






我编写了一段简单的代码,用Pandas的melt函数将宽数据转换为长数据,基本思路为将所有非数值型列作为变量。这段代码可以用于绝大多数经济领域宽面板数据(id+year)的处理,为Powerquery不好使等特定情况设计,以满足一些特定需求,比如使用SPSS分析前的数据预处理。
代码如下:
import pandas as pd
import numpy as np # 导入NumPy,用np.number来确定非数值型列
def convert_wide_to_long(input_file_path, output_file_path, id_vars=None):
"""
这段代码可以将绝大多数列为非数值型变量的宽面板数据Excel文件转换为长面板数据Excel文件,以便于在SPSS等数据分析软件中进行处理。
参数:
- input_file_path: 输入文件的路径(Excel文件)
- output_file_path: 输出文件的路径(Excel文件)
- id_vars: 要保持为行索引的列名列表,默认为None,99%的情况下用np.number自动确定就行了,手动调整太麻烦
"""
# 读取Excel文件
df = pd.read_excel(input_file_path)
# 宽面板需要提前整理好,列需要是非数值型的变量,如果是数值型变量(比如年份)的话,在Excel里整体转置一下!列变量可以是X1、X2,或者安徽省、北京市等等
id_vars = df.select_dtypes(exclude=[np.number]).columns.tolist()
# 使用melt函数进行转换
long_df = df.melt(id_vars=id_vars, var_name='variable', value_name='value')
# 将结果写回Excel文件
long_df.to_excel(output_file_path, index=False)
# 下面是需要自己修改的部分
input_path = '/2900 数据集/007 中国省级财政透明度合并/2007-2021省级财政透明度修正.xlsx' # 更改为你的输入文件路径
output_path = '/2900 数据集/007 中国省级财政透明度合并/2007-2021省级财政透明度修正_convert.xlsx' # 更改为你的输出文件路径
# 如果不想覆盖原文件的话,可以在输出文件路径里改一下文件名,比如像我一样在原文件名后面加一个_convert的后缀作标识
convert_wide_to_long(input_path, output_path)虽然SPSS也可以使用数据重构功能将宽数据转换为长数据,但在处理year这种数值型变量时会遇到两个问题:
第一,纯数字的年份YYYY不能作为有效的变量名导入SPSS,导入时会改写变量名为@YYYY的形式,无法调整。
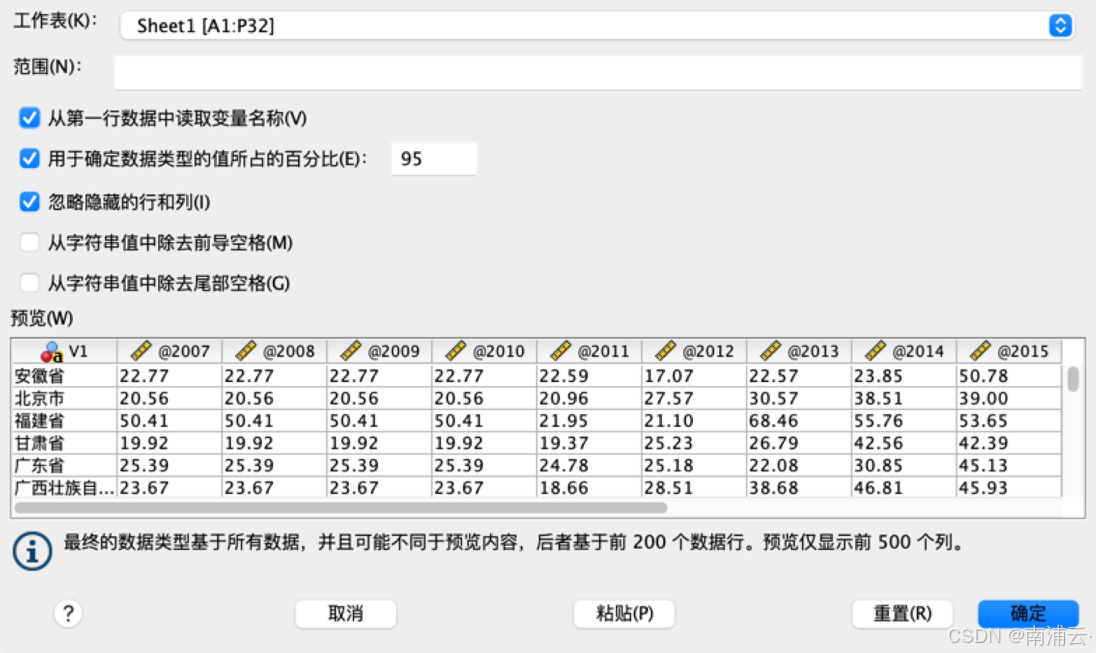
第二,在用数据重构功能创建索引变量时,软件会把YYYY改写为连续数字序列,或者@YYYY形式的变量名。无论哪种形式,这样创建出来的变量组成的长数据和其他长数据(部分原始数据获取时就是长数据)都不能直接比较。
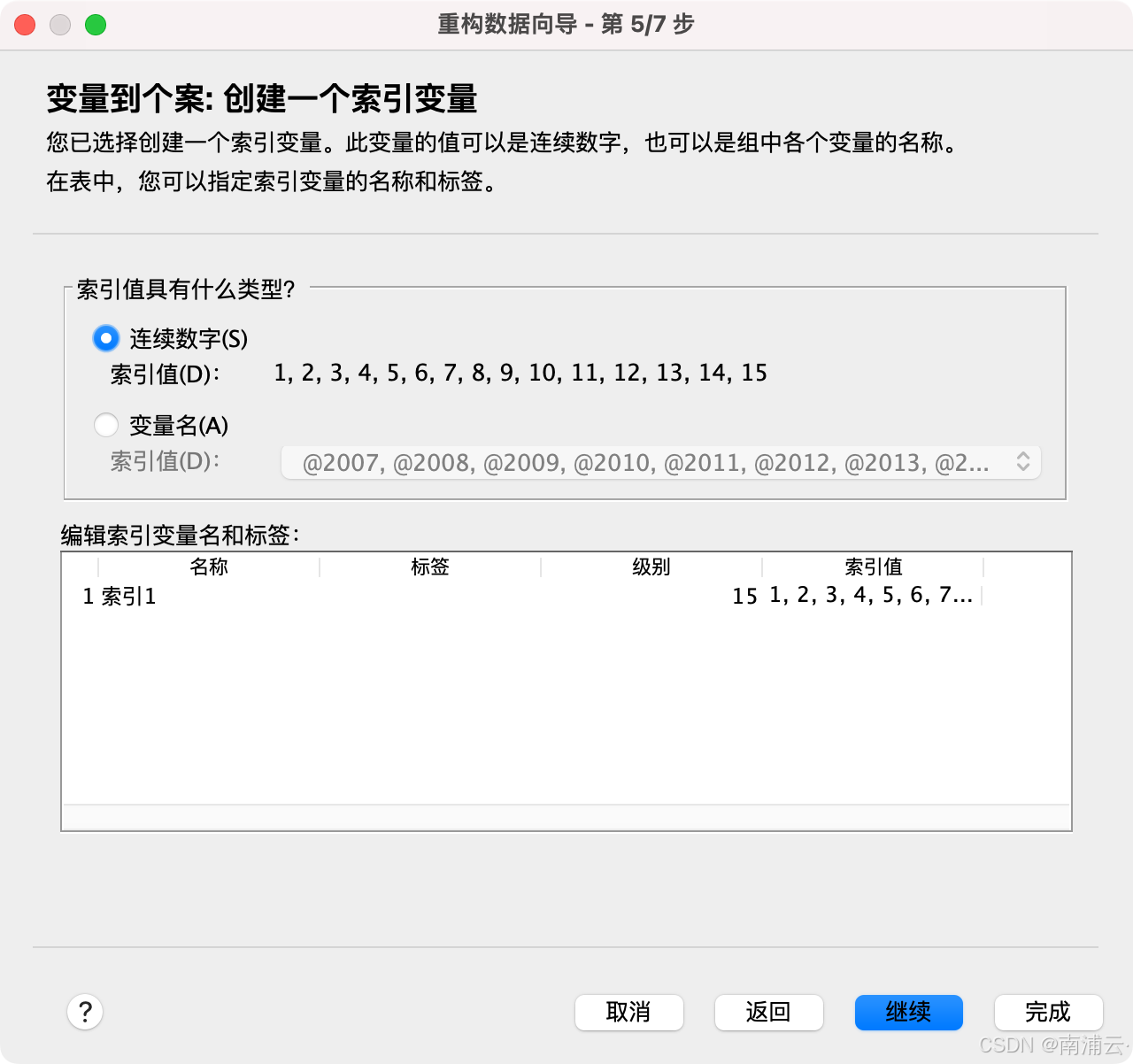
所以,对于经济领域常见的id+year宽面板数据,用SPSS的数据重构功能进行转换可能并不是一个好方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









