







 本文详述了曹哲在CVPR2017发表的实时多人人体姿态识别方法,对比了传统自上而下与自下而上的姿态估计方法,重点介绍了Part Affinity Fields(PAFs)在人体关键点检测和连接中的应用。该方法通过深度学习网络同时学习关键点检测和连接,以解决多人姿态估计的效率和准确性问题。
本文详述了曹哲在CVPR2017发表的实时多人人体姿态识别方法,对比了传统自上而下与自下而上的姿态估计方法,重点介绍了Part Affinity Fields(PAFs)在人体关键点检测和连接中的应用。该方法通过深度学习网络同时学习关键点检测和连接,以解决多人姿态估计的效率和准确性问题。
最近学习了曹哲的这篇Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,认真读了,也看了曹哲直播的视频,虽然程序还是看不懂,但也算是学到东西了,写个笔记记录一下,其实大部分也就是直接把论文翻译过来,里面出现的PPT截图也是我之前自己做的,但是不小心存成兼容模式之后文字变成图片了o(╥﹏╥)o,所以就直接截了图,还是希望能和大家多多交流,更好地学习理解这篇论文。
本文的研究目标为给定一张RGB图像,得到所有人体关键点的位置信息,同时知道每一个关键点是属于图片中具体哪个人的,即得到关键点之间的连接信息。具体的效果展示即实时的在视频上对每一帧图像进行检测的结果,并没有做任何的目标追踪,或其他利用时间上的连续性加速这个结果。
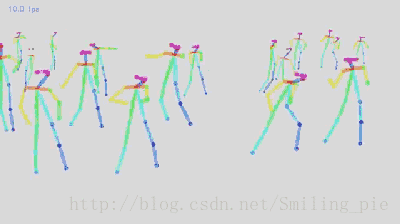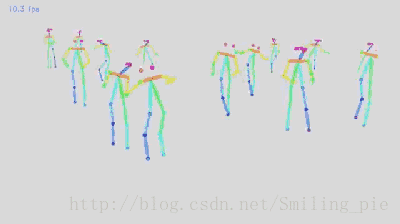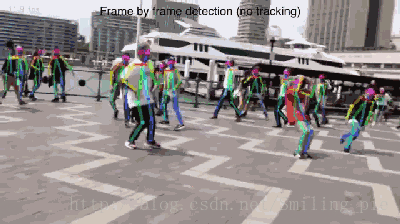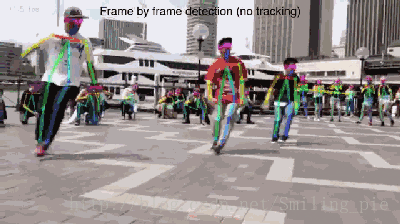
一、与传统多人人体姿态估计方法的对比
论文首先介绍了该方法与传统多人人体姿态估计方法的对比,大多数方法都是采用一种自上而下的方式(Top-down Approach:Person Detection + Pose Estimation),就是给定一张图片,先做人体的检测,在每个人的位置上都得到一个边缘方框信息,在每个方框上,做单人的人体姿态估计,重复这个步骤,直到得到最终的结果。

这种方法存在两个主要的缺陷:
1)十分依赖人体姿态检测的结果(假如说有两个人靠的很近,有的时候会只得到一个方框信息,它的最终结果也会少一个人)
2)算法速度与图片上人的数目成正比,假如说一张图有30个人,它要重复30次单人的人体估计,这样使得这个方法在复杂场景下变得十分缓慢
为改进上述缺陷,该论文采用了一种自下而上的方法(Down-topApproach:PartsDetection + Parts Association),首先检测人关键点的位置,比如图片上人体右肩膀的位置,得到检测结果是通过预测人体关键点的热点图,可以看到在每个人体关键点上都有一个高斯的峰值,代表神经网络相信这里有一个人体的关键点。同样的我们对其他人体关键点比如说右手肘作同样的处理,得到这个检测结果。在得到检测结果之后,对关键点检测结果进行连接,换句话说,就是想知道每个关键点具体是属于图片中哪个人。
对于这个步骤,他们的方法是通过一个新的特征进行推测,这个特征是一个矢量场,叫作人体关键点亲和场(PAFs),在后面会具体介绍这个特征的表示,这里先整体介绍方法的结构。然后重复这个步骤,对另外关键点之间(另外人体的躯干)的连接进行推测,同样是通过人体关键点亲和场来进行推测,重复这个步骤,直到得到人体的全部骨架信息。

二、Jointly Learning Parts Detection and Parts Association
同时对人体关键点检测和关键部位连接进行学习。这个方法主要包括两个部分,第一个部分右侧的分支,人体关键点的检测。第二个部分就是人体关键点的连接。他们的创新点就是设计了一个设计了一个深度学习网络结构,同时学习人体关键点的检测和人体关键点的连接。并且,同时学习会使得他们互相帮助,得到更好的结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









