






大家对数据资产目录都很熟悉,做大数据都知道数据资产和数据资产目录,那么什么是数据编织。
什么是数据编织?
当下,数据是企业数字化转型重要驱动因素,而随着业务的发展,企业的数据环境日趋复杂。在更高程度数字化要求下,企业必须使用一种新型的数据结构来应对企业数据资产日益加剧的多样化、分布式、规模、复杂性等问题。
因此,数据编织(Data Fabric)应运而生。
Gartner认为数据编织是一种跨平台的数据整合方式,它不仅可以集合所有业务用户的信息,还具有灵活且弹性的特点,使得人们可以随时随地使用任何数据。
作为一种新兴的数据管理和处理方法,数据编织能够基于网络架构而不是点对点的连接来处理数据。这实现了从数据源层面到分析、分析结果生成、协调和应用的一体化数据层(结构)。该方法在底层数据组件上设置抽象层,使业务用户可以获得信息和分析结果,而无需进行重复或强制性的数据科学工作。
据Gartner预测:数据编制利用分析功能来持续监控数据管道,通过对数据资产的持续分析,支持各种数据的设计、部署和使用,可以缩短集成时间和部署时间各30%,缩短维护时间70%。从而可以有效解决数据孤岛激增而人才供给不足的问题。
编织在大数据中理解
其实就是通过不同的数据源,将数据形成统一的数据资产的加工过程;
原来我们的数据是这样的架构流程
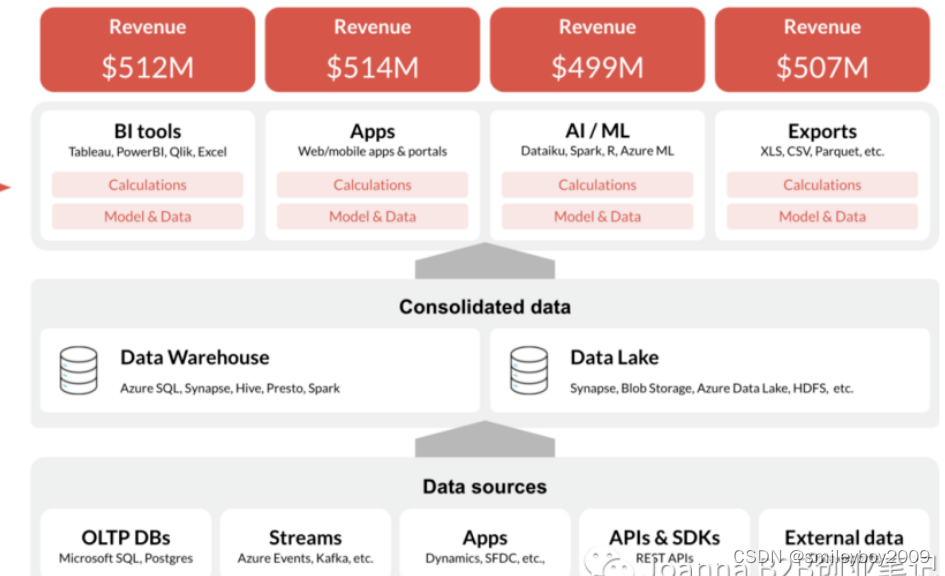
例如:业务的明细数据存储在hbase里面,数仓的数据在hive 中,搜索的数据在ES中,那我想要在es里面搜索,hive关联后的hbase明细数据。 那这个时候,就需要数据编织,就像织布一样,把数据制成一张网,为应用提供服务,或者挂在数据资产目录上面。
有了数据编织以后呢:多了一层API

数据编织目前市场使用的工具:
目前市场用的比较多的两个工具:Denodo 和cube.dev
Denodo 可以组织数据进行数据关联,同时可以生成web service 服务,前端通过调用web service 服务进行查询,省去了java jdbc 连接数据库,可以直接对接报表。
cube.dev 是纯js 的产品,可以选择不同的源,可以自己构建虚拟模型,并且进行关联查询,提供API服务进行查询。
两个产品都是用于数据的编织,目前denodo 不开源,cube.dev 是开源工具。

数据网关
数据通过编织后,生成API 列表,但是要实现高可用,形成资产目录,就需要用到网关服务,在这里介绍两个网关产品:Kong API和 apisix
Kong API 国外用的比较多一些,可以将数据编织后的API注册到服务上。统一进行数据服务查询。














 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









