







YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Chien-Yao Wang1, Alexey Bochkovskiy, and Hong-Yuan Mark Liao1 1Institute of Information Science, Academia Sinica, Taiwan kinyiu@iis.sinica.edu.tw, alexeyab84@gmail.com, and liao@iis.sinica.edu.tw
 |
|---|
Abstract
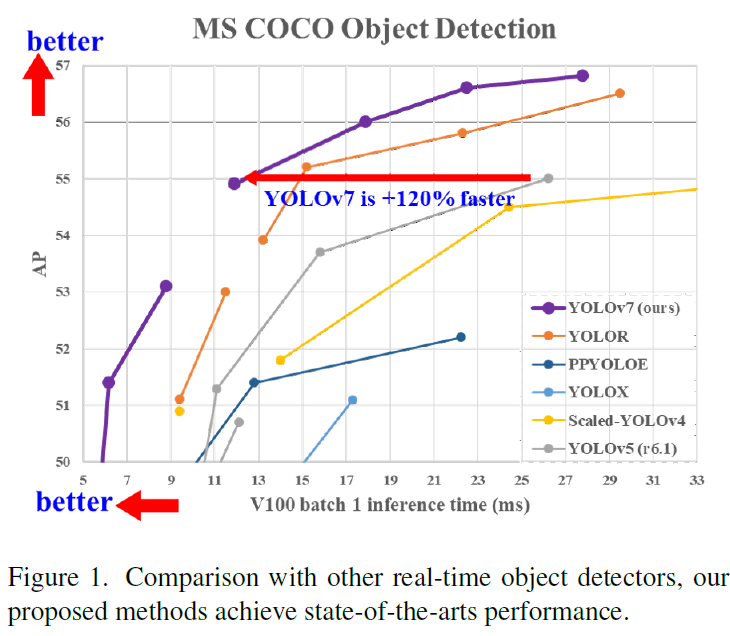
Real-time object detection is one of the most important research topics in computer vision. As new approaches regarding architecture optimization and training optimization are continually being developed, we have found two research topics that have spawned when dealing with these latest state-of-the-art methods. To address the topics, we propose a trainable bag-of-freebies oriented solution. We combine the flexible and efficient training tools with the proposed architecture and the compound scaling method. YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 120 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30 FPS or higher on GPU V100. Source code is released in https://github.com/WongKinYiu/yolov7.
实时目标检测是计算机视觉领域最重要的研究课题之一。随着有关架构优化和训练优化的新方法不断被开发出来,我们发现在处理这些最新的先进方法时产生了两个研究课题。为了解决这两个问题,我们提出了一种可训练的自由包导向解决方案。我们将灵活高效的训练工具与所提出的架构和复合缩放方法相结合。在 5 FPS 到 120 FPS 的范围内,YOLOv7 在速度和准确性上都超越了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时目标检测器中,YOLOv7 具有最高的准确性 56.8% AP。源代码发布于 https://github.com/WongKinYiu/yolov7。
1 Introduction
Real-time object detection is a very important topic in computer vision, as it is often a necessary component in computer vision systems. For example, multi-object tracking [90, 91], autonomous driving [17, 39], robotics [34, 55], medical image analysis [33, 44], etc. The computing devices that execute real-time object detection is usually some mobile CPUs or GPUs, as well as various neural processing units (NPUs). For example, the Apple neural engine (Apple), the neural compute stick (Intel), Jetson AI edge devices (Nvidia), the edge TPU (Google), the neural processing engine (Qualcomm), the AI processing unit (MediaTek), and the AI SoCs (Kneron), are all NPUs. Some of edge devices focus on speeding up different operations such as vanilla convolution, depth-wise convolution, or MLP operations. In this paper, the real-time object detector we proposed mainly hopes that it can support both mobile GPU and GPU devices from the edge to the cloud.
实时目标检测是计算机视觉领域一个非常重要的课题,因为它往往是计算机视觉系统的必要组成部分。例如,多目标跟踪[90, 91]、自动驾驶[17, 39]、机器人[34, 55]、医学图像分析[33, 44]等。执行实时目标检测的计算设备通常是一些移动 CPU 或 GPU,以及各种神经处理单元(NPU)。例如,Apple神经引擎(Apple)、神经计算棒(Intel)、Jetson AI 边缘设备(Nvidia)、边缘 TPU(Google)、神经处理引擎(Qualcomm)、AI 处理单元(MediaTek)和 AI SoC(Kneron)都属于 NPU。一些边缘设备专注于加速不同的操作,如虚构卷积、深度卷积或 MLP 操作。在本文中,我们提出的实时目标检测器主要希望能同时支持从边缘到云端的移动 GPU 和 GPU 设备。
In recent years, the real-time object detector is still developed for different edge devices. For example, the development of MCUNet [46,47] and NanoDet [51] focused on producing low-power single-chip and improving the inference speed on edge CPU. As for methods such as YOLOX [20] and YOLOR [79], they focus on improving the inference speed of various GPUs. More recently, the development of real-time object detector has focused on the design of efficient architecture. As for real-time object detectors that can be used on CPU [51, 81, 82, 86], their design is mostly based on MobileNet [26, 27, 63], ShuffleNet [52, 89], or GhostNet [24]. Another real-time object detectors are developed for GPU [20, 79, 94], they mostly use ResNet [25], DarkNet [60], or DLA [85], and then use the CSPNet [77] strategy to optimize the architecture. The development direction of the proposed methods in this paper are different from that of the current real-time object detectors. In addition to architecture optimization, our proposed methods will focus on the optimization of the training process. Our focus will be on some optimized modules and optimization methods which may strengthen the training cost for improving the accuracy of object detection, but without increasing the inference cost. We call these modules and optimization methods trainable bag-of-freebies.
近年来,实时目标检测器仍在针对不同的边缘设备进行开发。例如,MCUNet [46,47] 和 NanoDet [51]的开发侧重于生产低功耗单芯片和提高边缘 CPU 的推理速度。至于 YOLOX [20] 和 YOLOR [79] 等方法,则侧重于提高各种 GPU 的推理速度。近来,实时目标检测器的发展主要集中在高效架构的设计上。至于可用于 CPU 的实时目标检测器[51, 81, 82, 86],其设计大多基于 MobileNet [26, 27, 63]、ShuffleNet [52, 89] 或 GhostNet [24]。另一种针对 GPU 开发的实时目标检测器[20, 79, 94],它们大多采用 ResNet [25], DarkNet [60] 或 DLA [85],然后使用 CSPNet [77] 策略来优化架构。本文所提方法的发展方向与目前的实时目标检测器不同。除了架构优化,我们提出的方法还将重点放在训练过程的优化上。我们的重点将放在一些优化模块和优化方法上,这些模块和优化方法可以加强训练成本以提高目标检测的准确性,但不会增加推理成本。我们称这些模块和优化方法为可训练的自由包。
Recently, model re-parameterization [11, 12, 28] and dynamic label assignment [16, 19, 40] have become important topics in network training and object detection. Mainly after the above new concepts are proposed, the training of object detector evolves many new issues. In this paper, we will present some of the new issues we have discovered and devise effective methods to address them. For model reparameterization, we analyze the model re-parameterization strategies applicable to layers in different networks with the concept of gradient propagation path, and propose planned re-parameterization model. In addition, when we discover that with dynamic label assignment technology, the training of model with multiple output layers will generate new issues. That is: “How to assign dynamic targets for the outputs of different branches?” For this problem, we propose a new label assignment method called coarse-to-fine lead guided label assignment.
最近,模型重参数化[11, 12, 28]和动态标签分配[16, 19, 40]成为网络训练和目标检测中的重要课题。主要是在上述新概念提出后,目标检测器的训练演变出了许多新问题。本文将介绍我们发现的一些新问题,并设计有效的方法来解决这些问题。在模型重参数化方面,我们用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了有计划的重参数化模型。此外,当我们发现使用动态标签分配技术时,多输出层模型的训练会产生新的问题。那就是 “如何为不同分支的输出分配动态目标?针对这个问题,我们提出了一种新的标签分配方法,即粗到细的引导标签分配法。
The contributions of this paper are summarized as follows: (1) we design several trainable bag-of-freebies methods, so that real-time object detection can greatly improve the detection accuracy without increasing the inference cost; (2) for the evolution of object detection methods, we found two new issues, namely how re-parameterization module replaces original module, and how dynamic label assignment strategy deals with assignment to different output layers. In addition, we also propose methods to address the difficulties arising from these issues; (3) we propose “extend” and “compound scaling” methods for the real-time object detector that can effectively utilize parameters and computation; and (4) the method we proposed can effectively reduce large amount of parameters and computation of state-of-the-art real-time object detector, and has faster inference speed and higher detection accuracy.
本文的贡献总结如下: (1)我们设计了几种可训练的自由包(bag-of-freebies)方法,使实时目标检测在不增加推理成本的前提下,大大提高了检测精度;(2)对于目标检测方法的演化,我们发现了两个新问题,即重新参数化模块如何替代原有模块,以及动态标签赋值策略如何处理对不同输出层的赋值。此外,我们还提出了解决这些问题带来的困难的方法;(3)我们提出了实时目标检测器的 “扩展 ”和 “复合缩放 ”方法,可以有效利用参数和计算量;(4)我们提出的方法可以有效减少最先进的实时目标检测器的大量参数和计算量,具有更快的推理速度和更高的检测精度。
2 Related work
2.1 Real-time object detectors
Currently state-of-the-art real-time object detectors are mainly based on YOLO [58–60] and FCOS [73, 74], which are [2, 20, 22, 51, 76, 79, 83]. Being able to become a state-of-the-art real-time object detector usually requires the following characteristics: (1) a faster and stronger network architecture; (2) a more effective feature integration method [8, 21, 29, 36, 43, 56, 71, 94]; (3) a more accurate detection method [66, 73, 74]; (4) a more robust loss function [5, 53, 54, 61, 92, 93]; (5) a more efficient label assignment method [16, 19, 40, 80, 96]; and (6) a more efficient training method. In this paper, we do not intend to explore selfsupervised learning or knowledge distillation methods that require additional data or large model. Instead, we will design new trainable bag-of-freebies method for the issues derived from the state-of-the-art methods associated with (4), (5), and (6) mentioned above.
目前最先进的实时目标检测器主要基于 YOLO [58-60] 和 FCOS [73, 74],它们分别是[2, 20, 22, 51, 76, 79, 83]。要想成为最先进的实时目标检测器,通常需要具备以下特点:
- (1) 更快、更强的网络架构;
- (2) 更有效的特征整合方法 [8、21、29、36、43、56、71、94];
- (3) 更精确的检测方法 [66、73、74];
- (4) 更robust的损失函数 [5、53、54、61、92、93];
- (5) 更高效的标签分配方法 [16、19、40、80、96];
- (6) 更有效的训练方法。
在本文中,我们不打算探索需要额外数据或大型模型的自我监督学习或知识提炼方法。相反,我们将针对与上述 (4)、(5) 和 (6) 相关的最先进方法中衍生出的问题,设计新的可训练自由包方法。
2.2. Model reparameterization
Model re-parametrization techniques [3,9–13,18,23,28, 30, 32, 68, 72, 75] merge multiple computational modules into one at inference stage. The model re-parameterization technique can be regarded as an ensemble technique, and we can divide it into two categories, i.e., module-level ensemble and model-level ensemble. There are two common practices for model-level re-parameterization to obtain the final inference model. One is to train multiple identical models with different training data, and then average the weights of multiple trained models. The other is to perform a weighted average of the weights of models at different iteration number. Module-level re-parameterization is a more popular research issue recently. This type of method splits a module into multiple identical or different module branches during training and integrates multiple branched modules into a completely equivalent module during inference. However, not all proposed re-parameterization module can be perfectly applied to different architectures. With this in mind, we have developed new re-parameterization module and designed related application strategies for various architectures.
模型重参数化技术[3,9-13,18,23,28,30,32,68,72,75]在推理阶段将多个计算模块合并为一个模块。模型重参数化技术可视为一种集合技术,我们可将其分为两类,即模块级集合和模型级集合。为获得最终推理模型,模型级参数化通常有两种做法。一种是用不同的训练数据训练多个相同的模型,然后平均多个训练模型的权重。另一种是对不同迭代次数的模型权重进行加权平均。模块级重新参数化是最近比较热门的研究课题。这类方法在训练过程中将一个模块分成多个相同或不同的模块分支,在推理过程中将多个分支模块整合成一个完全等价的模块。然而,并不是所有提出的重参数化模块都能完美地应用于不同的架构。有鉴于此,我们开发了新的重参数化模块,并针对不同的架构设计了相关的应用策略。
2.3. Model scaling
Model scaling [1, 14, 15, 49, 57, 69–71] is a way to scale up or down an already designed model and make it fit in different computing devices. The model scaling method usually uses different scaling factors, such as resolution (size of input image), depth (number of layer), width (number of channel), and stage (number of feature pyramid), so as to achieve a good trade-off for the amount of network parameters, computation, inference speed, and accuracy. Network architecture search (NAS) is one of the commonly used model scaling methods. NAS can automatically search for suitable scaling factors from search space without defining too complicated rules. The disadvantage of NAS is that it requires very expensive computation to complete the search for model scaling factors. In [14], the researcher analyzes the relationship between scaling factors and the amount of parameters and operations, trying to directly estimate some rules, and thereby obtain the scaling factors required by model scaling. Checking the literature, we found that almost all model scaling methods analyze individual scaling factor independently, and even the methods in the compound scaling category also optimized scaling factor independently. The reason for this is because most popular NAS architectures deal with scaling factors that are not very correlated. We observed that all concatenation-based models, such as DenseNet [31] or VoVNet [38], will change the input width of some layers when the depth of such models is scaled. Since the proposed architecture is concatenationbased, we have to design a new compound scaling method for this model.
模型缩放 [1, 14, 15, 49, 57, 69-71] 是一种将已设计好的模型放大或缩小,使其适合不同计算设备的方法。模型缩放方法通常使用不同的缩放因子,如分辨率(输入图像的大小)、深度(层数)、宽度(通道数)和阶段(特征金字塔数),从而在网络参数量、计算量、推理速度和准确度之间实现良好的权衡。网络结构搜索(NAS)是常用的模型缩放方法之一。NAS 可以自动从搜索空间中搜索合适的缩放因子,而无需定义过于复杂的规则。NAS 的缺点是需要非常昂贵的计算来完成模型缩放因子的搜索。在文献[14]中,研究者分析了缩放因子与参数量和运算量之间的关系,试图直接估计一些规则,从而得到模型缩放所需的缩放因子。查阅文献发现,几乎所有的模型缩放方法都是独立分析单个缩放因子的,即使是复合缩放类的方法也是独立优化缩放因子的。究其原因,是因为大多数流行的 NAS 架构处理的缩放因子相关性不强。我们观察到,所有基于串联的模型,如 DenseNet [31] 或 VoVNet [38],在缩放深度时都会改变某些层的输入宽度。由于拟议的架构是基于连接的,我们必须为该模型设计一种新的复合缩放方法。
3 Architecture
3.1. Extended efficient layer aggregation networks
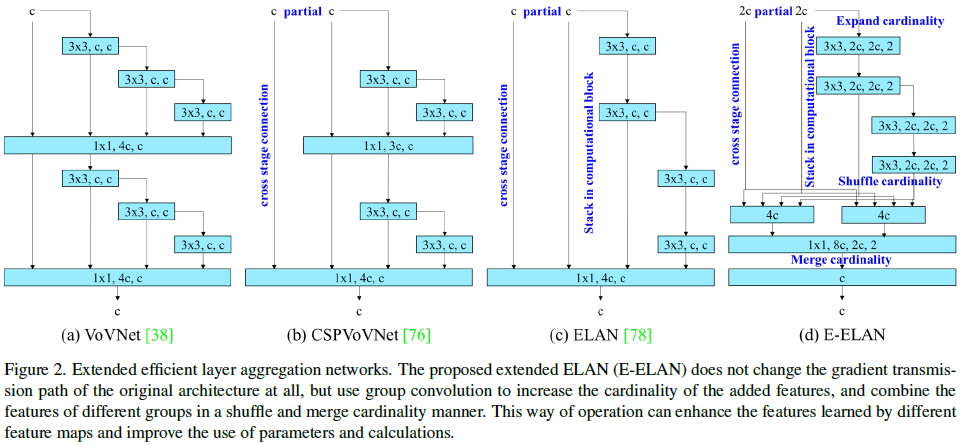
In most of the literature on designing the efficient architectures, the main considerations are no more than the number of parameters, the amount of computation, and the computational density. Starting from the characteristics of memory access cost, Ma et al. [52] analyzed the influence of the input/output channel ratio, the number of branches of the architecture, and the element-wise operation on the network inference speed. Doll´ar et al. [14] additionally considered activation when performing model scaling, that is, to put more consideration on the number of elements in the output tensors of convolutional layers. The design of CSPVoVNet [76] in Figure 2 (b) is a variation of VoVNet [38]. In addition to considering the aforementioned basic designing concerns, the architecture of CSPVoVNet [76] also analyzes the gradient path, in order to enable the weights of different layers to learn more diverse features. The gradient analysis approach described above makes inferences faster and more accurate. ELAN [78] in Figure 2 © considers the following design strategy – “How to design an efficient network?.” They came out with a conclusion: By controlling the longest shortest gradient path, a deeper network can learn and converge effectively. In this paper, we propose Extended-ELAN (E-ELAN) based on ELAN and its main architecture is shown in Figure 2 (d).
在大多数关于设计高效架构的文献中,主要考虑的因素不外乎参数数量、计算量和计算密度。Ma 等人[52]从内存访问成本的特点出发,分析了输入与输出的通道比(inputs/outputs)、架构分支数和元素操作对网络推理速度的影响。Dollar 等人[14]在进行模型缩放时还考虑了激活,即更多地考虑卷积层输出张量中的元素数量。图 2 (b) 中 CSPVoVNet [76] 的设计是 VoVNet [38] 的变体。除了考虑上述基本设计问题外,CSPVoVNet [76] 的架构还分析了梯度路径,以使不同层的权重能学习到更多不同的特征。上述梯度分析方法使推断更快、更准确。图 2 © 中的 ELAN [78] 考虑了以下设计策略—"如何设计一个高效的网络?他们得出了一个结论:通过控制最长最短梯度路径,深度网络可以有效地学习和收敛。本文在 ELAN 的基础上提出了扩展 ELAN(E-ELAN),其主要架构如图 2 (d) 所示。
 |
|---|
Regardless of the gradient path length and the stacking number of computational blocks in large-scale ELAN, it has reached a stable state. If more computational blocks are stacked unlimitedly, this stable state may be destroyed, and the parameter utilization rate will decrease. The proposed E-ELAN uses expand, shuffle, merge cardinality to achieve the ability to continuously enhance the learning ability of the network without destroying the original gradient path. In terms of architecture, E-ELAN only changes the architecture in computational block, while the architecture of transition layer is completely unchanged. Our strategy is to use group convolution to expand the channel and cardinality of computational blocks. We will apply the same group parameter and channel multiplier to all the computational blocks of a computational layer. Then, the feature map calculated by each computational block will be shuffled into g groups according to the set group parameter g, and then concatenate them together. At this time, the number of channels in each group of feature map will be the same as the number of channels in the original architecture. Finally, we add g groups of feature maps to perform merge cardinality. In addition to maintaining the original ELAN design architecture, E-ELAN can also guide different groups of computational blocks to learn more diverse features.
在大规模 ELAN 中,无论梯度路径长度和计算块堆叠数量如何,它都达到了稳定状态。如果无限制地堆叠更多计算块,这种稳定状态可能会被破坏,参数利用率也会下降。本文提出的E-ELAN利用expand、shuffle、merge cardinality 来实现在不破坏原有梯度路径的情况下,不断增强网络的学习能力。在架构上,E-ELAN 只改变了计算块的架构,而过渡层的架构则完全不变。我们的策略是利用组卷积来扩展计算块的通道和卡数。我们将对计算层的所有计算块应用相同的组参数和通道乘数。然后,每个计算块计算出的特征图将根据设定的组参数 g 分成 g 组,然后将它们串联起来。此时,每组特征图中的通道数将与原始架构中的通道数相同。最后,我们再添加 g 组特征图来执行合并。除了保持原有的 ELAN 设计架构外,E-ELAN 还能引导不同的计算模块组学习更多样化的特征。
3.2. Model scaling for concatenationbased models
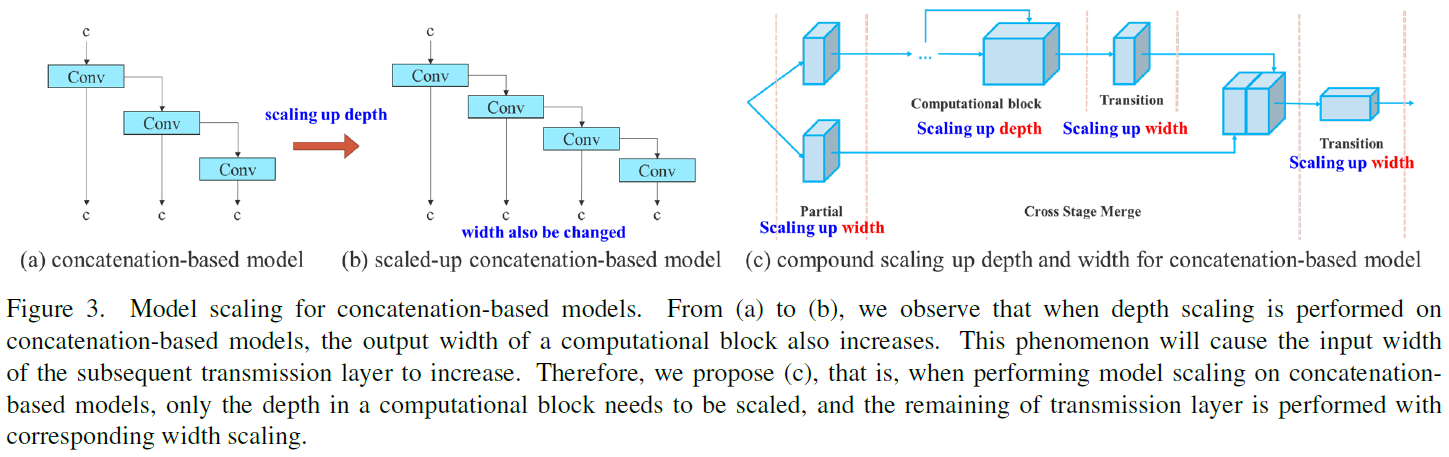
The main purpose of model scaling is to adjust some attributes of the model and generate models of different scales to meet the needs of different inference speeds. For example the scaling model of EfficientNet [69] considers the width, depth, and resolution. As for the scaled-YOLOv4 [76], its scaling model is to adjust the number of stages. In [14], Doll´ar et al. analyzed the influence of vanilla convolution and group convolution on the amount of parameter and computation when performing width and depth scaling, and used this to design the corresponding model scaling method. The above methods are mainly used in architectures such as PlainNet or ResNet. When these architectures are in execut-ing scaling up or scaling down, the in-degree and out-degree of each layer will not change, so we can independently analyze the impact of each scaling factor on the amount of parameters and computation. However, if these methods are applied to the concatenation-based architecture, we will find that when scaling up or scaling down is performed on depth, the in-degree of a translation layer which is immediately after a concatenation-based computational block will decrease or increase, as shown in Figure 3 (a) and (b).
模型缩放的主要目的是调整模型的某些属性,生成不同尺度的模型,以满足不同推理速度的需要。例如,EfficientNet [69] 的缩放模型考虑了宽度、深度和分辨率。至于 Scaled-YOLOv4 [76],其缩放模型是调整阶段数。在文献[14]中,Dollar 等人分析了在进行宽度和深度缩放时,vanilla convolution和group convolution对参数量和计算量的影响,并据此设计了相应的模型缩放方法。上述方法主要用于 PlainNet 或 ResNet 等架构。当这些架构执行向上或向下缩放时,各层的入度和出度不会发生变化,因此我们可以独立分析各缩放因子对参数量和计算量的影响。但是,如果将这些方法应用于基于串联的架构,我们会发现,当对深度进行扩展或缩减时,紧跟在基于串联的计算块之后的translation layer的入度会减少或增加,如图 3(a)和(b)所示。
It can be inferred from the above phenomenon that we cannot analyze different scaling factors separately for a concatenation-based model but must be considered together. Take scaling-up depth as an example, such an action will cause a ratio change between the input channel and output channel of a transition layer, which may lead to a decrease in the hardware usage of the model. Therefore, we must propose the corresponding compound model scaling method for a concatenation-based model. When we scale the depth factor of a computational block, we must also calculate the change of the output channel of that block. Then, we will perform width factor scaling with the same amount of change on the transition layers, and the result is shown in Figure 3 ©. Our proposed compound scaling method can maintain the properties that the model had at the initial design and maintains the optimal structure.
从上述现象可以推断,我们不能单独分析基于连接的模型的不同缩放因子,而必须综合考虑。以扩大深度为例,这种行为会导致过渡层的输入通道和输出通道之间的比例发生变化,从而可能导致模型的硬件使用率下降。因此,我们必须针对基于串联的模型提出相应的复合模型缩放方法。当我们缩放计算块的深度因子时,还必须计算该计算块输出通道的变化。然后,我们将以相同的变化量对过渡层进行宽度因子缩放,结果如图 3(c)所示。我们提出的复合缩放方法可以保持模型在初始设计时的特性,并保持最佳结构。
 |
|---|
4 Trainable bag-of-freebies
4.1. Planned reparameterization model
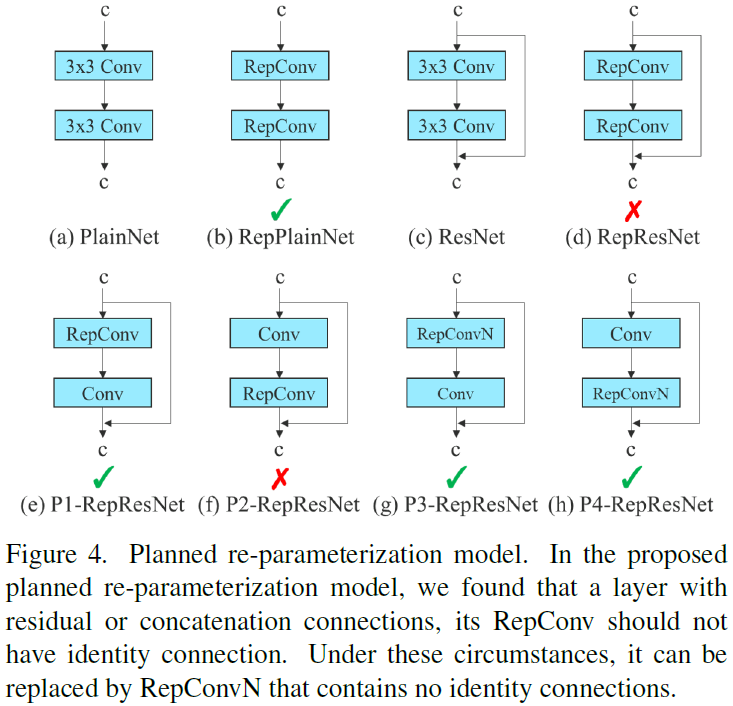
Although RepConv [12] has achieved excellent performance on the VGG [65], when we directly apply it to ResNet [25] and DenseNet [31] and other nonplain architectures, its accuracy will be significantly reduced. We use gradient flow propagation paths to analyze how re-parameterization convolution should be combined with different network. We also designed planned re-parameterization model accordingly.
虽然 RepConv [12] 在 VGG [65] 上取得了优异的性能,但当我们直接将其应用于 ResNet [25] 和 DenseNet [31] 以及其他非平原架构时,其准确性将大大降低。我们利用梯度流传播路径分析了重参数化卷积应如何与不同的网络相结合。我们还设计了相应的重参数化模型。
RepConv actually combines 33 convolution, 11 convolution, and identity connection in one convolutional layer. After analyzing the combination and corresponding performance of RepConv and different architectures, we find that the identity connection in RepConv destroys the residual in ResNet and the concatenation in DenseNet, which provides more diversity of gradients for different feature maps. For the above reasons, we use RepConv without identity connection (RepConvN) to design the architecture of planned re-parameterization model. In our thinking, when a convolutional layer with residual or concatenation is replaced by re-parameterization convolution, there should be no identity connection. Figure 4 shows examples of how our designed “planned re-parameterization model” is applied in PlainNet and ResNet. As for the complete planned reparameterization model experiment in residual-based model and concatenation-based model, it will be presented in the ablation study session.
RepConv 实际上在一个卷积层中结合了 33 个卷积、11 个卷积和身份连接。在分析了 RepConv 与不同架构的组合和相应性能后,我们发现 RepConv 中的身份连接破坏了 ResNet 中的残差和 DenseNet 中的串联,从而为不同的特征图提供了更多样化的梯度。基于上述原因,我们使用不带身份连接的 RepConv(RepConvN)来设计规划重参数化模型的架构。按照我们的想法,当有残差或连接的卷积层被重参数化卷积取代时,不应该有身份连接。图 4 展示了我们设计的 “计划重参数化模型 ”在 PlainNet 和 ResNet 中的应用实例。至于基于残差模型和基于并集模型的完整计划重参数化模型实验,将在消融研究环节中介绍。
 |
|---|
4.2. Coarse for auxiliary and fine for lead loss
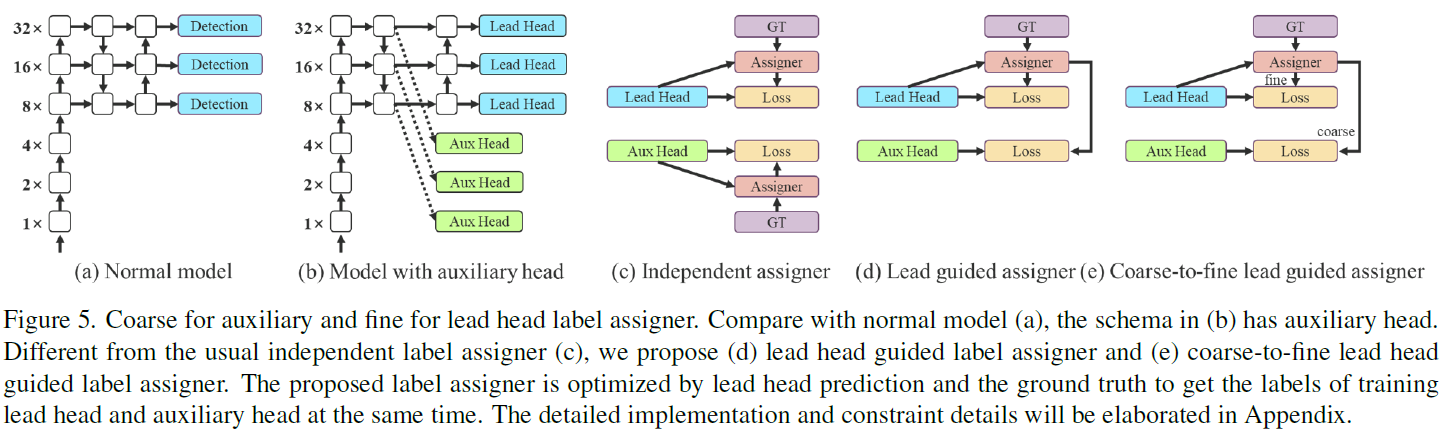
Deep supervision [37] is a technique used for training deep networks. Its main concept is to add extra auxiliary head in the middle layers of the network, and the shallow network weights with assistant loss as the guide. Even for architectures such as ResNet [25] and DenseNet [31] which usually converge well, deep supervision [45, 48, 62, 64, 67, 80, 84, 95] can still significantly improve the performance of the model on many tasks. Figure 5 (a) and (b) show, respectively, the object detector architecture “without” and “with” deep supervision. In this paper, we call the head responsible for the final output as the lead head, and the head used to assist training is called auxiliary head.
深度监督 [37] 是一种用于训练深度网络的技术。它的主要概念是在网络的中间层添加额外的辅助头,并以辅助损失为导向的浅层网络权重。即使对于 ResNet [25] 和 DenseNet [31] 这样通常收敛良好的架构,深度监督 [45, 48, 62, 64, 67, 80, 84, 95] 仍能显著提高模型在许多任务中的性能。图 5 (a) 和 (b) 分别显示了 “无 ”和 “有 ”深度监督的目标检测器架构。在本文中,我们把负责最终输出的头称为主导头,把用于辅助训练的头称为辅助头。
Next we want to discuss the issue of label assignment. In the past, in the training of deep network, label assignment usually refers directly to the ground truth and generate hard label according to the given rules. However, in recent years, if we take object detection as an example, researchers often use the quality and distribution of prediction output by the network, and then consider together with the ground truth to use some calculation and optimization methods to generate a reliable soft label [7, 16, 19, 35, 40–42, 58, 87, 88, 96]. For example, YOLO [58] use IoU of prediction of bounding box regression and ground truth as the soft label of objectness. In this paper, we call the mechanism that considers the network prediction results together with the ground truth and then assigns soft labels as “label assigner.”
接下来,我们想讨论标签分配的问题。在过去的深度网络训练中,标签分配通常直接参考ground truth实况,并根据给定的规则生成硬标签。但近年来,如果以目标检测为例,研究者往往通过网络输出预测的质量和分布,再结合ground truth实况一起考虑,使用一些计算和优化方法生成可靠的软标签[7, 16, 19, 35, 40-42, 58, 87, 88, 96]。例如,YOLO [58] 使用边界框回归预测的 IoU 和ground truth实况作为目标性的软标签。在本文中,我们把将网络预测结果与地面实况一并考虑,然后分配软标签的机制称为 “标签分配器”。
Deep supervision needs to be trained on the target objectives regardless of the circumstances of auxiliary head or lead head. During the development of soft label assigner related techniques, we accidentally discovered a new derivative issue, i.e., “How to assign soft label to auxiliary head and lead head ?” To the best of our knowledge, the relevant literature has not explored this issue so far. The results of the most popular method at present is shown in Figure 5 ©, which is to separate auxiliary head and lead head, and then use their own prediction results and the ground truth to execute label assignment. The method proposed in this paper is a new label assignment method that guides both auxiliary head and lead head by the lead head prediction. In other words, we use lead head prediction as guidance to generate coarse-to-fine hierarchical labels, which are used for auxiliary head and lead head learning, respectively. The two proposed deep supervision label assignment strategies are shown in Figure 5 (d) and (e), respectively. Lead head guided label assigner is mainly calculated based on the prediction result of the lead head and the ground truth, and generate soft label through the optimization process. This set of soft labels will be used as the target training model for both auxiliary head and lead head. The reason to do this is because lead head has a relatively strong learning capability, so the soft label generated from it should be more representative of the distribution and correlation between the source data and the target. Furthermore, we can view such learning as a kind of generalized residual learning. By letting the shallower auxiliary head directly learn the information that lead head has learned, lead head will be more able to focus on learning residual information that has not yet been learned.
无论辅助头或主导头的情况如何,深度监督都需要针对目标进行训练。在开发软标签分配器相关技术的过程中,我们意外地发现了一个新的衍生问题,即 "如何为辅助头和引导头分配软标签?” 据我们所知,迄今为止相关文献还没有探讨过这个问题。目前最流行的方法结果如图 5 ©所示,即把辅助头和引导头分开,然后利用各自的预测结果和ground truth实况来执行标签分配。本文提出的方法是一种新的标签分配方法,它通过引导头预测来引导辅助头和引导头。换句话说,我们以引导头预测为指导,生成从粗到细的分层标签,分别用于辅助头和引导头学习。图 5(d)和(e)分别显示了所提出的两种深度监督标签分配策略。引导头引导标签分配器主要根据引导头的预测结果和ground truth实况进行计算,并通过优化过程生成软标签。这组软标签将作为辅助头和引导头的目标训练模型。这样做的原因是,主导头的学习能力相对较强,因此由它生成的软标签应该更能代表源数据与目标数据之间的分布和相关性。此外,我们还可以把这种学习看作是一种广义残差学习。让较浅的辅助头直接学习引导头已学习的信息,引导头就能更专注地学习尚未学习的残差信息。
 |
|---|
Coarse-to-fine lead head guided label assigner also used the predicted result of the lead head and the ground truth to generate soft label. However, in the process we generate two different sets of soft label, i.e., coarse label and fine label, where fine label is the same as the soft label generated by lead head guided label assigner, and coarse label is generated by allowing more grids to be treated as positive target by relaxing the constraints of the positive sample assignment process. The reason for this is that the learning ability of an auxiliary head is not as strong as that of a lead head, and in order to avoid losing the information that needs to be learned, we will focus on optimizing the recall of auxiliary head in the object detection task. As for the output of lead head, we can filter the high precision results from the high recall results as the final output. However, we must note that if the additional weight of coarse label is close to that of fine label, it may produce bad prior at final prediction. Therefore, in order to make those extra coarse positive grids have less impact, we put restrictions in the decoder, so that the extra coarse positive grids cannot produce soft label perfectly. This mechanism allows the importance of fine label and coarse label to be dynamically adjusted during the learning process, and makes the optimizable upper bound of fine label always higher than coarse label.
从粗到细的引导头引导标签分配器也使用引导头的预测结果和ground truth来生成软标签。但在此过程中,我们生成了两组不同的软标签,即粗标签和细标签,其中细标签与引导头引导标签分配器生成的软标签相同,而粗标签则是通过放宽正样本分配过程的限制,允许更多的网格被视为正目标而生成的。这是因为辅助头的学习能力不如引导头强,为了避免丢失需要学习的信息,我们将重点优化辅助头在目标检测任务中的召回率。至于导引头的输出,我们可以从高召回率结果中筛选出高精度结果作为最终输出。但是,我们必须注意,如果粗标签的附加权重与细标签的附加权重接近,可能会在最终预测时产生不好的先验结果。因此,为了减少这些额外的粗正网格的影响,我们在解码器中设置了限制,使额外的 coarse positive grids不能完美地生成软标签。这种机制允许在学习过程中动态调整fine标签和coarse标签的重要性,并使fine标签的可优化上限始终高于coarse标签。
4.3. Other trainable bag-of-freebies
In this section we will list some trainable bag-offreebies. These freebies are some of the tricks we used in training, but the original concepts were not proposed by us. The training details of these freebies will be elaborated in the Appendix, including (1) Batch normalization in conv-bn-activation topology: This part mainly connects batch normalization layer directly to convolutional layer. The purpose of this is to integrate the mean and variance of batch normalization into the bias and weight of convolutional layer at the inference stage. (2) Implicit knowledge in YOLOR [79] combined with convolution feature map in addition and multiplication manner: Implicit knowledge in YOLOR can be simplified to a vector by pre-computing at the inference stage. This vector can be combined with the bias and weight of the previous or subsequent convolutional layer. (3) EMA model: EMA is a technique used in mean teacher [72], and in our system we use EMA model purely as the final inference model.
在本节中,我们将列出一些可训练的 “ bag-of-freebies”。这些freebies 是我们在训练中使用的一些技巧,但最初的概念并不是我们提出的。这些免费工具的训练细节将在附录中详细说明,其中包括 (1) conv-bn-activation 拓扑中的批量归一化: 这部分主要是将批量归一化层直接连接到卷积层。其目的是在推理阶段将批量归一化的均值和方差整合到卷积层的偏置和权重中。(2) YOLOR [79] 中的内隐知识以加法和乘法的方式与卷积特征图相结合: YOLOR 中的隐含知识可在推理阶段通过预计算简化为一个向量。该向量可与前一个或后一个卷积层的偏置和权重相结合。(3) EMA 模型: EMA 是 mean teacher中使用的一种技术[72],在我们的系统中,我们纯粹使用 EMA 模型作为最终推理模型。
5 Experiments
5.1. Experimental setup
MS COCO dataset is used to conduct experiments. All our models were trained from scratch. We used train 2017 set for training, and then used val 2017 set for verification and choosing hyperparameters. Finally, test 2017 set is used to compare with the state-of-the-art object detectors. Detailed training settings are described in Appendix. We designed basic model for edge GPU, normal GPU, and cloud GPU, and they are respectively called YOLOv7-tiny, YOLOv7, and YOLOv7-W6. We also use basic model for model scaling for different service requirements. For YOLOv7, we do stack scaling on neck, and use the proposed compound scaling method to perform scalingup of the depth and width of the entire model to obtain YOLOv7-X. As for YOLOv7-W6, we use the newly proposed compound scaling method to obtain YOLOv7-E6 and YOLOv7-D6. In addition, we use the proposed E-ELAN for YOLOv7-E6, and thereby complete YOLOv7-E6E. Since YOLOv7-tiny is an edge GPU-oriented architecture, it will use leaky ReLU as activation function. As for other models we use SiLU as activation function. We will describe the scaling factor of each model in detail in Appendix.
我们使用 MS COCO 数据集进行实验。我们的所有模型都是从零开始训练的。我们使用 train 2017 数据集进行训练,然后使用 val 2017 数据集进行验证和选择超参数。最后,使用 test 2017 集与最先进的目标检测器进行比较。详细的训练设置见附录。我们为边缘 GPU、正常 GPU 和云 GPU 设计了基本模型,它们分别被称为 YOLOv7-tiny、YOLOv7 和 YOLOv7-W6。我们还使用基本模型进行模型扩展,以满足不同的服务需求。对于 YOLOv7,我们在neck进行堆叠缩放,并使用建议的复合缩放方法对整个模型的深度和宽度进行向上缩放,从而得到 YOLOv7-X。至于 YOLOv7-W6,我们使用新提出的复合缩放方法得到 YOLOv7-E6 和 YOLOv7-D6。此外,我们还对 YOLOv7-E6 使用了建议的 E-ELAN,从而完成了 YOLOv7-E6E。由于 YOLOv7-tiny 是面向边缘 GPU 的架构,它将使用leaky ReLU 作为激活函数。至于其他模型,我们使用 SiLU 作为激活函数。我们将在附录中详细描述每个模型的缩放因子。
5.2. Baselines
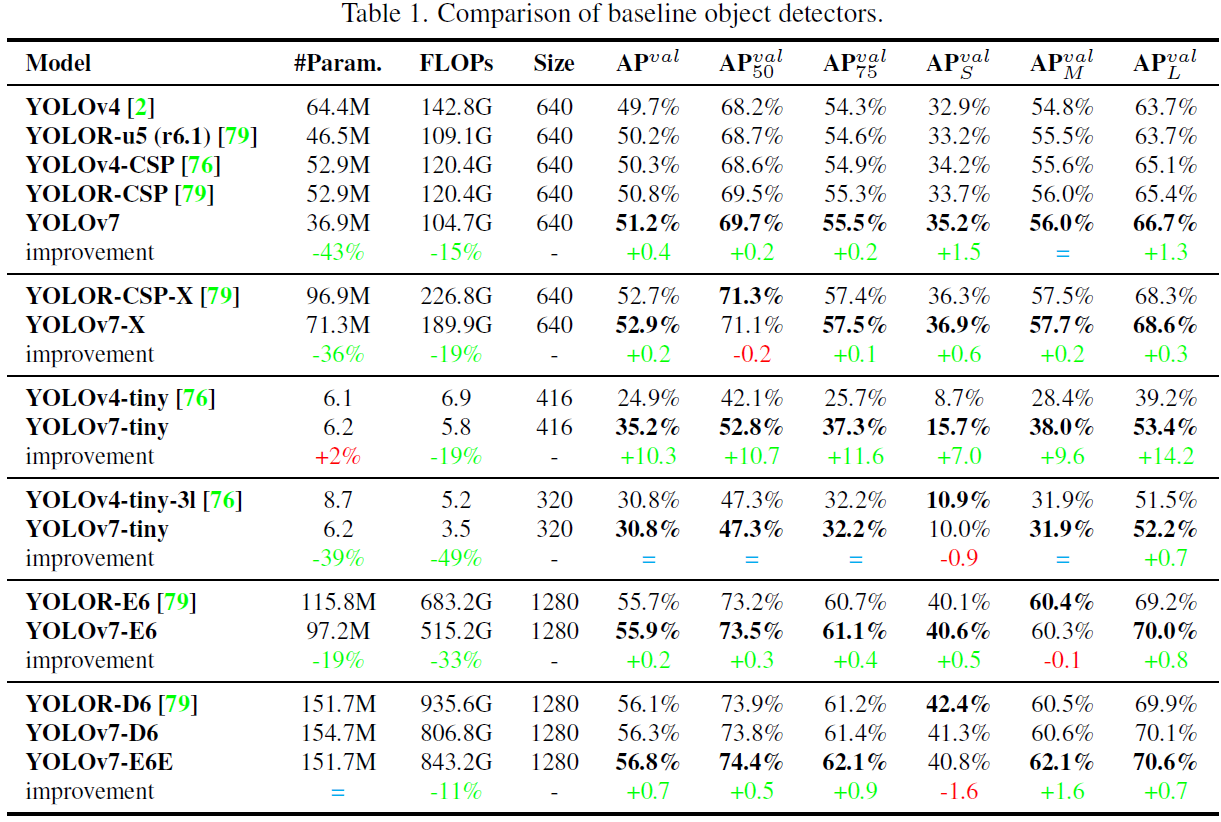
We choose previous version of YOLO [2, 76] and stateof-the-art object detector YOLOR [79] as our baselines. Table 1 shows the comparison of our proposed YOLOv7 models and those baseline that are trained with the same settings. From the results we see that YOLOv7-based models outperform the baseline models in terms of number of parameters, amount of computation, and accuracy. For models designed for normal GPU, YOLOv7 and YOLOv7x reduce about 40% parameters and 20% computations, and still achieve higher AP. For model designed for edge GPU, YOLOv7-tiny reduce 39% parameters and 49% computation and achieve same AP as YOLOv4-tiny-3l.
我们选择以前版本的 YOLO [2, 76] 和最先进的目标检测器 YOLOR [79] 作为基线。表 1 显示了我们提出的 YOLOv7 模型与在相同设置下训练的基线模型的比较。从结果中我们可以看出,基于 YOLOv7 的模型在参数数量、计算量和准确度方面都优于基线模型。对于为普通 GPU 设计的模型,YOLOv7 和 YOLOv7x 减少了约 40% 的参数和 20% 的计算量,但仍然获得了更高的 AP。对于为边缘 GPU 设计的模型,YOLOv7-tiny 减少了 39% 的参数和 49% 的计算量,获得的 AP 与 YOLOv4-tiny-3l 相同。
 |
|---|
5.3. Comparison with stateofthearts
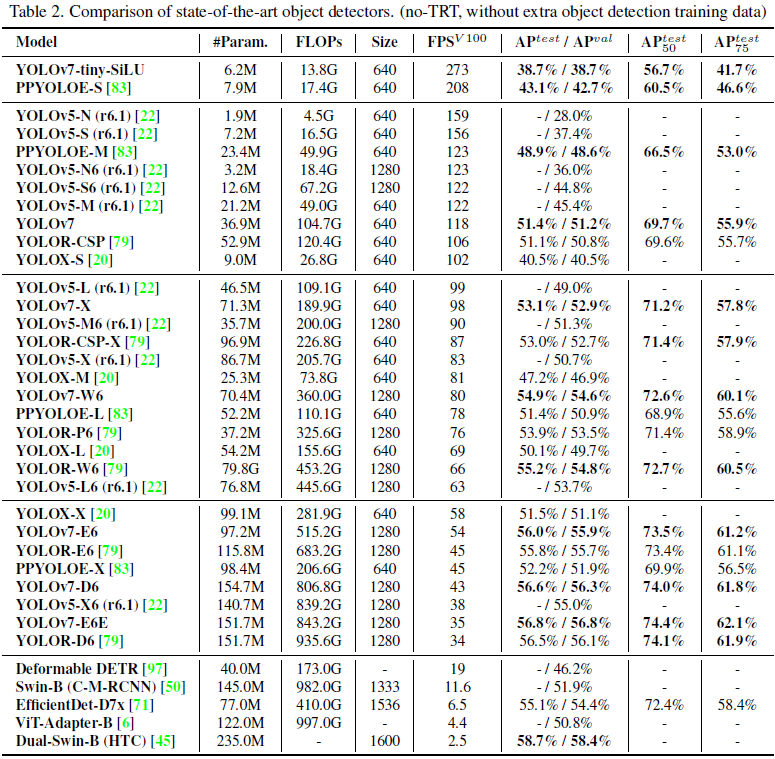
We compare the proposed method with state-of-the-art object detectors, and the results are shown in Table 2. From Table 2 we know that the proposed method has the best speed-accuracy trade-off comprehensively.
我们将提出的方法与最先进的目标检测器进行了比较,结果如表 2 所示。从表 2 中我们可以看出,本文提出的方法在速度和准确度之间的权衡最为合理。
 |
|---|
5.4. Ablation study
5.4.1 Proposed compound scaling method
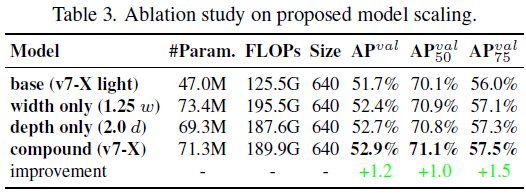
Table 3 shows the results obtained when using different model scaling strategies for scaling up. Among them, our proposed compound scaling method is to scale up the depth of computational block by 1.5 times and the width of transition block by 1.25 times. It can be seen from the results of Table 3 that our proposed compound scaling strategy can utilize parameters and computation more efficiently.
表 3 显示了使用不同模型缩放策略进行缩放时得到的结果。其中,我们提出的复合缩放方法是将计算块的深度缩放 1.5 倍,过渡块的宽度缩放 1.25 倍。从表 3 的结果可以看出,我们提出的复合缩放策略可以更有效地利用参数和计算量。
 |
|---|
5.4.2 Proposed planned re-parameterization model
In order to verify the generality of our proposed planed reparameterization model, we use it on concatenation-based model and residual-based model respectively for verification. The concatenation-based model and residual-based model we chose for verification are 3-stacked ELAN and CSPDarknet, respectively.
为了验证我们提出的计划重参数化模型的通用性,我们将其分别用于基于串联的模型和基于残差的模型进行验证。我们选择的基于串联的模型和基于残差的模型分别是 3 -stacked ELAN 和 CSPDarknet。
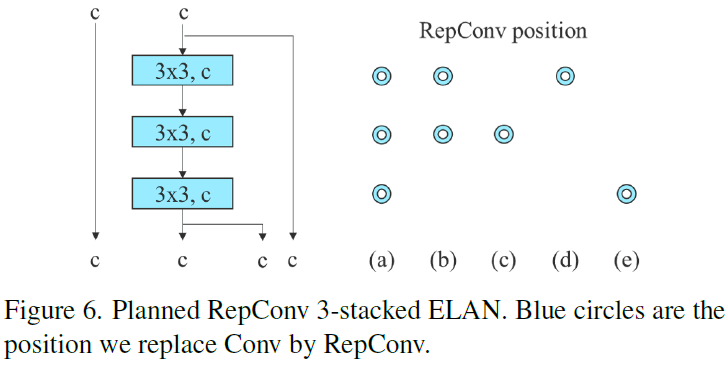
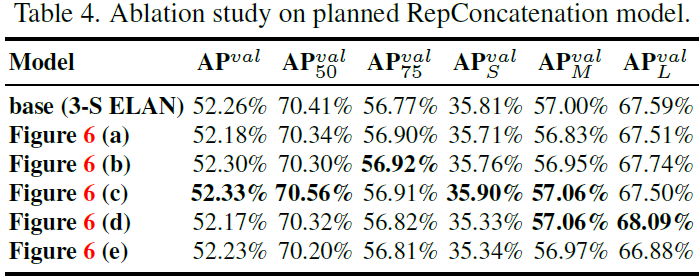
In the experiment of concatenation-based model, we replace the 33 convolutional layers in different positions in 3-stacked ELAN with RepConv, and the detailed configuration is shown in Figure 6. From the results shown in Table 4 we see that all higher AP values are present on our proposed planned re-parameterization model.
在基于串联模型的实验中,我们用 RepConv 替换了 3-stack ELAN 中不同位置的 33 个卷积层,具体配置如图 6 所示。从表 4 中显示的结果可以看出,所有较高的 AP 值都出现在我们提出的计划重参数化模型中。
 |
|---|
 |
|---|
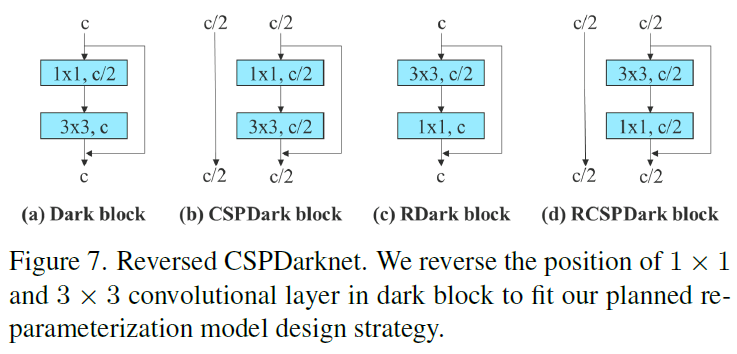
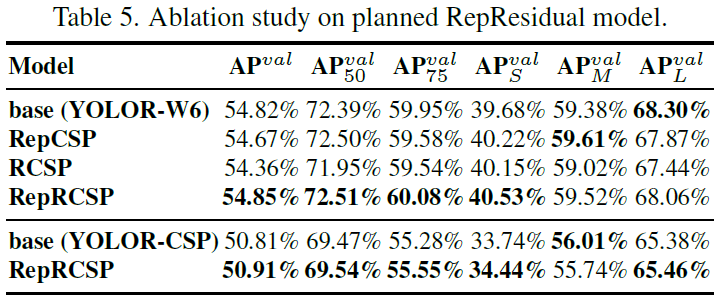
In the experiment of residual-based model, we design a reversed dark block to fit our design strategy for the experiment, whose architecture is shown in Figure 7. The experiment results illustrated in Table 5 fully confirm that the proposed planned re-parameterization model is equally effective on residual-based model. We find that the design of RepCSPResNet [83] also fits our design pattern.
在基于残差模型的实验中,我们设计了一个residual-based,以适应我们的实验设计策略,其架构如图 7 所示。表 5 所示的实验结果充分证实了所提出的计划重参数化模型对基于残差的模型同样有效。我们发现 RepCSPResNet [83] 的设计也符合我们的设计模式。
 |
|---|
 |
|---|
5.4.3 Proposed assistant loss for auxiliary head
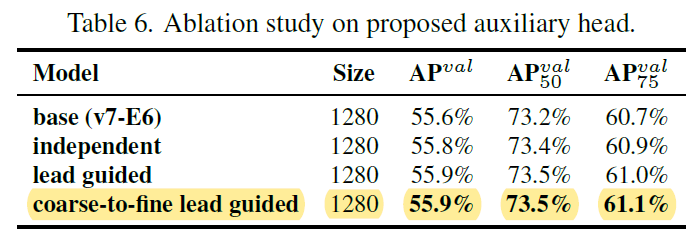
In the assistant loss for auxiliary head experiments, we compare the general independent label assignment for lead head and auxiliary head methods, and we also compare the two proposed lead guided label assignment methods. We show all comparison results in Table 6. From the results listed in Table 6, it is clear that any model that increases assistant loss can significantly improve the overall performance.
在辅助头的辅助损失实验中,我们比较了一般的引导头和辅助头独立标签分配方法,还比较了两种建议的引导引导标签分配方法。表 6 列出了所有比较结果。从表 6 中列出的结果可以看出,任何增加辅助损失的模型都能显著提高整体性能。
 |
|---|
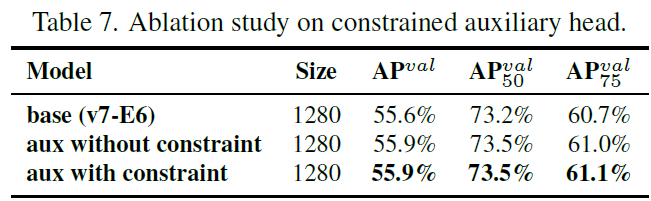
In Table 7 we further compared the results of with/without the introduction of upper bound constraint. Judging from the numbers in the Table, the method of constraining the upper bound of objectness by the distance from the center of the object can achieve better performance.
在表 7 中,我们进一步比较了引入/不引入上限约束的结果。从表中的数字来看,用距离目标中心的距离来约束目标度上界的方法可以取得更好的性能。
 |
|---|
Directly connect auxiliary head to the pyramid in the middle layer for training can make up for information that may be lost in the next level pyramid prediction. To solve this issue, our approach is to connect auxiliary head after one of the sets of feature map before merging cardinality of E-ELAN. Table 8 shows the results obtained using coarse to fine lead guided and partial coarse-to-fine lead guided methods. Obviously, the partial coarse-to-fine lead guided method has a better auxiliary effect.
将辅助头直接连接到中间层的金字塔进行训练,可以弥补下一层金字塔预测可能丢失的信息。为了解决这个问题,我们的方法是在合并 E-ELAN 的 cardinality 之前,在特征图的其中一组之后连接辅助头。表 8 显示了使用corase-fine引导法和部分corase-fine引导法得到的结果。显然,部分corase-fine引导法的辅助效果更好。
 |
|---|
6 Conclusions
In this paper we propose a new architecture of realtime object detector and the corresponding model scaling method. Furthermore, we find that the evolving process of object detection methods generates new research topics. During the research process, we found the replacement problem of re-parameterization module and the allocation problem of dynamic label assignment. To solve the problem, we propose the trainable bag-of-freebies method to enhance the accuracy of object detection. Based on the above, we have developed the YOLOv7 series of object detection systems, which receives the state-of-the-art results.
本文提出了一种新的实时目标检测器架构及相应的模型缩放方法。此外,我们发现目标检测方法的演进过程会产生新的研究课题。在研究过程中,我们发现了重新参数化模块的替换问题和动态标签分配的分配问题。为了解决这个问题,我们提出了可训练的自由包方法,以提高目标检测的准确性。在此基础上,我们开发了 YOLOv7 系列目标检测系统,收到了最先进的效果。
7 Acknowledgements
The authors wish to thank National Center for High performance Computing (NCHC) for providing computational and storage resources.
作者感谢美国国家高性能计算中心(NCHC)提供的计算和存储资源。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









