










作为一款APM和全链路监控平台,Skywalking算是挺出色的。Skywalking是APM监控平台的后起之秀,大有超越其他开源APM监控平台的趋势。它通过探针自动收集所需的指标,并进行分布式追踪。通过这些调用链路以及指标,Skywalking APM会感知应用间关系和服务间关系,并进行相应的指标统计。
目前Skywalking支持h2、mysql、ElasticSearch作为数据存储,我就说一下,这三个种库的优缺点和使用要求:
1、首先是默认的h2
h2是Skywalking自带的,对应的jar包路径是Skywalking/oap-libs/h2-1.4.196.jar,h2是一种内存数据库,在Skywalking配置文件的默认配置如下:
h2:
driver: ${SW_STORAGE_H2_DRIVER:org.h2.jdbcx.JdbcDataSource}
url: ${SW_STORAGE_H2_URL:jdbc:h2:mem:skywalking-oap-db}
user: ${SW_STORAGE_H2_USER:sa}
metadataQueryMaxSize: ${SW_STORAGE_H2_QUERY_MAX_SIZE:5000}作为内存数据库,当然是保存在内存中,只要服务重启或是Skywalking应用故障了,基本上所监控到的数据也就丢失了,所以h2的内存模式其实不适合于应用服务长时间监控的场景。但是h2也可以变为文件数据库,配置如下:
h2:
driver: ${SW_STORAGE_H2_DRIVER:org.h2.jdbcx.JdbcDataSource}
url: ${SW_STORAGE_H2_URL:jdbc:h2:tcp://127.0.0.1/~/skywalking-oap-db;AUTO_SERVER=TRUE}
user: ${SW_STORAGE_H2_USER:sa}
metadataQueryMaxSize: ${SW_STORAGE_H2_QUERY_MAX_SIZE:5000}和内存模式的配置区别就是URL换成了文件的路径,默认路径是在用户目录下(如administrator或root或home/user等用户目录)自动创建数据库文件skywalking-oap-db。
要使用文件数据库,有个前提是要先启动h2的TCP服务,因为默认skywalking调用的是内存数据库,如果没有启动h2 TCP,由于监听不到端口,oapService就会判断为连接故障而关闭。启动h2 TCP服务,可以在bin目录新建启动脚本,linux脚本如下:
#!/usr/bin/env sh
PRG="$0"
PRGDIR=`dirname "$PRG"`
[ -z "$OAP_HOME" ] && OAP_HOME=`cd "$PRGDIR/.." >/dev/null; pwd`
OAP_LOG_DIR="${OAP_HOME}/logs"
JAVA_OPTS=" -Xms64M -Xmx256M"
if [ ! -d "${OAP_HOME}/logs" ]; then
mkdir -p "${OAP_LOG_DIR}"
fi
_RUNJAVA=${JAVA_HOME}/bin/java
[ -z "$JAVA_HOME" ] && _RUNJAVA=java
CLASSPATH="$OAP_HOME/config:$CLASSPATH"
for i in "$OAP_HOME"/oap-libs/h2*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
OAP_OPTIONS=" -Doap.logDir=${OAP_LOG_DIR}"
# 如果需要远程连接h2数据库,需将-tcp改为-tcpAllowOthers
eval exec "\"$_RUNJAVA\" ${JAVA_OPTS} ${OAP_OPTIONS} -classpath $CLASSPATH org.h2.tools.Server -tcp \
2>${OAP_LOG_DIR}/h2Tcp.log 1> /dev/null &"
if [ $? -eq 0 ]; then
sleep 1
echo "SkyWalking h2Tcp started successfully!"
else
echo "SkyWalking h2Tcp started failure!"
exit 1
fi对应的windows脚本如下:
@REM 如果需要远程查看h2数据库(tcp端口9092,页面访问端口8082),需将-tcp改为-tcpAllowOthers
@echo off
setlocal
set OAP_PROCESS_TITLE=Skywalking-H2TcpServer
set OAP_HOME=%~dp0%..
set OAP_OPTS="-Xms64M -Xmx256M -Doap.logDir=%OAP_HOME%\logs"
set CLASSPATH=%OAP_HOME%\config;.;
set CLASSPATH=%OAP_HOME%\oap-libs\*;%CLASSPATH%
if defined JAVA_HOME (
set _EXECJAVA="%JAVA_HOME%\bin\java"
)
if not defined JAVA_HOME (
echo "JAVA_HOME not set."
set _EXECJAVA=java
)
start "%OAP_PROCESS_TITLE%" %_EXECJAVA% "%OAP_OPTS%" -cp "%CLASSPATH%" org.h2.tools.Server -tcp
endlocal先启动h2文件数据库,确保9092端口能被监听,再启动Skywalking的其他服务。
h2文件数据库虽然非常轻量级,毕竟skywalking自带了,但是稳定性却很差,一但文件损坏(大并发量和大吞吐量的监控数据,就会把它干坏),oapService服务就启动不了了,需要清除文件或是恢复及覆盖文件才能启动(对于一般应用者来说,这也是要命的事)。
2、Mysql数据库
启用mysql存储,有两个地方需要配置,一个是application.yml
mysql:
metadataQueryMaxSize: ${SW_STORAGE_H2_QUERY_MAX_SIZE:5000}另一个是datasource-settings.properties
jdbcUrl=jdbc:mysql://localhost:3306/swtest
dataSource.user=root
dataSource.password=root@1234mysql数据库相对要稳定,毕竟是被大量使用的数据库,而且可以做相应的优化,配置缓存,加大数据吞吐量。但是基于mysql的查询速度我觉得不快,特别是skywalking中【追踪】查看,3万条以上的记录查询基本上觉得卡。但作为长时间的应用性能监控来说,mysql合适。而对于Linux下的部署来说,mysql偏重量级了(编译后的二进制mysql安装包就有好几百M)。
3、ElasticSearch
官网好像是推荐使用ElasticSearch,为什么推荐?我猜的,应该是快呀。ES(ElasticSearch)是一款分布式全文检索框架,底层基于Lucene实现,是给搜索引擎专用的,不快都不行。试了一下10万条的追踪记录,基本上很快就能查询展示。
ElasticSearch不是自带的,需要安装,考虑到轻量级,我选用的是elasticsearch-6.2.4,原因是包小免安装,解压完也才30多M,而且目前最新版本的Skywalking 6.2.0是能够支持该版本的ElasticSearch。
Skywalking启用ES,只需要配置文件设置如下:
storage:
elasticsearch:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:2}
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}
# Those data TTL settings will override the same settings in core module.
recordDataTTL: ${SW_STORAGE_ES_RECORD_DATA_TTL:7} # Unit is day
otherMetricsDataTTL: ${SW_STORAGE_ES_OTHER_METRIC_DATA_TTL:45} # Unit is day
monthMetricsDataTTL: ${SW_STORAGE_ES_MONTH_METRIC_DATA_TTL:18} # Unit is month
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:2000} # Execute the bulk every 2000 requests
bulkSize: ${SW_STORAGE_ES_BULK_SIZE:20} # flush the bulk every 20mb
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10} # flush the bulk every 10 seconds whatever the number of requests
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}另外如果,想让ES能同时被本地和远程访问到,可以改一下ES的配置文件,IP改为如下:
network.host: 0.0.0.0我专门写了linux下的ES启动脚本(脚本放在skywalking的bin目录下,ES放在Skywalking的根目录下),由于ES不能以root用户启动,所以脚本里加了用户的自动创建:
#!/bin/bash
check_user()
{
#判断用户是否存在passwd中
i=`cat /etc/passwd | cut -f1 -d':' | grep -w "$1" -c`
if [ $i -le 0 ]; then
echo "User $1 is not in the passwd"
return 0
else
#显示用户存在
echo "User $1 is in then use"
return 1
fi
}
uname=elsearch
check_user $uname
if [ $? -eq 0 ]
then
#添加此用户
sudo useradd $uname
passwd $uname --stdin "123456"
echo "user $uname add!!!"
fi
Cur_Dir=$(cd "$(dirname "$0")"; pwd)
chown $uname:$uname -R $Cur_Dir/../elasticsearch
chmod -R 766 $Cur_Dir/../elasticsearch
chmod -R 777 $Cur_Dir/../elasticsearch/bin
su - $uname -c "nohup $Cur_Dir/../elasticsearch/bin/elasticsearch > $Cur_Dir/../elasticsearch/logs/output.log 2>&1 &"
echo "elasticsearch start success!"考虑到ES也是需要先启动,确保端口监听正常了,才能启动oapService,所以我改造了skywalking自带的启动脚本,加了端口监听判断:
#!/usr/bin/env sh
check_port()
{
grep_port=`netstat -tlpn | grep "\b$1\b"`
echo "grep port is $grep_port"
if [ -n "$grep_port" ]
then
echo "port $port is in use"
return 1
else
echo "port is not established,please wait a moment......"
return 0
fi
}
PRG="$0"
PRGDIR=`dirname "$PRG"`
OAP_EXE=oapService.sh
WEBAPP_EXE=webappService.sh
elsearch_EXE=elasticsearchStart.sh
"$PRGDIR"/"$elsearch_EXE"
port=9200
echo "check $port"
for i in $(seq 1 20)
do
check_port $port
if [ $? -eq 0 ]
then
sleep 2s
else
break
fi
done
"$PRGDIR"/"$OAP_EXE"
"$PRGDIR"/"$WEBAPP_EXE"Windows下的脚本就简单多了:
@echo off
setlocal
set OAP_PROCESS_TITLE=Skywalking-Elasticsearch
set OAP_HOME=%~dp0%..
start "%OAP_PROCESS_TITLE%" %OAP_HOME%\elasticsearch\bin\elasticsearch.bat
endlocal而且windows下启动ES很快,没有端口启动的延时时间,所以整个skywalking启动脚本的改造量不大:
@echo off
setlocal
call "%~dp0"\elasticsearchUp.bat
call "%~dp0"\oapService.bat start
call "%~dp0"\webappService.bat start
endlocal以上的准备,就是为Skywalking应用ES存储做好了准备,但是Elasticsearch本身也是存在写入瓶颈的,也就是说ES也会崩溃,一但崩溃,就可能oapService关闭,或是导致skywalking页面大盘空白。
我们可以做些调优,skywalking写入ES的操作是使用了ES的批量写入接口。我们可以调整这些批量的维度。尽量降低ES索引的写入频率,如:
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:4000} # Execute the bulk every 2000 requests
bulkSize: ${SW_STORAGE_ES_BULK_SIZE:40} # flush the bulk every 20mb
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:30} # flush the bulk every 10 seconds whatever the number of requests
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:4} # the number of concurrent requests
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:8000}调整bulkActions默认2000次请求批量写入一次改到4000次;bulkSize批量刷新从20M一次到40M一次;flushInterval每10秒刷新一次堆改为每30秒刷新;concurrentRequests查询的最大数量由5000改为8000。这种配置调优确实生效了,重启服务后两三天了都没有出现过ES写入阻塞的问题。不过这种设置只是暂时的,你只能期望流量不突发,或者应用不增加。一旦遇到突发流量和应用的增加,ES写入瓶颈还是会凸显出来。而且参数设置过大带来了一个新的问题,就是数据写入延时会比较大,一次服务交互发生的trace隔好久才能在skywalking页面上查询到。所以最终解决方案是优化ES的写入性能,具体优化可以参考别人的文章:https://www.easyice.cn/archives/207
另外作为开源化的平台,扩展性也是其中的优势,本身ES就是分布式全文检索框架,可以部署成高可用的集群,另外Skyawalking也是分布式链路跟踪系统,分布式既然是它应用的特性,那么怎么去构建集群化的监控平台,就完全靠你自己的想象和发挥了。
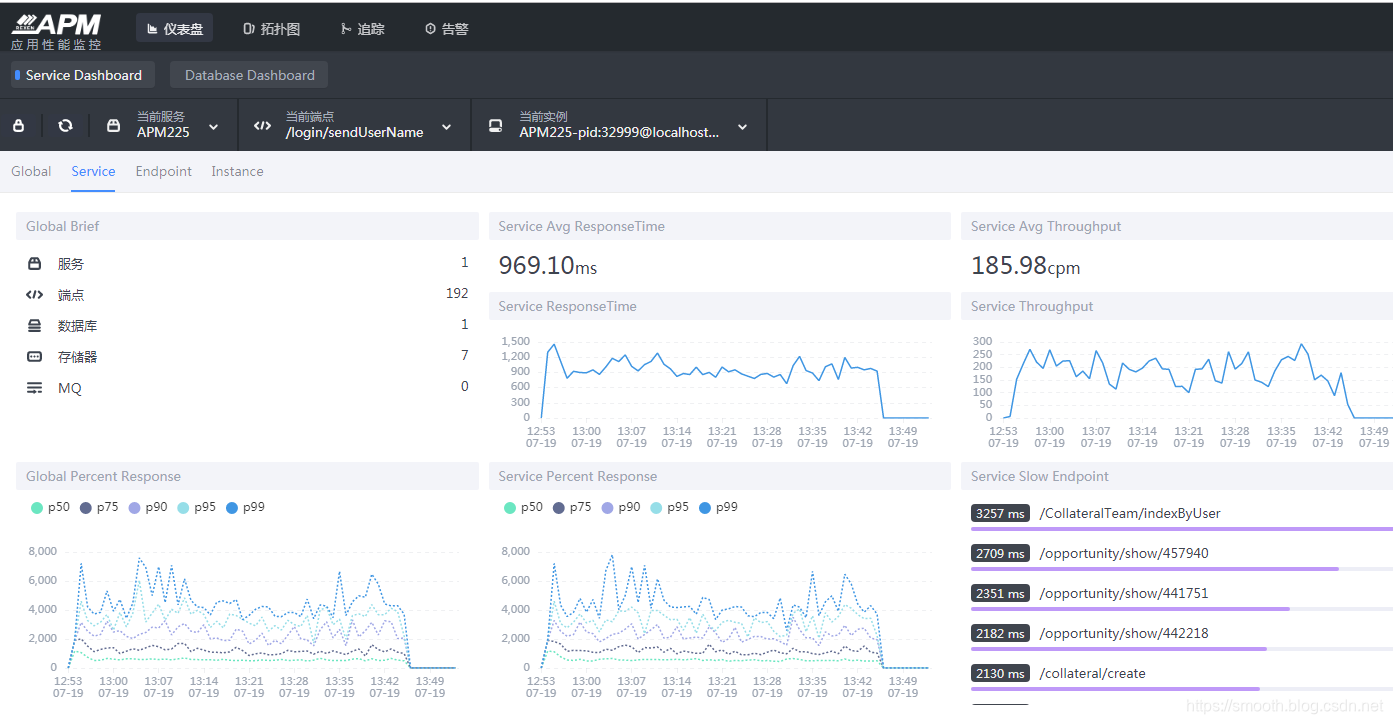
最后放一张我的Skywalking监控平台的监控效果图(压测过程中的应用监控),我可是斗胆把人家的Logo都换了,但我可不会用在商用领域,只是部门内部使用,方便其他人一眼认出这是个APM监控平台:
另外附上Skywalking各模块完整的配置说明(为看不明白英文注释的人准备):
(1)Skywalking collector 配置
OAP(Collector)链路数据归集器,主要用于数据落地,大部分都会选择 Elasticsearch 6,OAP配置文件为 /opt/apache-skywalking-apm-6.2.0/config/application.yml,配置单点的 OAP(Collector)配置如下:
cluster:
# 单节点模式
standalone:
# zk用于管理collector集群协作.
# zookeeper:
# 多个zk连接地址用逗号分隔.
# hostPort: localhost:2181
# sessionTimeout: 100000
# 分布式 kv 存储设施,类似于zk,但没有zk重型(除了etcd,consul、Nacos等都是类似功能)
# etcd:
# serviceName: ${SW_SERVICE_NAME:"SkyWalking_OAP_Cluster"}
# 多个节点用逗号分隔, 如: 10.0.0.1:2379,10.0.0.2:2379,10.0.0.3:2379
# hostPort: ${SW_CLUSTER_ETCD_HOST_PORT:localhost:2379}
core:
default:
# 混合角色:接收代理数据,1级聚合、2级聚合
# 接收者:接收代理数据,1级聚合点
# 聚合器:2级聚合点
role: ${SW_CORE_ROLE:Mixed} # Mixed/Receiver/Aggregator
# rest 服务地址和端口
restHost: ${SW_CORE_REST_HOST:localhost}
restPort: ${SW_CORE_REST_PORT:12800}
restContextPath: ${SW_CORE_REST_CONTEXT_PATH:/}
# gRPC 服务地址和端口
gRPCHost: ${SW_CORE_GRPC_HOST:localhost}
gRPCPort: ${SW_CORE_GRPC_PORT:11800}
downsampling:
- Hour
- Day
- Month
# 设置度量数据的超时。超时过期后,度量数据将自动删除.
# 单位分钟
recordDataTTL: ${SW_CORE_RECORD_DATA_TTL:90}
# 单位分钟
minuteMetricsDataTTL: ${SW_CORE_MINUTE_METRIC_DATA_TTL:90}
# 单位小时
hourMetricsDataTTL: ${SW_CORE_HOUR_METRIC_DATA_TTL:36}
# 单位天
dayMetricsDataTTL: ${SW_CORE_DAY_METRIC_DATA_TTL:45}
# 单位月
monthMetricsDataTTL: ${SW_CORE_MONTH_METRIC_DATA_TTL:18}
storage:
elasticsearch:
# elasticsearch 的集群名称
nameSpace: ${SW_NAMESPACE:"local-ES"}
# elasticsearch 集群节点的地址及端口
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:192.168.2.10:9200}
# elasticsearch 的用户名和密码
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
# 设置 elasticsearch 索引分片数量
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:2}
# 设置 elasticsearch 索引副本数
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}
# 批量处理配置
# 每2000个请求执行一次批量
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:2000}
# 每 20mb 刷新一次内存块
bulkSize: ${SW_STORAGE_ES_BULK_SIZE:20}
# 无论请求的数量如何,每10秒刷新一次堆
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10}
# 并发请求的数量
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2}
# elasticsearch 查询的最大数量
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
# elasticsearch 查询段最大数量
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200} (2)Skywalking webApp 配置
Skywalking 的 WebApp 主要是用来展示落地的数据,因此只需要配置 Web 的端口及获取数据的 OAP(Collector)的IP和端口,webApp 配置文件地址为 /opt/apache-skywalking-apm-6.2.0/webapp/webapp.yml 配置如下:
server:
port: 9000
collector:
path: /graphql
ribbon:
ReadTimeout: 10000
# 指向所有后端collector 的 restHost:restPort 配置,多个使用, 分隔
listOfServers: localhost:12800
security:
user:
# username
admin:
# password
password: admin(3)Skywalking Agent 配置
Skywalking 的 Agent 主要用于收集和发送数据到 OAP(Collector),因此需要进行配置 Skywalking OAP(Collector)的地址,Agent 的配置文件地址为 /opt/apache-skywalking-apm-6.2.0/agent/config/agent.config,配置如下:
# 设置Agent命名空间,它用来隔离追踪和监控数据,当两个应用使用不同的名称空间时,跨进程传播链会中断。
agent.namespace=${SW_AGENT_NAMESPACE:default-namespace}
# 设置服务名称,会在 Skywalking UI 上显示的名称
agent.service_name=${SW_AGENT_NAME:Your_ApplicationName}
# 每 3秒采集的样本跟踪比例,如果是负数则表示 100%采集
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:-1}
# 启用 Debug ,如果为 true 则将把所有检测到的类文件保存在"/debug"文件夹中
# agent.is_open_debugging_class = ${SW_AGENT_OPEN_DEBUG:true}
# 后端的 collector 端口及地址
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.2.215:11800}
# 日志级别
logging.level=${SW_LOGGING_LEVEL:DEBUG}


















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











