






属于QAT (Quantization-Aware Training)的一种,训练阶段用量化。
特点是:
1. 从16-bit INT开始训练,逐渐减1bit,训练一些steps就减1bit,直至减至8bit INT;
2. (可选,不一定非用)多久减1bit,这个策略,使用模型参数的二阶特征来决定,每层独立的(同一时刻,每层的特征值们大小不一致,也就造成bit减少速度不一致,造成bit数目不同);
参数:
quantizer_kernel:是否使用quantization kernel,默认不使用。我的理解是,量化版kernel目前还不是很ready。但是,如果不使用,那就要把模型参数再重新反量化为FP32/FP16,再计算?
quantize_type:对称量化,量化结果为signed int(-128~127),就是float的0对应量化后int的0;非对称量化,量化结果为unsigned int(0~255),就是float的0对应INT中的某个值(不一定是127、128);
quantize_period: 首次训练这么多step,就减少1个bit;下次训练2*这么多step,减少1个bit;再下次训练4*这么多step,减少1个bit; 。。。注意:自己算好,训练结束时,得下降到8bit;
schedule_offset: 刚开始训练的这些steps,不进行量化;为了保持开头训练的效果稳定性;
quantize_groups:所有参数分成这么多组,每组根据组内统计,使用自己的量化scale;
例子:
{
......
"quantize_training": {
"enabled": true,
"quantize_verbose": true,
"quantizer_kernel": true,
"quantize_type": "symmetric",
"quantize_bits": {
"start_bits": 12,
"target_bits": 8
},
"quantize_schedule": {
"quantize_period": 10,
"schedule_offset": 0
},
"quantize_groups": 8,
"fp16_mixed_quantize": {
"enabled": false,
"quantize_change_ratio": 0.001
},
"eigenvalue": {
"enabled": true,
"verbose": true,
"max_iter": 50,
"tol": 1e-2,
"stability": 0,
"gas_boundary_resolution": 1,
"layer_name": "bert.encoder.layer",
"layer_num": 12
}
}
}
效果:
都用对称量化,quantize_groups设为8;
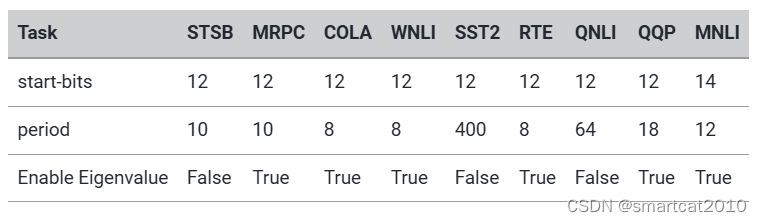
结果:
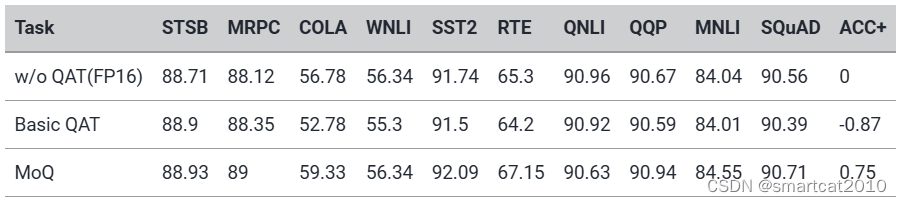
结论:经典QAT会造成acc下降;MoQ不降反升;
疑似早期版本的文档:
(动机:观察到,大模型推理期间,batch较小时,模型参数加载,非常耗费时间)
(weights量化为INT8,计算时再转为FP16,和压根没有量化的FP16的activation,使用FP16的kernel,进行计算)
To further reduce the inference cost for large-scale models, we created the DeepSpeed Quantization Toolkit(opens in new tab), which involves two parts:
Mixture of Quantization (MoQ) is a novel quantize-aware training method designed under the observation that inference time for large Transformer-based models with small batch sizes is primarily dominated by the parameter loading time from main memory. It is therefore sufficient to quantize just the parameters to achieve inference performance improvements, while the activation can be computed and stored in FP16. With this insight, MoQ uses the existing FP16 mixed-precision training pipeline in DeepSpeed to support seamless quantization of parameters during training. It does so by simply converting the FP32 parameter value to lower precision (INT4, INT8, and so on). It then stores them as FP16 parameters (FP16 datatype but with values mapping to lower precision) during the weight update.
This approach has three advantages: 1) it does not require any code change from users, 2) it does not require using actual low-precision datatypes or specialized kernels during training, and 3) it allows us to dynamically adjust the number of quantization bits as the training progresses, offering the ability to use flexible quantization schedules and policies. For example, MoQ can leverage second-order information during training, like those shown in Q-BERT(opens in new tab), to adaptively adjust the quantization schedule and target bits for each model layer.
With unquantized activations, flexible quantization schedule, and adaptive targets using second-order information, MoQ is much more robust in terms of accuracy when compared to conventional quantization approaches for the same compression ratio.
High-performance INT8 inference kernels are extensions of generic and specialized Transformer kernels discussed earlier, designed to work together with INT8 parameters trained using MoQ. These kernels offer the same set of optimizations as the FP16 versions, but instead of loading FP16 parameters from main memory, they load INT8 parameters. Once the parameters are loaded to registers or shared memory, they are converted on-the-fly to FP16 before they are used in inference computation. Loading INT8 instead of FP16 reduces the data movement from main memory by half, resulting in up to 2x improvement in inference performance.
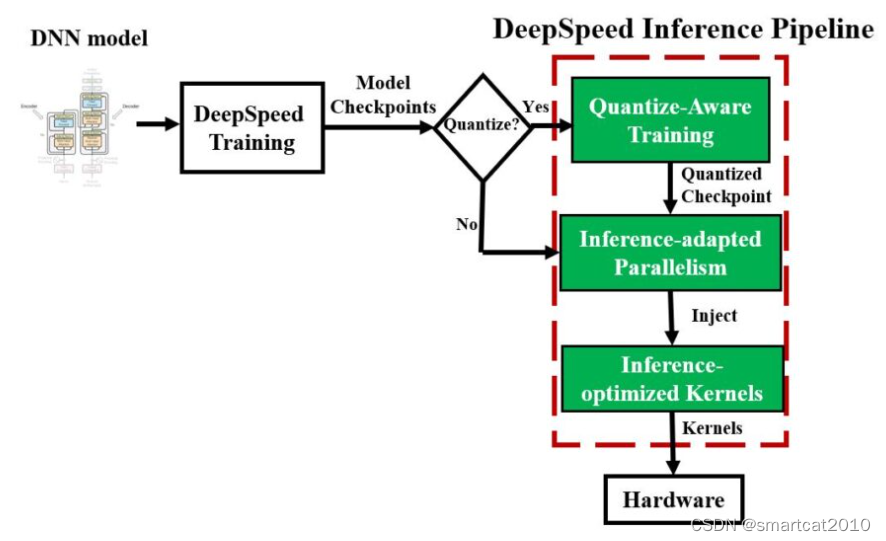
DeepSpeed | Knowledge Center (emotibot.com)
早期的 DeepSpeed 为进一步降低大模型的推理成本,开发了 DeepSpeed Quantization Toolkit,主要包括两个部分:
- 量化混合 DeepSpeed Mixture-of-Quantization (MoQ) :是一种新的量化感知训练(QAT)方法,它的设计主要基于以下观察:小批量的大模型推理时间主要由主内存的参数加载时间决定。因此,仅量化参数就足以实现推理性能改进?而激活可以计算并存储在 FP16 中。基于这个理念,MoQ 利用 DeepSpeed 中现有的 FP16 混合精度训练管道(training pipeline)来支持训练期间参数的无缝量化。它简单地将 FP32 参数值转换为较低精度(
INT4、INT8等),然后在权重更新期间将它们存储为FP16参数(FP16数据类型,但值映射到较低精度)。这种方法具有三个优点:1)它不需要用户更改任何代码;2)不需要在训练期间使用实际的低精度数据类型或专用内核;3)它允许在训练过程中动态调整量化位数,提供了灵活的量化时间表和策略。例如,MoQ 可以利用训练过程中的二阶信息(如 Q-BERT 中所示),自适应地调整量化时间表和每个模型层的目标位数。
通过使用未量化的激活值、灵活的量化时间表和使用二阶信息的自适应目标,与相同压缩比的传统量化方法相比,MoQ 在准确性方面更加稳健。
- 高性能 INT8 推理内核:是前面讨论过的通用和专用 Transformer 内核的扩展版本,用于与使用 MoQ 训练的 INT8 参数模型配合使用。这些内核提供了与 FP16 版本相同的一系列优化,但加载的不是来自主存的 FP16 参数,而是 INT8 参数。一旦参数加载到寄存器或共享内存中,它们会在被用于推理计算之前即时转换为 FP16。加载 INT8 而不是 FP16 可以将数据从主存的传输量减少一半,从而提高推理性能高达 2 倍。















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









