









 文章讲述了如何使用StableDiffusion进行AI绘图,特别是创建机甲狂暴男的过程,强调了人物骨骼定位、提示词选择、参数调整以及图生图技术的重要性。作者指出,理解参数和具备美术基础能更好地控制AI生成的图像。
文章讲述了如何使用StableDiffusion进行AI绘图,特别是创建机甲狂暴男的过程,强调了人物骨骼定位、提示词选择、参数调整以及图生图技术的重要性。作者指出,理解参数和具备美术基础能更好地控制AI生成的图像。
S:你安装stable diffusion就是为了看小姐姐么?
I :当然不是,当然是为了公司的发展谋出路~~
预先学习:
- 安装及其问题解决参考:《Windows安装Stable Diffusion WebUI及问题解决记录》;
- 运行使用时问题《Windows使用Stable Diffusion时遇到的各种问题整理》;
- 模型运用及参数《Stable Diffusion 个人推荐的各种模型及设置参数、扩展应用等合集》;
- 提示词生图咒语《AI绘图提示词/咒语/词缀/关键词使用指南(Stable Diffusion Prompt 设计师操作手册)》;
- 不同类的模型Models说明《解析不同种类的StableDiffusion模型Models》;
- 绘制人物动作及手脚细节《Stable Diffusion 准确绘制人物动作及手脚细节(需ControlNet扩展)》;
- 各种风格对比及实际运用《AI绘图风格对照表/画风样稿详细研究记录及经验总结》;
stable diffusion就只能小姐姐么?不,今天我们用stable diffusion绘制一个机甲狂暴男。
起因是有大神说ai无法达到人的绘制水平,我不服,因为我确实没法达到。。。。哈哈,这样,我正好拿他的草图来渲染一个机甲狂暴男了。

一、确定人物骨骼
-
在openpose中标识人物骨骼
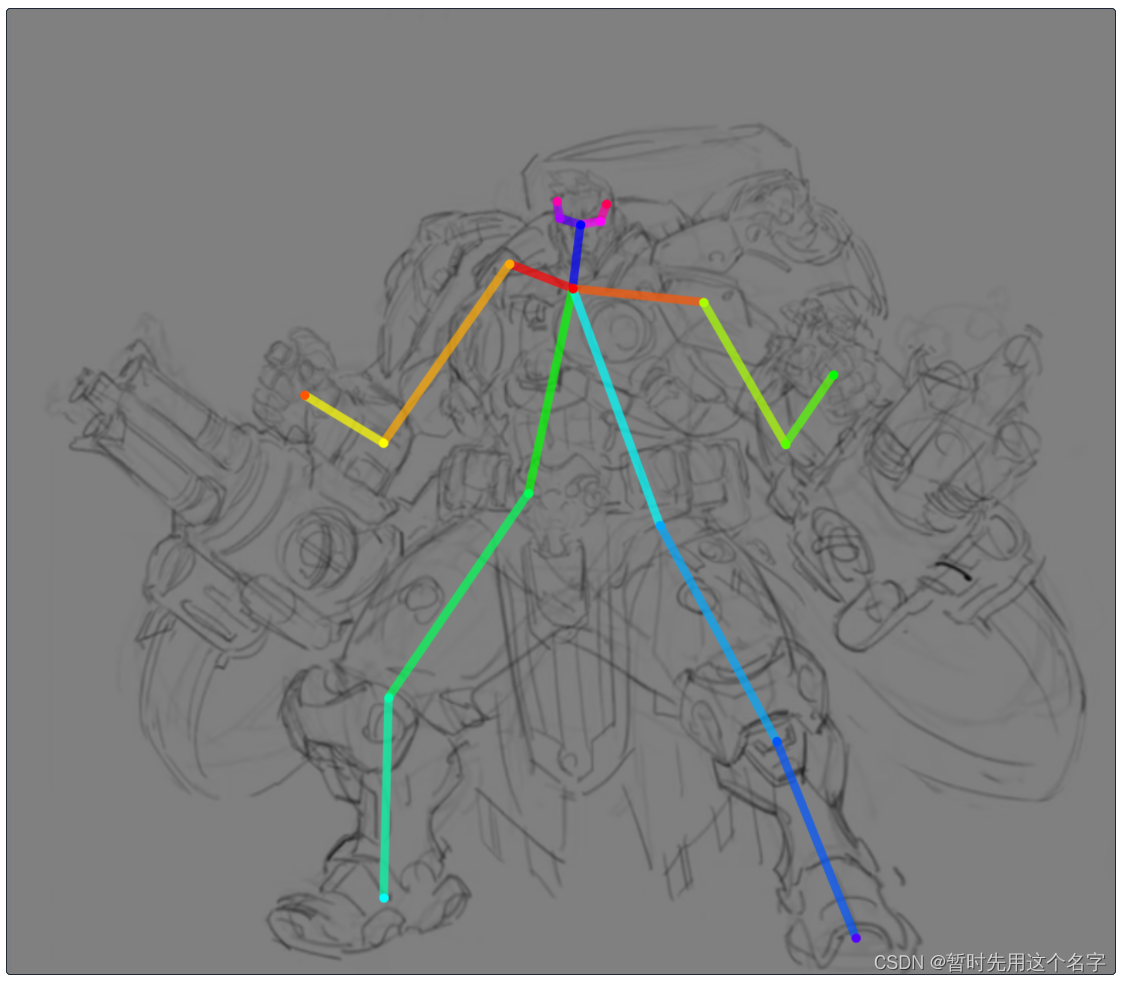
-
标示完成后,另存png在文生图模式的controlnet中导入
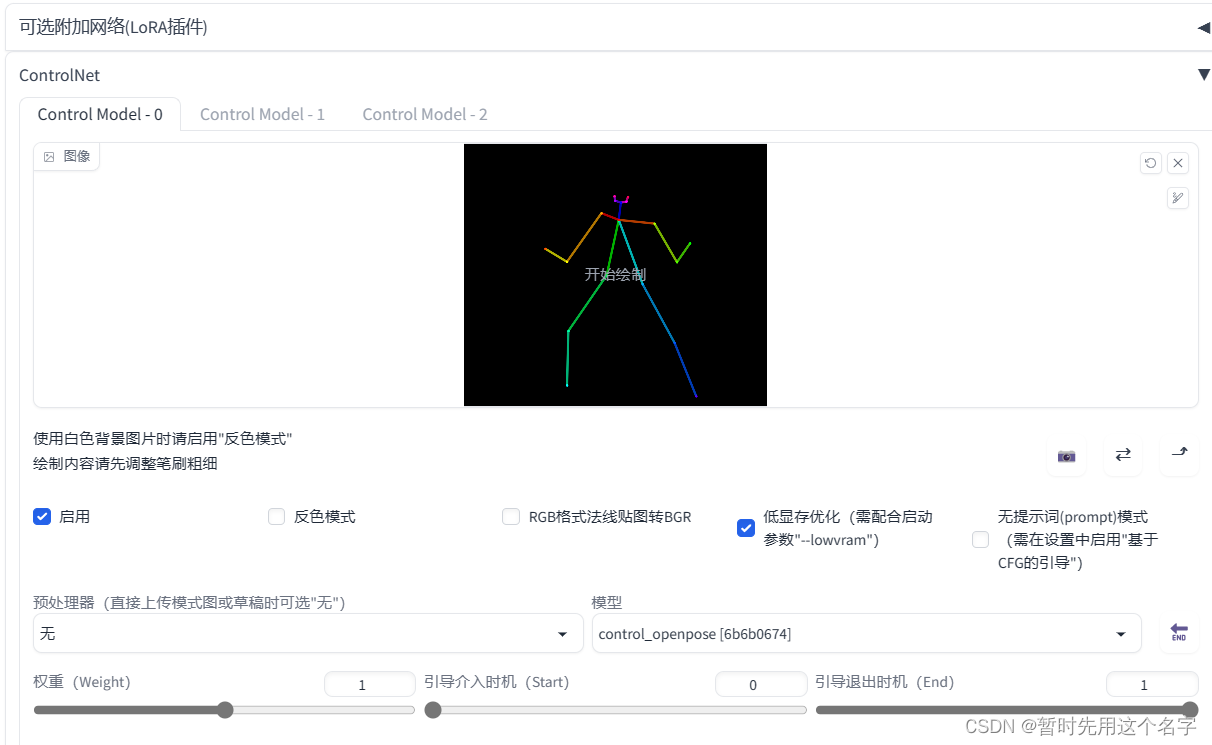
- 使用边缘控制,否则出的图可能只会有变形金刚~~
预览可以让你知道参数调成什么样子是你所需的。
二、加入提示词
提示词相关性(CFG Scale)数值可以拉高一些,让提示词尽可能实现,我这次用了25。
((mecha style)),8k, realistic, strong sharp, highlights, obvious refraction, ((mecha driver is wearing armor with an exposed head)), (short hair and bread), groin protector, (left arm with M134 Minigun)(right arm with M134 Minigun), (magazine is from M134 Minigun to giant iron), chest flash, a giant iron barrel on back, heavy mecha, wearing mecha, buildings,
- 注意controlnet的权重不要过低,否则可能由于提示词中的词缀权重更强,从而导致出图的动作和细节会有偏差。

- 出一张512的图,为什么是这个大小呢?因为分辨率高了以后我目前模型给的就是变形金刚。。。

当时的参数如下,如果

想着是不是重绘幅度太高了,修复采样太低导致,于是改为

出图就是没完成。。。

可能是出bug或者有别的地方没调整好,不管了,我们现在就直接图生图吧。
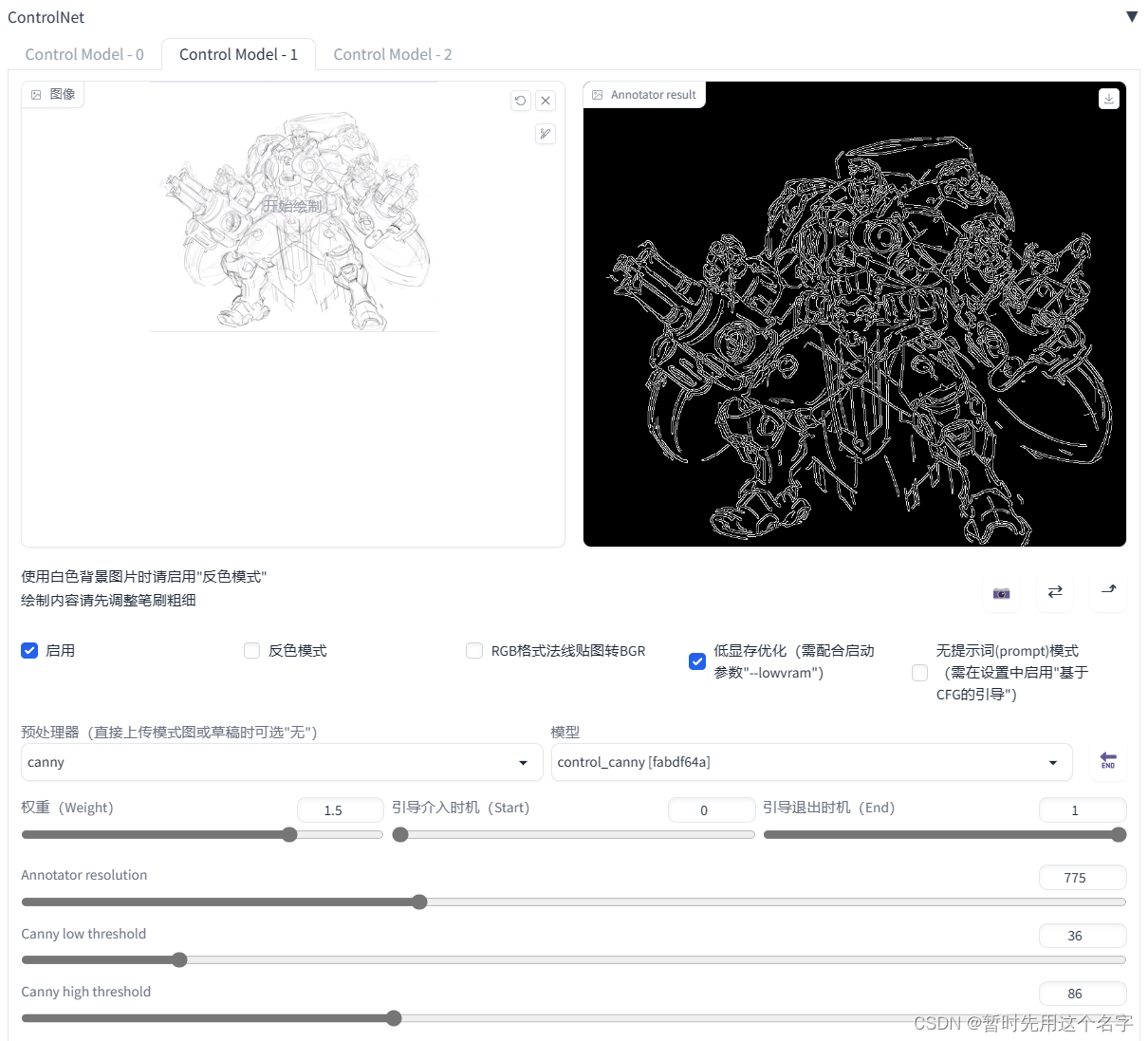
三、图生图
-
只能使用直接缩放,否则我的显存完全不够。
图生图的时候记住用controlnet界定一下边缘和骨骼。
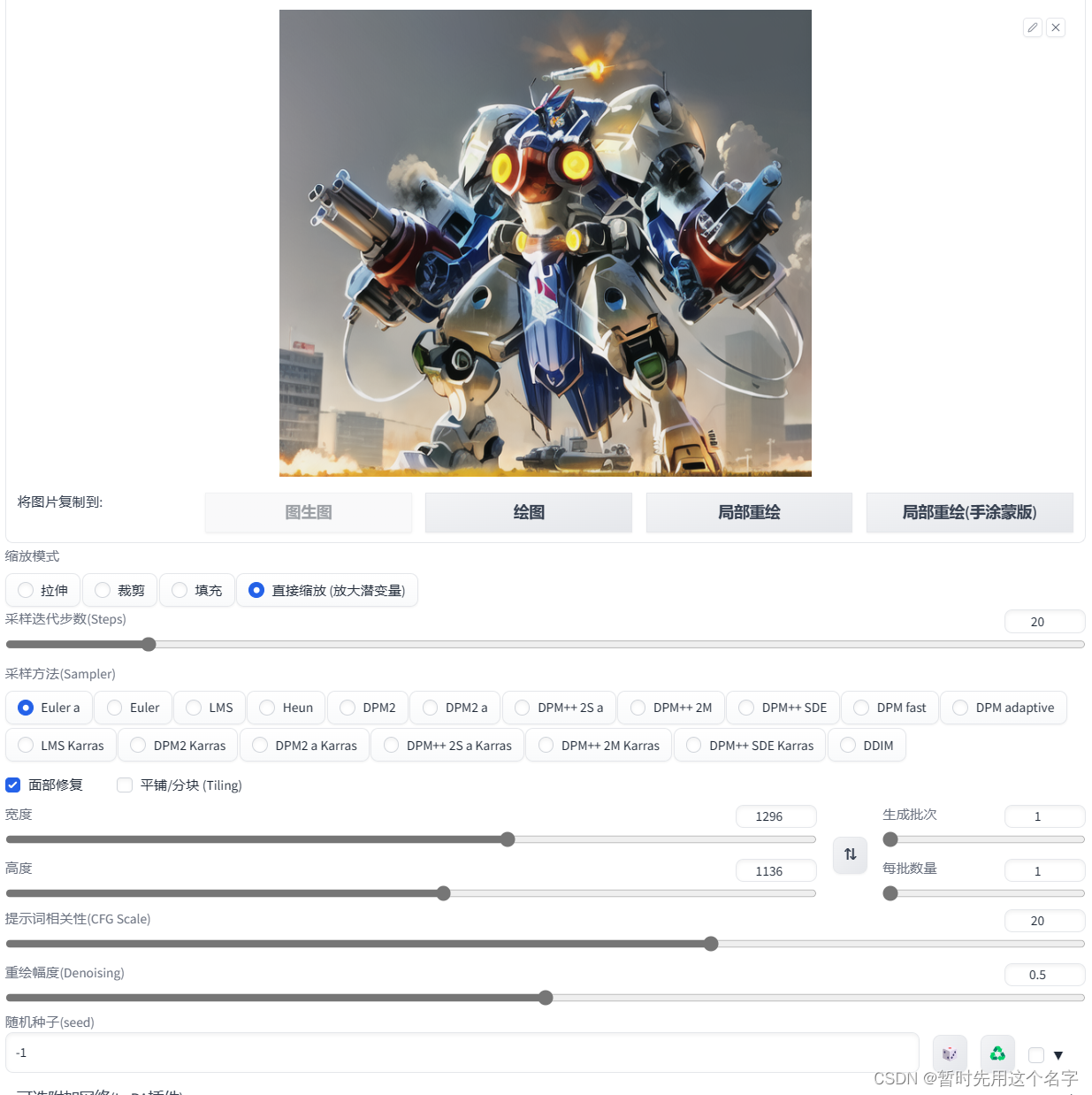
-
出图

四、P图加细节
-
把弹药桶、子弹带补完。
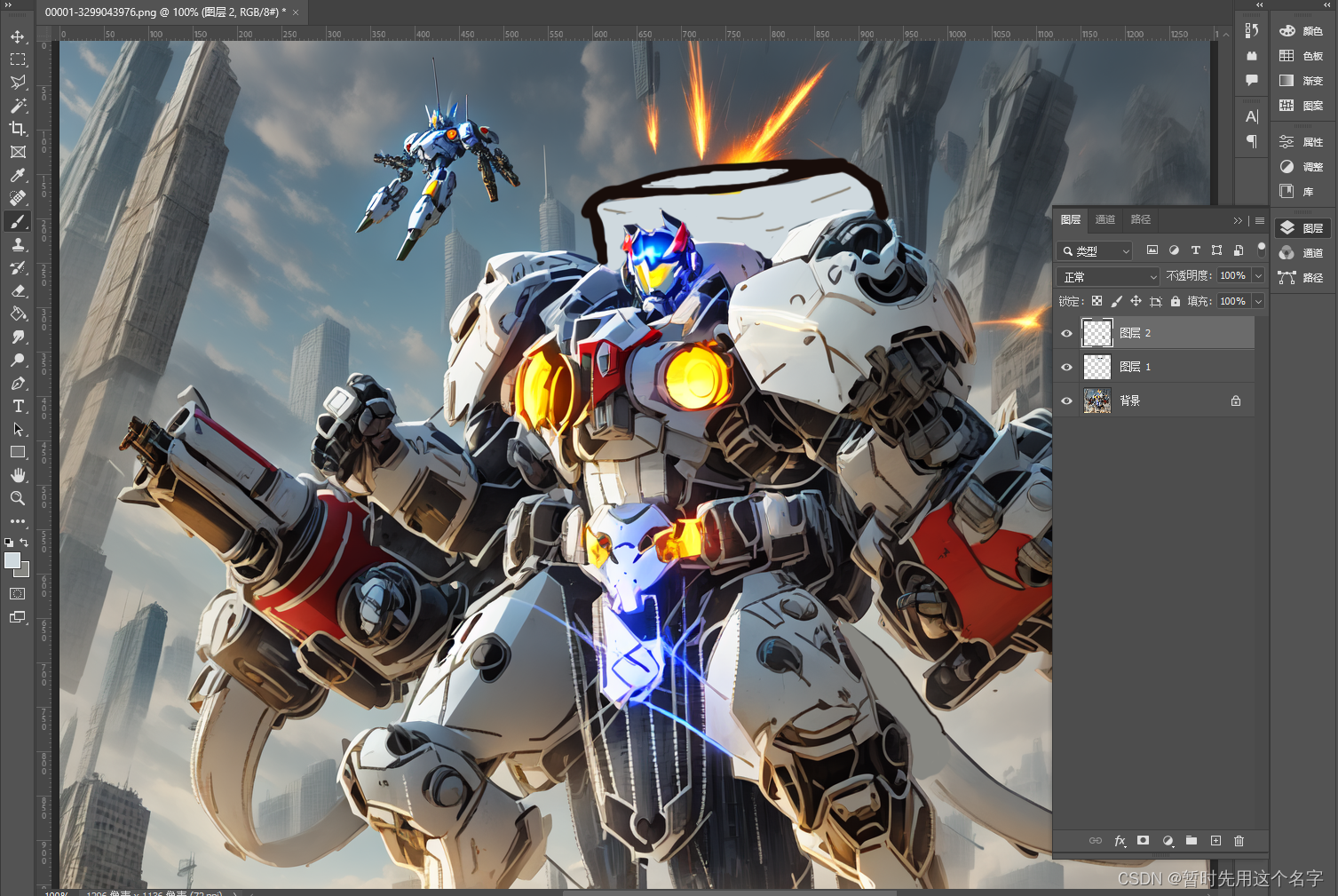
-
继续图生图,让ai自己调整一下
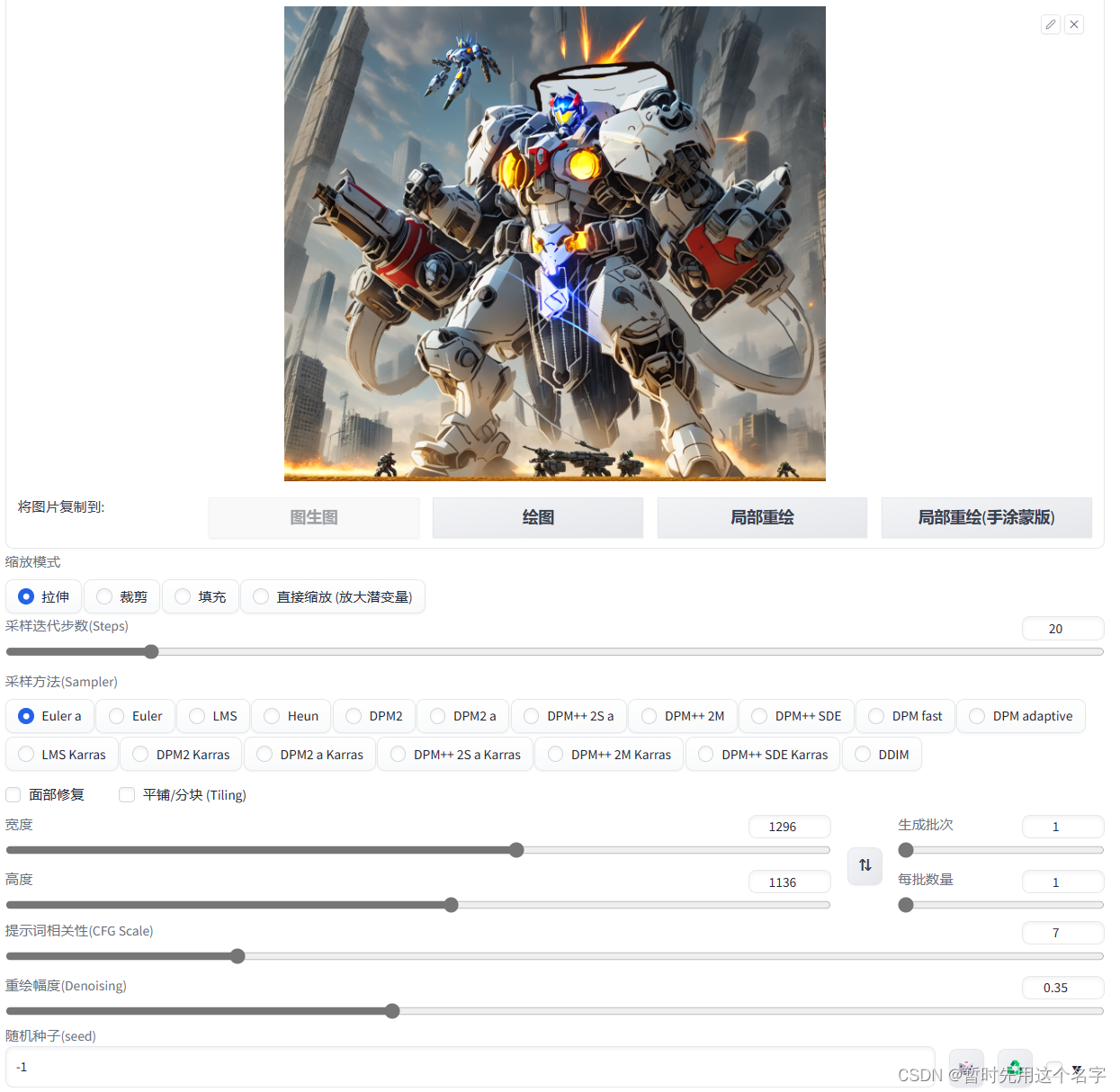
- 多次生图后

今天得甲流了。。。就这样吧,总结:
- 有美术设计基础才是上策,除非完全让AI给你创意,否则你所构思的结构、布局、细节、色彩需要调整很久才可能接近;
- 要理解各个参数的意思,会更快得到理想中的图片;
- 显卡不行的时候先从512像素开始,看自己的提示词、参数等是否符合要求,然后再用大图。
- 硬件硬件硬件~~
- 像这种草图比较干净的,出图就非常迅速,一步到位。

best quality, masterpiece, (realistic:1.2), 1 girl, brown hair, brown eyes,Front, detailed face, beautiful eyes,((look looking at viewer))




最后,大家学习过这篇内容了么?AI绘图实战(二):制作一页海洋、沙滩、男孩与狗的绘本画 | Stable Diffusion成为设计师生产力工具



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









