'.center(50,'—'))``#去空格``word=input('请输入你要查询的单词:').strip()``#1.网址传参数的两种写法``#url='https://cn.bing.com/dict/search?q={}'.format(word)``url=f'https://cn.bing.com/dict/search?q={word}'`` ``response = requests.get(url, headers=headers)`` ``#2.解析数据``html = etree.HTML(response.text)``data = html.xpath('//div[@class="qdef"]/ul/li')``#print(data)``#3.打印得到的数据``for i in data:` `print(i.xpath('string(.)'))`` ``print('\n查询完毕!!')``
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python书籍和视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉Python副业创收路线👈
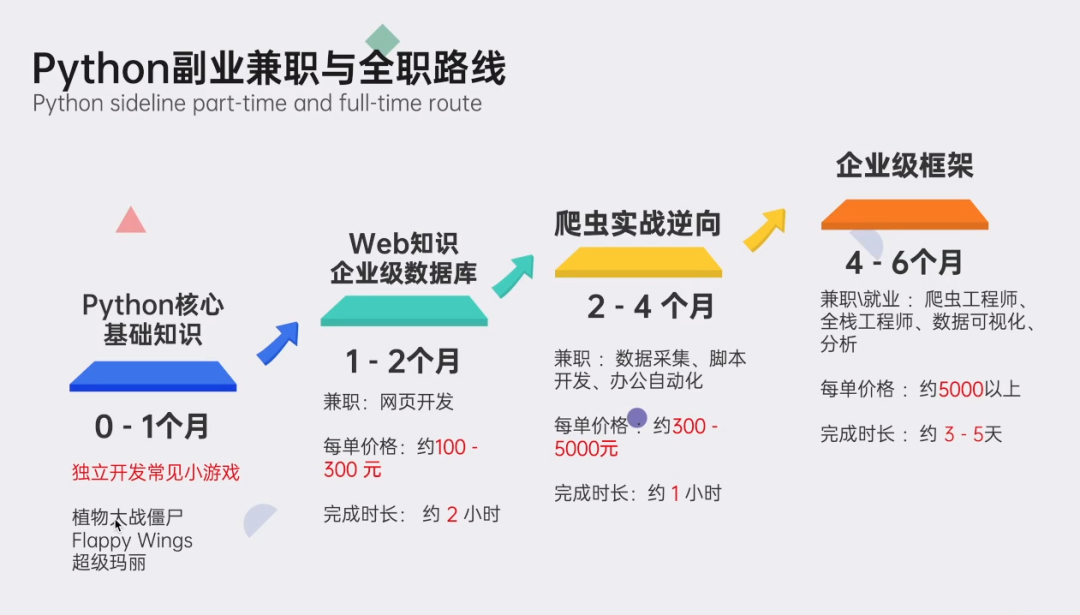
这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
本文转自网络,如有侵权,请联系删除。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









