








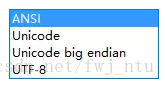
本人使用的是Jupyter notebook 编辑器做数据分析的,API 是pyspark,有时候需要把 pyspark DataFrame 转成 pandas Dataframe,然后转成CSV 文件去汇报工作,发现有中文导出的时候是乱码,问了运维的同事的他们已经设置成了UTF-8 的模式,我在代码里也设置了UTF-8 .后来发现是CSV的问题,先将CSV用txt记事本打开,然后选择ANSI编码方式。另存为,点编码这里,这里的编码有这么几种选择,最后用excel去打开就可以了。

pyspark 导出代码:
aa1 = aa.toPandas()
aa1.to_csv('output_file.csv')















 1895
1895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









