







作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
码哥源码部分
码哥讲源码-原理源码篇【2024年最新大厂关于线程池使用的场景题】
码哥讲源码-原理源码篇【揭秘join方法的唤醒本质上决定于jvm的底层析构函数】
码哥源码-原理源码篇【Doug Lea为什么要将成员变量赋值给局部变量后再操作?】
码哥讲源码【谁再说Spring不支持多线程事务,你给我抽他!】
打脸系列【020-3小时讲解MESI协议和volatile之间的关系,那些将x86下的验证结果当作最终结果的水货们请闭嘴】
1 介绍
1.1 数据一致性的概念
缓存与数据库的数据一致性指的是,缓存中存储的数据与数据库中存储的数据需保持一致。
即缓存中存有数据,缓存的数据值 = 数据库中的值;缓存中没有该数据,数据库中的值 = 最新值。数据一致性主要包含以下两种情况:
- 缓存中有数据,那么缓存中的值需要和数据库中值相同。
- 缓存中本身没有数据,那么,数据库中的值必须是最新值。
如果存在以下情况,则说明存在不一致性情况:
- 缓存中有数据,但是缓存中的数据与数据库中的数据不一致。
- 缓存或者数据库中存在旧的数据,导致单个线程读到的数据是旧的。
1.2 数据不一致的原因
缓存(Redis)和 数据库(MySQL)是两套系统,所以任何一方的数据改写,都需要另一方的协同来保证。但这种协同可能存在一定的失败率,如下:
- 数据库更新出错:在更新数据库时发生错误,导致缓存中的数据与数据库中的数据不一致。
- 缓存刷新机制错误:一些缓存系统可能存在刷新机制的问题,导致缓存中的数据没有及时更新,从而与数据库数据出现不一致的情况。
- 并发请求:当有多个请求同时进行操作时,由于缓存、数据库操作的顺序和时机不同,可能造成不一致的情况。
- 数据一致性策略不当:在实现缓存和数据库的数据一致性策略时,如果选择不当的数据一致性策略,可能会导致数据不一致的情况。
为了保持缓存和数据库的数据一致性,需要采取适当的一致性策略(如引入 2PC 或 Paxos 等分布式一致性协议,或者分布式锁),并及时处理数据库更新和缓存刷新中的错误。同时,在实现并发请求时,需要合理控制操作的顺序和时机,以避免不一致的情况发生。
2 缓存的执行策略
我们先来了解下缓存常用的执行策略,再分析下那种策略最适合一致性保障。
- Cache-Aside(缓存旁路):这是最广泛使用的缓存策略之一。在读取数据时,先从缓存中读取数据,如果缓存中没有数据,则从数据库中读取数据,并将读取到的数据存储到缓存中。在写入数据时,先写入数据库,然后更新缓存中的数据。这个策略可以极大地提高读取性能,但是可能会降低写入性能。
- Read-Through(读穿透):这个策略类似于Cache-Aside,但是它会自动从缓存中读取数据,而不需要先从数据库中读取数据。如果缓存中没有数据,则自动从数据库中读取数据,并将读取到的数据存储到缓存中。这个策略可以提高读取性能,但是可能会增加数据库的负载。
- Write-Through(写贯穿):这个策略类似于Cache-Aside,但是在写入数据时,它会直接写入缓存和数据库,而不是先写入数据库再更新缓存。这个策略可以提高写入性能,但是可能会降低缓存的利用率。
- Write-Behind(写后置):这个策略类似于Write-Through,但是在写入数据时,它会异步地更新缓存和数据库,而不是立即更新。这个策略可以提高写入性能,但是可能会增加数据库的负载和缓存的不一致性。
- Update-In-Place(原地更新):这种策略在缓存中直接更新数据,而不是先删除旧数据再添加新数据。这样可以减少缓存的冲突,但是可能会增加缓存的大小和内存消耗。
- Write-Back(回写):这种策略在写入数据时,先更新缓存,然后再异步地更新数据库。这样可以提高写入性能,但是可能会增加缓存的不一致性和数据库的负载。
- Partitioning(分区):这种策略将缓存分成多个分区,不同的数据分区采用不同的缓存策略,以适应不同的访问模式和负载情况。
2.1 Cache-Aside(缓存旁路)
缓存旁路策略也是目前业务系统最常用的策略。在Cache-Aside机制中,系统将缓存视为一个辅助的存储介质,所有的读取缓存、读取数据库和更新缓存的操作都由应用服务来完成。
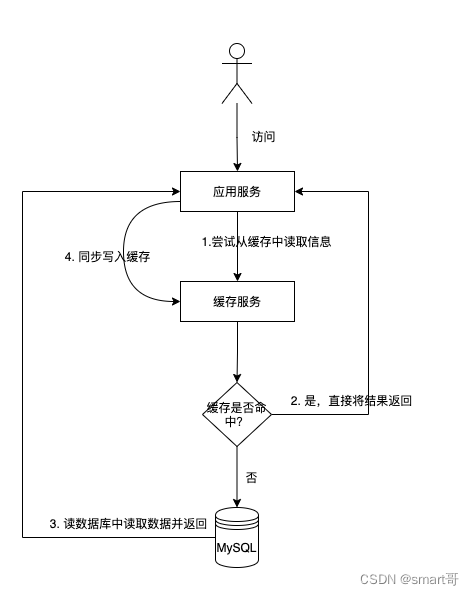
2.1.1 读取数据
读取缓存数据的步骤如下:
- 当需要访问某个数据时,系统首先尝试从缓存中获取该数据,检查缓存是否命中。
- 如果缓存中不存在该数据,则从数据库等数据源中获取数据,并将数据进行缓存更新。此时,缓存中就有了该数据的副本,下次需要访问该数据时就可以直接从缓存中获取,而无需再次查询数据库。
- 如果缓存中存在该数据,则代表缓存命中,直接返回。
程序实现如下(go 语言版本伪代码):
func main() {
// 尝试从缓存获取数据
cacheValue := getFromCache("testinfo")
if cacheValue != "" {
return cacheValue
} else {
// 如果缓存缺失,则从数据库获取数据
cacheValue = getDataFromDB()
// 将数据写入缓存
setInCache(cacheValue)
return cacheValue
}
}
2.1.2 更新数据
更新数据的步骤如下:
- 当进行数据更新时,先将数据更新到数据库中
- 还需要同时更新缓存或者将缓存进行失效(写时更新)
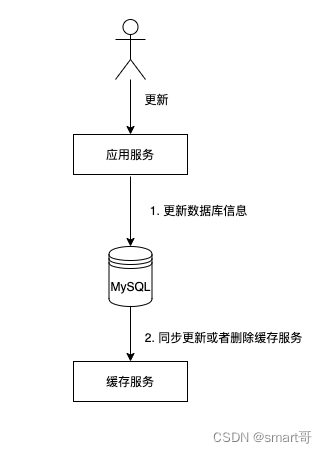
可以看到数据库更新之后,让缓存与数据库的同步的方式有两种,一种是同步去更新缓存的value,一种是直接删除数据库。
因为高频模式下,更新够频繁,更新线程的执行先后可能导致脏数据情况,所以比较常用的方式是删除缓存使缓存数据失效来实现同步。具体优势如下:
- 性能优势
如果缓存的更新成本很高,访问频率不高,建议直接删除缓存,而不是更新缓存数据来保证一致性。因为可能你的缓存更新之后长时间没有被使用,那还不如使用的时候创建。 - 安全优势
在高并发场景下,多线程可能会造成查询查到的数据是旧值。
程序实现如下(go 语言版本伪代码):
func main() {
_, err = db.Save(&user) // 保存更新后的数据到数据库
if err != nil {
log.Fatal(err)
} else {
// 更新成功之后,删除缓存
err = deleteCache(id)
}
}
整体优势:
Cache-Aside机制可以有效地提高系统的性能,因为缓存可以减少数据库等数据源的访问量,从而减少了系统的响应时间。同时,它还可以提高数据的可靠性和一致性,避免脏数据的出现。
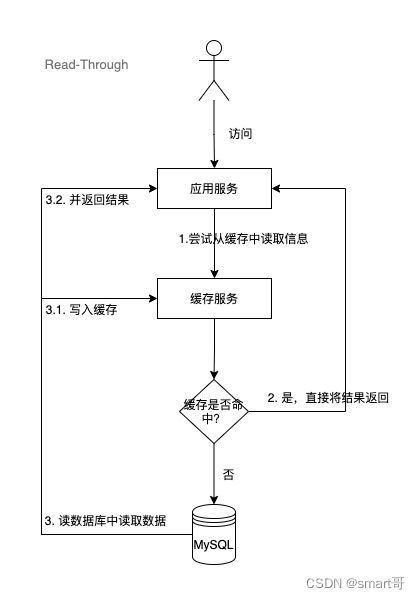
2.2 Read-Through(读穿透)
当缓存未命中,从数据库读取数据,同时写到缓存中并返回给应用服务。
这个策略类似于Cache-Aside,但是它会自动从缓存中读取数据,而不需要先从数据库中读取数据。如果缓存中没有数据,则自动从数据库中读取数据,并将读取到的数据存储到缓存中。
值得注意的是,Read-Through 不对数据库与缓存的同步关注,代码只与缓存交互,由缓存组件来管理自身与数据库之间的数据同步。所以说这个策略虽然可以提高读取性能,但是可能会增加数据库的负载。
2.3 Write-Through(写贯穿)
这个策略类似于Cache-Aside,但是在写入数据时,Write-Through 将写入责任转移到缓存系统,由缓存服务来执行更新,而不是先写入数据库再更新缓存。
将同步可能产生的故障处理和重试逻辑,交给缓存层来管理实现。
流程图如下:
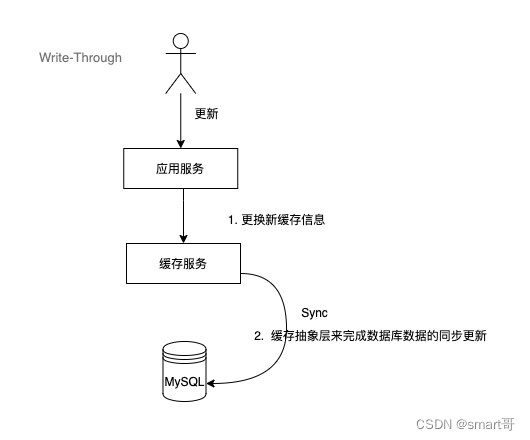
这个策略可以提高写入性能,但是可能会降低缓存的利用率。
可以看出与Cache-Aside最大不通就是对调了顺序,更新数据时,数据先写缓存,接着由缓存组件将数据同步到数据库。
2.4 Write-Behind(写后置)
这个策略类似于Write-Through,但是在写入数据时,它会异步地更新缓存和数据库,而不是立即更新。这个策略可以提高写入性能,但是可能会增加数据库的负载和缓存的不一致性。
流程如下:
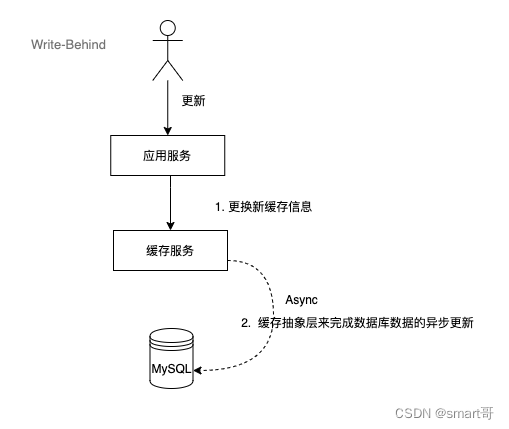
这种策略下,缓存与数据库存在一定程度的不一致性,对强要求一致的系统不建议使用。
3 Cache-Aside策略下的一致性
我们在业务场景中最经常使用的是 Cache-Aside 策略。在该策略下,先从缓存中读取数据,如果缓存中没有数据,则从数据库中读取数据,并将读取到的数据存储到缓存中。在写入数据时,先写入数据库,然后更新缓存中的数据。
可以看出,读操作不会导致缓存与数据库的不一致。而写操作则存在风险,数据库和缓存毕竟是两套系统,如果都需要进行修改,它们的先后顺序可能导致数据不一致。
上面其实我们有讨论过,更新的时候有两种办法,一种是将数据库的修改更新到缓存;一种是直接删除缓存,等有需要调用的时候再去更新缓存。
所以规避一致性风险的时候,我们需要考虑的有:
- 先更新缓存还是更新数据库?哪种顺序是最优选
- 数据库更新完我们是选择更新缓存(modify)还是删除缓存(drop)?
这两个需要考虑的问题,我们可以得到4种组合方案:
- 先更新缓存,再更新数据库。
- 先更新数据库,再更新缓存。
- 先删除缓存,再更新数据库。
- 先更新数据库,再删除缓存。
在对这四种的方案的分析过程中,我们考虑两个点:
- 操作原子性问题,其中一个操作失败会有什么问题。
- 数据一致性问题,高并发下会否有数据不一致情况。
3.1 先更新缓存,再更新数据库
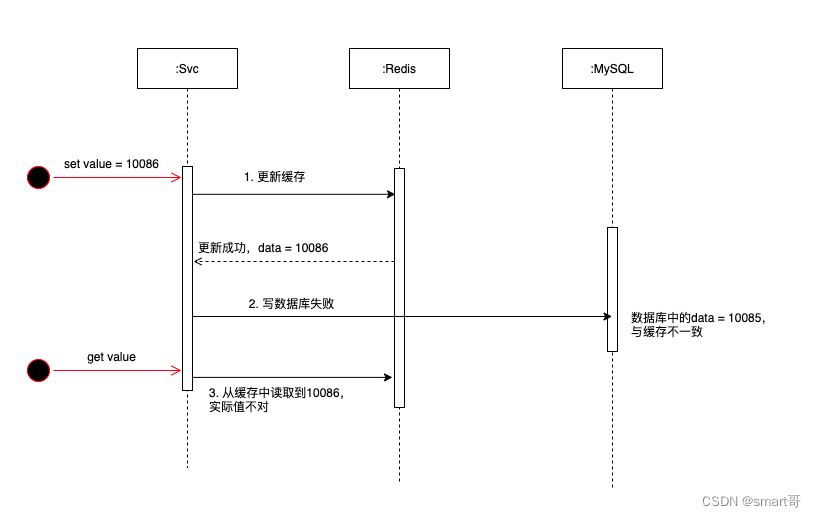
如图可以看出:如果缓存更新成功,数据库更新失败,就会导致数据库和缓存的数据不一致,那缓存就是脏数据了。
而查询的时候,会从缓存中查询到数据库不一致的数据,这样的数据是不正确的。
3.2 先更新数据库,再更新缓存
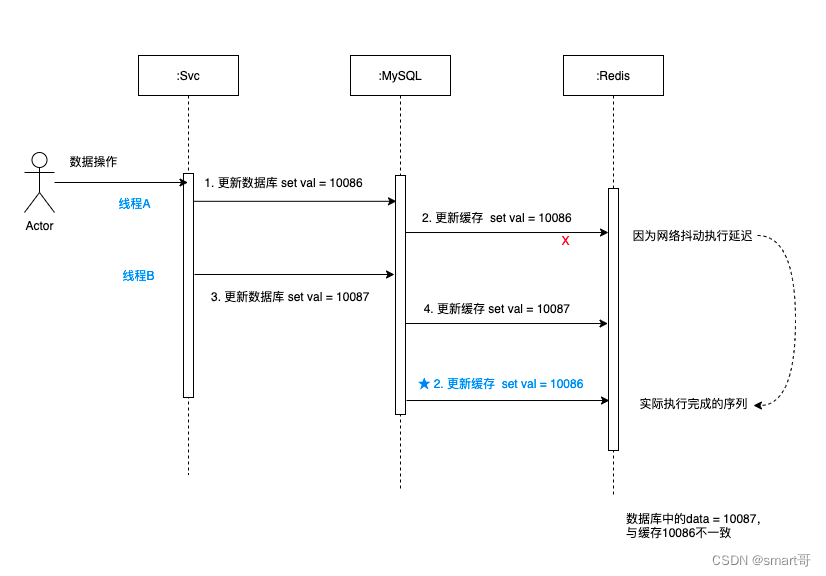
如图可以看出:
- 10086先发送,更新完成数据库之后,更新缓存遇到网络抖动,有延迟。
- 10087紧接着发送,更新完数据库之后,继续更新缓存,很快更新完成,10087 写到缓存中了。
- 这时候10086在缓存更新那边响应过来了,将10086写到缓存中了。
- 最后发现,数据库的值 = 10087,而缓存的值 = 10086,出现不一致的情况。
综上,高并发场景中,多线程同时写缓存写数据库时,很容易出现双值不一致的情况。
3.3 先删除缓存,再更新数据库
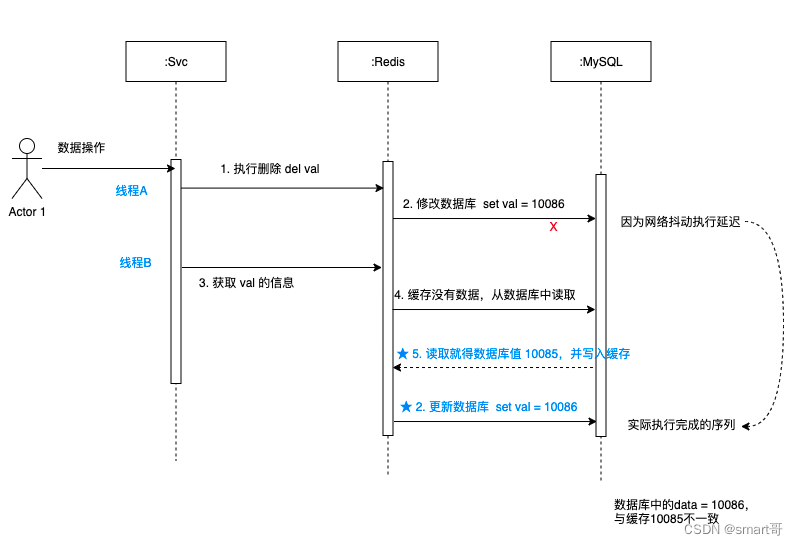
如图可以看出:
- 先删除缓存val,然后更新数据库,遇到网络抖动,有延迟。
- 紧接着获取 val的值,因为缓存是空的,所以从数据库中取出旧的值 10085,并更新到缓存中。
- 这时候更新数据库的操作响应过来了,把数据库修改成10086。
- 更新完数据库中的data = 10086,又与缓存10085不一致了。
综上,这种情况也有很大缺陷,不论是异常情况还是高并发场景,都可能导致数据不一致。
3.4 先更新数据库,再删缓存
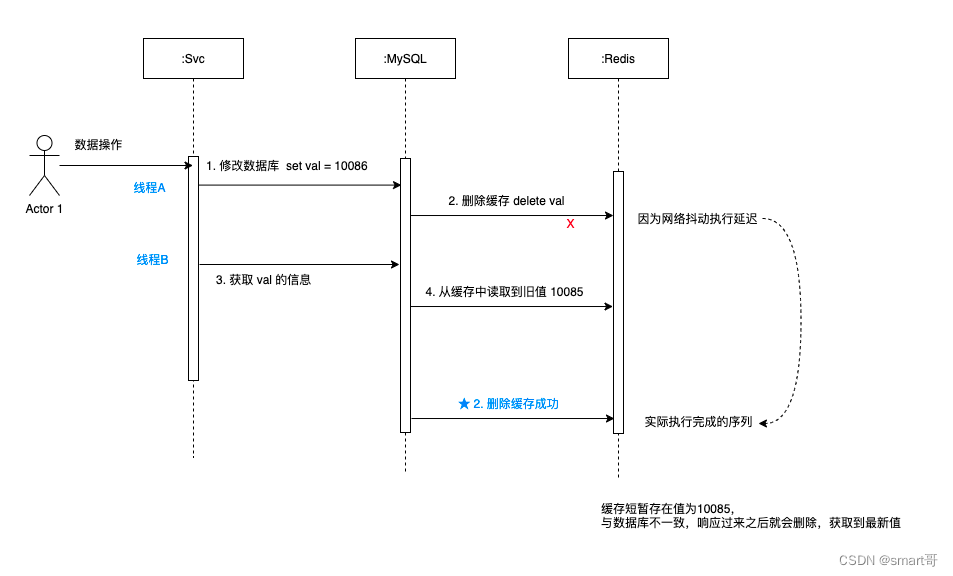
如图可以看出:
- 先修改数据库,数据库修改之后删除缓存,这时候遇到网络抖动,有延迟。
- 紧接着获取 val的值,因为缓存未被删除,所以从缓存中取出旧的值 10085。
- 这时候更新缓存的操作响应过来了,直接把 key = value 的缓存删除。
- 后续拿到的值都应该是最新的值,就不会有问题了,
可以看出,可能出现短暂的少量读取旧值的情况,但是很快缓存就会被删除,然后从数据库获取最新的值并更新到缓存。
之后的请求都能获取最新数据,这个方案比之前的三种都好很多。
4 一致性的解决方案
4.1 延迟双删策略
延迟双删策略主要是是应对先删除缓存,再更新数据库的场景。
我们知道在这种场景中,很容易因为删除数据库太慢导致重新获取的缓存依旧读是数据库旧值,读完旧值之后,数据库才更新完毕。这时候缓存的数据就跟数据库不一致了。参考 3.3 节。
所以这边多加了一个步骤,就是在数据库更新完成之后,再删除一次缓存。所以步骤如下:
- 删除缓存
- 缓存删除完成之后,更新数据库
- 数据库更新完成之后,休眠 n ms,二次删除缓存
这时候唯一存在的一个问题就是,在(更新据库 + 休眠 n ms) 这个时间窗口中,依旧能读取到旧值,而这个短暂时间控制的好的话,是可以接受的。
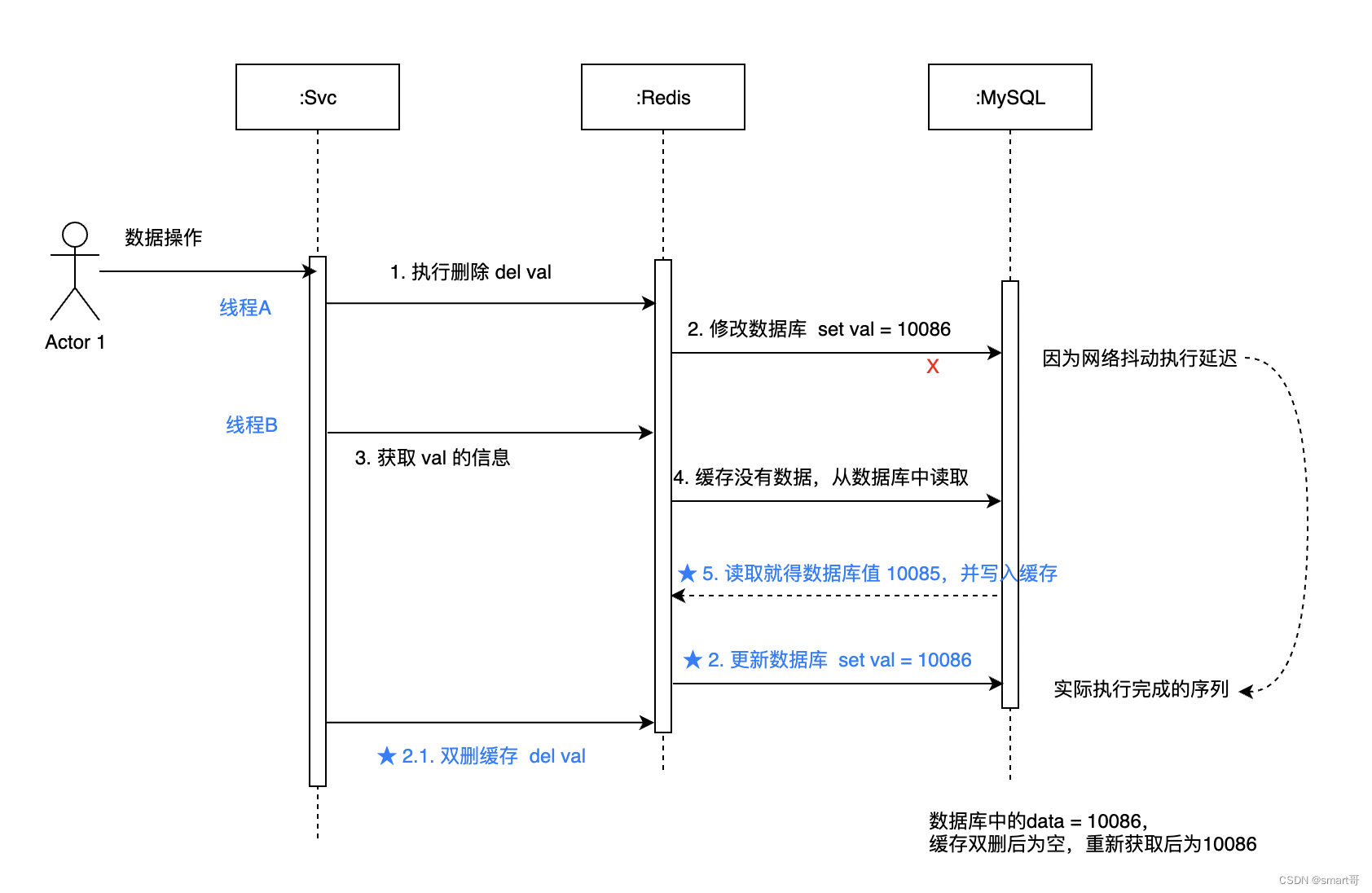
4.2 事务保证
无论是先更新数据库,再删除缓存;还是先删除缓存,在更新数据库。
保持事务性都是一种方案,如果删除缓存失败,则数据库更新会被回滚;如果更新数据库失败,则缓存也不会被删除。这个需要一致性策略接入。不过无论怎么做,这个都会在一定程度上影响执行完成的性能。
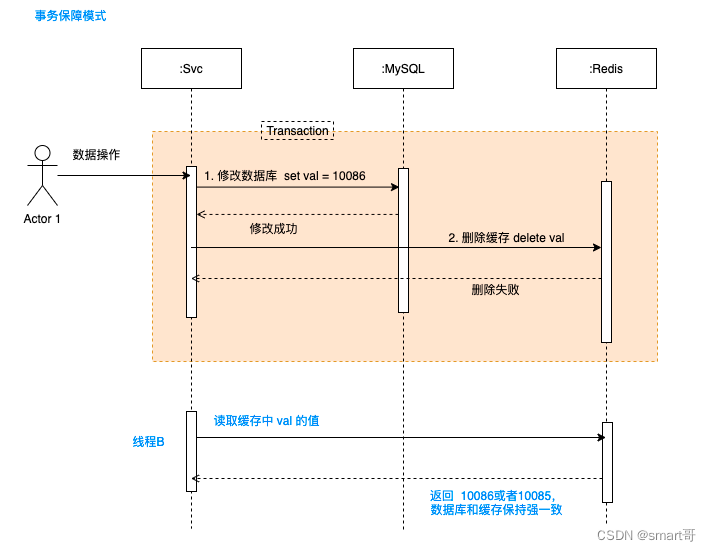
4.3 缓存删除重试保障机制
接着 4.1 的模式,如果双删还是失败呢,那可咋整,还是会产生缓存和数据库数据不一致的现象。
一般的做法是做一层兜底,比如记录日志,人工来处理;或者通过MQ来发布消息,然后开发一个独立的服务来订阅,专门用于数据清理,这就将操作异步化了。
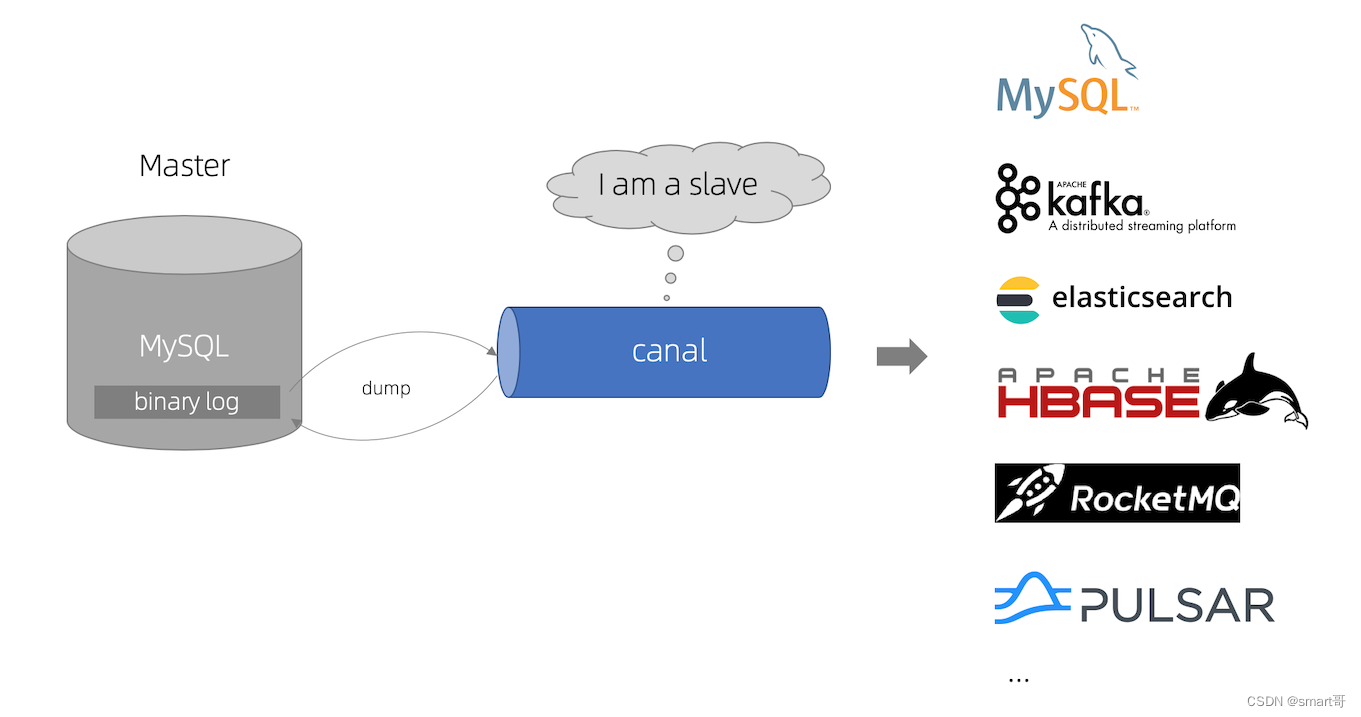
4.4 binlog独立删除能力
我们知道,数据库有类似Binlog之类的东西,记录每次数据的更新。所以我们有另外一种方案,就是把同步缓存的操作交给独立的能力中,从应用层解耦。
图中我们可以看到步骤如下:
-
更新数据库数据
-
数据库更新完成之后会把变更记录在 binlog 中
-
使用 canal 订阅 binlog 日志获取待删除的key(或者更完整的数据对象)
-
消费者(缓存删除服务)获取到 canal 数据,获得待删除的key,并删除缓存
5 总结
- 缓存策略的最常用模式是 Cache Aside Pattern。
- 读缓存最优策略:读取缓存,命中则返回结果;未命中则查询数据库,写缓存,再返回。
- 写缓存最优策略是:先写数据库,再直接删除缓存
- 在实践中,建议使用延迟双删和删除重试兜底的模式为数据一致性做保障。















 1844
1844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









