






原文:
Deploying Large Language Models can yield significant accuracy improvements for specific business applications. Yet, the training process presents big challenges. It requires a lot of GPU resources.
In this article, I will focus only on one aspect of training LLMs — GPU memory requirements.
In particular, I will explain:
- How much GPU memory do you need to train X billion Transformer based LLM per each GPU device.
- What is the formula to estimate memory requirements.
- What would you do in practise to reduce the memory needs if the model does not fit.
What Consumed All the Memory?
This was the first question I asked myself immediately I saw the the error when launched training for one of my first multibillion LLM:
RuntimeError: CUDA out of memory
I bet every ML Engineer saw this error thousands times. In the early era of Deep Learning models (e.g VGG or ResNets) the common solution was to reduce the batch_size and use gradient_accumulation_steps.
Unfortunately, nowadays, when we’re working with LLMs finding the root cause of the error is no longer straightforward.
Imagine, you have a 10B parameters (or weights) model. It requires 20GB of in 16-bit precision. This fits pretty well to any popular GPU for model trainings: V100 (which has 32 GB of GPU memory) or A100 (which has 40 GB of GPU memory). Yet, such model cannot be trained on a single GPU with memory using Tensorflow or PyTorch. You might be surprised, but you won’t be able to train a 1.5B GPT model with 32GB of GPU memory. One may wonder where all the memory goes?
During model training, most of the memory is consumed by two things:
- Model states. Which includes tensors comprising of optimizer states, gradients, and parameters.
- Activations. Which includes any tensor that is created in the forward pass and is necessary for gradient computation during backward pass.
In the sections below I will explain how much memory each component requires and write down approximate formulas that can be used in practise.
Model States: Optimizer States, Gradients and Parameters
Exploring memory consumption for model states is the crucial topic in the amazing paper by Microsoft ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. Authors explore the memory requirements for model training using the most popular Adam optimizer. In practise this means, that at any time during training, for each model parameter we always need to have enough GPU memory to store:
pamount of bytes for copy of the model parameterpamount of bytes for copy of the gradients- 12 bytes for optimizer states: copy of the parameter, momentum and variance (we keep all optimizer states in FP32 to preserve stable training and avoid numerical explosion)
To sum up, that means, that while training we need this amount of memory to store all model states:
![]()
where p is precision in bytes for a parameter, typically 2 or 4, model_size is the size of the model in billions
If we have a 10B parameter model and we train in mixed-precision (in this case p will be 2), we will need to store 160 GB of GPU memory.
Whoa! It’s bigger then the A100 GPU capacity. Imagine you were interested in training this in full FP32 mode (p will be 4 in this case) — insane!
Luckily, we have a great engineering solution to shrink this number, Model State Partitioning, which allows to distribute the model states across many GPUs. For ML engineers this is better known as Zero Redundancy Optimizer (ZeRO)in DeepSpeed library or FSDP in torch 2.x. I’ll use ZeRO everywhere later in text as it’s was the first successful example of a framework for model states sharding.
ZeRO reduces the memory consumption of each GPU by partitioning the various model training states across the available devices (GPUs and CPUs) in the distributed training hardware. Concretely, ZeRO is being implemented as incremental stages of optimizations, where optimizations in earlier stages are available in the later stages. To deep dive into ZeRO, please see their paper.
The library supports 3 stages
Stage 1: The optimizer states are partitioned across the processes, so that each process updates only its partition.
So the memory requirement for model states will become:
![]()
Stage 2: Gradients for updating the model weights are also partitioned such that each process retains only the gradients corresponding to its portion of the optimizer states.
So the memory requirement for model states will become:
![]()
Stage 3: The model parameters are partitioned across the processes. ZeRO-3 will automatically collect and partition them during the forward and backward passes.
So the memory requirement for model states will become:
![]()
Great, we will use this later in the final formula to udnerstand how much memory is required per each GPU device.
Activations
In the previous section we estimated the amount of GPU memory that is required just to store the model and it’s states for training. But we also need to store all intermediate outputs of each model’s layer in order to update model weights during backpropagation step. At first glance, it looks negligible. But hold on…
In a great paper Reducing Activation Recomputation in Large Transformer Models researchers from Nvidia derive an approximate formula for the memory required to store activations in the forward pass of a single stack transformer model. I will use the same notation as the authors of the paper and explain how they derived it.
First of all, let’s look at how the traditional Transformer block looks like:
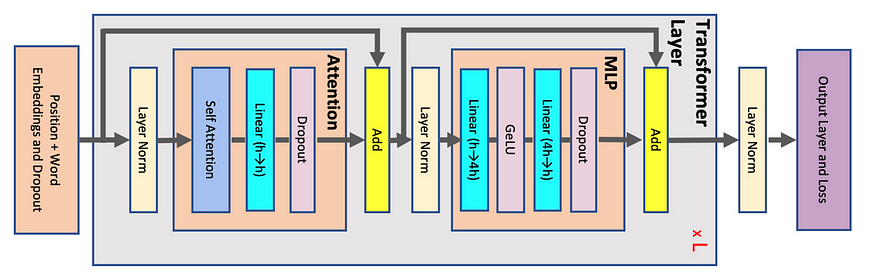
Image from the paper Reducing Activation Recomputation in Large Transformer Models. The image represents Transformer Architecture. Each gray block represents a single transformer layer that is replicated L times
Now, let’s introduce some notations:

Having this in mind, let’s break down how much memory each component is required.
Here and below psbh is referring to p * s * b * h,
Let’s start with the MLP part:
- We need to store the output of the first Linear layer, this will require
4 psbh(input to this layer will requirepsbhbytes , and the Linear layer make the output wider by 4x times) bytes - We need to store the output from the GeLU layer, which will require
4 psbhbytes - We need to store output from the second Linear layer, this will require
psbhbytes. - We need to store dropout mask, this will require
sbhbytes (we will need the dropout mask in the backward pass. Here we do not introduce precision factor p as mask is binary)
So in total, MLP part will require to store: 9psbh + sbh bytes for activations.
Let’s break down the Attention part.
Here we will need to store:
- Intermediate outputs from Self-Attention (this will be covered separately)
- Output from Self-Attention, which will require
psbhbytes - Output from the Linear layer, which will require
psbhbytes - Dropout mask (we will need the dropout mask in the backward pass. Here we do not introduce precision factor p as mask is binary), this will require
sbhbytes
Now, let’s analyze the last block — Self-Attention.
Self-attention formula is following:
![]()
So we need to store:
psbhbytes for output from XQpsbhbytes for output from XKpsbhbytes for output from XV
We also need to store the output from the softmax operation. We know that in standard self-attention the result of multiplication (XQ) *(XK)^T is just a b x s x s matrix which contains logits. However in practise we use multi-head self-attention, so we store a separate s x s for each of a heads. This means that there will be pas²b bytes required to store those logits. Next, we need to store the softmax output, which will again require pas²b bytes. Finally, there is usually a dropout applied after softmax, so it will require additional as²b bytes to store the dropout mask.
To sum up, we need 5psbh + sbh + 2pas²b + as²b bytes for Attention part.
Additionally, there are 2 Norm Layers in the Transformer Layer, the output from each such layer will require to store psbh bytes, so in total 2psbh bytes.
We’re ready for the final formula for acitvations. We just need to sum everything that was mentioned above. After some simplifications total amount of bytes required to store the activations will be approximately:
![]()
Total amount of bytes required to store the activations for Transformer based model
Let’s write a quick python function to automate the calculations depending on the architecture:
def activations_memory(num_layers, seq_len, batch_size, hidden_dim, num_heads, precision=2):
"Returns amount of GPU VRAM (in GB) required to store intermediate activations for traditional Transformer Encoder block"
mem_bytes = num_layers * precision * seq_len * batch_size * hidden_dim * (
16 + 2/precision + 2*num_heads*seq_len/hidden_dim + num_heads*seq_len/(precision*hidden_dim))
return round(mem_bytes / 10**9, 2)
This function will compute how much GPU memory is required to store the activations for a defined transformer architecture in GB.
Usually, when we’re dealing with some well-know model and want to train / fine-tune it on our custom data, we don’t really change the architecture, so the key parameter which we can vary for training is batch size
Let’s see what happens with the activations memory for the 10B model, XLM-RoBERTa-XL, if we were to train it with one GPU and different batch sizes:
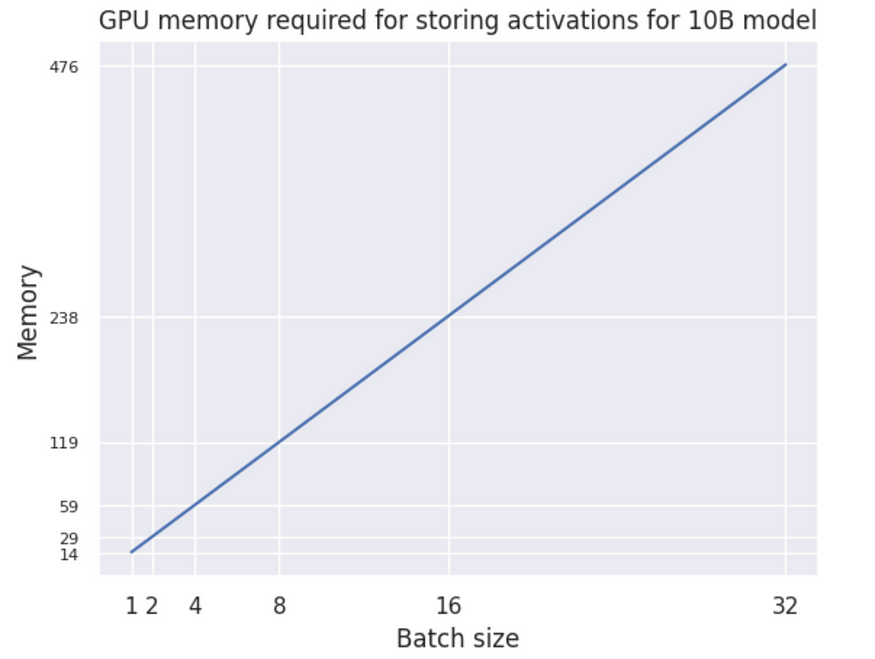
GPU memory required for storing activations for 10B model in GB
Well… relationship is linear but the memory growing insanely fast! So how do we deal with this?
Fortunately, we can use activation checkpointing technique. This allows to avoid saving intermediate tensors necessary for backward computation if we just recompute them on demand instead. The authors of the paper Training Deep Nets with Sublinear Memory Cost showed, we can reduce memory by approximately the square root of the total activations at the expense of 33% re-computation overhead.
Using activation checkpointing, we can say that the required GPU memory for activations will be roughly in bytes:
![]()
Understanding and Estimating GPU Memory Demands for Training LLMs in practise
In the above sections we derived few formulas to understand what happens with the GPU memory when we’re trying to train a large LLM.
Here I will give a high level list of actions that ML Engineer should do while trying to understand what are the hardware requirements when training yet another LLM oh his own.
- Understand what type of GPU accelerators are available and, more specifically, how many.
- Get the size of the model and compute how much GPU memory is required for storing model states. At this point one may already start looking into ZeRO stages.
- Get the detailed model specifications (e.g configs) and analyze it. This will help to build an intuition about the memory requirements for the activations. At this point one may already build an intuition about batch size, whether to use activation checkpointing or not.
- As the result come up with some number that will make sense and make a toy training to verify that it matches the estimations.
The code snippet below will be useful in making some high level maths:
def activations_memory(num_layers, seq_len, batch_size, hidden_dim, num_heads, precision=2):
"Returns amount of GPU VRAM (in GB) required to store intermediate activations for traditional Transformer Encoder block"
mem_bytes = num_layers * precision * seq_len * batch_size * hidden_dim * (
16 + 2/precision + 2*num_heads*seq_len/hidden_dim + num_heads*seq_len/(precision*hidden_dim))
return round(mem_bytes / 10**9, 2)
def gpu_memory_required(model_size, num_gpus, num_layers, seq_len, batch_size, hidden_dim, num_heads, precision=2, activations_checkpoint=False, stage=0):
model_in_memory = (precision + precision + 12) * model_size
print(f'In default mode model states would have taken: {model_in_memory} GB')
if stage == 0:
model_in_memory = (precision + precision + 12) * model_size
elif stage == 1:
model_in_memory = precision * model_size + precision * model_size + (12 * model_size) / num_gpus
elif stage == 2:
model_in_memory = precision * model_size + (precision +12) * model_size / num_gpus
elif stage == 3:
model_in_memory = (precision + precision + 12) * model_size / num_gpus
else:
raise ValueError
print(f'Stage {stage} selected, model states would require {model_in_memory} GB')
activations = activations_memory(num_layers, seq_len, batch_size, hidden_dim, num_heads, precision)
print(f'Model activations would require {activations} GB without activations checkpointing')
if activations_checkpoint:
activations = activations ** 0.5
print(f'Activations checkpointing is enabled, activations would require {activations} GB')
return activations + model_in_memory
Let’s assume I want to train the XLM-RoBERTa-XL model. This is a 10B model. Model configs with the hidden dimensions, number of heads can be found here.
Next, I need to understand the memory requirements. To simplify things I will fix batch size as 8 and use 64 GPUs.
Having this all in mind I can run the code snippet above in different setups and come up with the table like:
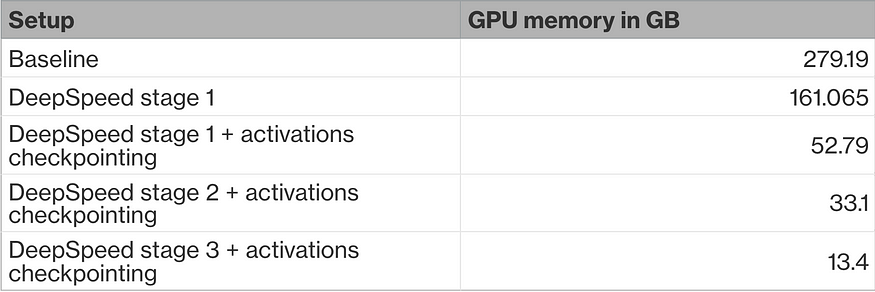
From this table I can understand, that just sharding the model states (using DeepSpeed stage 1) is not enough, I need to use activation checkpointing as well. But even this is not enough, I need either to reduce the batch size (and use gradient accumulation) or go to DeepSpeed stage 2. At this point it becomes feasible with A100 GPU (you still need to go further and play with the training hyperparameters if you’re on the smaller GPU) and I can train the large LLM almost with the efficiency of standard DDP. Going to DeepSpeed stage 3 is the last call, this will dramatically reduce the memory footprint with a huge impact on the training speed. Alternatively, one can go further and use quantization techniques to train even with lower precision, this will free extra memory or, trying CPU offloading. But these things are out of the scope for this post.
Thanks for reading!
References
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models by Samyam Rajbhandari , Jeff Rasley , Olatunji Ruwase, Yuxiong He
- Reducing Activation Recomputation in Large Transformer Models by Vijay Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro
LLama2-70B:
L (num_layers): 80
s (seq_length): 4096
b (8*8张卡): 64
h (hidden_size): 8192
a (num_attention_heads): 64
p (BF16 precision): 2
Model size: 70BWeights: (Zero2-offload)
2*70Billion + 2*70Billion/8卡 = 157.5GB假如不用Group Attention, Activation:
80*2*4096*64*8192*(16 + 2/2 + 2*64*4096/8192 + 64*4096/2/8192) = 33TB()里面等于97,每层是416GB;
"num_kv_attention_heads": 8
"train_micro_batch_size_per_gpu": 8,















 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









