







所谓图片爬虫,即是从互联网中自动把对方服务器上的图片爬下来的爬虫程序。
一、图片爬虫前的网页链接分析
1.首先打开淘宝首页,在搜索框中输入关键词,如“神舟”,在搜索结果界面中点击下一页,分别打开第一页,第二页,第三页的搜索结果,并记下每一页结果的URL至记事本中,如下:
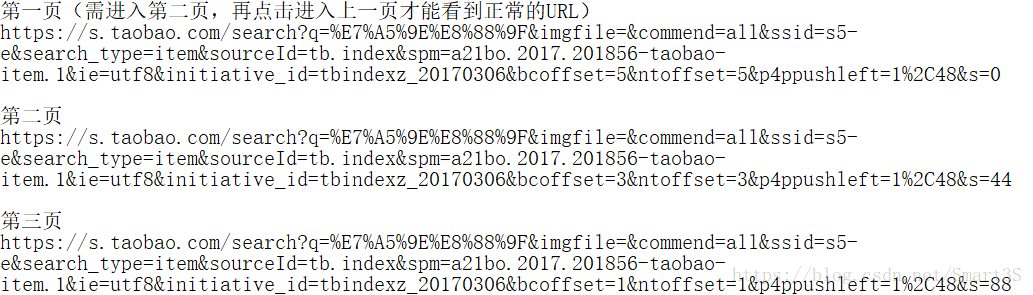
2.观察每一个网页的URL,不要去观察它们不同的部分,而是着眼于每个URL中相似的部分。
(1)可以注意到每个URL中都有“s=XXX”部分,推测为代表了不同的页码的数值,0代表第一页,44代表了第二页,88代表了第三页,推测132代表第四页,将第一页的URL中的“s=0”修改为“s=132”,即可发现神奇般地跳转到了第四页。
(2)虽然将URL复制下来之后无法看到关键词,但是在浏览器中可以清晰看到“q=XXX”为输入的关键词内容,可以推测,浏览器在实际获取网页时将中文字符进行了编码。
3.因此可以初步设想出图片爬虫所需要的网页链接的结构:
二、图片爬虫前的图片链接分析
1.右键单击淘宝网页上的图片,点击复制图片地址,粘贴到记事本中分析:
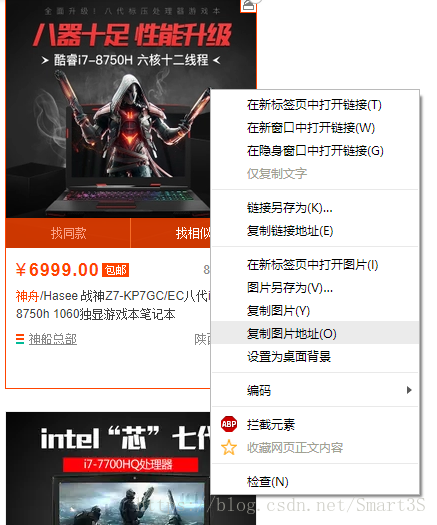
3.观察URL,注意到前半部分为图片资源在服务器中的地址,后半部分为图片名称以及其格式,特别是“250X250”代表了图片的分辨率,因为在淘宝搜索页中,为节省资源,采取了缩略图的方式。
4.将图片URL中的核心部分,如本例的“TB2ISTydyCYBuNkSnaVXXcMsVXa”在源代码页面中进行搜索:
将链接复制下来打开,即可发现,高清大图无处遁形:
5.观察图片链接的前后格式,注意到前以 pic_url":" 开头,后以 ", 结尾,本例内容比较简单,无需进行抓包即可获取图片链接。
三、图片爬虫程序编写
import urllib.request
import re
keyname="神舟"
key=urllib.request.quote(keyname) #编码
#尝试爬取前三页内容
for i in range(0,3):
#构造页面URL
url="https://s.taobao.com/search?q="+key+"&s=44"
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat='pic_url":"//(.*?)"'
#获得图片URL
imagelist=re.compile(pat).findall(data)
for j in range(0,len(imagelist)):
thisimg=imagelist[j]
#构造图片URL
thisimgurl="http://"+thisimg
file="F:/taobaoIMG/"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(thisimgurl,filename=file)













 3247
3247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









