







Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
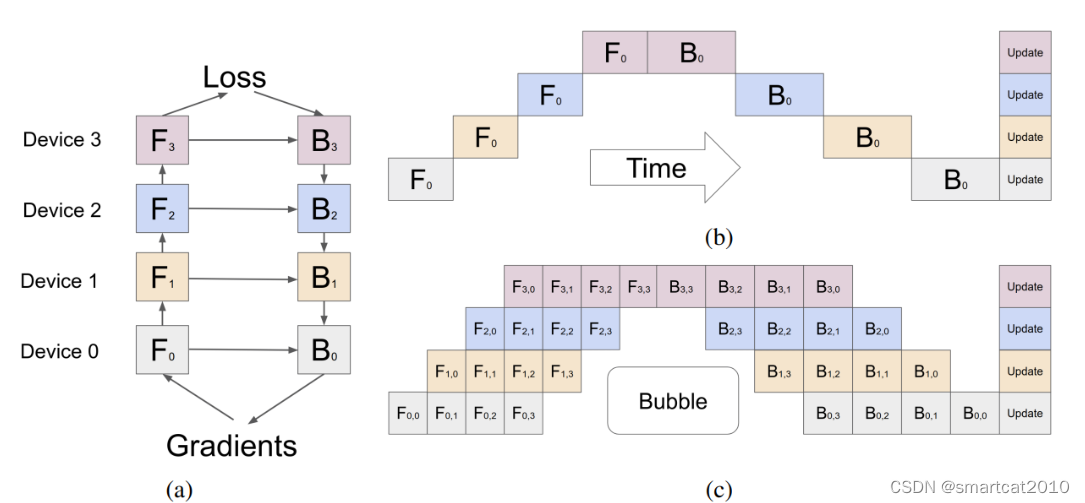
Pipeline并行:
缓解"气泡"(Bubble)的办法:把大batch拆成多个小batch;
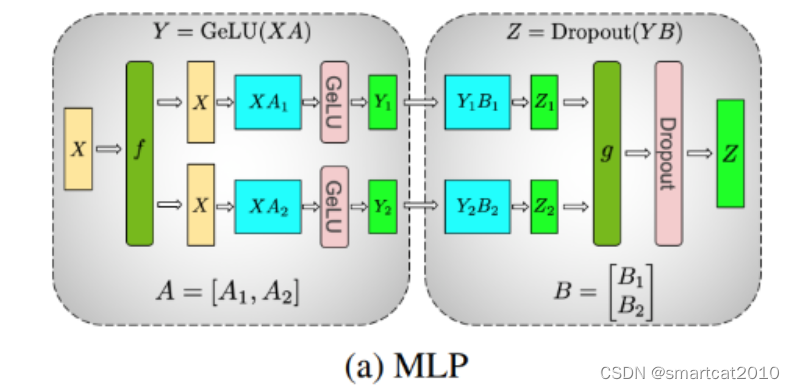
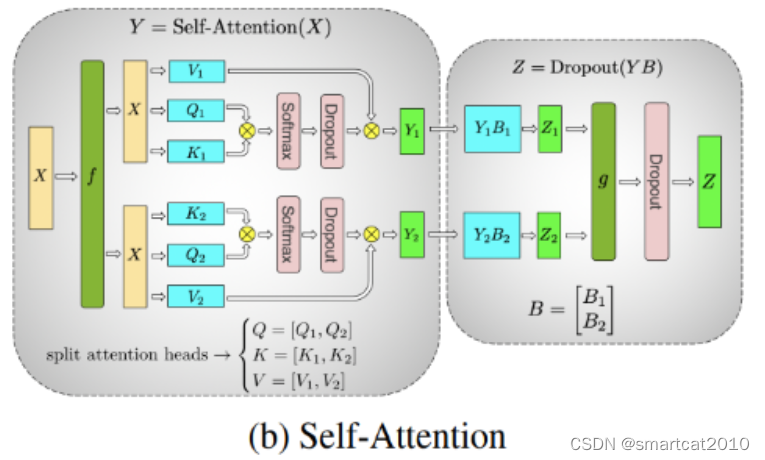
Megatron的Tensor并行:
1. MLP: 连续乘以2个矩阵;第一个W矩阵,竖着切分为左右2个;第二个W矩阵,横着切分为上下2个;g表示2个结果矩阵加和到一起;这样可以避免中间结果Y的AllGather通信;
2. Self-Attention: 一张卡负责前一半heads的Q、K、V(KV cache也是放前一半heads的);后一张卡负责后一半heads的Q、K、V(KV cache也是放后一半heads的);转换矩阵B横着切分为上下2个,各自乘完之后,2个结果矩阵相加;可以避免中间结果Y的AllGather;
3. 最后一层FN的W矩阵(也就是复用的Embedding组成的矩阵,几千行几万列,因为vocabulary size是几万)很大;把W按列切分到多个GPU,模型并行来计算;跑完的结果,不需要all-gather,只需要每张卡element-wise得计算e^x,然后加和自己那部分的e^x,然后all-reduce所有GPU上的加和值做分母,再将本卡上的那部分e^x除以该分母得到概率p;
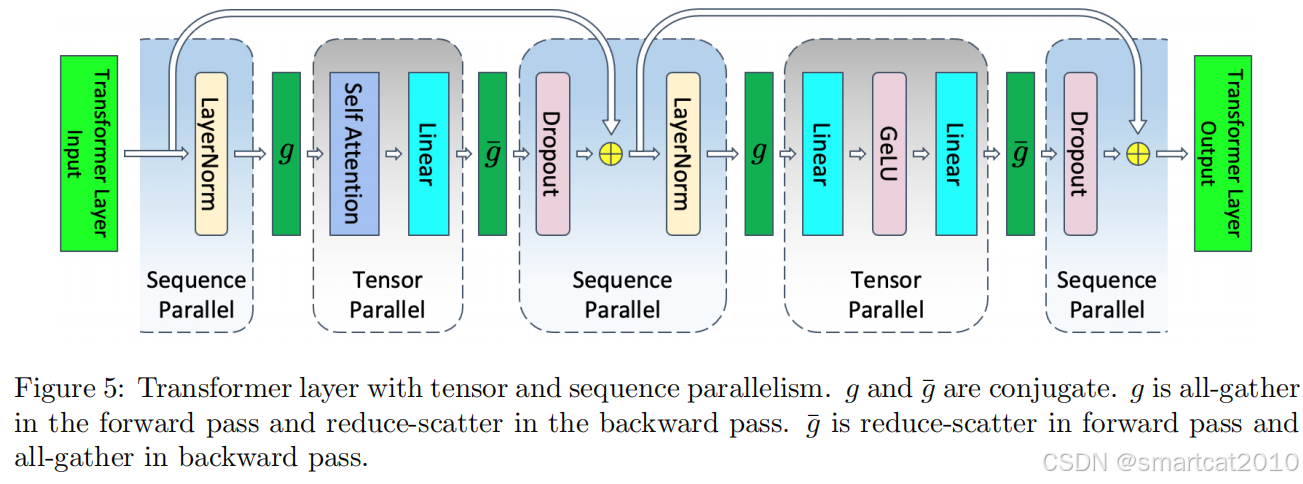
Sequence并行
和Megatron Tensor并行,一起用;
把LayerNorm、Dropout,进行多卡并行,每张卡处理一部分token的完整激活;
用AllGather和Reduce-Scatter,代替之前的AllReduce,总通信量没有增加;
如上,Linear完后,所有卡上的矩阵,要进行加和到一起;但现在改成Reduce-Scatter,每张卡加和自己那部分token的子矩阵,也就是大矩阵横着切;加完后,每张卡计算Dropout和LayerNorm都只在自己那部分token的子矩阵上计算;输入到后面的Linear层之前,所有GPU卡上的加和后的子矩阵,进行AllGather;
上面,forward阶段,从左往右,依次是
g: AllGatherg~: Reduce-Scatter
g: AllGather
g~: Reduce-Scatter
注意:同一位置的通信操作,在forward和backward时,是不一样的通信pattern;
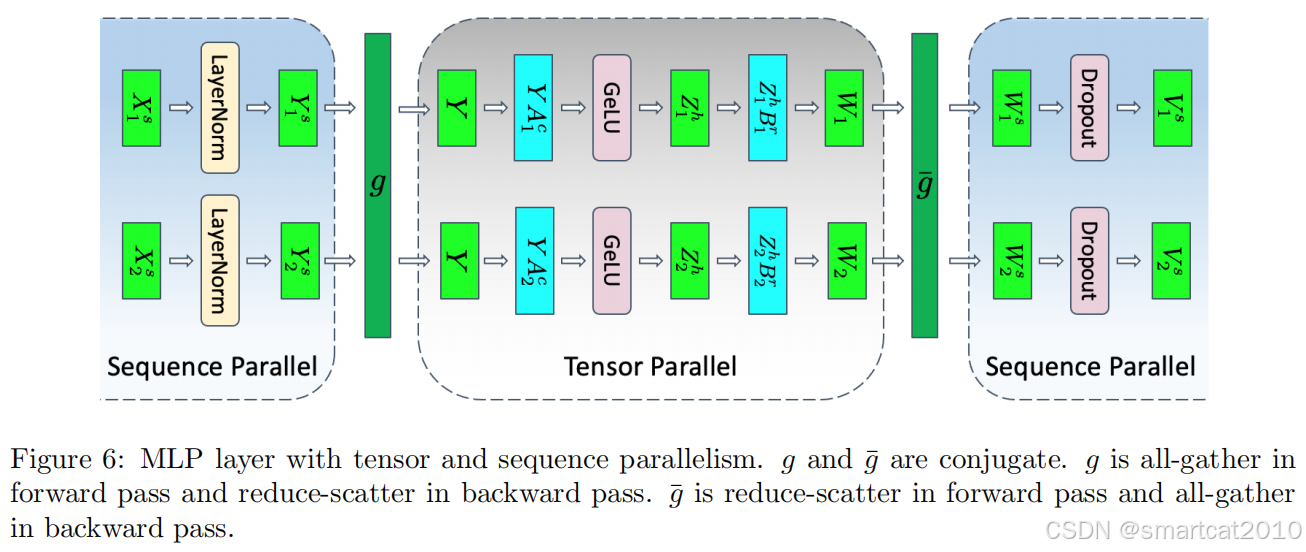
Tensor并行+Sequence并行,好处:
1. TP将模型参数分担至多张卡,减少了单张卡的显存占用量;
2. TP和SP减少了单张卡的计算量,并行计算,加速了;
3. TP和SP减少了单张卡的激活数据量,训练时消耗的activation缓存减少,减少了显存占用量;
结合activation checkpointing来使用,不保存那些存储量大但计算量小的激活,这部分在backward时重新计算之。
DeepSpeed Ulysses
在Sequence并行的基础上,不做Tensor并行;
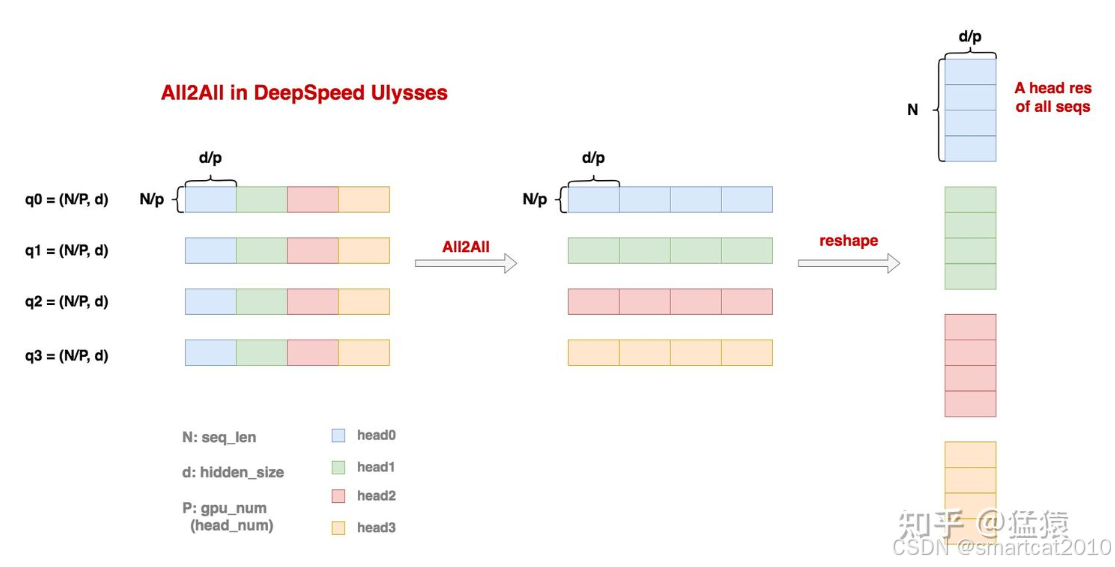
token激活和Q、K、V转换矩阵乘完之后,每张卡拥有自己这部分token的所有heads的q、k、v;
将这些q、k、v按照heads划分,AllToAll通信,每张卡得到所有token的一部分heads的q、k、v;
每张卡独立计算自己这部分heads的:q*k,softmax,再乘以v;每张卡得到所有token的一部分heads的结果;
再次AllToAll通信,每张卡得到自己这部分token的所有heads的结果;和转换矩阵做乘法;
MLP的两个矩阵乘法,每张卡计算自己这部分token的就行,和完整的权重矩阵相乘。
优点:通信量降低为SP+TP的1/p,p为GPU卡数目。
缺点:没有使用Tensor并行对模型的partition;模型参数过大一张卡装不下的情况无法应对;
AllToAll通信示意图:
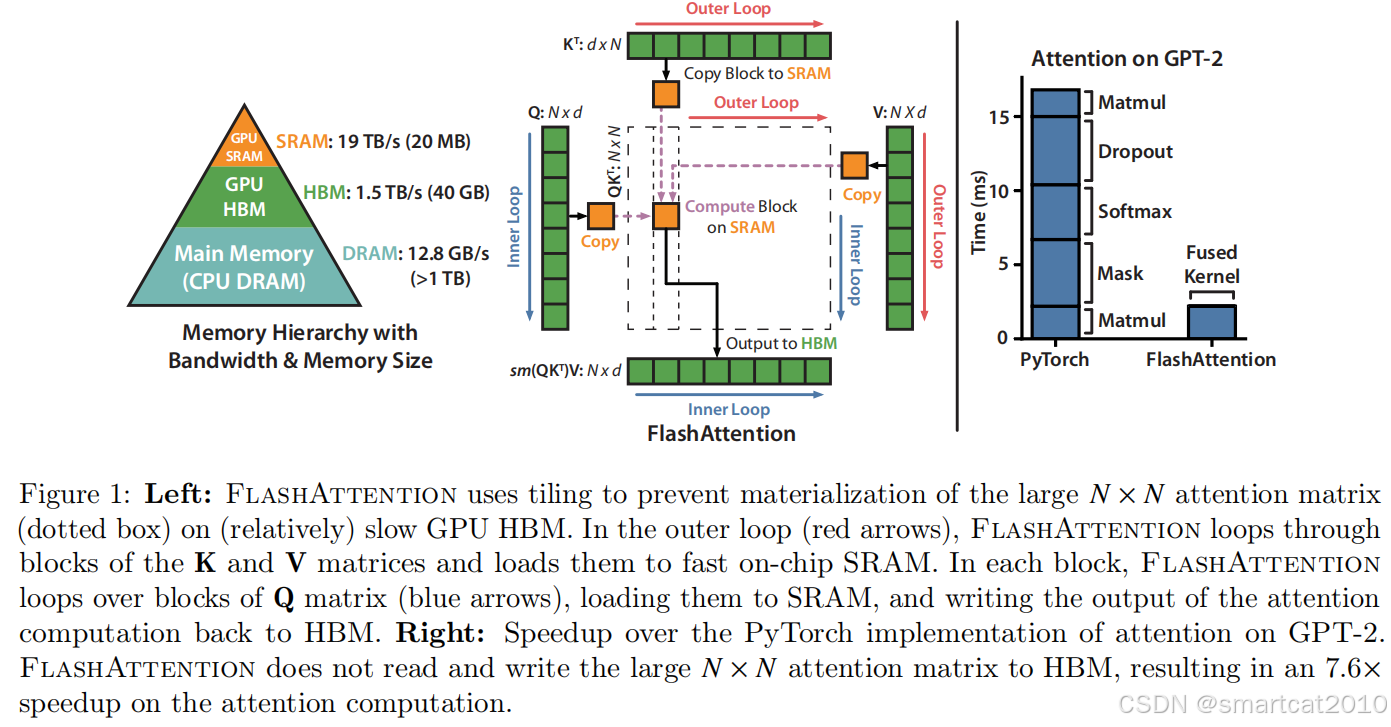
原始Attention计算的示意图:
FlashAttention:
1. 为了中间结果(特别是序列长度N^2的S矩阵)不落盘,使用Fused kernel;
2. S矩阵太大,无法放入SharedMemory;所以使用分块矩阵乘法;
读写显存:
设M为shared-memory大小,N为sequence length,d为单个head的hidden size;
老方法:O(N*N);
FlashAttention: 外层循环一共做N*d/M次(K、V每个的总size为N*d,shared-memory大小为M);每次总共读Q的size为N*d;所以是O(N*N*d*d/M);
因为d*d/M远小于1,所以优于老方法;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









