构建词云图
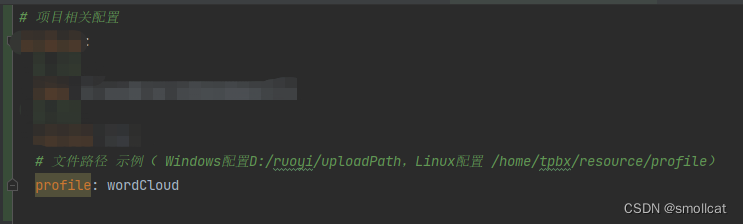
1、配置项
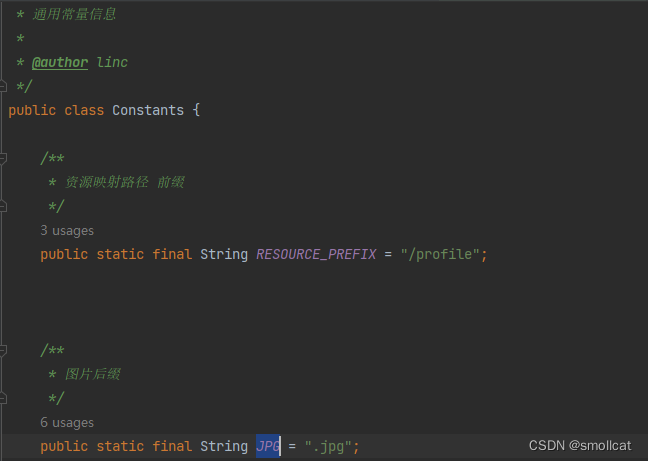
2、常量信息
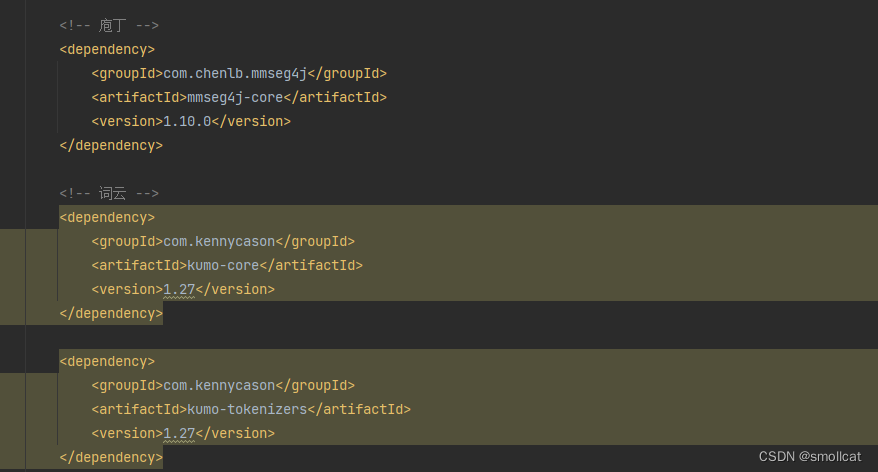
3、依赖包
4、实现过程
package top.cfl.cflwork.common.utils;
import com.chenlb.mmseg4j.*;
import com.chenlb.mmseg4j.Dictionary;
import com.google.common.collect.Lists;
import com.kennycason.kumo.CollisionMode;
import com.kennycason.kumo.WordCloud;
import com.kennycason.kumo.WordFrequency;
import com.kennycason.kumo.bg.CircleBackground;
import com.kennycason.kumo.font.KumoFont;
import com.kennycason.kumo.font.scale.SqrtFontScalar;
import com.kennycason.kumo.nlp.FrequencyAnalyzer;
import com.kennycason.kumo.nlp.tokenizers.ChineseWordTokenizer;
import com.kennycason.kumo.palette.LinearGradientColorPalette;
import org.apache.commons.lang.time.DateFormatUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import top.cfl.cflwork.common.Constants;
import top.cfl.cflwork.config.ArchivesConfig;
import java.awt.*;
import java.io.File;
import java.io.IOException;
import java.io.StringReader;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.util.*;
import java.util.List;
import static top.cfl.cflwork.common.Constants.JPG;
/**
* 词云图
*
* @author linc
*/
@Configuration
public class WordCloudUtils {
@Autowired
private ArchivesConfig archivesConfig;
/**
* 庖丁分词器
*
* @throws UnsupportedEncodingException
*/
public String mMSeg(String txt) throws UnsupportedEncodingException {
StringReader input = new StringReader(txt);
Dictionary dic = Dictionary.getInstance();
Seg seg = new ComplexSeg(dic);//Complex分词
//seg = new SimpleSeg(dic);//Simple分词
MMSeg mmSeg = new MMSeg(input, seg);
Word word;
String wordCloudFilePath = "";
List<String> wordList = Lists.newArrayList();
try {
while ((word = mmSeg.next()) != null) {
//word是单个分出的词,先放到List里下面统一按竖线拼接词打印出来
wordList.add(word.getString());
}
} catch (IOException e) {
e.printStackTrace();
} finally {
input.close();
}
if (wordList.size() > 0) {
wordCloudFilePath = wordCloud(wordList);
}
return wordCloudFilePath;
}
/**
* 词云
*
* @param wordList
* @return path
* @throws UnsupportedEncodingException
*/
public String wordCloud(List<String> wordList) throws UnsupportedEncodingException {
FrequencyAnalyzer frequencyAnalyzer = new FrequencyAnalyzer();
frequencyAnalyzer.setWordFrequenciesToReturn(600);
frequencyAnalyzer.setMinWordLength(2);
frequencyAnalyzer.setWordTokenizer(new ChineseWordTokenizer());
// 可以直接从文件中读取
//List<WordFrequency> wordFrequencies = frequencyAnalyzer.load(getInputStream("WordList.txt"));
List<WordFrequency> wordFrequencies = new ArrayList<>();
// 用词语来随机生成词云
String strValue = frequencyOfListW(wordList).toString();
String replace = strValue.replace("{", "");
String strValueNew = replace.replace("}", "");
//以逗号为分割号
String[] strSplit = strValueNew.split(", ");
String word = "";
int count = 0;
for (int i = 0; i < strSplit.length; i++) {
String[] wordInfo = strSplit[i].split("=");
word = wordInfo[0];
count = Integer.valueOf(wordInfo[1]);
wordFrequencies.add(new WordFrequency(word, count));
}
//加入分词并随机生成权重,每次生成得图片都不一样
// wordList.stream().forEach(e -> wordFrequencies.add(new WordFrequency(e, new Random().nextInt(wordList.size()))));
//此处不设置会出现中文乱码
java.awt.Font font = new java.awt.Font("STSong-Light", 2, 18);
//设置图片分辨率
Dimension dimension = new Dimension(500, 500);
//此处的设置采用内置常量即可,生成词云对象
WordCloud wordCloud = new WordCloud(dimension, CollisionMode.PIXEL_PERFECT);
//设置边界及字体
wordCloud.setPadding(2);
//因为我这边是生成一个圆形,这边设置圆的半径
wordCloud.setBackground(new CircleBackground(255));
wordCloud.setFontScalar(new SqrtFontScalar(12, 42));
//设置词云显示的三种颜色,越靠前设置表示词频越高的词语的颜色
wordCloud.setColorPalette(new LinearGradientColorPalette(Color.RED, Color.BLUE, Color.GREEN, 30, 30));
wordCloud.setKumoFont(new KumoFont(font));
wordCloud.setBackgroundColor(new Color(255, 255, 255, 0));
//因为我这边是生成一个圆形,这边设置圆的半径
wordCloud.setBackground(new CircleBackground(255));
wordCloud.build(wordFrequencies);
//生成词云图路径
System.out.println(archivesConfig.getProfile() + "+路径");
String filePath = URLDecoder.decode(archivesConfig.getProfile(), "UTF-8");//如果路径中带有中文会被URLEncoder,因此这里需要解码
System.out.println(filePath);
String fileName = "/wordCloud" + getDate() + ".png";
String filePath1 = filePath + fileName;
wordCloud.writeToFile(filePath1);
String wordCloudFilePath = Constants.RESOURCE_PREFIX + fileName;
return wordCloudFilePath;
}
/**
* 获取当天日期
* @return
*/
public String getDate() {
Date now = new Date(); // 创建一个Date对象,获取当前时间
String strDateFormat = "yyyyMMdd";
return DateFormatUtils.format(now, strDateFormat);
}
/**
* 判断文件是否存在
* @return
*/
public boolean isExist() {
File file = new File(getCurrentDayWordCloudPath());
boolean exists = file.exists();
return exists;
}
/**
* 获取问卷地址
* @return
*/
public String getCurrentDayWordCloudPath() {
String folder = System.getProperty("user.dir") + "\\" + archivesConfig.getProfile();
String fileName = "/wordCloud" + getDate() + JPG;
String absolutePath = folder + "\\" + fileName;
return absolutePath;
}
/**
* 适用于 jdk 1.8及以下,统计List集合中每个元素出现的次数
* 例如frequencyOfListElements(["111","111","222"])
* ->
* 则返回Map {"111"=2,"222"=1}
*
* @param items
* @return Map<String, Integer>
* @author wuqx
*/
public Map<String, Integer> frequencyOfListW(List<String> items) {
Map<String, Integer> map = new HashMap<>();
if (items == null || items.size() == 0) {
return map;
}
for (String k : items) {
Integer counts = map.get(k);
map.put(k, (counts == null) ? 1 : ++counts);
}
int sum = 0;
int total = 0;
Collection values = map.values();
for (Object object : values) {
total = total + Integer.parseInt(object.toString());
sum += 1;
}
int avg = total / sum;
Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, Integer> entry = it.next();
if (entry.getValue() < avg)
it.remove();//使用迭代器的remove()方法删除元素
}
return map;
}
}
























 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









