










刷完了牛客Java题,整理了自己做错的题,希望可以帮助到各位突破0ffer,获得Offer。
1、可以把任何一种数据类型的变量赋给Object类型的变量。
A、对
B、错
Object类是所有类的父类,基本数据类型直接赋值给Object对象时,会先自动装箱成对应的包装类,然后再赋值。
2、有关线程的叙述正确的是
A、可以获得对任何对象的互斥锁定。
B、通过继承Thread类或实现Runnable接口,可以获得对类中方法的互斥锁定。
C、线程通过使用synchronized关键字可获得对象的互斥锁定。
D、线程的创建只能通过继承Thread类来实现。
A应该是"任何"那错了,比如在一个static方法中就无法对一个非static对象加锁
private volatile String a = “lock”;
public static void f() {
synchronized (a) {} //错误的,无法获取该对象的锁
}
B 线程的创建方式与线程之间互斥无关
C synchronized关键字可以实现互斥
D 线程创建方式不止通过继承Thread类来实现
3、Java中可以将布尔值与整数进行比较吗 ?
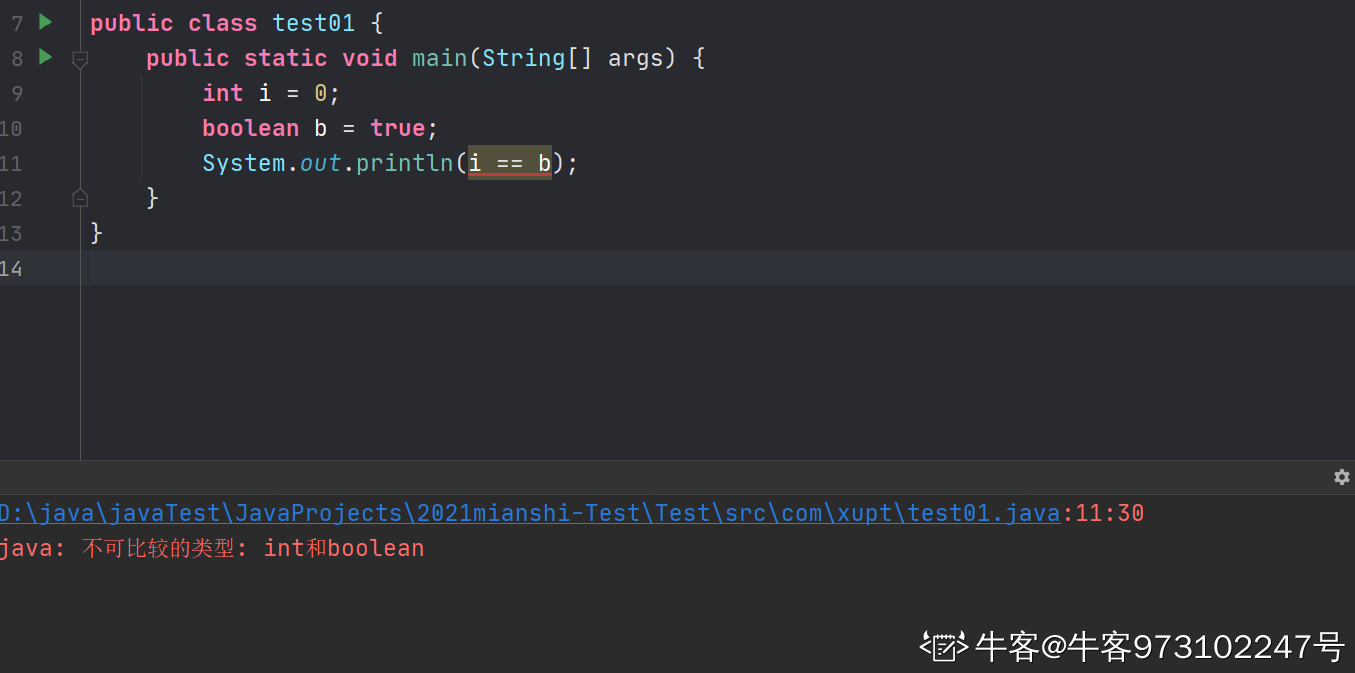
4、下面关于依赖注入(DI)的说法不正确的是
A、只有通过Spring才能实现依赖注入(DI)
B、依赖注入的主要目的是解耦合
C、常见的依赖注入方式有Setter和构造方法
A 依赖注入是一种设计模式与具体框架无关
属性注入:
创建对象时候,向类里面属性里面设置值
注入的三种方式(java),在Spring框架中只支持前面两种方式
第一种:使用set方法注入
public class User{
private String name;
public void setName(String name){
this.name=name;
}
}
User user=new User();
user.setName("abcd");
第二种:有参数构造注入
public class User{
private String name;
public User(String name){
this.name=name;
}
}
User user=new User("lucy");
第三种:使用接口注入
public interface Dao{
public void delete(String name);
}
public class DaoImplements Dao{
private String name;
public void delete(String name){
this.name=name;
}
}
使用有参数构造注入属性
<bean id="demo" class="cn.itcast.property.propertyDemo1">
<constructor-arg name="username" value="小王小马"></constructor>
</bean>
public class TestIOC{
public void testUser(){
1.加载Spring配置文件,根据创建对象
APPlicationContext context=new ClassPathXmlApplicationContext("bean1.xml")
2.得到配置创建的对象
PropertyDemo1 demo1=(PropertyDemo1)context.getBean("demo");
demo1.test1();
}
}
使用set方法注入属性(使用的更多)
<bean id="book" class="cn.itcast.property.Book"> //代表对象已经创建
//name属性值:类里面定义的属性名称 value属性:设置具体的值
<property name="bookname" vlaue="易筋经"></property>
</bean>
public class Book{
private String bookname;
public void setName(String bookname){
this.bookname=bookname;
}
pubic void demobook(){
system.out.println("book........"+bookname);
}
}
public class TestIOC{
public void testUser(){
1.加载Spring配置文件,根据创建对象
APPlicationContext context=new ClassPathXmlApplicationContext("bean1.xml")
2.得到配置创建的对象
Book book=(Book)context.getBean("book");
book.demobook();
}
}
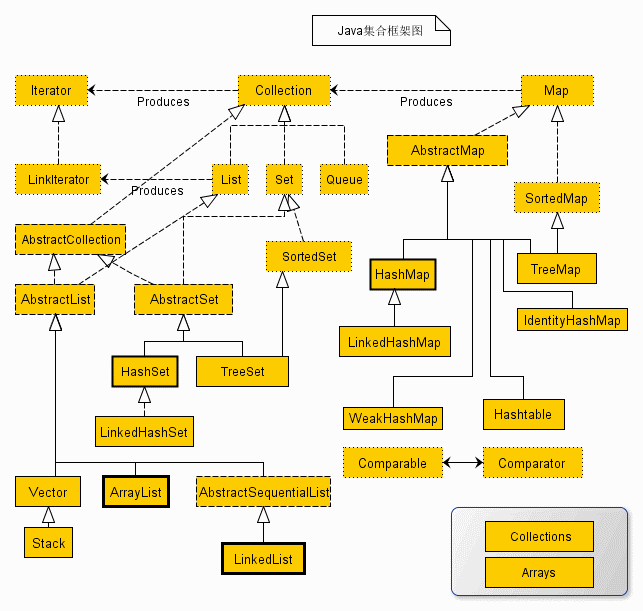
5、下列关于计算机系统和Java编程语言的说法,正确的是
A、计算机是由硬件、操作系统和软件组成,操作系统是缺一不可的组成部分。
B、Java语言编写的程序源代码可以不需要编译直接在硬件上运行。
C、在程序中书写注释不会影响程序的执行,可以在必要的地方多写一些注释。
D、Java的集成开发环境(IDE),如Eclipse,是开发Java语言必需的软件工具。
A 计算机是由硬件和软件组成,软件分为系统软件和应用软件,操作系统是系统软件。
B. Java程序源代码需要编译后在Java虚拟机上运行
C. Java的集成开发环境(IDE),不是必须的,JDK才是必须的,有jdk就行。
6、以下代码段执行后的输出结果为
public class Test {
public static void main(String args[]) {
int x = -5;
int y = -12;
System.out.println(y % x);
}
}
A、-1
B、2
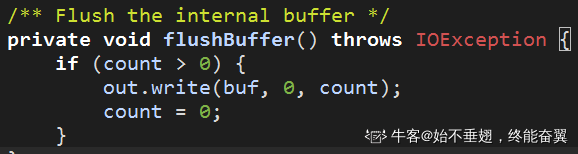
C、1
D、-2
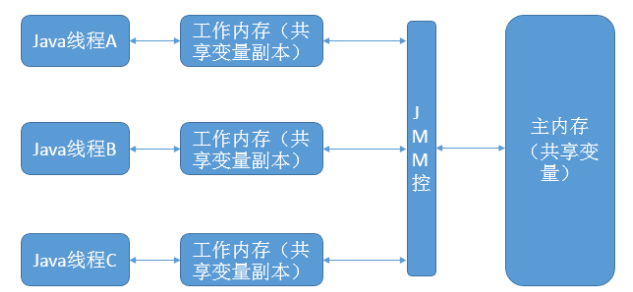
java的取余计算,12%-5=2; 取模计算方法为Math.floorMod(12,-5)=-3;

6、在Java中,以下关于方法重载和方法重写描述正确的是?
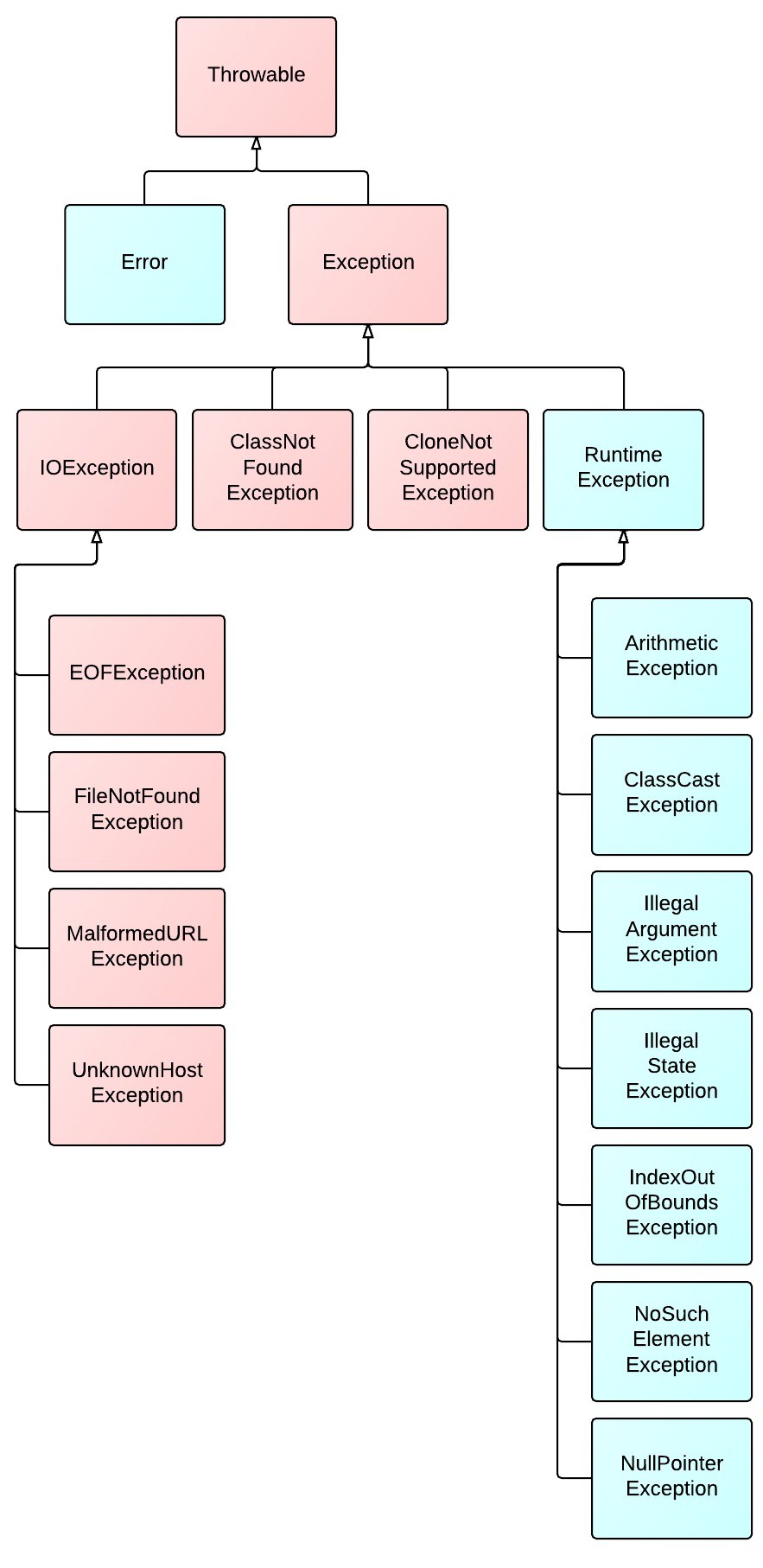
A、方法重载和方法的重写实现的功能相同
B、方法重载出现在父子关系中,方法重写是在同一类中
C、方法重载的返回值类型必须一致,参数项必须不同
D、方法重写的返回值类型必须相同或相容。(或是其子类)
方法重载(overload):
1.必须是同一个类
2.方法名(也可以叫函数)一样
3.参数类型不一样或参数数量不一样
方法的重写(override)两同两小一大原则:
方法名相同,参数类型相同
子类返回类型小于等于父类方法返回类型,
子类抛出异常小于等于父类方法抛出异常,
子类访问权限大于等于父类方法访问权限。
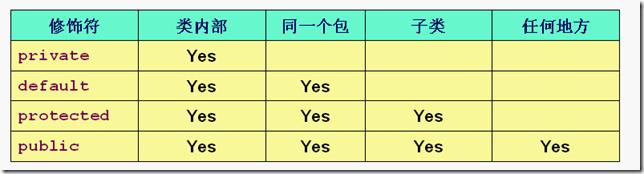
7、访问权限控制从最大权限到最小权限依次为:public、 包访问权限、protected和private 。
A、正确
B、错误
8、java如何返回request范围内存在的对象?
A、request.getRequestURL()
B、request.getAttribute()
C、request.getParameter()
D、request.getWriter()
request.getAttribute()方法返回request范围内存在的对象,而request.getParameter()方法是获取http提交过来的数据。getAttribute是返回对象,getParameter返回字符串。
9、下列代码编译和运行的结果是:
public class Threads4{
public static void main(String[] args){
new Threads4().go();
}
public void go(){
Runnable r=new Runnable(){
public void run(){
System.out.print("foo");
}
};
Thread t=new Thread(r);
t.start();
}
}
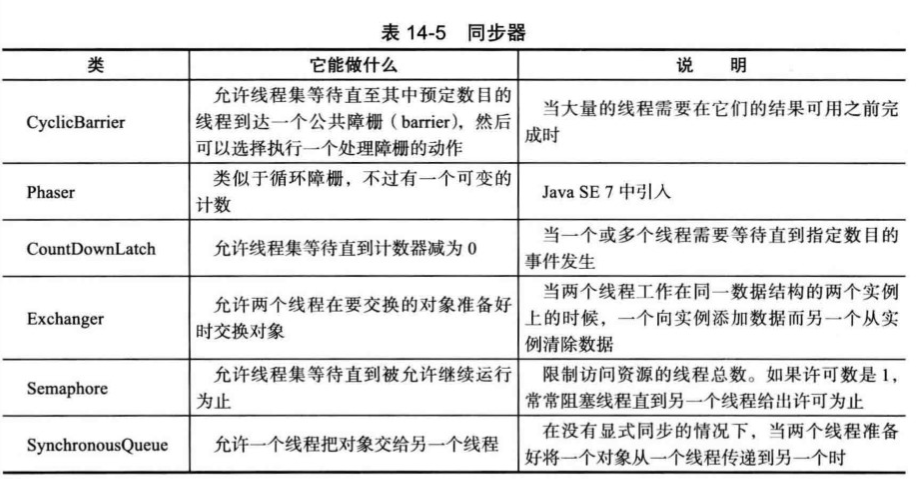
A、编译错误
B、抛出运行时异常
C、foo
D、代码正常运行,但是无输出
在java多线程中实现多线程的方式有两种①extends Thread ②implements Runnable。这两种情况是我们最常见的,还有一种是由第二种变形而来的直接new Runnable(){},我们都知道java的接口是不可以实例化的,但代码中的new Runnable(){xxx}确是实例化了,为什么? 接口和抽象类不可以实例化是对的,这个是java语法规范来的,而new Runnable(){}其实不是实例化Runnable接口来的,实际上一种内部类的一种简写 在这里:
①首先构造了一个”implements Runnable “的无名local内部类(方法内的内部类)
②然后构造了这个无名local内部类的一个实例
③然后用Runnable来表示这个无名local内部类的type(OO多态)。 例如上面这段代码编译后你会看到其实是编译了两个类来的,如下: 其中Text2$1就是无名local内部内类,这个也就很好地解释了为什么在main()方法中new Runnable(){xxx}里面的调用main()方法中的变量的时候要用final关键字来修饰
10、使用mvc模式设计的web应用程序具有以下优点,除了
A、可维护行强
B、可扩展性强
C、代码重复少
D、大大减少代码量
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。 MVC只是将分管不同功能的逻辑代码进行了隔离,增强了可维护和可扩展性,增强代码复用性,因此可以减少代码重复。但是不保证减少代码量,多层次的调用模式还有可能增加代码量。
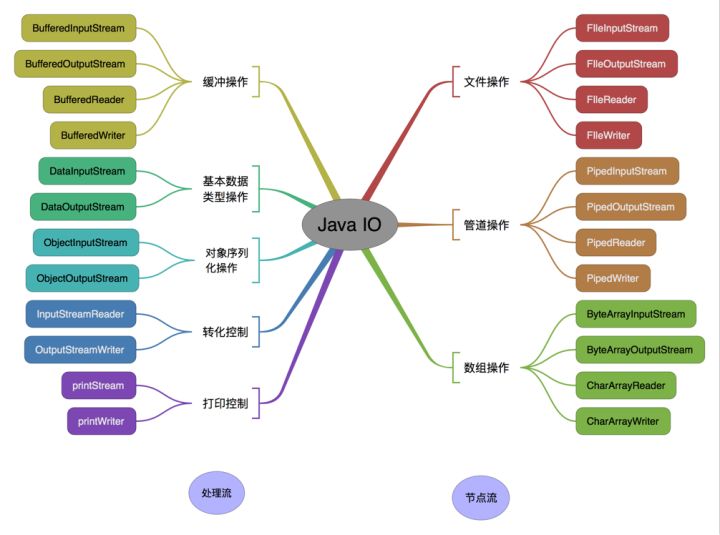
11、一般用()创建InputStream对象,表示从标准输入中获取数据,用()创建OutputStream对象,表示输出到标准输出设备中。
A、System.in System.out
B、System.out System.in
C、System.io.in System.io.out
D、System.io.out System.io.in
System.in 和 System.out 是java中的标准输入输出流,一般情况下代表从控制台输入和输出到控制台。
12、下面哪段程序能够正确的实现了GBK编码字节流到UTF-8编码字节流的转换:
A、dst=String.fromBytes(src,“GBK”).getBytes(“UTF-8”)
B、dst=new String(src,“GBK”).getBytes(“UTF-8”)
C、dst=new String(“GBK”,src).getBytes()
D、dst=String.encode(String.decode(src,“GBK”)),“UTF-8” )

String类没有fromBytes()和encode以及decode方法!!
13、关于Java语言描述正确的是?
A、java和C++都保留了指针
B、java和C++都有三个特征:封装、继承和多态
C、java的垃圾回收机制是指程序结束时系统自动回收内存
D、以上说法都不正确
A,Java没有指针,只有引用。
C,并不是程序结束的时候进行GC,GC的时间是不确定的,且GC的过程需要经过可达性分析,一个对象只有被标记两次才会被GC
14、下面哪种情况会导致持久区jvm堆内存溢出?
A、循环上万次的字符串处理
B、在一段代码内申请上百M甚至上G的内存
C、使用CGLib技术直接操作字节码运行,生成大量的动态类
D、不断创建对象
Java中堆内存分为两部分,分别是permantspace和heap space。permantspace(持久区)主要存放的是Java类定义信息,与垃圾收集器要收集的Java对象关系不大。持久代溢出通常由于持久代设置过小,动态加载了大量Java类,因此C选项正确。
heap space分为年轻代和年老代, 年老代常见的内存溢出原因有循环上万次的字符串处理、在一段代码内申请上百M甚至上G的内存和创建成千上万的对象,也就是题目中的ABD选项。
JVM堆内存分为2块:Permanent Space 和 Heap Space。
-
Permanent 即 持久代(Permanent Generation),主要存放的是Java类定义信息,与垃圾收集器要收集的Java对象关系不大。
-
Heap = { Old + NEW = {Eden, from, to} },Old 即 年老代(Old Generation),New 即 年轻代(Young Generation)。年老代和年轻代的划分对垃圾收集影响比较大。
年轻代
所有新生成的对象首先都是放在年轻代。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代一般分3个区,1个Eden区,2个Survivor区(from 和 to)。
大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当一个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当另一个Survivor区也满了的时候,从前一个Survivor区复制过来的并且此时还存活的对象,将可能被复制到年老代。
2个Survivor区是对称的,没有先后关系,所以同一个Survivor区中可能同时存在从Eden区复制过来对象,和从另一个Survivor区复制过来的对象;而复制到年老区的只有从另一个Survivor区过来的对象。而且,因为需要交换的原因,Survivor区至少有一个是空的。特殊的情况下,根据程序需要,Survivor区是可以配置为多个的(多于2个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
针对年轻代的垃圾回收即 Young GC。
年老代
在年轻代中经历了N次(可配置)垃圾回收后仍然存活的对象,就会被复制到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
针对年老代的垃圾回收即 Full GC。
持久代
用于存放静态类型数据,如 Java Class, Method 等。持久代对垃圾回收没有显著影响。但是有些应用可能动态生成或调用一些Class,例如 Hibernate CGLib 等,在这种时候往往需要设置一个比较大的持久代空间来存放这些运行过程中动态增加的类型。
所以,当一组对象生成时,内存申请过程如下:
- JVM会试图为相关Java对象在年轻代的Eden区中初始化一块内存区域。
- 当Eden区空间足够时,内存申请结束。否则执行下一步。
- JVM试图释放在Eden区中所有不活跃的对象(Young GC)。释放后若Eden空间仍然不足以放入新对象,JVM则试图将部分Eden区中活跃对象放入Survivor区。
- Survivor区被用来作为Eden区及年老代的中间交换区域。当年老代空间足够时,Survivor区中存活了一定次数的对象会被移到年老代。
- 当年老代空间不够时,JVM会在年老代进行完全的垃圾回收(Full GC)。
- Full GC后,若Survivor区及年老代仍然无法存放从Eden区复制过来的对象,则会导致JVM无法在Eden区为新生成的对象申请内存,即出现“Out of Memory”。
OOM(“Out of Memory”)异常一般主要有如下2种原因:
-
年老代溢出,表现为:java.lang.OutOfMemoryError:Javaheapspace
这是最常见的情况,产生的原因可能是:设置的内存参数Xmx过小或程序的内存泄露及使用不当问题。
**例如循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存。**还有的时候虽然不会报内存溢出,却会使系统不间断的垃圾回收,也无法处理其它请求。这种情况下除了检查程序、打印堆内存等方法排查,还可以借助一些内存分析工具,比如MAT就很不错。 -
持久代溢出,表现为:java.lang.OutOfMemoryError:PermGenspacez
通常由于持久代设置过小,动态加载了大量Java类而导致溢出 ,解决办法唯有将参数 -XX:MaxPermSize 调大(一般256m能满足绝大多数应用程序需求)。将部分Java类放到容器共享区(例如Tomcat share lib)去加载的办法也是一个思路,但前提是容器里部署了多个应用,且这些应用有大量的共享类库
15、下列在Java语言中关于数据类型和包装类的说法,正确的是
A、基本(简单)数据类型是包装类的简写形式,可以用包装类替代基本(简单)数据类型
B、long和double都占了64位(64bit)的存储空间。
C、默认的整数数据类型是int,默认的浮点数据类型是float。
D、和包装类一样,基本(简单)数据类型声明的变量中也具有静态方法,用来完成进制转化等。
A,包装和基本类型不是同一个概念
B, long和double都占了64位(64bit)的存储空间
C,默认的浮点数据类型是double,如果要指明使用float,则需要在后面加f
D,基本数据类型是没有静态方法的,但是基本数据类型的包装类却有
16、以下代码运行输出的是
public class Person{
private String name = "Person";
int age=0;
}
public class Child extends Person{
public String grade;
public static void main(String[] args){
Person p = new Child();
System.out.println(p.name);
}
}
A、输出:Person
B、没有输出
C、编译出错
D、运行出错
父类private的成员变量,根据权限修饰符的访问控制范围,只有在类内部才能被访问,就算是他的子类,也不能访问。这里如果将Person p = new Child();改成Person p = new Person();代码依然无法通过编译,因为子类作用域中访问不到父类的私有变量,无法为其生成正确的字节码。另外,一个Java文件中不能有两个public类。
17、在开发中使用泛型取代非泛型的数据类型(比如用ArrayList取代ArrayList),程序的运行时性能会变得更好。
A、正确
B、错误
使用泛型的好处
1,类型安全。 泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。没有泛型,这些假设就只存在于程序员的头脑中(或者如果幸运的话,还存在于代码注释中)。
2,消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。 3,潜在的性能收益。 泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的 JVM 的优化带来可能。由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改。所有工作都在编译器中完成,编译器生成类似于没有泛型(和强制类型转换)时所写的代码,只是更能确保类型安全而已。
所以泛型只是提高了数据传输安全性,并没有改变程序运行的性能
18、ServletConfig接口默认是哪里实现的?
A、Servlet
B、GenericServlet
C、HttpServlet
D、用户自定义servlet
19、在Java中,对于不再使用的内存资源,如调用完成的方法,“垃圾回收器”会自动将其释放。
A、正确
B、错误
JVM 内存可简单分为三个区:
1、堆区(heap):用于存放所有对象,是线程共享的(注:数组也属于对象)
2、栈区(stack):用于存放基本数据类型的数据和对象的引用,是线程私有的(分为:虚拟机栈和本地方法栈)
3、方法区(method):用于存放类信息、常量、静态变量、编译后的字节码等,是线程共享的(也被称为非堆,即 None-Heap)
Java 的垃圾回收器(GC)主要针对堆区
20、java中提供了哪两种用于多态的机制
A、通过子类对父类方法的覆盖实现多态
B、利用重载来实现多态.即在同一个类中定义多个同名的不同方法来实现多态。
C、利用覆盖来实现多态.即在同一个类中定义多个同名的不同方法来实现多态。
D、通过子类对父类方法的重载实现多态

21、以下哪几种是java的基本数据类型。
A、String
B、int
C、boolean
D、Double
java四类八种基本数据类型:
1、整型 byte,short,int,long
2、浮点型 float,double
3、逻辑型 boolean
4、字符型 char
基本数据类型在栈中直接分配内存
字节长度:
boolean布尔型 1或4(单独使用时是占4个字节(boolean被JVM编译成int),组成数组时每个布尔型数据占1个字节(boolean数组被JVM编译成byte数组))
byte字节类型 1
char字符型 2
short短整型 2
int整数类型 4
float单精度浮点型 4
long长整型 8
double双精度浮点型 8
22、下面哪些Java中的流对象是字节流?
A、FileInputStream
B、BufferedInputStream
C、PushbackInputStream
D、ByteArrayInputStream
stream结尾都是字节流,reader和writer结尾都是字符流 两者的区别就是读写的时候一个是按字节读写,一个是按字符。 实际使用通常差不多。 在读写文件需要对内容按行处理,比如比较特定字符,处理某一行数据的时候一般会选择字符流。 只是读写文件,和文件内容无关的,一般选择字节流。
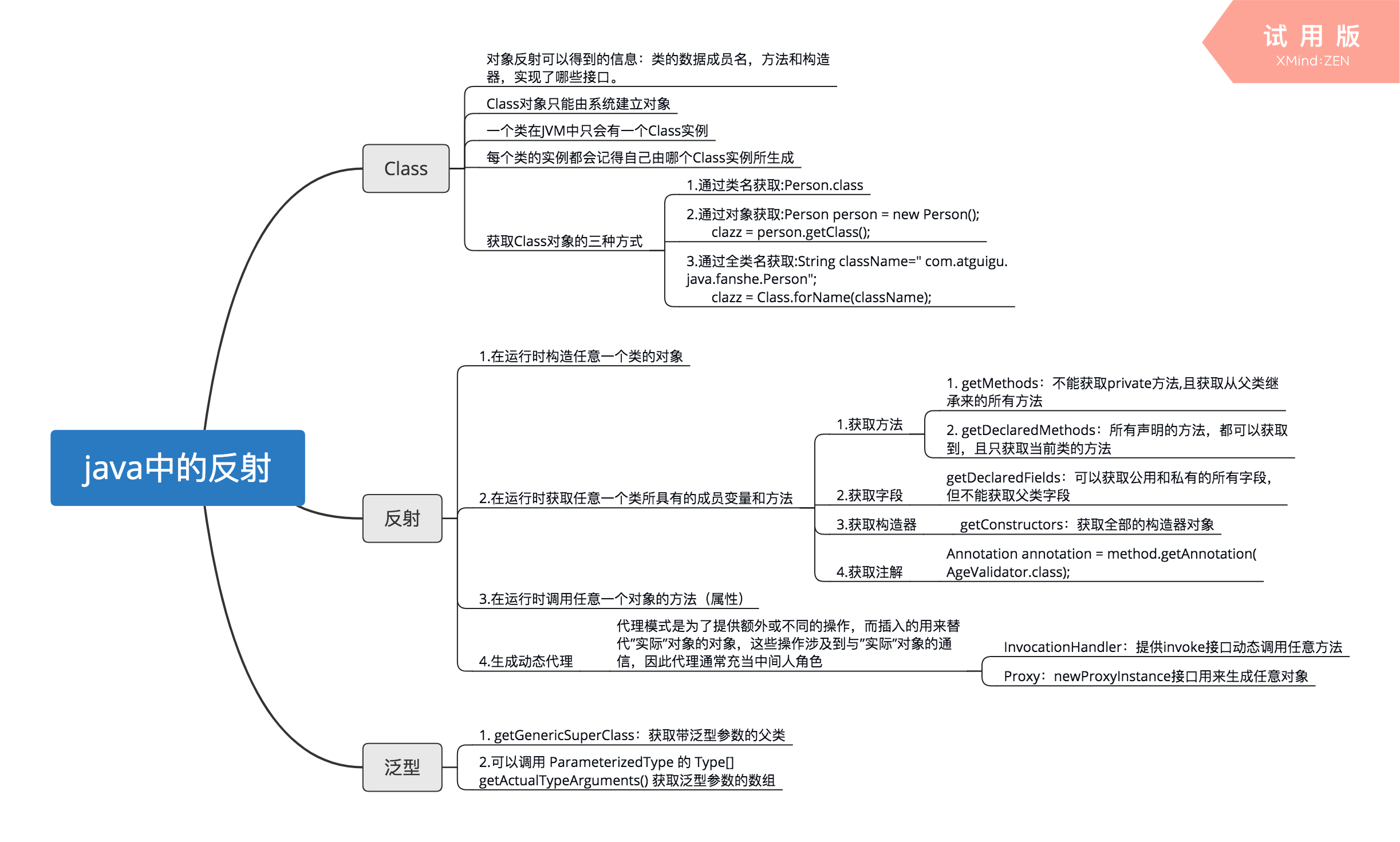
23、JAVA反射机制主要提供了以下哪些功能?
A、在运行时判断一个对象所属的类
B、在运行时构造一个类的对象
C、在运行时判断一个类所具有的成员变量和方法
D、在运行时调用一个对象的方法
A: Class.isInstance();
B: Class.newInstance();
C: Class.getMethod(); Class.getField();
D: Method.invoke();
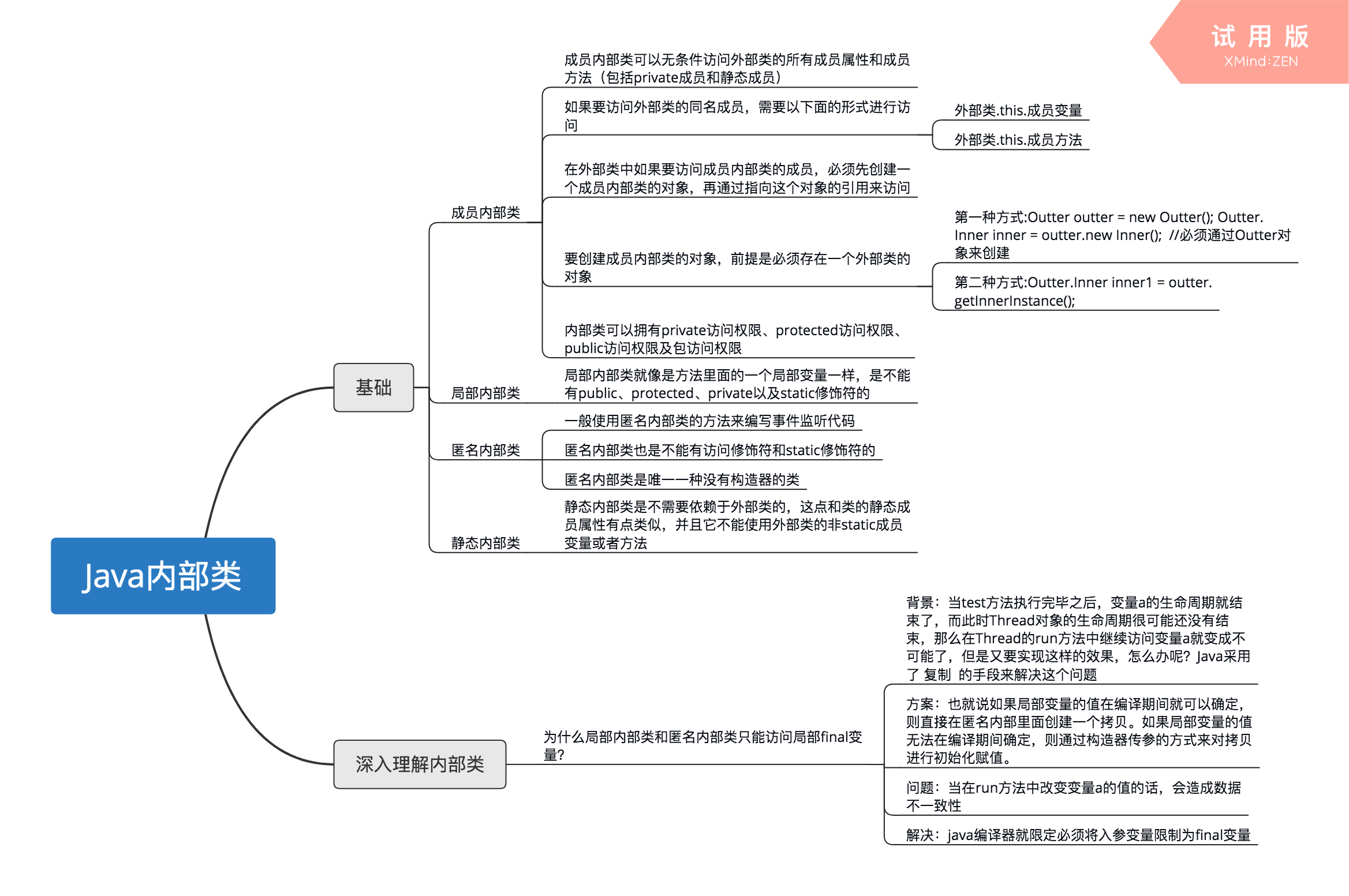
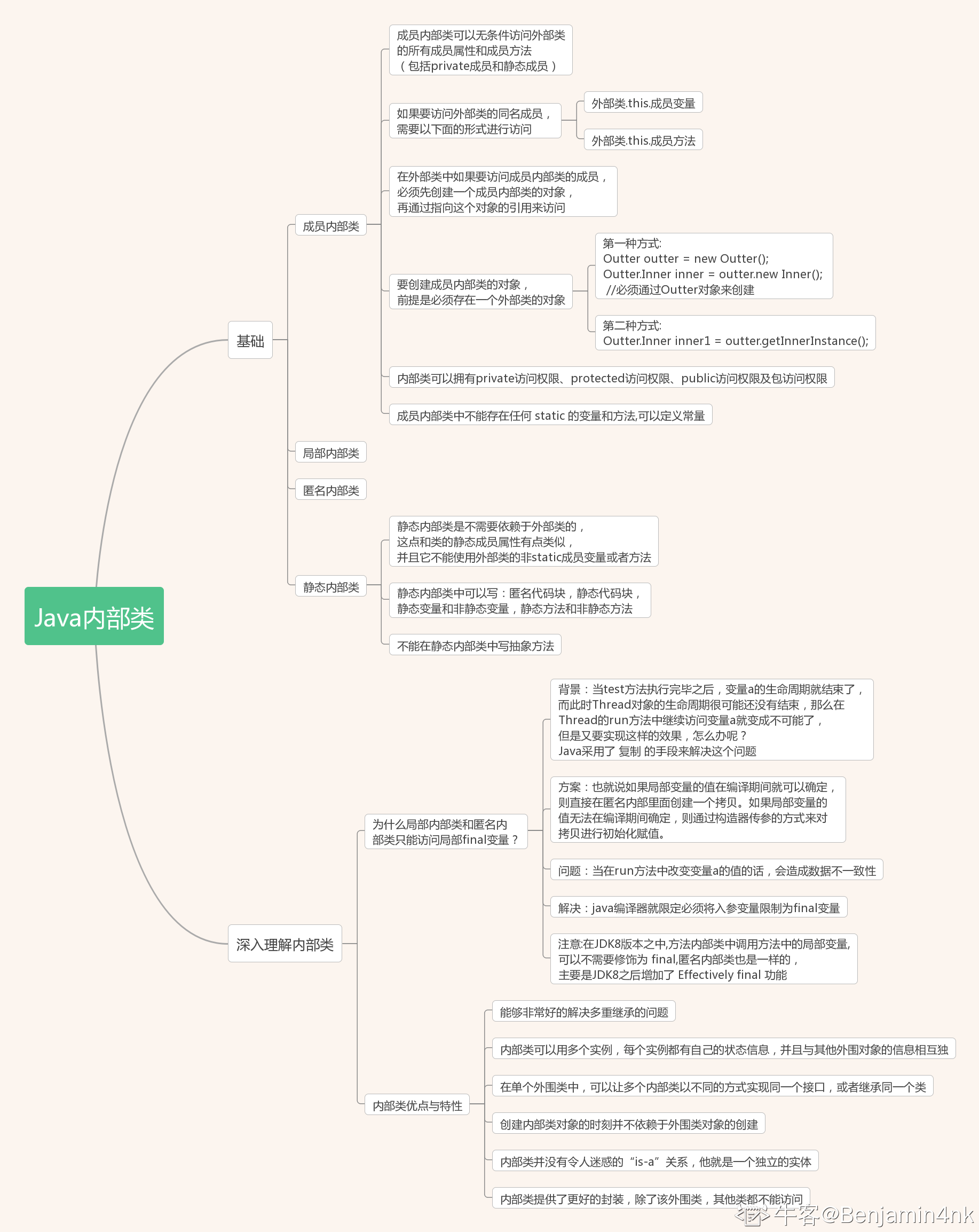
24、局部内部类可以用哪些修饰符修饰?
A、public
B、private
C、abstract
D、final
25、用户不能调用构造方法,只能通过new关键字自动调用。
A、正确
B、错误
创建对象有很多种方式:
在类内部可通过this关键字创建对象;
在子类中可使用super关键字创建对象;
通过反射机制可以创建对象;
通过控制翻转的方式实现依赖注入也可创建对象。
26、try括号里有return语句, finally执行顺序
A、不执行finally代码
B、return前执行
C、return后执行
1、不管有木有出现异常,finally块中代码都会执行;
2、当try和catch中有return时,finally仍然会执行;
3、finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,不管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在finally执行前确定的;
4、finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
27、选项中哪一行代码可以替换 //add code here 而不产生编译错误
public abstract class MyClass {
public int constInt = 5;
//add code here
public void method() {
}
}
A、public abstract void method(int a);
B、consInt=constInt+5;
C、public int method();
D、public abstract void anotherMethod(){}
A:抽象类可以包含抽象方法
B:类中定义成员和方法,不能直接进行运算,可以写在代码块{}或者静态代码块中static{}中
C: 与第四行想要构成重载,二者区别是返回类型,但是返回类型不能作为重载的依据
D: 该方法使用abstract修饰,是抽象方法,但是他有方法体(带有{}的就是方法体,即使里面是空的),就不能作为抽象方法
28、有以下类定义:
abstract class Animal{
abstract void say();
}
public class Cat extends Animal{
public Cat(){
System.out.printf("I am a cat");
}
public static void main(String[] args) {
Cat cat=new Cat();
}
}
A、I am a cat
B、Animal能编译,Cat不能编译
C、Animal不能编译,Cat能编译
D、编译能通过,但是没有输出结果
包含抽象方法的类称为抽象类,但并不意味着抽象类中只能有抽象方法,它和普通类一样,同样可以拥有成员变量和普通的成员方法。注意,抽象类和普通类的主要有三点区别:
1)抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。
2)抽象类不能用来创建对象;
3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
在其他方面,抽象类和普通的类并没有区别。
29、执行如下程序,输出结果是
class Test
{
private int data;
int result = 0;
public void m()
{
result += 2;
data += 2;
System.out.print(result + " " + data);
}
}
class ThreadExample extends Thread
{
private Test mv;
public ThreadExample(Test mv)
{
this.mv = mv;
}
public void run()
{
synchronized(mv)
{
mv.m();
}
}
}
class ThreadTest
{
public static void main(String args[])
{
Test mv = new Test();
Thread t1 = new ThreadExample(mv);
Thread t2 = new ThreadExample(mv);
Thread t3 = new ThreadExample(mv);
t1.start();
t2.start();
t3.start();
}
}
A、0 22 44 6
B、2 42 42 4
C、2 24 46 6
D、4 44 46 6
Test mv =newTest()声明并初始化对data赋默认值
使用synchronized关键字加同步锁线程依次操作m()
t1.start();使得result=2,data=2,输出即为2 2
t2.start();使得result=4,data=4,输出即为4 4
t3.start();使得result=6,data=6,输出即为6 6
System.out.print(result +" "+ data);是print()方法不会换行,输出结果为2 24 46 6
30、下面代码输出是?
double d1=-0.5;
System.out.println("Ceil d1="+Math.ceil(d1));
System.out.println("floor d1="+Math.floor(d1));
A、Ceil d1=-0.0 floor d1=-1.0
B、Ceil d1=0.0 floor d1=-1.0
C、Ceil d1=-0.0 floor d1=-0.0
D、Ceil d1=0.0 floor d1=0.0
E、Ceil d1=0 floor d1=-1
Ceil 天花板 大于等于x的最小的整数
Floor 地板 小于等于x的最大整数
Math.ceil(d1) :
ceil 方法上有这么一段注释:If the argument value is less than zero but greater than -1.0, then the result is negative zero
如果参数小于0且大于-1.0,结果为 -0
Math.floor(d1):
ceil 和 floor 方法 上都有一句话:If the argument is NaN or an infinity or positive zero or negative zero, then the result is the same as the argument,意思为:如果参数是 NaN、无穷、正 0、负 0,那么结果与参数相同,
如果是 -0.0,那么其结果是 -0.0
31、下列代码输出结果为
class Animal{
public void move(){
System.out.println("动物可以移动");
}
}
class Dog extends Animal{
public void move(){
System.out.println("狗可以跑和走");
}
public void bark(){
System.out.println("狗可以吠叫");
}
}
public class TestDog{
public static void main(String args[]){
Animal a = new Animal();
Animal b = new Dog();
a.move();
b.move();
b.bark();
}
}
A、动物可以移动
狗可以跑和走
狗可以吠叫
B、动物可以移动
动物可以移动
狗可以吠叫
C、运行错误
D、编译错误
编译看左边,运行看右边,左边Animal类中没有Dog类中的bark方法,而编译器认为b.bark调用了Animal中没有的bark方法,因此编译错误
32、以下哪种JAVA得变量声明方式可以避免程序在多线程竞争情况下读到不正确的值
A、volatile
B、static volatile
C、synchronized
D、static
A B选项,免程序在多线程竞争情况下读到不正确的值需要保证内存可见性,即当一个线程修改了volatile修饰的变量的值,volatile会保证新值立即同步到主内存,以及每次使用前立即从主内存读取。
C选项,synchronized可以修饰方法、代码块或对象,并不修饰变量。
D选项,static修饰的变量属于类,线程在使用这个属性的时候是从类中复制拷贝一份到线程工作内存中的,如果修改线程内存中的值之后再写回到原先的位置,就会有线程安全问题。用static修饰的变量可见性是无法确保的。
33、默认RMI采用的是什么通信协议?
A、HTTP
B、UDP/IP
C、TCP/IP
D、Multicast
RMI(Remote Method Invocation)远程方法调用是一种计算机之间利用远程对象互相调用实现双方通讯的一种通讯机制。使用这种机制,某一台计算机上的对象可以调用另外一台计算机上的对象来获取远程数据。RMI是Enterprise JavaBeans的支柱,是建立分布式Java应用程序的方便途径。在过去,TCP/IP套接字通讯是远程通讯的主要手段,但此开发方式没有使用面向对象的方式实现开发,在开发一个如此的通讯机制时往往令程序员感觉到乏味,对此RPC(Remote Procedure Call)应运而生,它使程序员更容易地调用远程程序,但在面对复杂的信息传讯时,RPC依然未能很好的支持,而且RPC未能做到面向对象调用的开发模式。针对RPC服务遗留的问题,RMI出现在世人面前,它被设计成一种面向对象的通讯方式,允许程序员使用远程对象来实现通信,并且支持多线程的服务,这是一次远程通讯的***,为远程通信开辟新的里程碑。 RMI的开发步骤 先创建远程接口及声明远程方法,注意这是实现双方通讯的接口,需要继承Remote 开发一个类来实现远程接口及远程方法,值得注意的是实现类需要继承UnicastRemoteObject 通过javac命令编译文件,通过java -server 命令注册服务,启动远程对象 最后客户端查找远程对象,并调用远程方法 所以选C
34、给定以下JAVA代码,这段代码运行后输出的结果是
public class Test
{
public static int aMethod(int i)throws Exception
{
try{
return i/10;
}
catch (Exception ex)
{
throw new Exception("exception in a aMethod");
}finally{
System.out.printf("finally");
}
}
public static void main(String[] args){
try
{
aMethod(0);
}
catch (Exception ex)
{
System.out.printf("exception in main");
}
System.out.printf("finished");
}
}
A、exception in main finished
B、finallyfinished
C、exception in main finally
D、finally exception in main finally
本题考的不仅仅是审题,而且是try…catch…finally块的关系,以及return与finally的执行关系。
具体执行过程:
1、先进入main函数,进入try块调用aMethod(0)方法;
2、执行aMethod()方法的try块,i/10可以正确执行,故并未抛出异常,catch块不执行,而需要执行finally(该块任何时候都要执行),故打印finally;
3、回到main函数,由于aMethod()调用成功,因此main函数的catch块同样不执行,顺序执行finally块,打印finished
因此,最终的输出结果就是:finally finished
35、运行下面代码,输出的结果是
class A {
public A() {
System.out.println("class A");
}
{ System.out.println("I'm A class"); }
static { System.out.println("class A static"); }
}
public class B extends A {
public B() {
System.out.println("class B");
}
{ System.out.println("I'm B class"); }
static { System.out.println("class B static"); }
public static void main(String[] args) {
new B();
}
}
A、
class A static
class B static
I’m A class
class A
I’m B class
class B
B、
class A static
I’m A class
class A
class B static
I’m B class
class B
C、
class A static
class B static
class A
I’m A class
class B
I’m B class
D、
class A static
class A
I’m A class
class B static
class B
I’m B class
Java程序初始化顺序:
- 父类的静态代码块
- 子类的静态代码块
- 父类的普通代码块
- 父类的构造方法
- 子类的普通代码块
- 子类的构造方法
36、Which lines of the following will produce an error?
byte a1 = 2, a2 = 4, a3;
short s = 16;
a2 = s;
a3 = a1 * a2;
A、Line 3 and Line 4
B、Line 1 only
C、Line 3 only
D、Line 4 only
数值型变量在默认情况下为Int型,byte和short型在计算时会自动转换为int型计算,结果也是int 型。所以a1*a2的结果是int 型的。
Java中涉及byte、short和char类型的算术运算首先会把这些值转换为int类型,然后对int类型值进行运算,最后得到int类型的结果。如果需要对byte/short/char类型的变量进行运算操作得到byte类型结果,必须将这个int类型的结果显式转换为byte类型。进行数值运算时要注意可能会发生溢出错误。如本题中Line4代码a1*a2的结果已被隐式转换为int类型,将其赋值给a3时要进行显示转换(在不溢出的情况下)
a3 = (byte)a1 * a2;
java各基本类型变量之间运算操作的隐式转换总结:除了自增和自减操作不进行转化外,其它操作都是无long型时,所有非int类型均隐式转成int类型;有long类型时,所有类型都隐式转成long类型。
37、以下程序的输出结果为
class Base{
public Base(String s){
System.out.print("B");
}
}
public class Derived extends Base{
public Derived (String s) {
System.out.print("D");
}
public static void main(String[] args){
new Derived("C");
}
}
1.写一个类,如果没有写构造函数,那么这类默认会有一个无参的构造函数。如果写构造函数了,那么就不会有默认的无参构造函数,
以自己写的构造函数为准。
2.子类在写构造函数的时候,第一行必须用super 关键字调用父类的任一构造函数。
3.用super调用父类的构造函数时,如果调用的是父类无参构造函数,则super()可以不用写,如果是有参构造函数,则必须显示调用。
所以看这道题:
1.父类 Base 有一个有参构造函数,那么默认的无参构造函数就没有了;
2.在子类Derived的构造函数中,必须通过super调用父类的构造函数
3.父类Base 没有无参的构造函数,所以必须显示调用父类的有参构造函数,即显示的调用 super(“”);
38、下面代码的运行结果是
public class Arraytest{
int a[] = new int[6];
public static void main ( String arg[] ) {
System.out.println ( a[0] );
}
}
A、null
B、0
C、编译出错
D、运行出错
在static方法中是不能访问非静态变量 a 的,需要将 a 声明为static,答案才会是 0 ,否则是编译出错
39、以下关于java封装的描述中,正确的是
A、封装的主要作用在于对外隐藏内部实现细节,增强程序的安全性
B、封装的意义不大,因此在编码中尽量不要使用
C、如果子类继承父类,对于父类中进行封装的方法,子类仍然可以直接调用
D、只能对一个类中的方法进行封装,不能对属性进行封装
封装主要是隐藏内部代码;
继承主要是复用现有代码;
多态主要是改写对象行为。
A:正确
B : 意义很大,在程序的可维护性上大大减轻了负担。不会出现很多的错误的直接操作数据的行为
C :封装后,子类想要调用父类的方法,要通过对外公开的公共方法进行访问。
D : 错误的,封装会将属性私有化的。提供方法访问操作。
40、BufferedReader的父类是以下哪个?
A、FilterReader
B、InputStreamReader
C、PipedReader
D、Reader
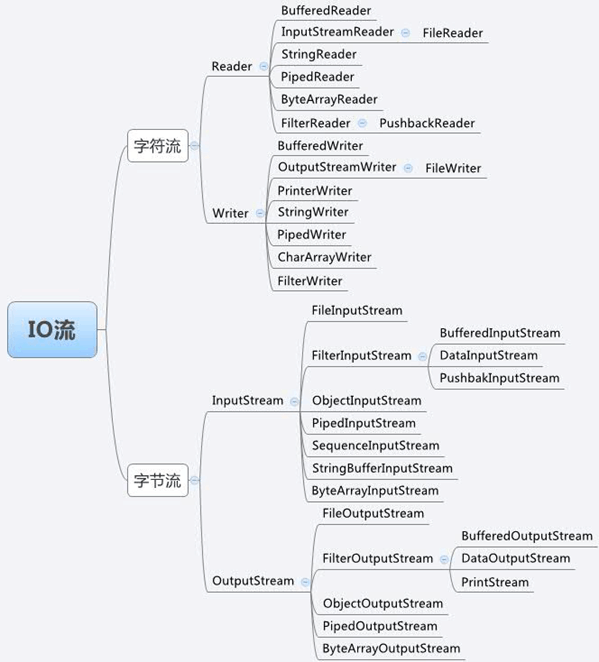
41、如果一个接口Glass有个公有方法setColor(),有个类BlueGlass实现接口Glass,则在类BlueGlass中正确的是?
A、protected void setColor() { …}
B、void setColor() { …}
C、public void setColor() { …}
D、以上语句都可以用在类BlueGlass中
特殊的抽象类:彻底抽象,没有构造器,只有常量(public static final)与抽象方法(public abstract)。
实现接口的类,必须重写接口中的所有抽象方法,若没有全部重写,则此类仍然是抽象类。
实现接口类,其类中的方法权限不能低于接口,故为:public
42、定义有StringBuffer s1=new StringBuffer(10);s1.append(“1234”),则s1.length()和s1.capacity()分别是多少?
A、4 10
B、4 4
C、10 10
D、10 4
length()代表的是其中的内容的长度,capacity()代表的是容器的大小。
StringBuffer s = new StringBuffer(x); x为初始化容量长度
s.append(“Y”); "Y"表示长度为y的字符串
length始终返回当前长度即y;
对于s.capacity():
1.当y<x时,值为x
以下情况,容器容量需要扩展
2.当x<y<2x+2时,值为 2x+2
3.当y>2*x+2时,值为y
43、下面程序的运行结果是
public static void main(String args[]) {
Thread t = new Thread() {
public void run() {
pong();
}
};
t.run();
System.out.print("ping");
}
static void pong() {
System.out.print("pong");
}
A、pingpong
B、pongping
C、pingpong和pongping都有可能
D、都不输出
t.run直接执行代码,按顺序打印代码;
t.start是另起线程,与当前线程同时竞争cpu资源,结果存在不确定性
44、java程序内存泄露的最直接表现
A、频繁FullGc
B、jvm崩溃
C、程序抛内存溢出的Exception
D、java进程异常消失
java是自动管理内存的,通常情况下程序运行到稳定状态,内存大小也达到一个基本稳定的值 但是内存泄露导致Gc不能回收泄露的垃圾,内存不断变大. 最终超出内存界限,抛出OutOfMemoryExpection
45、一个容器类数据结构,读写平均,使用锁机制保证线程安全。如果要综合提高该数据结构的访问性能,最好的办法是
A、只对写操作加锁,不对读操作加锁
B、读操作不加锁,采用copyOnWrite的方式实现写操作
C、分区段加锁
D、无法做到
A: 只对写操作加锁,不对读操作加锁,会造成读到脏数据
B: CopyOnWrite的核心思想是利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用。这里读写平均,不适用 C,分段加锁,只在影响读写的地方加锁,锁可以用读写锁,可以提高效率
46、以下代码的输出结果是?
public class B
{
public static B t1 = new B();
public static B t2 = new B();
{
System.out.println("构造块");
}
static
{
System.out.println("静态块");
}
public static void main(String[] args)
{
B t = new B();
}
}
A、静态块 构造块 构造块 构造块
B、构造块 静态块 构造块 构造块
C、构造块 构造块 静态块 构造块
D、构造块 构造块 构造块 静态块
总结一下: 1.程序入口main方法要执行首先要加载类B 2.静态域:分为静态变量,静态方法,静态块。这里面涉及到的是静态变量和静态块,当执行到静态域时,按照静态域的顺序加载。并且静态域只在类的第一次加载时执行 3.每次new对象时,会执行一次构造块和构造方法,构造块总是在构造方法前执行(当然,第一次new时,会先执行静态域,静态域〉构造块〉构造方法) 注意:加载类时并不会调用构造块和构造方法,只有静态域会执行 4.根据前三点,首先加载类B,执行静态域的第一个静态变量,static b1=new B,输出构造块和构造方法(空)。ps:这里为什么不加载静态方法呢?因为执行了静态变量的初始化,意味着已经加载了B的静态域的一部分,这时候不能再加载另一个静态域了,否则属于重复加载 了(静态域必须当成一个整体来看待。否则加载会错乱) 于是,依次static b2 =new B,输出构造块,再执行静态块,完成对整个静态域的加载,再执行main方法,new b,输出构造块。
47、以下表达式中,正确的是
A、byte i=128
B、boolean i=null
C、long i=0xfffL
D、double i=0.9239d
A、byte:-128~127。直接给个128,编译器会认为是int值,这个时候需要强转成byte。
B、boolean:这可是基本数据类型啊,只有false,true。默认值是false。一旦是包装类Boolean,那默认值是null。ojbk
C、十六进制没毛病
D、double这个东西本来就可以写成有d的形式。
48、有关finally语句块说法正确的是
A、不管catch是否捕获异常,finally语句块都是要被执行的
B、在try语句块或catch语句块中执行到System.exit(0)直接退出程序
C、finally块中的return语句会覆盖try块中的return返回
D、finally 语句块在 catch语句块中的return语句之前执行
49、以下哪几种方式可用来实现线程间通知和唤醒
A、Object.wait/notify/notifyAll
B、ReentrantLock.wait/notify/notifyAll
C、Condition.await/signal/signalAll
D、Thread.wait/notify/notifyAll
wait()、notify()和notifyAll()是 Object类中的方法
从这三个方法的文字描述可以知道以下几点信息:
1)wait()、notify()和notifyAll()方法是本地方法,并且为final方法,无法被重写。
2)调用某个对象的wait()方法能让当前线程阻塞,并且当前线程必须拥有此对象的monitor(即锁)
3)调用某个对象的notify()方法能够唤醒一个正在等待这个对象的monitor的线程,如果有多个线程都在等待这个对象的monitor,则只能唤醒其中一个线程;
4)调用 notifyAll() 方法能够唤醒所有正在等待这个对象的monitor的线程;
有朋友可能会有疑问:为何这三个不是Thread类声明中的方法,而是Object类中声明的方法 (当然由于Thread类继承了Object类,所以Thread也可以调用者三个方法)?其实这个问题很简单,由于每个对象都拥有monitor(即锁),所以让当前线程等待某个对象的锁,当然 应该通过这个对象来操作了。而不是用当前线程来操作,因为当前线程可能会等待多个线程 的锁,如果通过线程来操作,就非常复杂了。
上面已经提到,如果调用某个对象的wait()方法,当前线程必须拥有这个对象的monitor(即 锁),因此调用wait()方法必须在同步块或者同步方法中进行(synchronized块或者 synchronized方法)。 调用某个对象的wait()方法,相当于让当前线程交出此对象的monitor,然后进入等待状态, 等待后续再次获得此对象的锁(Thread类中的sleep方法使当前线程暂停执行一段时间,从 而让其他线程有机会继续执行,但它并不释放对象锁); notify()方法能够唤醒一个正在等待该对象的monitor的线程,当有多个线程都在等待该对象的monitor的话,则只能唤醒其中一个线程,具体唤醒哪个线程则不得而知。 同样地,调用某个对象的notify()方法,当前线程也必须拥有这个对象的monitor,因此调用notify()方法必须在同步块或者同步方法中进行(synchronized块或者synchronized方法)。nofityAll()方法能够唤醒所有正在等待该对象的monitor的线程,这一点与notify()方法是不同的。Condition是在java 1.5中才出现的,它用来替代传统的Object的wait()、notify()实现线程间的协作,相比使用Object的wait()、notify(),使用Condition1的await()、signal()这种方式实现线程间协作更加安全和高效。因此通常来说比较推荐使用Condition,在阻塞队列那一篇博文中就讲述到了,阻塞队列实际上是使用了Condition来模拟线程间协作。
- Condition是个接口,基本的方法就是await()和signal()方法;
- Condition依赖于Lock接口,生成一个Condition的基本代码是lock.newCondition()
- 调用Condition的await()和signal()方法,都必须在lock保护之内,就是说必须在lock.lock()和lock.unlock之间才可以使用Conditon中的await()对应Object的wait(); Condition中的signal()对应Object的notify(); Condition中的signalAll()对应Object的notifyAll()
50、Java中基本的编程单元为:
A、类
B、函数
C、变量
D、数据
java的基本编程单元是类,基本存储单元是变量。
51、有时为了避免某些未识别的异常抛给更高的上层应用,在某些接口实现中我们通常需要捕获编译运行期所有的异常, catch 下述哪个类的实例才能达到目的
A、Error
B、Exception
C、RuntimeException
D、Throwable

53、事务隔离级别是由谁实现的
A、Java应用程序
B、Hibernate
C、数据库系统
D、JDBC驱动程序
Java程序可以指定事务隔离级别,但实现隔离级别的是数据库系统。CD选项,JDBC全称是Java Database connect,它是一套用于执行SQL语句的Java API。而Hibernate是开放源代码的对象关系映射框架,它对JDBC做了非常轻量级的封装。二者均是程序与数据库连接的桥梁,无法实现事务隔离级别。
54、jre 判断程序是否执行结束的标准是
A、所有的前台线程执行完毕
B、所有的后台线程执行完毕
C、所有的线程执行完毕
D、和以上都无关
后台线程:指为其他线程提供服务的线程,也称为守护线程。JVM的垃圾回收线程就是一个后台线程。
前台线程:是指接受后台线程服务的线程,其实前台后台线程是联系在一起,就像傀儡和幕后操纵者一样的关系。傀儡是前台线程、幕后操纵者是后台线程。由前台线程创建的线程默认也是前台线程。可以通过isDaemon()和setDaemon()方法来判断和设置一个线程是否为后台线程。
其实这个题,就是在说守护线程和非守护(用户)线程的问题。后台线程就是守护线程,前台线程就是用户线程。
守护线程:是指在程序运行时在后台提供一种通用服务的线程,这种线程并不是必须的。同时守护线程的线程优先级都很低的。JVM中的GC线程就是一个守护线程,只要JVM启动,GC线程就启动了。
用户线程和守护线程几乎没有什么区别,唯一的区别就在于,如果用户线程都已经退出了,只剩下了守护线程,那么JVM直接就退出了。
class ThreadDemo extends Thread{
public void run(){
System.out.println(Thread.currentThread().getName()+" : begin");
try{
Thread.sleep(2000);
}catch(Exception e){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+" : end");
}
}
public class Test{
public static void main(String[] args){
System.out.println("test : begin");
Thread t = new ThreadDemo();
t.setDaemon(true);
t.start();
System.out.println("test : end");
}
}
/**
程序输出:
test : begin
test : end
Thread-0 :begin
运行结果中不会有Thread-0 : end,是因为,守护线程开启之后,中间睡了2s,这个时候又没有锁,主线程直接就执行完了,
一旦主线程结束,那么JVM中就只剩守护线程了,JVM直接就退出了,不管你守护线程有没有执行完。 */
55、如何获取ServletContext设置的参数值?
A、context.getParameter()
B、context.getInitParameter()
C、context.getAttribute()
D、context.getRequestDispatcher()
getParameter()是获取POST/GET传递的参数值
getInitParameter获取的是Tomcat的server.xml中设置Context的初始化参数
getAttribute()是获取对象容器中的数据值;
getRequestDispatcher是请求转发
56、对于JVM内存配置参数:-Xmx10240m -Xms10240m -Xmn5120m -XXSurvivorRatio=3,其最小内存值和Survivor区总大小分别是
A、5120m,1024m
B、5120m,2048m
C、10240m,1024m
D、10240m,2048m
-Xmx -Xms分别设置堆的最大值和最小值,如果要设置成堆的大小可变,那么可以将最大值和最小值设置成不一样,如果要将堆大小固定,那么只需将最大值和最小值设置成一样的就行。
jvm中分为堆和方法区
堆又进一步分为新生代和老年代
方法区为永久代
堆中区分的新生代和老年代是为了垃圾回收,新生代中的对象存活期一般不长,而老年代中的对象存活期较长,所以当垃圾回收器回收内存时,新生代中垃圾回收效果较好,会回收大量的内存,而老年代中回收效果较差,内存回收不会太多。
基于以上特性,新生代中一般采用复制算法,因为存活下来的对象是少数,所需要复制的对象少,而老年代对象存活多,不适合采用复制算法,一般是标记整理和标记清除算法。
因为复制算法需要留出一块单独的内存空间来以备垃圾回收时复制对象使用,所以将新生代分为eden区和两个survivor区,每次使用eden和一个survivor区,另一个survivor作为备用的对象复制内存区。
综上:
-Xmn设置了新生代的大小为5120m,而-XXSurvivorRatio=3,所有将新生代共分成5分,eden占三份,survivor占两份,每份1/5
新生代大部分要回收,采用Copying算法,快!
老年代 大部分不需要回收,采用Mark-Compact算法

-XX:NewRatio=1:老年代和新生代所占比值为 1:1,新生代占整个堆栈的 1/2。
57、在JAVA中,下列哪些是Object类的方法
A、synchronized()
B、wait()
C、notify()
D、notifyAll()
E、sleep()
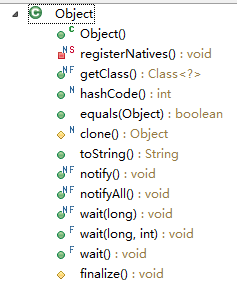

58、对于线程局部存储TLS(thread local storage),以下表述正确的是
A、解决多线程中的对同一变量的访问冲突的一种技术
B、TLS会为每一个线程维护一个和该线程绑定的变量的副本
C、每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了
D、Java平台的java.lang.ThreadLocal是TLS技术的一种实现
C:同一全局变量或者静态变量每个线程访问的是同一变量,多个线程同时访存同一全局变量或者静态变量时会导致冲突,尤其是多个线程同时需要修改这一变量时,通过TLS机制,为每一个使用该全局变量的线程都提供一个变量值的副本,每一个线程均可以独立地改变自己的副本,而不会和其它线程的副本冲突。
59、对抽象类的描述正确的是
A、抽象类的方法都是抽象方法
B、一个类可以继承多个抽象类
C、抽象类不能有构造方法
D、抽象类不能被实例化
A:抽象类中可以没有抽象方法。
B:类都是单继承,但是继承有传递性。
C:抽象类可以有构造器,但是不能实例化。找个构造器有两个用处:
1、给非抽象子类实例化时调用,子类构造器中第一行默认是super()
2、可以在构造器中初始化抽象类中的成员、类方法。
60、下面有关java classloader说法错误的是?
A、Java默认提供的三个ClassLoader是BootStrap ClassLoader,Extension ClassLoader,App ClassLoader
B、ClassLoader使用的是双亲委托模型来搜索类的
C、JVM在判定两个class是否相同时,只用判断类名相同即可,和类加载器无关
D、ClassLoader就是用来动态加载class文件到内存当中用的
比较两个类是否相等,只有这两个类是由同一个类加载器加载才有意义。否则,即使这两个类是来源于同一个Class文件,只要加载它们的类加载器不同,那么这两个类必定不相等。
补充:
1.什么是类加载器?
把类加载的过程放到Java虚拟机外部去实现,让应用程序决定如何去获取所需要的类。实现这个动作的代码模块称为“类加载器”。
2.有哪些类加载器,分别加载哪些类
类加载器按照层次,从顶层到底层,分为以下三种:
(1)启动类加载器 : 它用来加载 Java 的核心库,比如String、System这些类
(2)扩展类加载器 : 它用来加载 Java 的扩展库。
(3)应用程序类加载器 : 负责加载用户类路径上所指定的类库,一般来说,Java 应用的类都是由它来完成加载的。
3.双亲委派模型
我们应用程序都是由以上三种类加载器互相配合进行加载的,还可以加入自己定义的类加载器。称为类加载器的双亲委派模型,这里类加载器之间的父子关系一般不会以继承的关系来实现,而是都使用组合关系来复用父加载器的。
4.双亲委托模型的工作原理
是当一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法加载这个加载请求的时候,子加载器才会尝试自己去加载。
5.使用双亲委派模型好处?(原因)
第一:可以避免重复加载,当父亲已经加载了该类的时候,子类不需要再次加载。
第二:考虑到安全因素,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时被加载,所以用户自定义类是无法加载一个自定义的类装载器。
61、对于Java中异常的描述正确的是
A、用throws定义了方法可能抛出的异常,那么调用此方法时一定会抛出此异常。
B、如果try块中没有抛出异常,finally块中的语句将不会被执行。
C、抛出异常意味着程序发生运行时错误,需要调试修改。
D、Java中的非检测(unchecked)异常可能来自RuntimeException类或其子类。
Exception(异常)
是程序本身可以处理的异常。主要包含RuntimeException等运行时异常和IOException,SQLException等非运行时异常。
运行时异常
包括:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
非运行时异常(编译异常)
包括:RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常
A错 如果方法只在方法头 throws Exception{},而方法里面没有实际的 异常对象 (引起异常的原因,或throw new Exception() ),也就是没有异常,何来抛出(抛什么呢)。
B错 finally块中的语句一定会被执行。除非catch块中有System.exit(0)。
C错 抛出异常不一定是运行时异常,也有可能是编译时异常。
D对 运行时异常的特点是Java编译器不会检查它。
62、在Java中,HashMap中是用哪些方法来解决哈希冲突的
A、开放地址法
B、二次哈希法
C、链地址法
D、建立一个公共溢出区
1.基本概念
**哈希算法**:根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上的算法。也称为散列算法、杂凑算法。
**哈希表**:数据经过哈希算法之后得到的集合。这样关键字和数据在集合中的位置存在一定的关系,可以根据这种关系快速查询。
非哈希表:与哈希表相对应,集合中的 数据和其存放位置没任何关联关系的集合。
由此可见,哈希算法是一种特殊的算法,能将任意数据散列后映射到有限的空间上,通常计算机软件中用作快速查找或加密使用。
**哈希冲突**:由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,因此总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
2.解决哈希冲突的方法
解决哈希冲突的方法一般有:开放定址法、链地址法(拉链法)、再哈希法、建立公共溢出区等方法。
2.1 开放定址法
从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。然后把发生冲突的元素存入到该单元的一种方法。开放定址法需要的表长度要大于等于所需要存放的元素。
在开放定址法中解决冲突的方法有:线行探查法、平方探查法、双散列函数探查法。
开放定址法的缺点在于删除元素的时候不能真的删除,否则会引起查找错误,只能做一个特殊标记。只到有下个元素插入才能真正删除该元素。
2.1.1 线行探查法
线行探查法是开放定址法中最简单的冲突处理方法,它从发生冲突的单元起,依次判断下一个单元是否为空,当达到最后一个单元时,再从表首依次判断。直到碰到空闲的单元或者探查完全部单元为止。
http://student.zjzk.cn/course_ware/data_structure/web/flash/cz/kfdzh.swf
2.1.2 平方探查法
平方探查法即是发生冲突时,用发生冲突的单元d[i], 加上 1²、 2²等。即d[i] + 1²,d[i] + 2², d[i] + 3²…直到找到空闲单元。
在实际操作中,平方探查法不能探查到全部剩余的单元。不过在实际应用中,能探查到一半单元也就可以了。若探查到一半单元仍找不到一个空闲单元,表明此散列表太满,应该重新建立。
2.1.3 双散列函数探查法
这种方法使用两个散列函数hl和h2。其中hl和前面的h一样,以关键字为自变量,产生一个0至m—l之间的数作为散列地址;h2也以关键字为自变量,产生一个l至m—1之间的、并和m互素的数(即m不能被该数整除)作为探查序列的地址增量(即步长),探查序列的步长值是固定值l;对于平方探查法,探查序列的步长值是探查次数i的两倍减l;对于双散列函数探查法,其探查序列的步长值是同一关键字的另一散列函数的值。
2.2 链地址法(拉链法)
链接地址法的思路是将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
如下一组数字,(32、40、36、53、16、46、71、27、42、24、49、64)哈希表长度为13,哈希函数为H(key)=key%13,则链表法结果如下: 0 1 -> 40 -> 27 -> 53 2 3 -> 16 -> 42 4 5 6 -> 32 -> 71 7 -> 46 8 9 10 -> 36 -> 49 11 -> 24 12 -> 64
注:在java中,链接地址法也是HashMap解决哈希冲突的方法之一,jdk1.7完全采用单链表来存储同义词,jdk1.8则采用了一种混合模式,对于链表长度大于8的,会转换为红黑树存储。
2.3 再哈希法
就是同时构造多个不同的哈希函数:
Hi = RHi(key) i= 1,2,3 … k;
当H1 = RH1(key) 发生冲突时,再用H2 = RH2(key) 进行计算,直到冲突不再产生,这种方法不易产生聚集,但是增加了计算时间。
2.4 建立公共溢出区
将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区。
63、ArrayList和Vector主要区别是什么
A、Vector与ArrayList一样,也是通过数组实现的,不同的是Vector支持线程的同步
B、Vector与ArrayList一样,也是通过数组实现的,不同的是ArrayList支持线程的同步
C、Vector是通过链表结构存储数据,ArrayList是通过数组存储数据
D、上述说法都不正确
**Vector & ArrayList 的主要区别 **
1)同步性:Vector是线程安全的,也就是说是同步的 ,而ArrayList 是线程序不安全的,不是同步的。
2)数据增长:当需要增长时,Vector默认增长为原来一倍 ,而ArrayList却是原来的50% ,这样,ArrayList就有利于节约内存空间。
如果涉及到堆栈,队列等操作,应该考虑用Vector,如果需要快速随机访问元素,应该使用ArrayList 。

扩展知识:
1. Hashtable & HashMap
Hashtable和HashMap它们的性能方面的比较类似 Vector和ArrayList,比如Hashtable的方法是同步的,而HashMap的不是。
2. ArrayList & LinkedList
ArrayList的内部实现是基于内部数组Object[],所以从概念上讲,它更象数组,但LinkedList的内部实现是基于一组连接的记录,所以,它更象一个链表结构,所以,它们在性能上有很大的差别:
从上面的分析可知,在ArrayList的前面或中间插入数据时,你必须将其后的所有数据相应的后移,这样必然要花费较多时间,所以,当你的操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能; 而访问链表中的某个元素时,就必须从链表的一端开始沿着连接方向一个一个元素地去查找,直到找到所需的元素为止,所以,当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
64、关于下列程序段的输出结果,说法正确的是
public class MyClass{
static int i;
public static void main(String argv[]){
System.out.println(i);
}
}
A、有错误,变量i没有初始化。
B、null
C、1
D、0
成员变量和局部变量的区别:
1、成员变量是独立于方法外的变量,局部变量是类的方法中的变量
1)成员变量:包括实例变量和类变量,用static修饰的是类变量,不用static修饰的是实例变量,所有类的成员变量可以通过this来引用。
2)局部变量:包括形参,方法局部变量,代码块局部变量,存在于方法的参数列表和方法定义中以及代码块中。
2、成员变量可以被public,protect,private,static等修饰符修饰,而局部变量不能被控制修饰符及 static修饰;两者都可以定义成final型。
3、成员变量存储在堆,局部变量存储在栈。局部变量的作用域仅限于定义它的方法,在该方法的外部无法访问它。成员变量的作用域在整个类内部都是可见的,所有成员方法都可以使用它。如果访问权限允许,还可以在类的外部使用成员变量。
4、局部变量的生存周期与方法的执行期相同。当方法执行到定义局部变量的语句时,局部变量被创建;执行到它所在的作用域的最后一条语句时,局部变量被销毁。类的成员变量,如果是实例成员变量,它和对象的生存期相同。而静态成员变量的生存期是整个程序运行期。
5、成员变量在累加载或实例被创建时,系统自动分配内存空间,并在分配空间后自动为成员变量指定初始化值,初始化值为默认值,基本类型的默认值为0,复合类型的默认值为null。(被final修饰且没有static的必须显式赋值),局部变量在定义后必须经过显式初始化后才能使用,系统不会为局部变量执行初始化。
6、局部变量可以和成员变量 同名,且在使用时,局部变量具有更高的优先级,直接使用同名访问,访问的是局部变量,如需要访问成员变量可以用this.变量名访问
本例中i为成员变量,有默认的初始值,如果定义在方法内部,就没有初始值
65、根据以下代码段,下列说法中正确的是
public class Parent {
private void m1(){}
void m2(){}
protected void m3(){}
public static void m4(){}
}
A、子类中一定能够继承和覆盖Parent类的m1方法
B、子类中一定能够继承和覆盖Parent类的m2方法
C、子类中一定能够继承和覆盖Parent类的m3方法
D、子类中一定能够继承和覆盖Parent类的m4方法
通过继承,子类可以拥有所有父类对其可见的方法和域
A.私有方法只能在本类中可见,故不能继承,A错误
B.缺省访问修饰符只在本包中可见,在外包中不可见,B错误
C.保护修饰符凡是继承自该类的子类都能访问,当然可被继承覆盖;C正确
D. static修饰的成员属于类成员,父类字段或方法只能被子类同名字段或方法遮蔽,不能被继承覆盖,D错误
66、下面为true的是
Integer i = 42;
Long l = 42l;
Double d = 42.0;
A、(i == l)
B、(i == d)
C、(l == d)
D、i.equals(d)
E、d.equals(l)
F、i.equals(l)
G、l.equals(42L)
ABC 3个选项很明显,不同类型引用的 == 比较,会出现编译错误,不能比较。
DEF 调用 equals 方法,因为此方法先是比较类型,而 i、d、l 是不同的类型,所以返回假。
选项 G ,会自动装箱,将 42L 装箱成 Long 类型,所以调用 equals 方法时,类型相同,且值也相同,因此返回真。
1、基本型和基本型封装型进行“==”运算符的比较,基本型封装型将会自动拆箱变为基本型后再进行比较,因此Integer(0)会自动拆箱为int类型再进行比较,显然返回true
int a = 220;
Integer b = 220;
System.out.println(a == b); //true
2、两个Integer类型进行“==”比较,如果其值在-128至127,那么返回true,否则返回false, 这跟Integer.valueOf()的缓冲对象有关,这里不进行赘述
Integer c=3;
Integer h=3;
Integer e=321;
Integer f=321;
System.out.println(c == h);//true
System.out.println(e==f);//false
3、两个基本型的封装型进行equals()比较,首先equals()会比较类型,如果类型相同,则继续比较值,如果值也相同,返回true。
Integer a=1;
Integer b=2;
Integer c=3;
System.out.println(c.equals(a+b));//true
4、基本型封装类型调用equals(),但是参数是基本类型,这时候,先会进行自动装箱,基本型转换为其封装类型,再进行3中的比较。
int i=1;
int j = 2;
Integer c=3;
System.out.println(c.equals(i+j));//true
67、假如某个JAVA进程的JVM参数配置如下:
-Xms1G -Xmx2G -Xmn500M -XX:MaxPermSize=64M -XX:+UseConcMarkSweepGC -XX:SurvivorRatio=3,
请问eden区最终分配的大小是多少?
A、64M
B、500M
C、300M
D、100M
-Xms:1G , 就是说初始堆大小为1G
-Xmx:2G , 就是说最大堆大小为2G
-Xmn:500M ,就是说年轻代大小是500M(包括一个Eden和两个Survivor)
-XX:MaxPermSize:64M , 就是说设置持久代最大值为64M
-XX:+UseConcMarkSweepGC , 就是说使用使用CMS内存收集算法
-XX:SurvivorRatio=3 , 就是说Eden区与Survivor区的大小比值为3:1:1
题目中所问的Eden区的大小是指年轻代的大小,直接根据-Xmn:500M和-XX:SurvivorRatio=3可以直接计算得出
500M*(3/(3+1+1)) =500M*(3/5) =500M*0.6 =300M
所以Eden区域的大小为300M。
Xms 起始内存
Xmx 最大内存
Xmn 新生代内存
Xss 栈大小。 就是创建线程后,分配给每一个线程的内存大小
-XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n:设置持久代大小
收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
68、在Web应用程序中,( )负责将HTTP请求转换为HttpServletRequest对象
A、Servlet对象
B、HTTP服务器
C、Web容器
D、JSP网页
http:HTTP协议(HyperText Transfer Protocol,超文本传输协议),是用于从WWW服务器传输超文本到本地浏览器的传输协议。
servlet:是一套技术标准,内含与web应用相关的一系列接口,用于为web应用实现方式提供宏观解决方案
web容器:例如tomcat,用于接受、响应客户端的请求,负责将HTTP请求转换为HttpServletRequest对象,也就是创建servlet实例对象 jsp网页:java的服务器页面,其本质也是一个servlet,由html网页代码、Java代码、jsp标签组成,当servlet处理完数据后会转发给jsp,jsp负责显示数据
Apache就是一个Http服务器,Tomcat是一个web容器,静态的htmlApache还可以处理,但是动态的需要转发给Tomcat去处理了,比如jsp页面,请求先经由Apache转发给Tomcat再由Tomcat解析请求。所以应该是web容器去解析成request对象。
69、Gadget has-a Sprocket and Gadget has-a Spring and Gadget is-a Widget and Widget has-a Sprocket 以下哪两段代码可以表示这个关系?
A、
class Widget { Sprocket s; }
class Gadget extends Widget { Spring s; }
B、
class Widget { }
class Gadget extends Widget { Spring s1; Sprocket s2; }
C、
class Widget { Sprocket s1; Spring s2; }
class Gadget extends Widget { }
D、
class Gadget { Spring s; }
class Widget extends Gadget{ Sprocket s; }
is-a 表示继承:Gadget is-a Widget就表示Gadget 继承 Widget;
has-a表示从属:Gadget has-a Sprocket就表示Gadget中有Sprocket的引用,Sprocket是Gadget的组成部分;
like-a表示组合:如果A like-a B,那么B就是A的接口
70、下列说法正确的是
A、在类方法中可用this来调用本类的类方法
B、在类方法中调用本类的类方法时可直接调用
C、在类方法中只能调用本类中的类方法
D、在类方法中绝对不能调用实例方法
先要理解什么是类的方法,所谓类的方法就是指类中用static 修饰的方法(非static 为实例方法),比如main 方法,那么可以以main 方法为例,可直接调用其他类方法,必须通过实例调用实例方法,this 关键字不是这么用的
71、一个Java源程序文件中定义几个类和接口,则编译该文件后生成几个以.class为后缀的字节码文件。
A、正确
B、错误
如果类中有内部类,会产生类名$内部类名.class,如果有匿名类则会产生 类名$1.class.。所以类编译不一定会产生1个class文件。所以答案应该是B
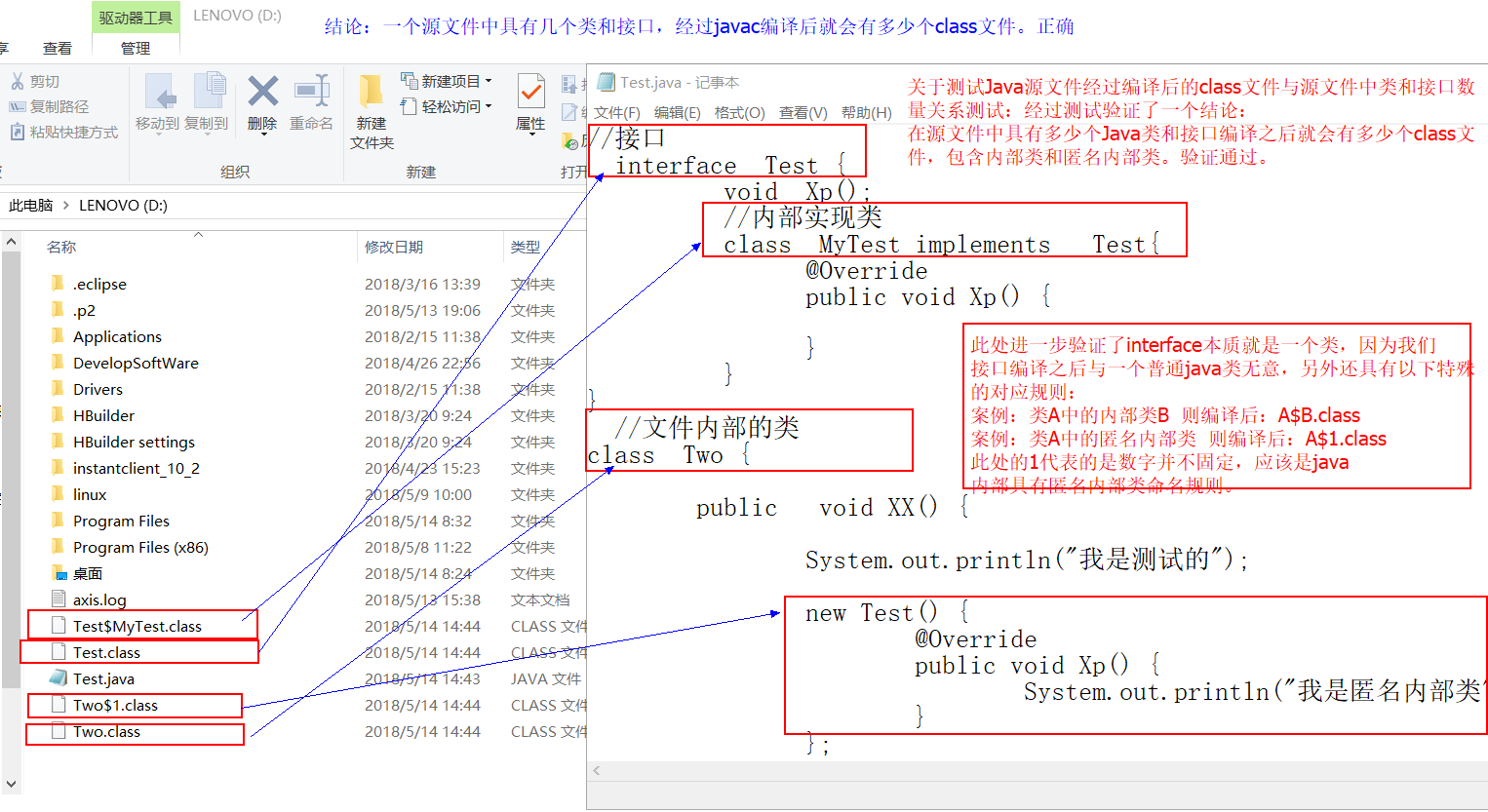
72、抽象类方法的访问权限默认都是public
A、正确
B、错误
关于抽象类
JDK 1.8以前,抽象类的方法默认访问权限为protected
JDK 1.8时,抽象类的方法默认访问权限变为default
关于接口
JDK 1.8以前,接口中的方法必须是public的
JDK 1.8时,接口中的方法可以是public的,也可以是default的
JDK 1.9时,接口中的方法可以是private的
73、最后输出什么
public void test() {
int a = 10;
System.out.println(a++ + a--);
}
A、19
B、20
C、21
D、22
后置运算符取当前值,然后再改变;前置运算符先改变,在获取当前值。
(a++ + a–)等于:
1.将a压栈(a=10)
2.a=a+1(a = 11)
3.运算符+压栈
4.将a压栈(a=11)
5.a=a-1(a=10)
74、将下列哪个代码(A、B、C、D)放入程序中标注的【代码】处将导致编译错误?
class A{
public float getNum(){
return 3.0f;
}
}
public class B extends A{
【代码】
}
A、public float getNum(){return 4.0f;}
B、public void getNum(){}
C、public void getNum(double d){}
D、public double getNum(float d){return 4.0d;}
Java重写有如下标准:
- 参数列表必须与被重写方法的相同。
- 重写方法不能限制比被重写方法更严格的访问级别
- 重写方法不能抛出新的异常或者比被重写方法声明的检查异常更广的检查异常
- 返回类型必须与被重写方法的返回类型相同。仅当返回值为类类型时,重写的方法才可以修改返回值类型,且必须是父类方法返回值的子类。
本题A选项符合要求,是正确的方法重写。
B选项返回值类型不同,不满足重写要求,B错误。
C、D选项并不是重写,只是一个同名函数。
综上所述答案选择B。
75、关于访问权限说法正确的是
A、外部类前面可以修饰public,protected和private
B、成员内部类前面可以修饰public,protected和private
C、局部内部类前面可以修饰public,protected和private
D、以上说法都不正确
可以把局部内部类当做一个局部变量,所以它是不需要加任何修饰符的
局部内部类前不能用修饰符public和private,protected
内部类就随意了。
(1)对于外部类而言,它也可以使用访问控制符修饰,但外部类只能有两种访问控制级别: public 和默认。因为外部类没有处于任何类的内部,也就没有其所在类的内部、所在类的子类两个范围,因此 private 和 protected 访问控制符对外部类没有意义。
(2)内部类的上一级程序单元是外部类,它具有 4 个作用域:同一个类(private)、同一个包( protected )和任何位置(public)。
(3) 因为局部成员的作用域是所在方法,其他程序单元永远不可能访问另一个方法中的局部变量,所以所有的局部成员都不能使用访问控制修饰符修饰。
76、下面有关maven和ant的描述,描述错误的是?
A、Ant 没有正式的约定如一个一般项目的目录结构,你必须明确的告诉 Ant 哪里去找源代码
B、Maven 拥有约定,因为你遵循了约定,它已经知道你的源代码在哪里
C、maven和ant都有“生命周期”的概念,当你输入一个命令后,maven或者ant会执行一系列的有序的步骤,直到到达你指定的生命周期
D、Ant构建文件默认命名为build.xml,Maven默认构建文件为pom.xml
Ant和Maven都是基于Java的构建(build)工具。理论上来说,有些类似于(Unix)C中的make ,但没有make的缺陷。Ant是软件构建工具,Maven的定位是软件项目管理和理解工具。 Ant特点 › 没有一个约定的目录结构 ›必须明确让ant做什么,什么时候做,然后编译,打包 ›没有生命周期,必须定义目标及其实现的任务序列 ›没有集成依赖管理 Maven特点 ›拥有约定,知道你的代码在哪里,放到哪里去 ›拥有一个生命周期,例如执行 mvn install 就可以自动执行编译,测试,打包等构建过程 ›只需要定义一个pom.xml,然后把源码放到默认的目录,Maven帮你处理其他事情 ›拥有依赖管理,仓库管理
Ant的作用:是一种基于Java的build工具
能够用ant编译java类。生成class文件
ant能够自己定义标签、配置文件,用于构建。
ant能够把相关层构建成jar包 。
ant把整个项目生成web包。并公布到Tomcat
Ant的长处:
跨平台性:Ant是纯Java语言编写的,因此具有非常好的跨平台性。
操作简单:Ant是由一个内置任务和可选任务组成的。Ant执行时须要一个XML文件(构建文件)。
Ant通过调用target树,就能够运行各种task:每一个task实现了特定接口对象。因为Ant构建文件时XML格式的文件。所以非常easy维护和书写,并且结构非常清晰。
Ant能够集成到开发环境中:因为Ant的跨平台性和操作简单的特点。它非常easy集成到一些开发环境中去。
Maven的作用: 除了以程序构建能力为特色之外,还提供高级项目管理工具。
Maven除了具备Ant的功能外。还添加了下面基本的功能:
使用Project Object Model来对软件项目管理。
内置了很多其它的隐式规则,使得构建文件更加简单。
内置依赖管理和Repository来实现依赖的管理和统一存储;
内置了软件构建的生命周期;
Maven的长处:
拥有约定,知道你的代码在哪里,放到哪里去
拥有一个生命周期,比如运行 mvn install就能够自己主动运行编译,測试。打包等构建过程
仅仅须要定义一个pom.xml,然后把源代码放到默认的文件夹,Maven帮你处理其它事情
拥有依赖管理。仓库管理
总体的比較:
Ant将提供了非常多能够重用的task,比如 copy, move, delete以及junit单元測试Maven则提供了非常多能够重用的过程。
77、java中Hashtable, Vector, TreeSet, LinkedList哪些线程是安全的?
A、Hashtable
B、Vector
C、TreeSet
D、LinkedList
线程安全概念:
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。

LinkedList 和 ArrayList 都是不同步的,线程不安全;
Vector 和 Stack 都是同步的,线程安全;
Set是线程不安全的;
Hashtable的方法是同步的,线程安全;
HashMap的方法不是同步的,线程不安全;
喂 SHE: 喂是指vector,S是指stack, H是指hashtable,E是指Eenumeration
78、常用的servlet包的名称是?
A、java.servlet
B、javax.servlet
C、servlet.http
D、javax.servlet.http
79、下面有关值类型和引用类型描述正确的是
A、值类型的变量赋值只是进行数据复制,创建一个同值的新对象,而引用类型变量赋值,仅仅是把对象的引用的指针赋值给变量,使它们共用一个内存地址。
B、值类型数据是在栈上分配内存空间,它的变量直接包含变量的实例,使用效率相对较高。而引用类型数据是分配在堆上,引用类型的变量通常包含一个指向实例的指针,变量通过指针来引用实例。
C、引用类型一般都具有继承性,但是值类型一般都是封装的,因此值类型不能作为其他任何类型的基类。
D、值类型变量的作用域主要是在栈上分配内存空间内,而引用类型变量作用域主要在分配的堆上。
引用类型的变量也在栈区,只是其引用的对象在堆区
80、以下说法错误的是
A、数组是一个对象
B、数组不是一种原生类
C、数组的大小可以任意改变
D、在Java中,数组存储在堆中连续内存空间里
Java中数组是对象,不是基本数据类型(原生类),大小不可变且连续存储,因为是对象所以存在堆中。
81、下列外部类定义中,不正确的是
A、class x { … }
B、class x extends y { … }
C、static class x implements y1,y2 { … }
D、public class x extends Applet { … }
内部类可以是静态static的,也可用public,default,protected和private修饰
外部类的修饰符只能是public,abstract,final ,缺省的(default)
static修饰的为类成员,会随着类的加载而加载,比如静态代码块,静态成员,静态方法(这里只是加载,并没有调用)等等,可以想象一下,如果把一个Class文件中的外部类设为static,目的难道是让这个类随着应用的启动而加载吗?如果在这次使用过程中根本没有使用过这个类,那么是不是就会浪费内存。这样来说设计不合理,总而言之,设计不合理的地方,Java是不会让它存在的。
而为什么内部类可以使用static修饰呢,因为内部类算是类的成员了,如果没有使用静态来修饰,那么在创建内部类的时候就需要先有一个外部类的对象,如果我们一直在使用内部类,那么内存中就会一直存在外部类的引用,而我们有时候只需要使用内部类,不需要外部类,那么还是会浪费内存,甚至会造成内存溢出。使用static修饰内部类之后,内部类在创建对象时就不需要有外部类对象的引用了。
最终结论就是:static可以用来修饰内部类,但是不可以用来修饰外部类
82、 以下 _____ 不是 Object 类的方法
A、clone()
B、finalize()
C、toString()
D、hasNext()

83、public interface IService {String NAME="default";}默认类型等价表示是哪一项:
A、public String NAME=“default”;
B、public static String NAME=“default”;
C、public static final String NAME=“default”;
D、private String NAME=“default”;
接口中的变量默认是public static final 的,方法默认是public abstract 的
84、对于非运行时异常,程序中一般可不做处理,由java虚拟机自动进行处理。
A、正确
B、错误
1.Java异常机制
Java把异常当做对象来处理,并定义一个基类java.lang.Throwable作为所有异常的超类。Java中的异常分为两大类:错误Error和异常Exception,Java异常体系结构如下图所示:
2.Throwable
Throwable类是所有异常或错误的超类,它有两个子类:Error和Exception,分别表示错误和异常。其中异常Exception分为运行时异常(RuntimeException)和非运行时异常,也称之为不检查异常(Unchecked Exception)和检查异常(Checked Exception)。
3.Error
一般是指java虚拟机相关的问题,如系统崩溃、虚拟机出错误、动态链接失败等,这种错误无法恢复或不可能捕获,将导致应用程序中断,通常应用程序无法处理这些错误,因此应用程序不应该捕获Error对象,也无须在其throws子句中声明该方法抛出任何Error或其子类。
4.运行时异常和非运行时异常
(1)运行时异常都是RuntimeException类及其子类异常,如NullPointerException、IndexOutOfBoundsException等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
当出现RuntimeException的时候,我们可以不处理。当出现这样的异常时,总是由虚拟机接管。比如:我们从来没有人去处理过NullPointerException异常,它就是运行时异常,并且这种异常还是最常见的异常之一。
出现运行时异常后,如果没有捕获处理这个异常(即没有catch),系统会把异常一直往上层抛,一直到最上层,如果是多线程就由Thread.run()抛出,如果是单线程就被main()抛出。抛出之后,如果是线程,这个线程也就退出了。如果是主程序抛出的异常,那么这整个程序也就退出了。运行时异常是Exception的子类,也有一般异常的特点,是可以被catch块处理的。只不过往往我们不对他处理罢了。也就是说,你如果不对运行时异常进行处理,那么出现运行时异常之后,要么是线程中止,要么是主程序终止。
如果不想终止,则必须捕获所有的运行时异常,决不让这个处理线程退出。队列里面出现异常数据了,正常的处理应该是把异常数据舍弃,然后记录日志。不应该由于异常数据而影响下面对正常数据的处理。
(2)非运行时异常是RuntimeException以外的异常,类型上都属于Exception类及其子类。如IOException、SQLException等以及用户自定义的Exception异常。对于这种异常,JAVA编译器强制要求我们必需对出现的这些异常进行catch并处理,否则程序就不能编译通过。所以,面对这种异常不管我们是否愿意,只能自己去写一大堆catch块去处理可能的异常。
- 常见RuntimeException:
ArrayStoreException: 试图将错误类型的对象存储到一个对象数组时抛出的异常
ClassCastException: 试图将对象强制转换为不是实例的子类时,抛出该异常
IllegalArgumentExceptio:抛出的异常表明向方法传递了一个不合法或不正确的参数
IndexOutOfBoundsException:指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出
NoSuchElementException:表明枚举中没有更多的元素
NullPointerException: 当应用程序试图在需要对象的地方使用 null 时,抛出该异常
85、在JAVA中,假设A有构造方法A(int a),则在类A的其他构造方法中调用该构造方法和语句格式应该为
A、this.A(x)
B、this(x)
C、super(x)
D、A(x)
A.这是调用普通方法的写法
C.这时显示调用父类构造方法
D.调用静态方法
86、在一个基于分布式的游戏服务器系统中,不同的服务器之间,哪种通信方式是不可行的
A、管道
B、消息队列
C、高速缓存数据库
D、套接字
对于管道,有下面这几种类型:
①普通管道(PIPE):通常有两种限制,一是单工,即只能单向传输;二是血缘,即常用于父子进程间(或有血缘关系的进程间)。
②流管道(s_pipe):去除了上述的第一种限制,实现了双向传输。
③命名管道(name_pipe):去除了上述的第二种限制,实现了无血缘关系的不同进程间通信。
显然,要求是对于不同的服务器之间的通信,是要要求全双工形式的,而管道只能是半双工,虽然可以双向,但是同一时间只能有一个方向传输。
什么是消息队列? 我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。
举例: 小红是小明的姐姐。 小红希望小明多读书,常寻找好书给小明看,之前的方式是这样:小红问小明什么时候有空,把书给小明送去,并亲眼监督小明读完书才走。久而久之,两人都觉得麻烦。 后来的方式改成了:小红对小明说「我放到书架上的书你都要看」,然后小红每次发现不错的书都放到书架上,小明则看到书架上有书就拿下来看。 书架就是一个消息队列,小红是生产者,小明是消费者。 这带来的好处有: 1.小红想给小明书的时候,不必问小明什么时候有空,亲手把书交给他了,小红只把书放到书架上就行了。这样小红小明的时间都更自由。 2.小红相信小明的读书自觉和读书能力,不必亲眼观察小明的读书过程,小红只要做一个放书的动作,很节省时间。 3.当明天有另一个爱读书的小伙伴小强加入,小红仍旧只需要把书放到书架上,小明和小强从书架上取书即可(唔,姑且设定成多个人取一本书可以每人取走一本吧,可能是拷贝电子书或复印,暂不考虑版权问题)。 4.书架上的书放在那里,小明阅读速度快就早点看完,阅读速度慢就晚点看完,没关系,比起小红把书递给小明并监督小明读完的方式,小明的压力会小一些。 这就是消息队列的四大好处: 1.解耦 每个成员不必受其他成员影响,可以更独立自主,只通过一个简单的容器来联系。 小红甚至可以不知道从书架上取书的是谁,小明也可以不知道往书架上放书的人是谁,在他们眼里,都只有书架,没有对方。 毫无疑问,与一个简单的容器打交道,比与复杂的人打交道容易一万倍,小红小明可以自由自在地追求各自的人生。 2.提速 小红选择相信「把书放到书架上,别的我不问」,为自己节省了大量时间。 小红很忙,只能抽出五分钟时间,但这时间足够把书放到书架上了。 3.广播 小红只需要劳动一次,就可以让多个小伙伴有书可读,这大大地节省了她的时间,也让新的小伙伴的加入成本很低。 4.削峰 假设小明读书很慢,如果采用小红每给一本书都监督小明读完的方式,小明有压力,小红也不耐烦。 反正小红给书的频率也不稳定,如果今明两天连给了五本,之后隔三个月才又给一本,那小明只要在三个月内从书架上陆续取走五本书读完就行了,压力就不那么大了。
1.管道(pipe)
管道是一种具有两个端点的通信通道,一个管道实际上就是只存在在内存中的文件,对这个文件操作需要两个已经打开文件进行,他们代表管道的两端,也叫两个句槟,管道是一种特殊的文件,不属于一种文件系统,而是一种独立的文件系统,有自己的数据结构,根据管道的使用范围划分为无名管道和命名管道。
无名管道用于父进程和子进程之间,通常父进程创建管道,然后由通信的子进程继承父进程的读端点句柄和写端点句柄,或者父进程有读写句柄的子进程,这些子进程可以使用管道直接通信,不需要通过父进程。
命名管道,命名管道是为了解决无名管道只能在父子进程间通信而设计的,命名管道是建立在实际的磁盘介质或文件系统(而不是只存在内存中),任何进程可以通过文件名或路径建立与该文件的联系,命名换到需要一种FIFO文件(有先进先出的原则),虽然FIFO文件的inode节点在磁盘上,但仅是一个节点而已,文件的数据还是存在于内存缓冲页面中,和普通管道相同。
2.信号
信号,用于接受某种事件发生,除了用于进程间通信之外,进程还可以发送信号给进程本身。除了系统内核和root之外,只有具备相同id的进程才可以信号进行通信。
3.消息队列
消息队列是消息的链表,包括Posix消息队列和system v消息队列(Posix常用于线程,system常用于进程),有权限的进程可以向消息队列中添加消息,有读权限的进程可以读走消息队列的消息。
消息队列克服了信号承载信息量少,管道只能承载无格式字节流及缓冲区大小受限等缺陷。
4.共享内存
共享内存使多个进程可以访问同一块内存空间,是最快的IPC形式,是针对其他通信方式运行效率低而设计的,往往与其他进程结合使用,如与信号量结合,来达到进程间的同步与互斥。传递文件最好用共享内存的方式。
87、下面属于java包装类的是
A、String
B、Long
C、Character
D、Short
Java 语言是一个面向对象的语言,但是Java中的基本数据类型却是不面向对象的,这在实际使用时存在很多的不便,为了解决这个不足,在设计类时为每个基本数据类型设计了一个对应的类进行代表,即包装类。对应的基本类型和包装类如下表: 基本数据类型 包装类 byte Byte boolean Boolean short Short char Character int Integer long Long float Float double Double
88、以下哪个不能用来处理线程安全
A、synchronized关键字
B、volatile关键字
C、Lock类
D、transient关键字
synchrozied关键字称作同步,主要用来给方法、代码块加锁,被加锁的代码段,同一时间内多线程同时访问同一对象的加锁方法/代码块时,只能有一个线程执行能执行方法/代码块中的代码,其余线程必须等待当前线程执行完以后才执行该方法/代码块。
volatile关键字1.保证了不同线程对该变量操作的内存可见性.(当一个线程修改了变量,其他使用次变量的线程可以立即知道这一修改)。2.禁止了指令重排序.
Lock接口提供了与synchronized关键字类似的同步功能,但需要在使用时手动获取锁和释放锁。
transient关键字简单地说,就是让某些被修饰的成员属性变量不被序列化。
89、通过以下哪些方法可反射获取到User对象中static属性的值?
A、User. class. getDeclaredField (“name”). get (null);
B、User. class. getField (“name”). get (null);
C、User user=new User(); return user. getClass(). getField (“name”).get (user);
D、User user=new User(): return user. getClass(). getDeclaredField (“name”). get (user);
90、下面哪个选项没有实现 java.util.Map 接口?
A、Hashtable
B、HashMap
C、Vector
D、IdentityHashMap
91、JDK8及之后版本,HashMap的数据结构是怎样的?
A、数组
B、链表
C、数组+链表/红黑树
D、二叉树
JDK8之前版本,HashMap的数据结构是数组+链表,JDK8及其以后版本,HashMap的数据结构是数组+链表+红黑树。
92、关于以下程序代码的说明正确的
class HasStatic{
private static int x = 100;
public static void main(String args[ ]){
HasStatic hs1 = new HasStatic();
hs1.x++;
HasStatic hs2 = new HasStatic();
hs2.x++;
hs1=new HasStatic();
hs1.x++;
HasStatic.x--;
System.out.println( "x=" +x);
}
}
A、5行不能通过编译,因为引用了私有静态变量
B、10行不能通过编译,因为x是私有静态变量
C、程序通过编译,输出结果为:x=103
D、程序通过编译,输出结果为:x=102
我感觉主要原因应该是main方法和静态私有变量处在同一个类中,变量对main方法是可见的,所以可以访问,如果不在同一个类里面的话,是不可以访问私有变量的。
93、关于以下application,说法正确是什么
public class Test {
static int x=10;
static {x+=5;}
public static void main(String[] args) { //4
System.out.println("x="+x);
}
static{x/=3;};//9
}
A、4行与9行不能通过编译,因为缺少方法名和返回类型
B、编译通过,执行结果是:x=5
C、编译通过,执行结果是:x=3
D、9行不能通过编译,因为只能有一个静态初始化器
94、对于子类的构造函数说明,下列叙述中错误的是
A、子类不能继承父类的无参构造函数。
B、子类可以在自己的构造函数中使用super关键字来调用父类的含参数构造函数,但这个调用语句必须是子类构造函数的第一个可执行语句。
C、在创建子类的对象时,若不含带参构造函数,将先执行父类的无参构造函数,然后再执行自己的无参构造函数。
D、子类不但可以继承父类的无参构造函数,也可以继承父类的有参构造函数。
构造函数不能被继承,构造方法只能被显式或隐式的调用。
95、下列关于JAVA多线程的叙述正确的是
A、调用start()方法和run()都可以启动一个线程
B、CyclicBarrier和CountDownLatch都可以让一组线程等待其他线程
C、Callable类的call()方法可以返回值和抛出异常
D、新建的线程调用start()方法就能立即进行运行状态
A.start是开启线程,run是线程的执行体,run是线程执行的入口。
B.CyclicBarrier和CountDownLatch都可以让一组线程等待其他线程。前者是让一组线程相互等待到某一个状态再执行。后者是一个线程等待其他线程结束再执行。
C.Callable中的call比Runnable中的run厉害就厉害在有返回值和可以抛出异常。同时这个返回值和线程池一起用的时候可以返回一个异步对象Future。
D.start是把线程从new变成了runnable
96、实现或继承了Collection接口的是
A、Map
B、List
C、Vector
D、Iterator
E、Set
Map不属于集合类。
vector实现list接口,list继承collection接口,set也继承collection接口。
collection没有继承Iterator接口,而是Iterable
97、往OuterClass类的代码段中插入内部类声明, 哪一个是错误的:
public class OuterClass{
private float f=1.0f;
//插入代码到这里
}
A、class InnerClass{ public static float func(){return f;} }
B、abstract class InnerClass{ public abstract float func(){} }
C、static class InnerClass{ protected static float func(){return f;} }
D、public class InnerClass{ static float func(){return f;} }
1.静态内部类才可以声明静态方法
2.静态方法不可以使用非静态变量
3.抽象方法不可以有函数体
98、下面几个关于Java里queue的说法哪些是正确的
A、LinkedBlockingQueue是一个可选有界队列,不允许null值
B、PriorityQueue,LinkedBlockingQueue都是线程不安全的
C、PriorityQueue是一个无界队列,不允许null值,入队和出队的时间复杂度是O(log(n)
D、PriorityQueue,ConcurrentLinkedQueue都遵循FIFO原则
A.LinkedBlockingQueue是一个基于节点链接的可选是否有界的阻塞队列,不允许null值。
B.LinkedBlockingQueue是一个线程安全的阻塞队列,实现了先进先出等特性。
C.PriorityQueue是一个队列,不允许null值,入队和出队的时间复杂度是O(log(n))
D.PriorityQueue是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素。ConcurrentLinkedQueue是一个基于链接节点的***线程安全队列,该队列的元素遵循FIFO原则。
99、在基本JAVA类型中,如果不明确指定,整数型的默认是什么类型?带小数的默认是什么类型?
A、int float
B、int double
C、long float
D、long double
整数类型 默认为 int 带小数的默认为 double boolean的默认值 false
100、String s = new String(“xyz”);创建了几个StringObject
A、两个或一个都有可能
B、两个
C、一个
D、三个
如果常量池没有,就会在常量池创建一个xyz字符串,然后执行new,在堆中再创建一个字符串;
如果常量池有,就会根据常量池中的xyz字符串,在堆中new一个新的字符串。
另外,字符串常量池在jdk1.7之后,也是存在于堆区。且常量池中保存的只是字符串的引用,实际上我们所说的常量池中的字符串,也是在堆中创建,但是他的引用在常量池中。
101、以下说法错误的是
A、虚拟机中没有泛型,只有普通类和普通方法
B、所有泛型类的类型参数在编译时都会被擦除
C、创建泛型对象时请指明类型,让编译器尽早的做参数检查
D、泛型的类型擦除机制意味着不能在运行时动态获取List<T>中T的实际类型
JVM是如何获取具体类型的呢,答案是强大的反射机制,也正因为有了反射才促生了泛型,所以D错。
1、创建泛型对象的时候,一定要指出类型变量T的具体类型。争取让编译器检查出错误,而不是留给JVM运行的时候抛出类不匹配的异常。
2、JVM如何理解泛型概念 —— 类型擦除。事实上,JVM并不知道泛型,所有的泛型在编译阶段就已经被处理成了普通类和方法。 处理方法很简单,我们叫做类型变量T的擦除(erased) 。
总结:泛型代码与JVM
① 虚拟机中没有泛型,只有普通类和方法。
② 在编译阶段,所有泛型类的类型参数都会被Object或者它们的限定边界来替换。(类型擦除)
③ 在继承泛型类型的时候,桥方法的合成是为了避免类型变量擦除所带来的多态灾难。无论我们如何定义一个泛型类型,相应的都会有一个原始类型被自动提供。原始类型的名字就是擦除类型参数的泛型类型的名字。

102、volatile关键字的说法错误的是
A、能保证线程安全
B、volatile关键字用在多线程同步中,可保证读取的可见性
C、JVM保证从主内存加载到线程工作内存的值是最新的
D、volatile能禁止进行指令重排序
A选项:volatile单纯使用不能保证线程安全,他只是提供了一种弱的同步机制来确保修饰的变量的更新操作通知到其他线程,A选项说法错误
B选项:对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。B选项说法正确。
C选项: 对于用volatile修饰的变量,JVM虚拟机会保证从主内存加载到线程工作内存的值是最新的,例如线程1和线程2在进行read和load的操作中,发现主内存中某个变量的值都是5,那么都会加载这个最新的值。这也是可见性的一种体现。C选项说法正确。
D选项:volatile的底层是采用内存屏障来实现的,就是在编译器生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。D选项说法正确。
Java中Volatile关键字详解 - 郑斌blog - 博客园 (cnblogs.com)
103、JDK1.8版本之前,抽象类和接口的区别,以下说法错误的是
A、接口是公开的,里面不能有私有的方法或变量,是用于让别人使用的,而抽象类是可以有私有方法或私有变量的。
B、abstract class 在 Java 语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface,实现多重继承。接口还有标识(里面没有任何方法,如Remote接口)和数据共享(里面的变量全是常量)的作用。
C、在abstract class 中可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(也就是必须是 static final的,不过在 interface中一般不定义数据成员),所有的成员方法默认都是 public abstract 类型的。
D、abstract class和interface所反映出的设计理念不同。其实abstract class表示的是"has-a"关系,interface表示的是"is-a"关系。
is-a,理解为是一个,代表继承关系。 如果A is-a B,那么B就是A的父类。
like-a,理解为像一个,代表组合关系。 如果A like a B,那么B就是A的接口。
has-a,理解为有一个,代表从属关系。 如果A has a B,那么B就是A的组成部分。
1)接口可以继承接口,而且可以继承多个接口,但是不能实现接口,因为接口中的方法全部是抽象的,无法实现;
另外,如果是Java 7以及以前的版本,那么接口中可以包含的内容有:1. 常量;2. 抽象方法
如果是Java 8,还可以额外包含有:3. 默认方法;4. 静态方法
如果是Java 9,还可以额外包含有:5. 私有方法
2)普通类可以实现接口,并且可以实现多个接口,但是只能继承一个类,这个类可以是抽象类也可以是普通类,如果继承抽象类,必须实现抽象类中的所有抽象方法,否则这个普通类必须设置为抽象类;
3)抽象类可以实现接口,可以继承具体类,可以继承抽象类,也可以继承有构造器的实体类。
抽象类中可以有静态main方法;抽象类里可以没有抽象方法,没有抽象方法的抽象类就是不想让别人实例化它;
另外,抽象类可以有构造方法,只是不能直接创建抽象类的实例对象而已。在继承了抽象类的子类中通过super(参数列表)调用抽象类中的构造方法,可以用于实例化抽象类的字段。
下面总结常见的抽象类与接口的区别:
1)抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象;
2)接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现(java8中 接口可以有实现方法 使用default修饰);
3)接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量;
4)抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个类实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类;
5)抽象方法要被实现,所以不能是静态static的,也不能是私有private的,也不能被final修饰(试想一下,静态方法可以被类名直接调用,而类名直接调用一个没有实现的抽象方法没有意义)。
104、下列Java代码中的变量a、b、c分别在内存的____存储区存放
class A {
private String a = "aa";
public boolean methodB() {
String b = "bb";
final String c = "cc";
}
}
A、堆区、堆区、堆区
B、堆区、栈区、堆区
C、堆区、栈区、栈区
D、堆区、堆区、栈区
E、静态区、栈区、堆区
F、静态区、栈区、栈区
105、设int x=1,float y=2,则表达式x/y的值是
A、0
B、1
C、2
D、0.5
本题的意义在于两点,明白这两点之后题会不会本身就不重要了:①float x = 1;与float x = 1.0f,这两种对于float类型的变量来说定义的方式都是正确的,也是比较常见的笔试题里面考察类型转换的例子,当第一种情况时,是将低精度int向上转型到float,是由于java的特性导致而不需要进行强制转换,而第二种情况则是比较正式的对于float变量的定义,由于这种类型本身在工作项目中并不常见,常用的带小数的数字我们一般都直接使用double类型,而double类型直接定义是没有问题的:double x = 1.0。而由于float的精度没有double类型高,因此必须对其进行显示的格式书写,如果没有这个f,就默认是double类型了。当然double x = 1.0d也是正确的命名,不信你可以尝试,虽然这是一个令人窒息的操作。②当多个精度的数字同时进行运算时,最终结果以最高精度为准。在多数情况下,整数和小数的各级混合运算中,一般结果都是double类型的。但就本题而言,结果是float类型的,因为x,y两个数字精度最高的就是float,所以最终结果是0.5,并且这个0.5是float类型的。为什么说不是double类型呢,当然如果你这样处理:double m = x/y,当然m是double类型的,也不会报错,而如果你写成int m = x/y,编译器报错提示的时候就会让你转换成float或者进行强制转换成int,他是不会提示你转换成double的,尽管这么写并没有报错,原因就是① 中所说的向上强转。float转换成double不需要任何提示。
106、关于下面程序,哪些描述是正确的:
public class While {
public void loop() {
int x= 10;
while ( x ) {
System.out.print("x minus one is " + (x - 1));
x -= 1;
}
}
}
A、行1有语法错误
B、行4有语法错误
C、行2有语法错误,loop是关键字
D、程序能够正常编译和运行
while()括号里参数必须是布尔类型,要么true要么false
107、从以下四个选项选出不同的一个。
A、LVS
B、Nginx
C、Lighttpd
D、Apache
LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。
Nginx (“engine x”) 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。
Lighttpd 是一个德国人领导的开源Web服务器软件,其根本的目的是提供一个专门针对高性能网站,安全、快速、兼容性好并且灵活的web server环境。具有非常低的内存开销、cpu占用率低、效能好以及丰富的模块等特点。
Apache是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一。
108、以下哪个类包含方法flush()
A、InputStream
B、OutputStream
C、A 和B 选项都包含
D、A 和B 选项都不包含
1)对于字符写出流,如FileWriter,必须要使用到flush将字符缓冲区的内容写到文件中。字符缓冲区的数据是按字符算的,必须集齐一个字符(汉字是2个字符或者3个字符)的数据才能将数据写入文件;
2)对于字节写出流,如FileOutputStream等,他们可以直接把数据写入文件,不需要用到flush()刷新,因为他们是一个字节一个字节写入的。
但是,字节写出流也有flush()方法(继承自父类OutoutStream)为何字节流的类要提供flush()这个方法呢?
查看API知道,OutputStream的直接子类有:FileOutputStream, FilterOutputStream, ObjectOutputStream, OutputStream, PipedOutputStream,ByteArrayOutputStream等,其中绝大部重写flush方法的子类调用的还是父类的空的flush方法。
我们查看FilterOutputStream的子类BufferedOutputStream重写的flush方法,调用了flushBuffer()方法,可以知道构造器的默认缓冲区是8k,如果读取的文件小于8k而没有调用flush方法,就不会将缓冲数据写到输出流,文件内容为空。

109、下面有关 java 类加载器,说法正确的是?
A、引导类加载器(bootstrap class loader):它用来加载 Java 的核心库,是用C++来实现的
B、扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。
C、系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类
D、tomcat 为每个 App 创建一个 Loader,里面保存着此 WebApp 的 ClassLoader。需要加载 WebApp 下的类时,就取出 ClassLoader 来使用
引导类加载器(bootstrap class loader):它用来加载 Java 的核心库,是用原生代码来实现的 注:元题目并没有指定是C++,而是说原生代码实现。
虚拟机上说Hotspot是由c++实现的,想MRP、Maxine等虚拟机,整个虚拟机本身都是由java编写的,自然Bootstrap ClassLoader是由java语言实现的
110、关于volatile关键字,下列描述不正确的是?
A、用volatile修饰的变量,每次更新对其他线程都是立即可见的。
B、对volatile变量的操作是原子性的。
C、对volatile变量的操作不会造成阻塞。
D、不依赖其他锁机制,多线程环境下的计数器可用volatile实现。
在JVM中,有主内存和工作内存的概念,每个线程对应一个工作内存,并共享主内存数据,
1. 对于普通变量:读操作会优先读取工作内存的数据,如果工作内存不存在,则从主内存中拷贝一份数据到工作内存,写操作只会修改工作内存中的副本数据,这种情况下,其他线程就无法读取变脸的最新值。
2. 对于volatile变量:读操作时JVM会把工作内存中对应的值设置为无效,要求线程从主内存中读取数据,写操作JVM也会把工作内存中对应的数据刷新到主内存中,这种情况下,其他线程就可以读取变量的最新值。
volatile变量的内存可见性,是基于内存屏蔽实现的,内存屏蔽也就是一个CPU指令。在程序运行的时候,为了提高执行性能,编译器和处理器会对指令进行重排序,JVM为了保证不同的编译器和CPU上有相同的结果,通过插入特定类型的内存屏蔽来禁止特定类型的编译器重排序和处理器重排序,插入一条内存屏蔽会告诉编译器和CPU,不管什么指令都不能和这条内存屏蔽指令重排序。
处理器为了提高处理速度,不直接和内存进行通讯,而是将系统内存的数据独到内部缓存后再进行操作,但操作完后不知什么时候会写到内存。
如果对声明了volatile变量进行写操作时,JVM会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写会到系统内存。 这一步确保了如果有其他线程对声明了volatile变量进行修改,则立即更新主内存中数据。
但这时候其他处理器的缓存还是旧的,所以在多处理器环境下,为了保证各个处理器缓存一致,每个处理会通过嗅探在总线上传播的数据来检查 自己的缓存是否过期,当处理器发现自己缓存行对应的内存地址被修改了,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作时,会强制重新从系统内存把数据读到处理器缓存里。 这一步确保了其他线程获得的声明了volatile变量都是从主内存中获取最新的。
1. volatile只保证了可见性和防止了指令重排序,并没有保证原子性。
2. volatile修饰的变量只是保证了每次读取时都从主存中读,每次修改时,都将修改后的值重新写入了主存。
3. 在synchronized修饰的方法体或者常量(final)不需要使用volatile。
4. 由于使用了volatile屏蔽掉了JVM中必要的代码优化,所以在效率上比较低,因此一定在必要的时候才能使用该关键字。
111、java7后关键字 switch 支不支持字符串作为条件:
A、支持
B、不支持
switch(exp),在JDK7之前,只能是byte、short、char、int或者对应的包装类,或者枚举常量(内部也是由整型或字符类型实现)。
为什么必须是这些呢,因为其实exp只是对int型支持的,其他都是因为可以自动拆卸或者自动向上转型到int,所以才可以。
到了JDK7的时候,String被引入了,为什么String能被引入呢?
其实本质上还是对int类型值得匹配。
原理如下,通过对case后面得String对象调用hashCode方法,得到一个int类型得hash值,然后用这个hash值来唯一标识这个case。那么当匹配时,首先调用exp的hashCode,得到exp的hash值,用这个hash值来匹配所有case,如果没有匹配成功,就说明不存在;如果匹配成功了,接着会调用字符串的equals方法进行匹配。(hash值一致,equals可不一定返回的就是true)。
所以,exp不能为null,cas子句使用的字符串也不能为null,不然会出现空指针异常。
112、下列哪种异常是检查型异常,需要在编写程序时声明?
A、NullPointerException
B、ClassCastException
C、FileNotFoundException
D、IndexOutOfBoundsException
113、java用()机制实现了线程之间的同步执行
A、监视器
B、虚拟机
C、多个CPU
D、异步调用
首先jvm中没有进程的概念 ,但是jvm中的线程映射为操作系统中的进程,对应关系为1:1。那这道题的问的就是jvm中线程如何异步执行 。 在jvm中 是使用监视器锁来实现不同线程的异步执行, 在语法的表现就是synchronized 。
114、off-heap是指那种内存
A、JVM GC能管理的内存
B、JVM进程管理的内存
C、在JVM老年代内存区
D、在JVM新生代内存
off-heap叫做堆外内存,将你的对象从堆中脱离出来序列化,然后存储在一大块内存中,这就像它存储到磁盘上一样,但它仍然在RAM中。对象在这种状态下不能直接使用,它们必须首先反序列化,也不受垃圾收集。序列化和反序列化将会影响部分性能(所以可以考虑使用FST-serialization)使用堆外内存能够降低GC导致的暂停。堆外内存不受垃圾收集器管理,也不属于老年代,新生代。
115、下列说法正确的是
A、我们直接调用Thread对象的run方法会报异常,所以我们应该使用start方法来开启一个线程
B、一个进程是一个独立的运行环境,可以被看做一个程序或者一个应用。而线程是在进程中执行的一个任务。Java运行环境是一个包含了不同的类和程序的单一进程。线程可以被称为轻量级进程。线程需要较少的资源来创建和驻留在进程中,并且可以共享进程中的资源
C、synchronized可以解决可见性问题,volatile可以解决原子性问题
D、ThreadLocal用于创建线程的本地变量,该变量是线程之间不共享的
116、以下会产生精度丢失的类型转换是
A、float a=10
B、int a=(int)8846.0
C、byte a=10; int b=-a
D、double d=100
精度丢失不仅仅代表值丢失,10.0->10和10.1->10这都叫做精度丢失。精度丢失只会发生在大单位化成小单位的情况,选项中只有B是double转化为int符合大转下情况
117、下面代码运行结果是?
class Value{
public int i=15;
}
public class Test{
public static void main(String argv[]){
Test t=new Test( );
t.first( );
}
public void first( ){
int i=5;
Value v=new Value( );
v.i=25;
second(v,i);
System.out.println(v.i);
}
public void second(Value v,int i){
i = 0;
v.i = 20;
Value val = new Value( );
v = val;
System.out.println(v.i+" "+i);
}
}
A、15 0 20
B、15 0 15
C、20 0 20
D、0 15 20
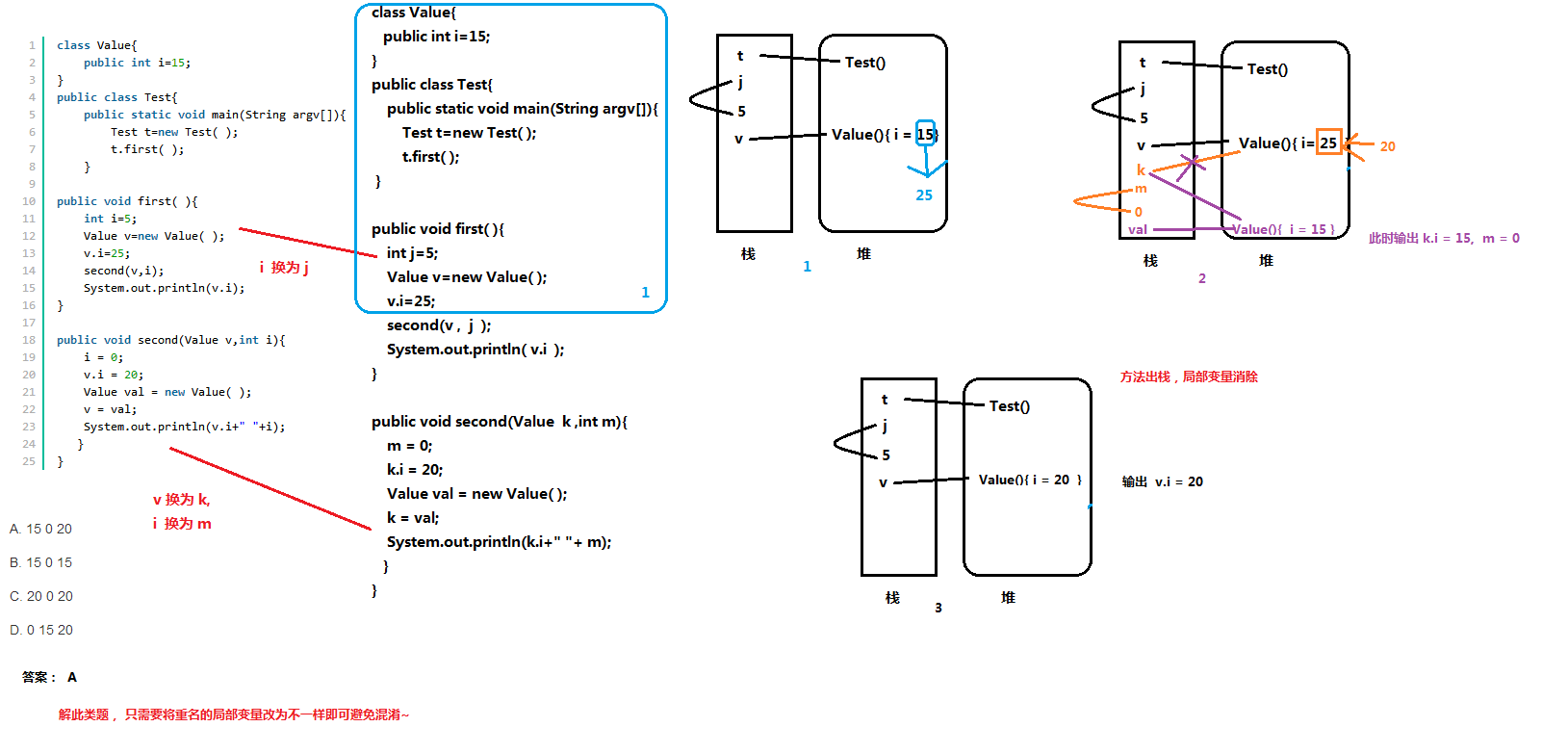
118、说明输出结果。
import java.util.Date;
public class SuperTest extends Date{
private static final long serialVersionUID = 1L;
private void test(){
System.out.println(super.getClass().getName());
}
public static void main(String[]args){
new SuperTest().test();
}
}
A、SuperTest
B、SuperTest.class
C、test.SuperTest
D、test.SuperTest.class
super.getClass().getName() 返回:包名+类名
super.getClass().getSuperclass() 返回:包名+父类名
119、下面有关java类加载器,说法正确的是?
A、引导类加载器(bootstrap class loader):它用来加载 Java 的核心库,是用原生代码来实现的
B、扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。
C、系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类
D、tomcat为每个App创建一个Loader,里面保存着此WebApp的ClassLoader。需要加载WebApp下的类时,就取出ClassLoader来使用
120、下列叙述中,错误的是( )
A、File类能够存储文件属性
B、File类能够读写文件
C、File类能够建立文件
D、File类能够获取文件目录信息
能够读写文件的是数据流(OutputStream和InputStream)
121、可以放入到横线位置,使程序正确编译运行,而且不产生错误的选项是( )
class A{
public A foo() {
return this;
}
}
class B extends A {
public A foo(){
return this;
}
}
class C extends B {
_______
}
A、public void foo(){}
B、public int foo(){return 1;}
C、public A foo(B b){return b;}
D、public A foo(){return A;}
重写 要求两同两小一大原则, 方法名相同,参数类型相同,子类返回类型小于等于父类方法返回类型, 子类抛出异常小于等于父类方法抛出异常, 子类访问权限大于等于父类方法访问权限。[注意:这里的返回类型必须要在有继承关系的前提下比较]
重载 方法名必须相同,参数类型必须不同,包括但不限于一项,参数数目,参数类型,参数顺序
再来说说这道题 A B 都是方法名和参数相同,是重写,但是返回类型没与父类返回类型有继承关系,错误 D 返回一个类错误 。C的参数类型与父类不同,所以不是重写,可以理解为广义上的重载访问权限小于父类,都会显示错误。虽然题目没点明一定要重载或者重写,但是当你的方法名与参数类型与父类相同时,已经是重写了,这时候如果返回类型或者异常类型比父类大,或者访问权限比父类小都会编译错误
122、文件名称:forward.jsp,如果运行以上jsp文件,地址栏的内容为
<html>
<head><title> 跳转 </title> </head>
<body>
<jsp:forward page="index.htm"/>
</body>
</html>
A、http://127.0.0.1:8080/myjsp/forward.jsp
B、http://127.0.0.1:8080/myjsp/index.jsp
C、http://127.0.0.1:8080/myjsp/index.htm
D、http://127.0.0.1:8080/myjsp/forward.htm
redirect:请求重定向:客户端行为,本质上为2次请求,地址栏改变,前一次请求对象消失。举例:你去银行办事(forward.jsp),结果告诉你少带了东西,你得先去局办(index.html)临时身份证,这时你就会走出银行,自己前往局,地址栏变为index.html.
forward:请求转发:服务器行为,地址栏不变。举例:你把钱包落在出租车上,你去警察局(forward.jsp)报案,警察局说钱包落在某某公司的出租车上(index.html),这时你不用亲自去找某某公司的出租车,警察局让出租车自己给你送来,你只要在警察局等就行。所以地址栏不变,依然为forward.jsp
123、以下哪种JAVA的变量表达式使得变量a和变量b具有相同的内存引用地址
A、String a = “hello”; String b = “hello”;
B、Integer a; Integer b = a;
C、int a = 1; Integer b = new Integer(1);
D、int a = 1; Integer b = 1;
(1)int与Integer、new Integer()进行==比较时,结果永远为true
(2)Integer与new Integer()进行==比较时,结果永远为false
(3)Integer与Integer进行==比较时,看范围;在大于等于-128小于等于127的范围内为true,在此范围外为false。
D选项我认为是错误的,a==b结果虽然结果是true,但是要注意的是,这是一个int与Integer的比较,Integer会进行拆箱,拆箱的结果是int型的,这就相当于两个int型之间的比较,而基本数据类型之间的比较,比较的是*数值*,所以结果是true,但并不表示两者的内存地址相等。
124、下面哪些类可以被继承?
A、Thread
B、Number
C、Double
D、Math
E、ClassLoader
125、下面有关 JAVA 异常类的描述,说法正确的有
A、异常的继承结构:基类为 Throwable,Error 和 Exception 。实现 Throwable, RuntimeException 和 IOException 等继承 Exception
B、非 RuntimeException 一般是外部错误(不考虑Error的情况下),其可以在当前类被 try{}catch 语句块所捕获
C、Error 类体系描述了 Java 运行系统中的内部错误以及资源耗尽的情形,Error 不需要捕捉
D、RuntimeException 体系包括错误的类型转换、数组越界访问和试图访问空指针等等,必须 被 try{}catch 语句块所捕获
126、子类要调用继承自父类的方法,必须使用super关键字。
A、正确
B、错误
如果子类没有重写父类的方法,super是可以省略;若是子类重写了父类的方法,再调用父类方法时要有super
127、下面关于静态方法说明正确的是
A、在静态方法中可用this来调用本类的类方法
B、在静态方法中调用本类的静态方法时可直接调用
C、在静态方法中只能调用本类中的静态方法
D、在静态方法中绝对不能调用实例方法
A错误:静态方法中没有this关键词,因为静态方法是和类同时被加载的,而this是随着对象的创建存在的,静态比对象优先存在。也就是说,静态可以访问静态,但静态不能访问非静态而非静态可以访问静态。
C错误:在静态方法中可直接调用本类的静态方法,也可以通过类名.静态方法名的方式来调用其他类的静态方法。
D错误:静态方法不能直接调用实例方法和对象,但可以通过在静态方法中创建类的实例的方式间接调用。
128、下面有关jdbc statement的说法错误的是
A、JDBC提供了Statement、PreparedStatement 和 CallableStatement三种方式来执行查询语句,其中 Statement 用于通用查询, PreparedStatement 用于执行参数化查询,而 CallableStatement则是用于存储过程
B、对于PreparedStatement来说,数据库可以使用已经编译过及定义好的执行计划,由于 PreparedStatement 对象已预编译过,所以其执行速度要快于 Statement 对象”
C、PreparedStatement中,“?” 叫做占位符,一个占位符可以有一个或者多个值
D、PreparedStatement可以阻止常见的SQL注入式攻击
1.Statement、PreparedStatement和CallableStatement都是接口(interface)。
2.Statement继承自Wrapper、PreparedStatement继承自Statement、CallableStatement继承自PreparedStatement。
3.Statement接口提供了执行语句和获取结果的基本方法; PreparedStatement接口添加了处理 IN 参数的方法; CallableStatement接口添加了处理 OUT 参数的方法。
4.a.Statement:
普通的不带参的查询SQL;支持批量更新,批量删除;
b.PreparedStatement:
可变参数的SQL,编译一次,执行多次,效率高;
安全性好,有效防止Sql注入等问题;
支持批量更新,批量删除;
c.CallableStatement:
继承自PreparedStatement,支持带参数的SQL操作;
支持调用存储过程,提供了对输出和输入/输出参数(INOUT)的支持;
Statement每次执行sql语句,数据库都要执行sql语句的编译 , 最好用于仅执行一次查询并返回结果的情形,效率高于PreparedStatement。
PreparedStatement是预编译的,使用PreparedStatement有几个好处
1.在执行可变参数的一条SQL时,PreparedStatement比Statement的效率高,因为DBMS预编译一条SQL当然会比多次编译一条SQL的效率要高。
2.安全性好,有效防止Sql注入等问题。
3.对于多次重复执行的语句,使用PreparedStament效率会更高一点,并且在这种情况下也比较适合使用batch;
4.代码的可读性和可维护性
129、下列关于Java并发的说法中正确的是
A、CopyOnWriteArrayList适用于写多读少的并发场景
B、ReadWriteLock适用于读多写少的并发场景
C、ConcurrentHashMap的写操作不需要加锁,读操作需要加锁
D、只要在定义int类型的成员变量i的时候加上volatile关键字,那么多线程并发执行i++这样的操作的时候就是线程安全的了
A:CopyOnWrite适用于读多写少的并发场景。
B:正确
C:ConcurrentHashMap,读操作不需要加锁,写操作需要加锁
D:对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
130、下列关于容器集合类的说法正确的是?
A、LinkedList继承自List
B、AbstractSet继承自Set
C、HashSet继承自AbstractSet
D、WeakMap继承自HashMap
131、以下哪几个是java中的集合类型?
A、Vector
B、Set
C、String
D、List
132、下面哪些情况会引发异常:
A、数组越界
B、指定URL不存在
C、使用throw语句抛出
D、使用throws语句
1、throws出现在方法头,throw出现在方法体
2、throws表示出现异常的一种可能性,并不一定会发生异常;throw则是抛出了异常,执行throw则一定抛出了某种异常。
3、两者都是消极的异常处理方式,只是抛出或者可能抛出异常,是不会由函数处理,真正的处理异常由它的上层调用处理。
133、下列正确的有()
A、call by value不会改变实际参数的数值
B、call by reference能改变实际参数的参考地址
C、call by reference不能改变实际参数的参考地址
D、call by reference能改变实际参数的内容
在程序语言中有两种参数传递方式:
1、按值传递(传递数值)
2、按引用传递(传递对象的引用,即数据的地址)
一、按值传递 call by value
1、不会改变传递的数值大小
二、按引用传递 call by reference
1、不会改变传递的数据的地址
2、可以改变传递的数据参数内容
134、以下选项中,合法的赋值语句是
A、a>1;
B、i++;
C、a= a+1=5;
D、y = int(i);
D项,y=(int)i
135、以下代码的输出的正确结果是
public class Test {
public static void main(String args[]) {
String s = "祝你考出好成绩!";
System.out.println(s.length());
}
}
A、24
B、16
C、15
D、8
java的String底层是char数组,它的length()返回数组大小,而unicode中一个汉字是可以用一个char表示的
String的 lengt() 方法在String.class中是这样的
public int length() {
return value.length;
}
这里的value又是一个char类型的数组
private final char value[];
所以,length() 方法返回的就是这个 char 类型数组的长度
136、有以下一个对象:
public class DataObject implements Serializable{
private static int i=0;
private String word=" ";
public void setWord(String word){
this.word=word;
}
public void setI(int i){
Data0bject.i=i;
}
}
创建一个如下方式的DataObject:
DataObject object=new Data0bject ( );
object.setWord("123");
object.setI(2);
将此对象序列化为文件,并在另外一个JVM中读取文件,进行反序列化,请问此时读出的Data0bject对象中的word和i的值分别为:
A、“”, 0
B、“”, 2
C、“123”, 2
D、“123”, 0
D,序列化保存的是对象的状态,静态变量属于类的状态,因此,序列化并不保存静态变量。所以i是没有改变的
137、将下列(A、B、C、D)哪个代码替换下列程序中的【代码】不会导致编译错误?
interface Com{
int M=200;
int f();
}
class ImpCom implements Com{
【代码】
}
A、public int f(){return 100+M;}
B、int f(){return 100;}
C、public double f(){return 2.6;}
D、public abstract int f();
1、必须实现接口中所有的方法。
在实现类中实现接口时,方法的名字、返回值类型、参数的个数及类型必须与接口中的完全一致,并且必须实现接口中的所有方法。
2、接口实现类相当于子类,子类的访问权限是不能比父类小的。
接口中所有方法默认都是public,至于为什么要是public,原因在于如果不是public,那么只能在同个包下被实现,可访问权限就降低很多了,那么在实现类中,实现的类相当于子类,子类的访问权限是不能比父类小的,而在java中一个类如果没有权限的修饰符,默认是defalut(同一个包内的其它类才可访问),所以在实现类中一定要写public
138、运行代码,输出的结果是
public class P {
public static int abc = 123;
static{
System.out.println("P is init");
}
}
public class S extends P {
static{
System.out.println("S is init");
}
}
public class Test {
public static void main(String[] args) {
System.out.println(S.abc);
}
}
A、P is init
123
B、S is init
P is init
123
C、P is init
S is init
123
D、S is init
123
不会初始化子类的几种
1.调用的是父类的static方法或者字段
2.调用的是父类的final方法或者字段
3.通过数组来引用
经过代码测试:
当直接new 子类 创建时的执行顺序为:父类静态块、子类静态块、父类构造方法、子类构造方法。
当new创建子类数组时,不加载任何东西
当用父类名调用父类静态变量、方法时:加载父类静态块
当用子类名调用父类静态变量、方法是:加载父类静态块
当用子类名调用子类特有静态变量、方法是:加载父类静态块、加载子类静态块
139、jdk1.8版本之前的前提下,接口和抽象类描述正确的有
A、抽象类没有构造函数
B、接口没有构造函数
C、抽象类不允许多继承
D、接口中的方法可以有方法体
A,抽象类是一个类,所以有构造器
B,接口不是一个类,所以没有构造函数
C,抽象类是一个类,类不允许继承多个类,但是可以实现多个接口。而接口可以继承多个接口,接口不能实现接口。
D,jdk1.8之前,接口中的方法都是抽象方法,用public abstract修饰,jdk1.8新特性:可以有默认方法(用default修饰,不能缺省)和静态方法(static修饰),jdk1.9:接口中的默认方法还可以用private修饰
140、下面选项中,哪些是interface中合法方法定义?()
A、public void main(String [] args);
B、private int getSum();
C、boolean setFlag(Boolean [] test);
D、public float get(int x);
interface中的方法默认为public abstract 的 ,变量默认为public static final
141、在Web应用程序的文件与目录结构中,web.xml是放置在
A、WEB-INF目录
B、conf目录
C、lib目录
D、classes目录

142、下列哪个说法是正确的
A、ConcurrentHashMap使用synchronized关键字保证线程安全
B、HashMap实现了Collction接口
C、Array.asList方法返回java.util.ArrayList对象
D、SimpleDateFormat是线程不安全的
A. JDK1.8 的 ConcurrentHashMap 采用CAS+Synchronized保证线程安全。 JDK1.7 及以前采用segment的分段锁机制实现线程安全, 其中segment继承自ReentrantLock,因此采用Lock锁来保证线程安全。
B. 
C. Arrays.asList() 返回 java.util.Arrays.ArrayList 对象,这里的 ArrayList 是 Arrays 私有的内部类
D. 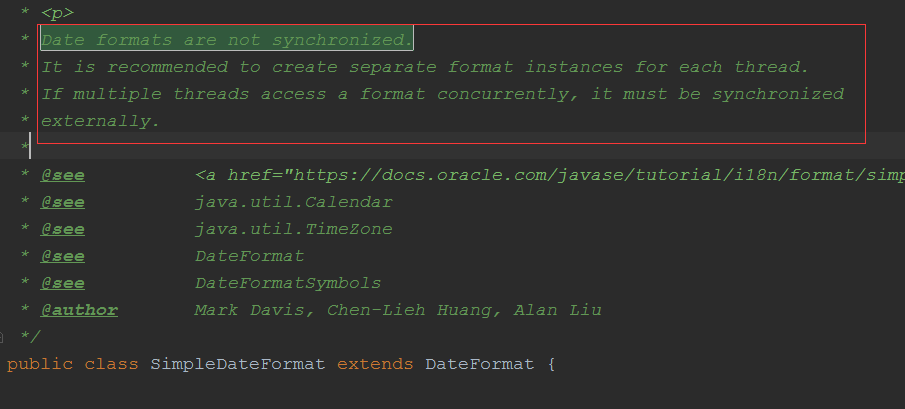
143、关于java编译和运行命令叙述不正确的是?
A、运行“java Scut.class”
B、运行“java Scut”
C、编译 Scut.java文件,使用“javac Scut.java”命令的输出文件是Scut.class
D、java这个命令的运行对象是Scut.class
A 错误 运行命令是 *j*ava + 你的 Java 程序的名字但是不加后缀 所以这道题错在多了 .class这个后缀
B 正确
C javac 是编译命令,后跟 你的 Java 程序名字加后缀,也就是 YourClassName.java 所以答案正确
D JVM (Java 虚拟机)运行的是编译后的字节码文件(以.class为后缀的文件)**,也就是 YourClassName.class 所以答案正确
144、URL u =new URL(“http://www.123.com”);。如果www.123.com不存在,则返回
A http://www.123.com
B、””
C、null
D、抛出异常
new URL()时必须捕获检查异常,但这个异常是由于字符串格式和URL不符导致的,与网址是否存在无关。URL的toString方法返回字符串,无论网址是否存在。

145、下面的Java赋值语句哪些是有错误的
A、int i =1000;
B、float f = 45.0;
C、char s = ‘\u0639’;
D、Object o = ‘f’;
E、String s = “hello,world\0”;
F、Double d = 100;
b:小数如果不加 f 后缀,默认是double类型。double转成float向下转换,意味着精度丢失,所以要进行强制类型转换。
c:是使用unicode表示的字符。
d:‘f’ 字符会自动装箱成包装类,就可以向上转型成Object了。
f:整数默认是int类型,int类型不能转型为Double,最多通过自动装箱变为Integer但是Integer与Double没有继承关系,也没法进行转型。double d = 100; int (小) ---->double(大) 可以赋值
146、Which of the following statements are valid array declaration?
(A) int number();
(B) float average[];
© double[] marks;
(D) counter int[];
数据的两种定义方式。 int[] nums; int nums[];
147、下面有关servlet中init,service,destroy方法描述错误的是?
A、init()方法是servlet生命的起点。一旦加载了某个servlet,服务器将立即调用它的init()方法
B、service()方法处理客户机发出的所有请求
C、destroy()方法标志servlet生命周期的结束
D、servlet在多线程下使用了同步机制,因此,在并发编程下servlet是线程安全的
init方法: 是在servlet实例创建时调用的方法,用于创建或打开任何与servlet相的资源和初始 化servlet的状态,Servlet规范保证调用init方法前不会处理任何请求
service方法:是servlet真正处理客户端传过来的请求的方法,由web容器调用, 根据HTTP请求方法(GET、POST等),将请求分发到doGet、doPost等方法
destory方法:是在servlet实例被销毁时由web容器调用。Servlet规范确保在destroy方法调用之 前所有请求的处理均完成,需要覆盖destroy方法的情况:释放任何在init方法中 打开的与servlet相关的资源存储servlet的状态
servlet在多线程下其本身并不是线程安全的。 如果在类中定义成员变量,而在service中根据不同的线程对该成员变量进行更改,那么在并发的时候就会引起错误。最好是在方法中,定义局部变量,而不是类变量或者对象的成员变量。由于方法中的局部变量是在栈中,彼此各自都拥有独立的运行空间而不会互相干扰,因此才做到线程安全。
148、针对jdk1.7,以下哪个不属于JVM堆内存中的区域
A、survivor区
B、常量池
C、eden区
D、old区
jvm堆分为:新生代(一般是一个Eden区,两个Survivor区),老年代(old区)。
常量池属于 PermGen(方法区)
149、JDK提供的用于并发编程的同步器有哪些?
A、Semaphore
B、CyclicBarrier
C、CountDownLatch
D、Counter
150、关于下面一段代码,以下说法正确的是
public class Test {
private synchronized void a() {
}
private void b() {
synchronized (this) {
}
}
private synchronized static void c() {
}
private void d() {
synchronized (Test.class) {
}
}
}
A、同一个对象,分别调用方法a和b,锁住的是同一个对象
B、同一个对象,分别调用方法a和c,锁住的是同一个对象
C、同一个对象,分别调用方法b和c,锁住的不是同一个对象
D、同一个对象,分别调用方法a、b、c,锁住的不是同一个对象
修饰非静态方法 锁的是this 对象
修饰静态方法 锁的是class对象
151、有关线程的叙述正确的是
A、可以获得对任何对象的互斥锁定
B、通过继承Thread类或实现Runnable接口,可以获得对类中方法的互斥锁定
C、线程通过使用synchronized关键字可获得对象的互斥锁定
D、线程调度算法是平台独立的
A,“任何对象”锁定,太绝对了,你能锁住你没有权限访问的对象吗?
B,前半句话讲的是创建线程的方式,后半句讲的是锁定,驴头不对马嘴。
C,正确。
D,线程调度分为协同式调度和抢占式调度,Java使用的是抢占式调度,也就是每个线程将由操作系统来分配执行时间,线程的切换不由线程本身来决定(协同式调度)。这就是平台独立的原因。
152、Java是一门支持反射的语言,基于反射为Java提供了丰富的动态性支持,下面关于Java反射的描述,哪些是错误的:( )
A、Java反射主要涉及的类如Class, Method, Filed,等,他们都在java.lang.reflet包下
B、通过反射可以动态的实现一个接口,形成一个新的类,并可以用这个类创建对象,调用对象方法
C、通过反射,可以突破Java语言提供的对象成员、类成员的保护机制,访问一般方式不能访问的成员
D、Java反射机制提供了字节码修改的技术,可以动态的修剪一个类
E、Java的反射机制会给内存带来额外的开销。例如对永生堆的要求比不通过反射要求的更多
F、Java反射机制一般会带来效率问题,效率问题主要发生在查找类的方法和字段对象,因此通过缓存需要反射类的字段和方法就能达到与之间调用类的方法和访问类的字段一样的效率
A Class类在java.lang包
D CGLIB实现了字节码修改,反射不行
F 反射带来的效率问题主要是动态解析类,JVM没法对反射代码优化。 使用cache和禁止安全检查等都可以提升反射的效率,但即使再怎么优化也不可能达到和直接调用类一样的效率,因为无论是通过字符串获取Class、Method还是Field,都需要JVM的动态链接机制动态的进行解析和匹配(即告诉JVM该如何去找这个类),而直接调用则不必。
153、以下关于 abstract 关键字的说法,正确的是
A、abstract 可以与final 并列修饰同一个类。
B、abstract 类中不可以有private的成员。
C、abstract 类中必须全部是abstract方法。
D、abstract 方法必须在abstract类或接口中。
abstract是需要被继承使用的,所以它不能被final使用,所以A错,也可以有private属性,B错,也可以有普通方法 甚至所有都可以是普通方法,当然这样也就失去了abstract类的意义,C错,interface属于特殊的abstract类,也是abstract类,所以D对 … 展开
abstract是需要被继承使用的,所以它不能被final使用,所以A错,也可以有private属性,B错,也可以有普通方法 甚至所有都可以是普通方法,当然这样也就失去了abstract类的意义,C错,interface属于特殊的abstract类,也是abstract类,所以D对
154、下面代码将输出什么内容
public class SystemUtil{
public static boolean isAdmin(String userId){
return userId.toLowerCase()=="admin";
}
public static void main(String[] args){
System.out.println(isAdmin("Admin"));
}
}
A、true
B、false
在源码中 toLowerCase 是重新 new String()

所以为 == 是比较对象是否是同一个对象,所以为 false 。
155、要导入java/awt/event下面的所有类,叙述正确的是?
A、import java.awt.和import java.awt.event.都可以
B、只能是import java.awt.
C、只能是import java.awt.event.
*D、import java.awt.*和import java.awt.event.*都不可以
import java.awt.*;导入的是awt下的包,awt下的包中的不会被导入
import java.awt.event.*; 导入的是event下面的类,java.awt中的其他包不会被导入
156、以下哪个式子有可能在某个进制下成立
A、13 14=204
B、1234=568
C、14*14=140
D、1+1=3
(3+x)*(4+x)=2x^2+4
x=8或-1
157、下面代码输出是
enum AccountType
{
SAVING, FIXED, CURRENT;
private AccountType()
{
System.out.println("It is a account type");
}
}
class EnumOne
{
public static void main(String[]args)
{
System.out.println(AccountType.FIXED);
}
}
A、编译正确,输出”It is a account type”once followed by”FIXED”
B、编译正确,输出”It is a account type”twice followed by”FIXED”
C、编译正确,输出”It is a account type”thrice followed by”FIXED”
D、编译正确,输出”It is a account type”four times followed by”FIXED”
枚举类在后台实现时,实际上是转化为一个继承了java.lang.Enum类的实体类,原先的枚举类型变成对应的实体类型,上例中AccountType变成了个class AccountType,并且会生成一个新的构造函数,若原来有构造函数,则在此基础上添加两个参数,生成新的构造函数,如上例子中:
private AccountType(){ System.out.println(“It is a account type”); }
会变成:
private AccountType(String s, int i){
super(s,i); System.out.println(“It is a account type”);
}
而在这个类中,会添加若干字段来代表具体的枚举类型:
public static final AccountType SAVING;
public static final AccountType FIXED;
public static final AccountType CURRENT;
而且还会添加一段static代码段:
static{
SAVING = new AccountType("SAVING", 0);
... CURRENT = new AccountType("CURRENT", 0);
$VALUES = new AccountType[]{
SAVING, FIXED, CURRENT
} }
以此来初始化枚举中的每个具体类型。(并将所有具体类型放到一个$VALUE数组中,以便用序号访问具体类型)
在初始化过程中new AccountType构造函数被调用了三次,所以Enum中定义的构造函数中的打印代码被执行了3遍。
158、有关会话跟踪技术描述正确的是
A、Cookie是Web服务器发送给客户端的一小段信息,客户端请求时,可以读取该信息发送到服务器端
B、关闭浏览器意味着临时会话ID丢失,但所有与原会话关联的会话数据仍保留在服务器上,直至会话过期
C、在禁用Cookie时可以使用URL重写技术跟踪会话
D、隐藏表单域将字段添加到HTML表单并在客户端浏览器中显示
1.session用来表示用户会话,session对象在服务端维护,一般tomcat设定session生命周期为30分钟,超时将失效,也可以主动设置无效;
2.cookie存放在客户端,可以分为内存cookie和磁盘cookie。内存cookie在浏览器关闭后消失,磁盘cookie超时后消失。当浏览器发送请求时,将自动发送对应cookie信息,前提是请求url满足cookie路径;
3.可以将sessionId存放在cookie中,也可以通过重写url将sessionId拼接在url。因此可以查看浏览器cookie或地址栏url看到sessionId;
4.请求到服务端时,将根据请求中的sessionId查找session,如果可以获取到则返回,否则返回null或者返回新构建的session,老的session依旧存在.
159、如下代码,执行test()函数后,屏幕打印结果为
public class Test2
{
public void add(Byte b)
{
b = b++;
}
public void test()
{
Byte a = 127;
Byte b = 127;
add(++a);
System.out.print(a + " ");
add(b);
System.out.print(b + "");
}
}
A、127 127
B、128 127
C、129 128
D、-128 127
160、下面哪些类实现或者继承了Collection接口?
A、HashMap
B、ArrayList
C、Vector
D、Iterator

161、下面哪些选项是正确的
A、>>是算术右移操作符
B、>>是逻辑右移操作符
C、>>>是算术右移操作符
D、>>>是逻辑右移操作符
>> 右移 高位补符号位
>>> 右移 高位补0
162、在J2EE中,使用Servlet过滤器,需要在web.xml中配置()元素
A、
B、
C、
D、

163、下面哪些写法能在 java8 中编译执行
A、dir.listFiles((File f)->f.getName().endsWith(“.Java”));
B、dir.listFiles((File f)=>f.getName().endsWith(“.Java”));
C、dir.listFiles((_.getName().endsWith(“.Java”)));
D、dir.listFiles( f->f.getName().endsWith(“.Java”));
用排除法做就行了,lambda表达式的格式为()→{},其中箭头是必不可少的。B选项中的箭头为=>,C选项中没箭头,故排除BC。
lamdda中,箭头左边表示的是参数,右边表示的是方法体。
若无参无返回值,左边为()
若只有一个参数,左边为(参数a),也可以直接将括号省略。
若有两个参数,左边为(参数a,参数b)
若方法体中只有一条语句,可省略大括号和return。
164、final、finally和finalize的区别中,下述说法正确的有
A、final用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
B、finally是异常处理语句结构的一部分,表示总是执行。
C、finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源的回收,例如关闭文件等。
D、引用变量被final修饰之后,不能再指向其他对象,它指向的对象的内容也是不可变的。
A,D考的一个知识点,final修饰变量,变量的引用(也就是指向的地址)不可变,但是引用的内容可以变(地址中的内容可变)。
B,finally表示总是执行。但是其实finally也有不执行的时候,但是这个题不要扣字眼。
1. 在try中调用System.exit(0),强制退出了程序,finally块不执行。
2. 在进入try块前,出现了异常,finally块不执行。
C,finalize方法,这个方法一个对象只能执行一次,只能在第一次进入被回收的队列,而且对象所属于的类重写了finalize方法才会被执行。第二次进入回收队列的时候,不会再执行其finalize方法,而是直接被二次标记,在下一次GC的时候被GC。
165、下面HttpServletResponse方法调用,那些给客户端回应了一个定制的HTTP回应头:( )
A、response.setHeader(“X-MyHeader”, “34”);
B、response.addHeader(“X-MyHeader”, “34”);
C、response.setHeader(new HttpHeader(“X-MyHeader”, “34”));
D、response.addHeader(new HttpHeader(“X-MyHeader”, “34”));
E、response.addHeader(new ServletHeader(“X-MyHeader”, “34”));
F、response.setHeader(new ServletHeader(“X-MyHeader”, “34”));
166、以下说法中正确的有?
A、StringBuilder是 线程不安全的
B、Java类可以同时用 abstract和final声明
C、HashMap中,使用 get(key)==null可以 判断这个Hasmap是否包含这个key
D、volatile关键字不保证对变量操作的原子性
A.StringBuilder线程不安全,StringBuffer线程安全。
B.同时用 abstract和final就会自相矛盾。
C.Hashmap中的value可以之null,get(key)==null有两种情况,一是key不存在,二是该key中存的是null,所以应该使用map.containskey(key)返回的true/false来判断是否存在这个key。
D.volatile关键字有两个作用:
1.并发环境可见性:volatile修饰后的变量能够保证该变量在线程间的可见性,线程进行数据的读写操作时将绕开工作内存(CPU缓存)而直接跟主内存进行数据交互,即线程进行读操作时直接从主内存中读取,写操作时直接将修改后端变量刷新到主内存中,这样就能保证其他线程访问到的数据是最新数据
2.并发环境有序性:通过对volatile变量采取内存屏障(Memory barrier)的方式来防止编译重排序和CPU指令重排序,具体方式是通过在操作volatile变量的指令前后加入内存屏障,来实现happens-before关系,保证在多线程环境下的数据交互不会出现紊乱。
167、以下哪些方法可以取到http请求中的cookie值()?
A、request.getAttribute
B、request.getHeader
C、request.getParameter
D、request.getCookies
下面的方法可用在 Servlet 程序中读取 HTTP 头。这些方法通过 HttpServletRequest 对象可用:
1)Cookie[] getCookies()
返回一个数组,包含客户端发送该请求的所有的 Cookie 对象。
2)Object getAttribute(String name)
以对象形式返回已命名属性的值,如果没有给定名称的属性存在,则返回 null。
3)String getHeader(String name)
以字符串形式返回指定的请求头的值。Cookie也是头的一种;
4)String getParameter(String name)
以字符串形式返回请求参数的值,或者如果参数不存在则返回 null。
168、建立Statement对象的作用是?
A、连接数据库
B、声明数据库
C、执行SQL语句
D、保存查询结果
statement 用于执行不带参数的SQL语句
preperStatement 用于执行带参数的SQL语句可以防SQL注入
callableStatement 用于执行存储过程的调用
169、下面的哪4个语句是正确的?
class A {}
class B extends A {}
class C extends A {}
class D extends B {}
A、The type Listis assignable to List.
B、The type Listis assignable to List.
C、The type Listis assignable to List<?>.
D、The type Listis assignable to List<?extends B>.
E、The type List<?extends A>is assignable to List.
F、The type Listis assignable to any List reference.
G、The type List<?extends B>is assignable to List<?extends A>.
- 只看尖括号里边的!!明确点和范围两个概念
- 如果尖括号里的是一个类,那么尖括号里的就是一个点,比如List,List,List
- 如果尖括号里面带有问号,那么代表一个范围,<? extends A> 代表小于等于A的范围,<? super A>代表大于等于A的范围,<?>代表全部范围
- 尖括号里的所有点之间互相赋值都是错,除非是俩相同的点
- 尖括号小范围赋值给大范围,对,大范围赋值给小范围,错。如果某点包含在某个范围里,那么可以赋值,否则,不能赋值
- List<?>和List 是相等的,都代表最大范围
- List既是点也是范围,当表示范围时,表示最大范围
public static void main(String[] args) {
List<A> a;
List list;
list = a; //A对,因为List就是List<?>,代表最大的范围,A只是其中的一个点,肯定被包含在内
List<B> b;
a = b; //B错,点之间不能相互赋值
List<?> qm;
List<Object> o;
qm = o; //C对,List<?>代表最大的范围,List<Object>只是一个点,肯定被包含在内
List<D> d;
List<? extends B> downB;
downB = d; //D对,List<? extends B>代表小于等于B的范围,List<D>是一个点,在其中
List<?extends A> downA;
a = downA; //E错,范围不能赋值给点
a = o; //F错,List<Object>只是一个点
downA = downB; //G对,小于等于A的范围包含小于等于B的范围,因为B本来就比A小,B时A的子类嘛
}
170、下面哪个语句是创建数组的正确语句?( )
A、float f[][] = new float[6][6];
B、float []f[] = new float[6][6];
C、float f[][] = new float[][6];
D、float [][]f = new float[6][6];
E、float [][]f = new float[6][];
数组声明,必须要明确行数,列数随意
171、Java类Demo中存在方法func1、func2、func3和func4,请问该方法中,哪些是不合法的定义?
public class Demo{
float func1()
{
int i=1;
return;
}
float func2()
{
short i=2;
return i;
}
float func3()
{
long i=3;
return i;
}
float func4()
{
double i=4;
return i;
}
}
A、func1
B、func2
C、func3
D、func4
自动转换按从低到高的顺序转换。不同类型数据间的优先关系如下:
低 ---------------------------------------------> 高
byte,short,char-> int -> long -> float -> double
这道题考的是数据类型转换问题。由大到小需要强制转换,由小到大不需要。
A:return; 没有返回值,错误
B:short → float 无须强制转换,正确
C:long → float 无须强制转换(这个最选项容易出错),正确。
float占4个字节为什么比long占8个字节大呢,因为底层的实现方式不同。
浮点数的32位并不是简单直接表示大小,而是按照一定标准分配的。
第1位,符号位,即S
接下来8位,指数域,即E。
剩下23位,小数域,即M,取值范围为[1 ,2 ) 或[0 , 1)
然后按照公式: V=(-1)^s * M * 2^E
也就是说浮点数在内存中的32位不是简单地转换为十进制,而是通过公式来计算而来,通过这个公式虽然,只有4个字节,但浮点数最大值要比长整型的范围要大
D:double → float 没有强制转换,错误。
172、ArrayList list = new ArrayList(20);中的list扩充几次
A、0
B、1
C、2
D、3
Arraylist默认数组大小是10,扩容后的大小是扩容前的1.5倍,最大值小于Integer 的最大值减8,如果新创建的集合有带初始值,默认就是传入的大小,也就不会扩容。
173、如果int x=20, y=5,则语句System.out.println(x+y +“”+(x+y)+y); 的输出结果是
A、2530
B、55
C、2052055
D、25255
1)不论有什么运算,小括号的优先级都是最高的,先计算小括号中的运算,得到x+y +“”+25+y
2)任何字符与字符串相加都是字符串,但是是有顺序的,字符串前面的按原来的格式相加,字符串后面的都按字符串相加,得到 25+“”+25+5
3)上面的结果按字符串相加得到25255
174、下面有关SPRING的事务传播特性,说法错误的是?
A、PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行
B、PROPAGATION_REQUIRED:支持当前事务,如果当前没有事务,就抛出异常
C、PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起
D、PROPAGATION_NESTED:支持当前事务,新增Savepoint点,与当前事务同步提交或回滚
事务属性的种类: 传播行为、隔离级别、只读和事务超时
a) 传播行为定义了被调用方法的事务边界。
| 传播行为 | 意义 |
|---|---|
| PROPERGATION_MANDATORY | 表示方法必须运行在一个事务中,如果当前事务不存在,就抛出异常 |
| PROPAGATION_NESTED | 表示如果当前事务存在,则方法应该运行在一个嵌套事务中。否则,它看起来和 PROPAGATION_REQUIRED 看起来没什么俩样 |
| PROPAGATION_NEVER | 表示方法不能运行在一个事务中,否则抛出异常 |
| PROPAGATION_NOT_SUPPORTED | 表示方法不能运行在一个事务中,如果当前存在一个事务,则该方法将被挂起 |
| PROPAGATION_REQUIRED | 表示当前方法必须运行在一个事务中,如果当前存在一个事务,那么该方法运行在这个事务中,否则,将创建一个新的事务 |
| PROPAGATION_REQUIRES_NEW | 表示当前方法必须运行在自己的事务中,如果当前存在一个事务,那么这个事务将在该方法运行期间被挂起 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要运行在一个是事务中,但如果有一个事务已经存在,该方法也可以运行在这个事务中 |
b) 隔离级别
在操作数据时可能带来3个副作用,分别是脏读、不可重复读、幻读。为了避免这3种副作用的发生,在标准的SQL语句中定义了4种隔离级别,分别是未提交读、已提交读、可重复读、可序列化。而在spring事务中提供了5种隔离级别来对应在SQL中定义的4种隔离级别,如下:
| 隔离级别 | 意义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 允许读取未提交的数据(对应未提交读),可能导致脏读、不可重复读、幻读 |
| ISOLATION_READ_COMMITTED | 允许在一个事务中读取另一个已经提交的事务中的数据(对应已提交读)。可以避免脏读,但是无法避免不可重复读和幻读 |
| ISOLATION_REPEATABLE_READ | 一个事务不可能更新由另一个事务修改但尚未提交(回滚)的数据(对应可重复读)。可以避免脏读和不可重复读,但无法避免幻读 |
| ISOLATION_SERIALIZABLE | 这种隔离级别是所有的事务都在一个执行队列中,依次顺序执行,而不是并行(对应可序列化)。可以避免脏读、不可重复读、幻读。但是这种隔离级别效率很低,因此,除非必须,否则不建议使用。 |
链接:https://www.nowcoder.com/questionTerminal/1c65d30e47fb4f59a5e5af728218cac4?
来源:牛客网
c) 只读
如果在一个事务中所有关于数据库的操作都是只读的,也就是说,这些操作只读取数据库中的数据,而并不更新数据,那么应将事务设为只读模式( READ_ONLY_MARKER ) , 这样更有利于数据库进行优化 。
因为只读的优化措施是事务启动后由数据库实施的,因此,只有将那些具有可能启动新事务的传播行为 (PROPAGATION_NESTED 、 PROPAGATION_REQUIRED 、 PROPAGATION_REQUIRED_NEW) 的方法的事务标记成只读才有意义。
如果使用 Hibernate 作为持久化机制,那么将事务标记为只读后,会将 Hibernate 的 flush 模式设置为 FULSH_NEVER, 以告诉 Hibernate 避免和数据库之间进行不必要的同步,并将所有更新延迟到事务结束。
d)事务超时
如果一个事务长时间运行,这时为了尽量避免浪费系统资源,应为这个事务设置一个有效时间,使其等待数秒后自动回滚。与设
置“只读”属性一样,事务有效属性也需要给那些具有可能启动新事物的传播行为的方法的事务标记成只读才有意义。
175、下列哪一个方法你认为是新线程开始执行的点,也就是从该点开始线程n被执行。
A、public void start()
B、public void run()
C、public void init()
D、public static void main(String args[])
题目的意思是,下列哪一个方法你认为是新线程开始执行的点,也就是从该点开始线程n被执行。
了解过线程的知识我们知道:
start()方法是启动一个线程,此时的线程处于就绪状态,但并不一定就会执行,还需要等待CPU的调度。
run()方法才是线程获得CPU时间,开始执行的点。
176、命令javac-d参数的用途是?
A、指定编译后类层次的根目录
B、指定编译时需要依赖类的路径
C、指定编译时的编码
D、没有这一个参数
-d destination 目的地
-s source 起源地
javac -d 指定放置生成的类文件的位置
javac -s 指定放置生成的源文件的位置
177、关于 Socket 通信编程,以下描述正确的是:( )
A、客户端通过new ServerSocket()创建TCP连接对象
B、客户端通过TCP连接对象调用accept()方法创建通信的Socket对象
C、客户端通过new Socket()方法创建通信的Socket对象
D、服务器端通过new ServerSocket()创建通信的Socket对象
A 错误
Client端通过new Socket()创建用于通信的Socket对象。
B 错误
Client端的Socket对象是直接new出来的。
C 正确
D 错误
Server端通过new ServerSocket()创建ServerSocket对象,ServerSocket对象的accept()方法产生阻塞,阻塞直到捕捉到一个来自Client端的请求。当Server端捕捉到一个来自Client端的请求时,会创建一个Socket对象,使用此Socket对象与Client端进行通信。
认识Socket
Socket,又称套接字,是在不同的进程间进行网络通讯的一种协议、约定或者说是规范。
对于Socket编程,它更多的时候是基于TCP/UDP等协议做的一层封装或者说抽象,是一套系统所提供的用于进行网络通信相关编程的接口。
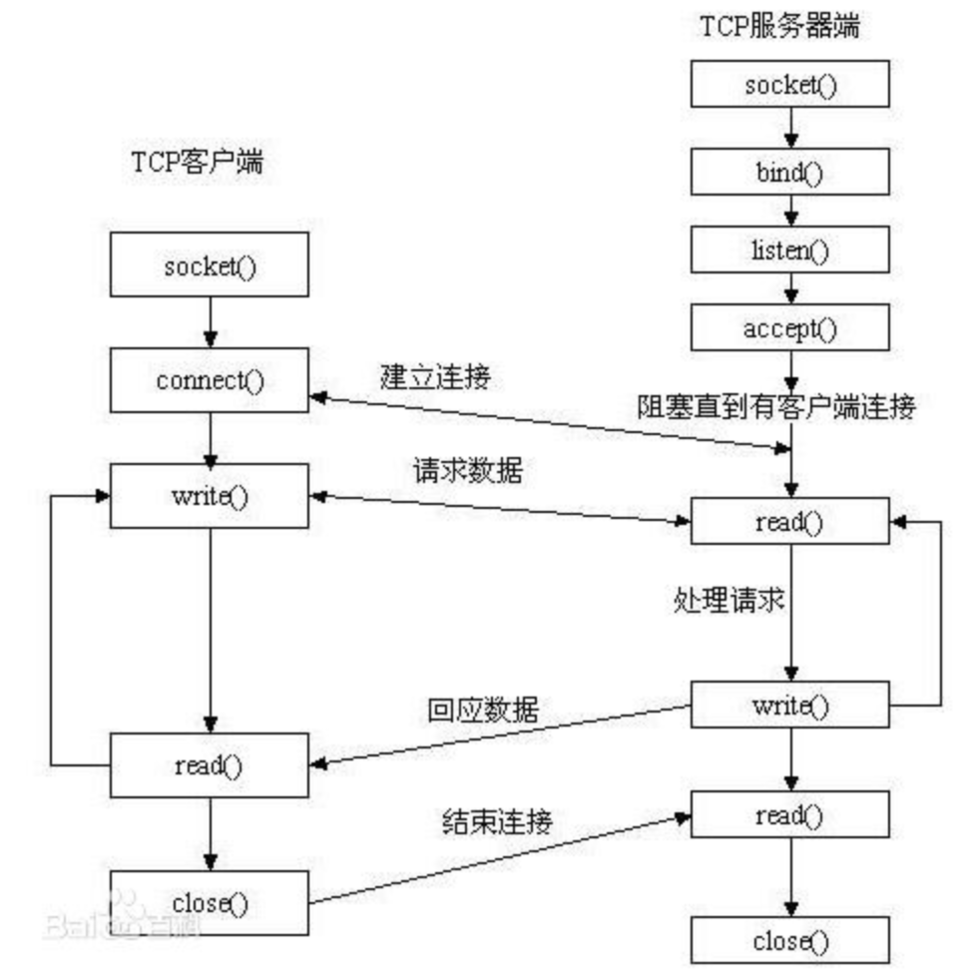
可以看到本质上,Socket是对TCP连接(当然也有可能是UDP等其他连接)协议,在编程层面上的简化和抽象。
ServerSocket类
创建一个ServerSocket类,同时在运行该语句的计算机的指定端口处建立一个监听服务,如:
ServerSocket serverSocket = new ServerSocket(600);
这里指定提供监听服务的端口是600,一台计算机可以同时提供多个服务,这些不同的服务之间通过端口号来区别,不同的端口号上提供不同的服务。为了随时监听可能的Client端请求,执行如下的语句:
Socket socket = serverSocket.accept();
该语句调用了ServerSocket对象的accept()方法,这个方法的执行将使Server端的程序处于阻塞状态,程序将一直阻塞直到捕捉到一个来自Client端的请求,并返回一个用于与该Client端通信的Socket对象。此后Server程序只需要向这个Socket对象读写数据,就可以向远端的Client端读写数据。结束监听时,关闭ServerSocket:
serverSocket.close();
ServerSocket一般仅用于设置端口号和监听,真正进行通信的是Server端的Socket与Client端的Socket。
Socket类
当Client端需要从Server端获取信息及其他服务时,应创建一个Socket对象:
Socket socket = ``new` `Socket(“IP”,``600``);
Socket类的构造方法有两个参数,第一个参数是欲连接到的Server端所在计算机的IP地址(请注意,是IP,不是域名),第二个参数是该Server机上提供服务的端口号。
如果需要使用域名表示Server端所在计算机的地址:
// 用此句代替IP地址,url为你的域名
InetAddress.getByName(url);
Socket对象建立成功之后,就可以在Client端和Server端之间建立一个连接,通过这个连接在两个端之间传递数据。利用Socket类的方法getInputStream()和getOutputStream()分别获得用于向Socket读写数据的输入/输出流。
当Server端和Client端的通信结束时,可以调用Socket类的close()方法关闭连接。
178、Java的Daemon线程,setDaemon( )设置必须要?
A、在start之前
B、在start之后
C、前后都可以
java线程是一个运用很广泛的重点知识,我们很有必要了解java的daemon线程.
1.首先我们必须清楚的认识到java的线程分为两类: 用户线程和daemon线程
A. 用户线程: 用户线程可以简单的理解为用户定义的线程,当然包括main线程(以前我错误的认为main线程也是一个daemon线程,但是慢慢的发现原来main线程不是,因为如果我再main线程中创建一个用户线程,并且打出日志,我们会发现这样一个问题,main线程运行结束了,但是我们的线程任然在运行).
B. daemon线程: daemon线程是为我们创建的用户线程提供服务的线程,比如说jvm的GC等等,这样的线程有一个非常明显的特征: 当用户线程运行结束的时候,daemon线程将会自动退出.(由此我们可以推出下面关于daemon线程的几条基本特点)
2. daemon 线程的特点:
A. 守护线程创建的过程中需要先调用setDaemon方法进行设置,然后再启动线程.否则会报出IllegalThreadStateException异常.(个人在想一个问题,为什么不能动态更改线程为daemon线程?有时间一个补上这个内容,现在给出一个猜测: 是因为jvm判断线程状态的时候,如果当前只存在一个线程Thread1,如果我们把这个线程动态更改为daemon线程,jvm会认为当前已经不存在用户线程而退出,稍后将会给出正确结论,抱歉!如果有哪位大牛看到,希望给出指点,谢谢!)
B. 由于daemon线程的终止条件是当前是否存在用户线程,所以我们不能指派daemon线程来进行一些业务操作,而只能服务用户线程. C. daemon线程创建的子线程任然是daemon线程.
179、下面有关JSP内置对象的描述,说法错误的是?
A、session对象:session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止
B、request对象:客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应
C、application对象:多个application对象实现了用户间数据的共享,可存放全局变量
D、response对象:response对象包含了响应客户请求的有关信息
其实解释就一句话,application服务器就创建了一个,C选项后面错误了,不是多个
180、运用下列哪个命令能够获取JVM的内存映像
A、jinfo
B、jmap
C、jhat
D、jstat
1、jps:查看本机java进程信息。
2、jstack:打印线程的栈信息,制作线程dump文件。
3、jmap:打印内存映射,制作堆dump文件
4、jstat:性能监控工具
5、jhat:内存分析工具
6、jconsole:简易的可视化控制台
7、jvisualvm:功能强大的控制台
181、ResultSet中记录行的第一列索引为?
A、-1
B、0
C、1
D、以上都不是
ResultSet跟普通的数组不同,索引从1开始而不是从0开始
182、关于HashMap和Hashtable正确的说法有
A、都实现了Map接口
B、Hashtable类不是同步的,而HashMap类是同步的
C、Hashtable不允许null键或值
D、HashMap不允许null键或值
1、继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map
2、Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
3、Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
4、两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
5、哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
6、Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
183、jdk1.8中,下面有关java 抽象类和接口的区别,说法错误的是?
A、抽象类可以有构造方法,接口中不能有构造方法
B、抽象类中可以包含非抽象的普通方法,接口中的方法必须是抽象的,不能有非抽象的普通方法
C、一个类可以实现多个接口,但只能继承一个抽象类
D、接口中可以有普通成员变量,抽象类中没有普通成员变量
抽象类
1.抽象类中可以构造方法
2.抽象类中可以存在普通属性,方法,静态属性和方法。
3.抽象类中可以存在抽象方法。
4.如果一个类中有一个抽象方法,那么当前类一定是抽象类;抽象类中不一定有抽象方法。
5.抽象类中的抽象方法,需要有子类实现,如果子类不实现,则子类也需要定义为抽象的。
接口
1.在接口中只有方法的声明,没有方法体。
2.在接口中只有常量,因为定义的变量,在编译的时候都会默认加上 public static final
3.在接口中的方法,永远都被public来修饰。
4.接口中没有构造方法,也不能实例化接口的对象。
5.接口可以实现多继承
6.接口中定义的方法都需要有实现类来实现,如果实现类不能实现接口中的所有方法
7.则实现类定义为抽象类。
184、关于多线程和多进程,下面描述正确的是
A、多进程里,子进程可获得父进程的所有堆和栈的数据;而线程会与同进程的其他线程共享数据,拥有自己的栈空间。
B、线程因为有自己的独立栈空间且共享数据,所有执行的开销相对较大,同时不利于资源管理和保护。
C、线程的通信速度更快,切换更快,因为他们在同一地址空间内。
D、一个线程可以属于多个进程。
**A.**子进程得到的是除了代码段是与父进程共享以外,其他所有的都是得到父进程的一个副本,子进程的所有资源都继承父进程,得到父进程资源的副本,子进程可获得父进程的所有堆和栈的数据,但二者并不共享地址空间。两个是单独的进程,继承了以后二者就没有什么关联了,子进程单独运行;进程的线程之间共享由进程获得的资源,但线程拥有属于自己的一小部分资源,就是栈空间,保存其运行状态和局部自动变量的。
**B.**线程之间共享进程获得的数据资源,所以开销小,但不利于资源的管理和保护;而进程执行开销大,但是能够很好的进行资源管理和保护。
**C.**线程的通信速度更快,切换更快,因为他们共享同一进程的地址空间。
**D.**一个进程可以有多个线程,线程是进程的一个实体,是CPU调度的基本单位。
185、以下哪一项正则能正确的匹配网址: http://www.bilibili.com/video/av21061574
A、/^(https?:\/\/)?([a-zA-Z\d]+).bilibili.com\/?video\/av(\D{1,8})\/?$/
<font color='red'>B、/^(http:\/\/)?(\w+)\.bilibili\.com\/?video\/av(\d{1,8})\/?$/</font>
C、/^(https?:\/\/)?(\w+)\.bilibili\.com\/?\w*$/
D、/^(http:\/\/)?([a-zA-Z\d]+).bilibili.com\/?video\/av\w*\/+$/
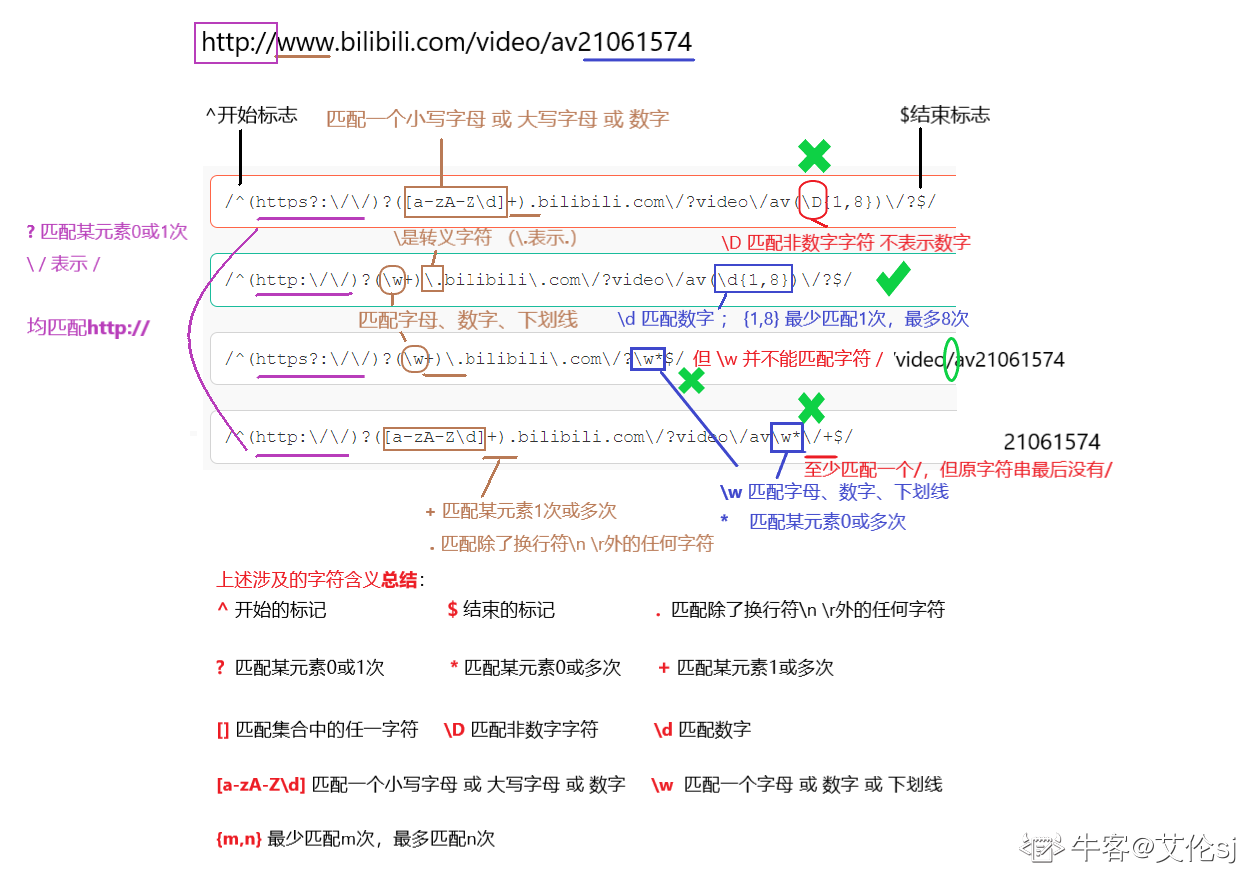
186、list是一个ArrayList的对象,哪个选项的代码填到//todo delete处,可以在Iterator遍历的过程中正确并安全的删除一个list中保存的对象?
Iterator it = list.iterator();
int index = 0;
while (it.hasNext())
{
Object obj = it.next();
if (needDelete(obj)) //needDelete返回boolean,决定是否要删除
{
//todo delete
}
index ++;
}
A、it.remove();
B、list.remove(obj);
C、list.remove(index);
D、list.remove(obj,index);
首先通过List接口的迭代器(Iterator)对list中的元素进行遍历,iterator是依赖于list存在的,遍历的时候,修改list的内容,但是iterator并不知道,java不允许这样的操作,会报ConcurrentModificationException(并发修改异常),直接使用iterator进行remove就没有问题;或者不使用iterator进行遍历,使用list的size方法和get方法结合进行遍历
187、下面有关servlet和cgi的描述,说法错误的是?
A、servlet处于服务器进程中,它通过多线程方式运行其service方法
B、CGI对每个请求都产生新的进程,服务完成后就销毁
C、servlet在易用性上强于cgi,它提供了大量的实用工具例程,例如自动地解析和解码HTML表单数据、读取和设置HTTP头、处理Cookie、跟踪会话状态等
D、cgi在移植性上高于servlet,几乎所有的主流服务器都直接或通过插件支持cgi
选择D,servlet处于服务器进程中,它通过多线程方式运行其service方法,一个实例可以服务于多个请求,并且其实例一般不会销毁,而CGI对每个请求都产生新的进程,服务完成后就销毁,所以效率上低于servlet。
188、Test.main()函数执行后的输出是
class Test {
public static void main(String[] args) {
System.out.println(new B().getValue());
}
static class A {
protected int value;
public A (int v) {
setValue(v);
}
public void setValue(int value) {
this.value= value;
}
public int getValue() {
try {
value ++;
return value;
} finally {
this.setValue(value);
System.out.println(value);
}
}
}
static class B extends A {
public B () {
super(5);
setValue(getValue()- 3);
}
public void setValue(int value) {
super.setValue(2 * value);
}
}
}
A、6 7 7
B、22 34 17
C、22 74 74
D、11 17 34
思考和解决这个题的主要核心在于对java多态的理解。个人理解时,执行对象实例化过程中遵循多态特性 ==> 调用的方法都是***将要实例化的子类中***的重写方法,只有明确调用了super.xxx关键词或者是子类中没有该方法时,才会去调用父类相同的同名方法。
Step 1: new B()构造一个B类的实例
此时super(5)语句调用显示调用父类A带参的构造函数,该构造函数调用setValue(v),这里有两个注意点一是虽然构造函数是A类的构造函数,但此刻正在初始化的对象是B的一个实例,因此这里调用的实际是B类的setValue方法,于是调用B类中的setValue方法 ==> 而B类中setValue方法显示调用父类的setValue方法,将B实例的value值设置为2 x 5 = 10。
紧接着,B类的构造函数还没执行完成,继续执行setValue(getValue()- 3) // 备注1语句。
先执行getValue方法,B类中没有重写getValue方法,因此调用父类A的getValue方法。这个方法比较复杂,需要分步说清楚:
- 调用getValue方法之前,B的成员变量value值为10。
- value++ 执行后, B的成员变量value值为11,此时开始执行到return语句,将11这个值作为getValue方法的返回值返回出去
- 但是由于getValue块被try finally块包围,因此finally中的语句无论如何都将被执行,所以步骤2中11这个返回值会先暂存起来,到finally语句块执行完毕后再真正返回出去。
- 这里有很重要的一点:finally语句块中 this.setValue(value)方法调用的是B类的setValue方法。为什么?因为此刻正在初始化的是B类的一个对象(运行时多态),就像最开始第一步提到的一样(而且这里用了使用了this关键词显式指明了调用当前对象的方法)。因此,此处会再次调用B类的setValue方法,同上,super.关键词显式调用A的setValue方法,将B的value值设置成为了2 * 11 = 22。
- 因此第一个打印项为22。
- finally语句执行完毕 会把刚刚暂存起来的11 返回出去,也就是说这么经历了这么一长串的处理,getValue方法最终的返回值是11。
回到前面标注了 //备注1 的代码语句,其最终结果为setValue(11-3)=>setValue(8)
而大家肯定也知道,这里执行的setValue方法,将会是B的setValue方法。 之后B的value值再次变成了2*8 = 16;
Step2: new B().getValue()
B类中没有独有的getValue方法,此处调用A的getValue方法。同Step 1,
- 调用getValue方法之前,B的成员变量value值为16。
- value++ 执行后, B的成员变量value值为17,此时执行到return语句,会将17这个值作为getValue方法的返回值返回出去
- 但是由于getValue块被try finally块包围而finally中的语句无论如何都一定会被执行,所以步骤2中17这个返回值会先暂存起来,到finally语句块执行完毕后再真正返回出去。
- finally语句块中继续和上面说的一样: this.setValue(value)方法调用的是B类的setValue()方法将B的value值设置成为了2 * 17 = 34。
- 因此第二个打印项为34。
- finally语句执行完毕 会把刚刚暂存起来的17返回出去。
- 因此new B().getValue()最终的返回值是17.
Step3: main函数中的System.out.println
将刚刚返回的值打印出来,也就是第三个打印项:17
最终结果为 22 34 17。 如果朋友们在看的过程中仍然有疑问,可以亲自把代码复制进去ide,在关键语句打下断点,查看调用方法的对象以及运行时的对象值,可以有更深刻的理解。
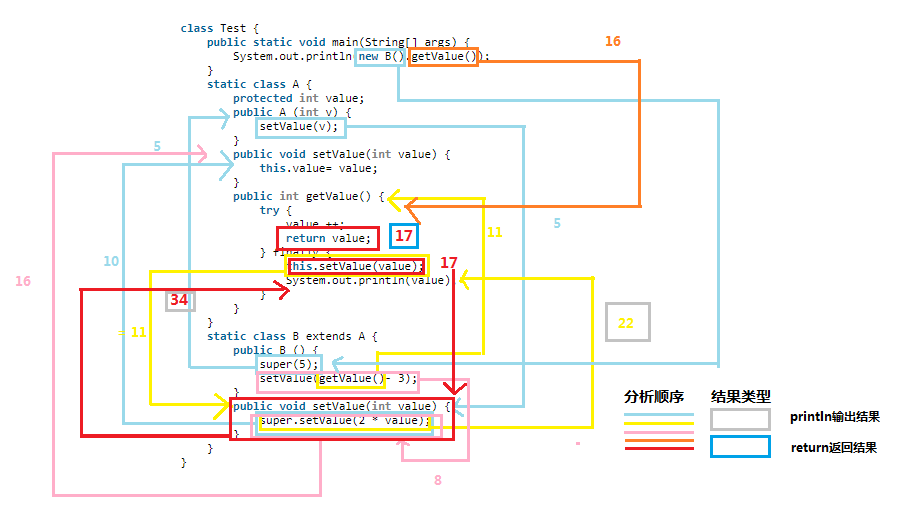
189、在java中,下列对继承的说法,正确的是
A、子类能继承父类的所有成员
B、子类继承父类的非私有方法和状态
C、子类只能继承父类的public方法和状态
D、子类只能继承父类的方法
在一个子类被创建的时候,首先会在内存中创建一个父类对象,然后在父类对象外部放上子类独有的属性,两者合起来形成一个子类的对象。所以所谓的继承使子类拥有父类所有的属性和方法其实可以这样理解,子类对象确实拥有父类对象中所有的属性和方法,但是父类对象中的私有属性和方法,子类是无法访问到的,只是拥有,但不能使用。就像有些东西你可能拥有,但是你并不能使用。所以子类对象是绝对大于父类对象的,所谓的子类对象只能继承父类非私有的属性及方法的说法是错误的。可以继承,只是无法访问到而已。
190、下面有关forward和redirect的描述,正确的是
A、forward是服务器将控制权转交给另外一个内部服务器对象,由新的对象来全权负责响应用户的请求
B、执行forward时,浏览器不知道服务器发送的内容是从何处来,浏览器地址栏中还是原来的地址
C、执行redirect时,服务器端告诉浏览器重新去请求地址
D、forward是内部重定向,redirect是外部重定向
E、redirect默认将产生301 Permanently moved的HTTP响应
1.从地址栏显示来说
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.
2.从数据共享来说
forward:转发页面和转发到的页面可以共享request里面的数据.
redirect:不能共享数据.
3.从运用地方来说
forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等.
4.从效率来说
forward:高.
redirect:低.
解释一
一句话,转发是服务器行为,重定向是客户端行为。为什么这样说呢,这就要看两个动作的工作流程:
转发过程:客户浏览器发送http请求----》web服务器接受此请求–》调用内部的一个方法在容器内部完成请求处理和转发动作----》将目标资源 发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客 户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。
重定向过程:客户浏览器发送http请求----》web服务器接受后发送302状态码响应及对应新的location给客户浏览器–》客户浏览器发现 是302响应,则自动再发送一个新的http请求,请求url是新的location地址----》服务器根据此请求寻找资源并发送给客户。在这里 location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的 路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
解释二
重定向,其实是两次request, 第一次,客户端request A,服务器响应,并response回来,告诉浏览器,你应该去B。这个时候IE可以看到地址变了,而且历史的回退按钮也亮了。重定向可以访问自己web应用以外的资源。在重定向的过程中,传输的信息会被丢失。
解释三
假设你去办理某个执照,
重定向:你先去了A局,A局的人说:“这个事情不归我们管,去B局”,然后,你就从A退了出来,自己乘车去了B局。
转发:你先去了A局,A局看了以后,知道这个事情其实应该B局来管,但是他没有把你退回来,而是让你坐一会儿,自己到后面办公室联系了B的人,让他们办好后,送了过来。
191、根据下面的程序代码,哪些选项的值返回true?
public class Square {
long width;
public Square(long l) {
width = l;
}
public static void main(String arg[]) {
Square a, b, c;
a = new Square(42L);
b = new Square(42L);
c = b;
long s = 42L;
}
}
A、a == b
B、s == a
C、b == c
D、a.equals(s)
这题考的是引用和内存。
//声明了3个Square类型的变量a, b, c。在stack中分配3个内存,名字为a, b, c
Square a, b, c;
//在heap中分配了一块新内存,里边包含自己的成员变量width值为48L,然后stack中的a指向这块内存
a = new Square(42L);
//在heap中分配了一块新内存,其中包含自己的成员变量width值为48L,然后stack中的b指向这块内存
b = new Square(42L);
//stack中的c也指向b所指向的内存
c = b;
//在stack中分配了一块内存,值为42
long s = 42L;
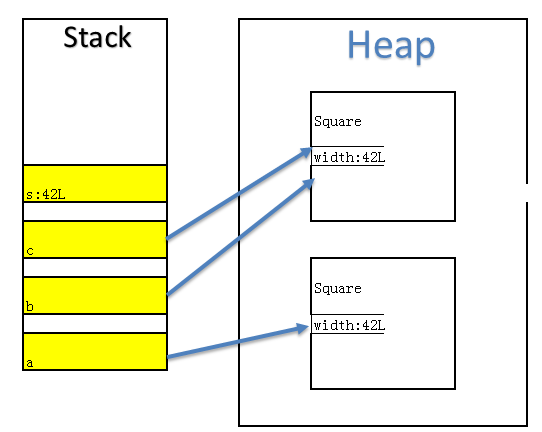
来看4个选项:
A: a == b 由图可以看出a和b指向的不是同一个引用,故A错
B: s == a 一个Square类型不能与一个long型比较,编译就错误,故B错
C: b == c 由图可以看出b和c指向的是同一个引用,故C正确
D: a equal s
程序会把s封装成一个Long类型,由于Square没有重写Object的equals方法, 所以调用的是Object类的equals方法,源码如下
public boolean equals(Object obj) {
return (this == obj);
}
其实就是判断两个引用是否相等,故D也错误。
192、Java数据库连接库JDBC用到哪种设计模式
A、生成器
B、桥接模式
C、抽象工厂
D、单例模式
桥接模式是结构型模式,关注点在依赖关系的维护。对于jdbc技术来说,它解耦了业务与数据库通信协议这两个纬度之间的关系,所以这两个纬度之间的关系就需要一个桥,即Driver,至于DriverManager把这个关系接到哪里就是运行时的事情了。
微观上,从connection的创建来看,它更像一个抽象工厂模式,特定的Driver创建对应的connection。
宏观上,从业务代码与connection的关系来看,关键点在于一个sql怎么转化为对应的通信协议,就属于桥接。
193、关于匿名内部类叙述正确的是
A、匿名内部类可以继承一个基类,不可以实现一个接口
B、匿名内部类不可以定义构造器
C、匿名内部类不能用于实参
D、以上说法都不正确
在使用匿名内部类的过程中,我们需要注意如下几点:
**1、**使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。 **2、**匿名内部类中是不能定义构造函数的。由于构造器的名字必须与类名相同,而匿名类没有类名,所以匿名类不能有构造器。
**3、**匿名内部类中不能存在任何的静态成员变量和静态方法。
**4、**匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
**5、**匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
194、以下说法哪个是正确的
A、IOException在编译时会被发现
B、NullPointerEception在编译时不会被发现
C、SQLException在编译时会被发现
D、FileNotFoundException在编译时会被发现
FileNotFoundException继承IOException,所以在编译时也会被发现!
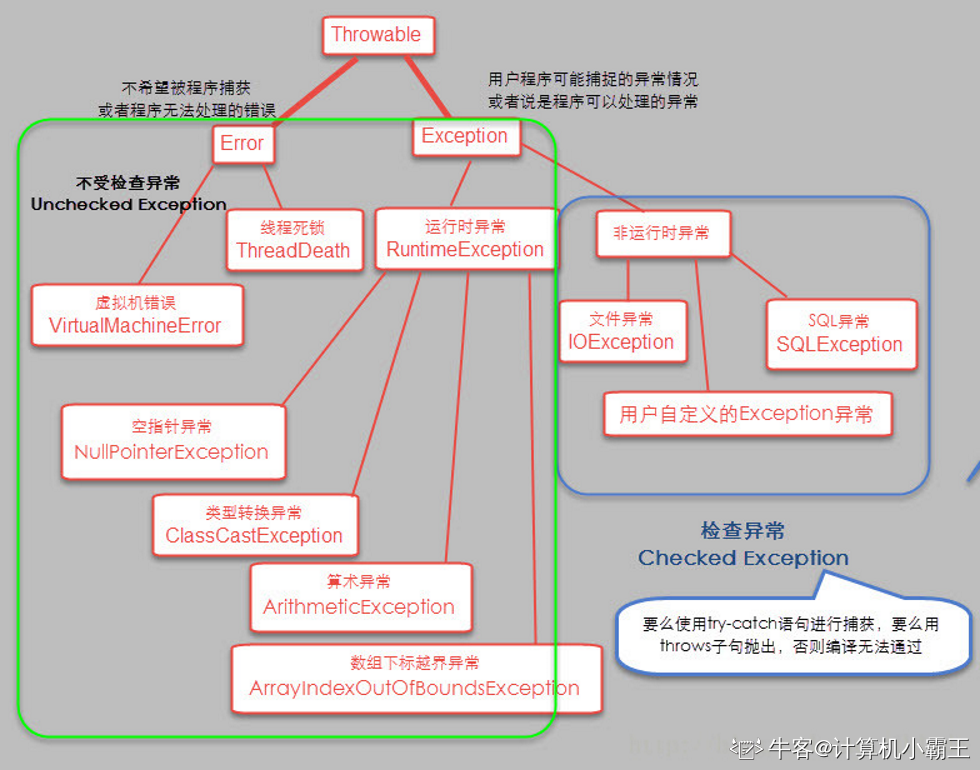
194、在Java语言中,下列关于字符集编码(Character set encoding)和国际化(i18n)的问题,哪些是正确的
A、每个中文字符占用2个字节,每个英文字符占用1个字节
B、假设数据库中的字符是以GBK编码的,那么显示数据库数据的网页也必须是GBK编码的。
C、Java的char类型,通常以UTF-16 Big Endian的方式保存一个字符。
D、实现国际化应用常用的手段是利用ResourceBundle类
A、显然是错误的,Java一律采用Unicode编码方式,每个字符无论中文还是英文字符都占用2个字节。
Java的class文件编码为UTF-8,而虚拟机JVM编码为UTF-16
UTF-8编码下,一个中文占3个字节,一个英文占1个字节
B、也是不正确的,不同的编码之间是可以转换的,通常流程如下:
将字符串S以其自身编码方式分解为字节数组,再将字节数组以你想要输出的编码方式重新编码为字符串。
例:String newUTF8Str = new String(oldGBKStr.getBytes(“GBK”), “UTF8”);
C、是正确的。Java虚拟机中通常使用UTF-16的方式保存一个字符
D、是正确的。ResourceBundle能够依据Local的不同,选择性的读取与Local对应后缀的properties文件,以达到国际化的目的。
195、Servlet的生命周期可以分为初始化阶段,运行阶段和销毁阶段三个阶段,以下过程属于初始化阶段是()。
A、加载Servlet类及.class对应的数据
B、创建servletRequest和servletResponse对象
C、创建ServletConfig对象
D、创建Servlet对象
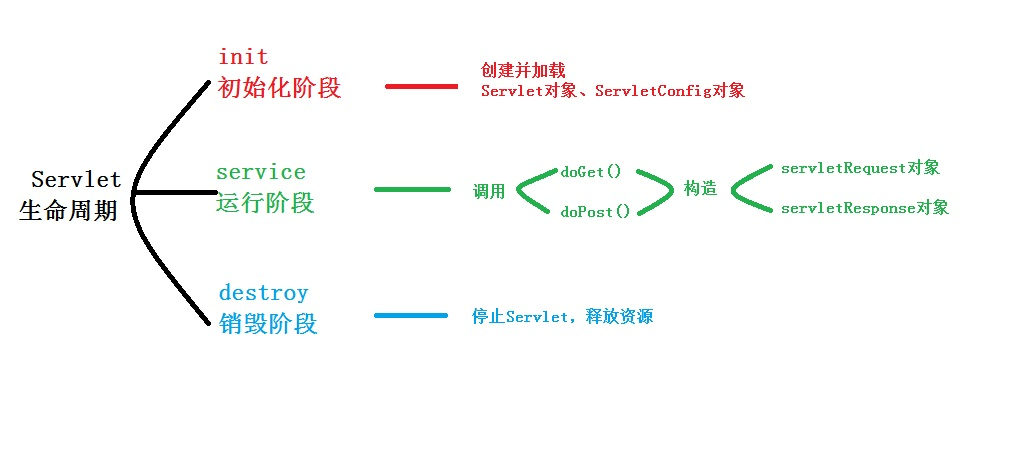
Servlet的生命周期一般可以用三个方法来表示:
init():仅执行一次,负责在装载Servlet时初始化Servlet对象
service() :核心方法,一般HttpServlet中会有get,post两种处理方式。在调用doGet和doPost方法时会构造servletRequest和servletResponse请求和响应对象作为参数。
destory():在停止并且卸载Servlet时执行,负责释放资源 初始化阶段:Servlet启动,会读取配置文件中的信息,构造指定的Servlet对象,创建ServletConfig对象,将ServletConfig作为参数来调用init()方法。所以选ACD。B是在调用service方法时才构造的
196、下面的对象创建方法中哪些会调用构造方法
A、new语句创建对象
B、调用Java.io.ObjectInputStream的readObject方法
C、java反射机制使用java.lang.Class或java.lang.reflect.Constructor的newInstance()方法
D、调用对象的clone()方法
构造函数的作用是完成对象的初始化。当程序执行到new操作符时, 首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化。而选项B、D中,对象的初始化并不是通过构造函数完成的,而是读取别的内存区域中的对象的各个域来完成。
为什么需要克隆对象?直接new一个对象不行吗?因为克隆的对象可能包含一些已经修改过的属性,而new出来的对象的属性都还是初始化时候的值,所以当需要一个新的对象来保存当前对象的“状态”就靠clone方法了。那么我把这个对象的临时属性一个一个的赋值给我新new的对象不也行嘛?可以是可以,但是一来麻烦不说,二来,大家通过上面的源码都发现了clone是一个native方法,是在底层实现的,运行效率特别高特别快。 常见的Object a=new Object();Object b;b=a;这种形式的代码复制的是引用,即对象在内存中的地址,a和b对象仍然指向了同一个对象。 而通过clone方法赋值的对象跟原来的对象时同时独立存在的。
序列化”是一种把对象的状态转化成字节流的机制,“反序列”是其相反的过程,把序列化成的字节流用来在内存中重新创建一个实际的Java对象。这个机制被用来“持久化”对象。通过对象序列化,可以方便的实现对象的持久化储存以及在网络上的传输。

197、在上下文和头文件正常的情况下,代码System.out.println(10%3*2);将打印?
A、1
B、2
C、4
D、6
%和*是同一个优先级,从左到右运算
198、下列哪些语句关于内存回收的说明是正确的?
A、程序员必须创建一个线程来释放内存
B、内存回收程序负责释放无用内存
C、内存回收程序允许程序员直接释放内存
D、内存回收程序可以在指定的时间释放内存对象
A、JVM一旦启动,就会创建一个守护线程来监测是否需要有对象内存被释放。
C、无法直接释放。
D、不可以指定时间,System.gc(),只是提醒JVM可以进行一次Full GC,但是什么时候真正执行,还是不知道的。

199、下面关于垃圾收集的说法正确的是
A、一旦一个对象成为垃圾,就立刻被收集掉。
B、对象空间被收集掉之后,会执行该对象的finalize方法
C、finalize方法和C++的析构函数是完全一回事情
D、一个对象成为垃圾是因为不再有引用指着它,但是线程并非如此
A、在java中,对象的内存在哪个时刻回收,取决于垃圾回收器何时运行。
B、一旦垃圾回收器准备好释放对象占用的存储空间,将首先调用其finalize()方法, 并且在下一次垃圾回收动作发生时,才会真正的回收对象占用的内存(《java 编程思想》)
C、在C++中,对象的内存在哪个时刻被回收,是可以确定的,在C++中,析构函数和资源的释放息息相关,能不能正确处理析构函数,关乎能否正确回收对象内存资源
200、以下Java程序运行的结果是
public class Tester{
public static void main(String[] args){
Integer var1=new Integer(1);
Integer var2=var1;
doSomething(var2);
System.out.print(var1.intValue());
System.out.print(var1==var2);
}
public static void doSomething(Integer integer){
integer=new Integer(2);
}
}
A、1true
B、2true
C、1false
D、2false
java中引用类型的实参向形参的传递,只是传递的引用,而不是传递的对象本身。
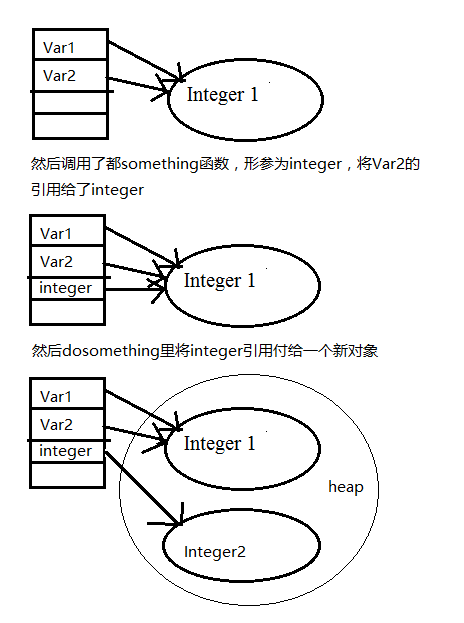
201、下列关于包(package)的描述,正确的是
A、包(package)是Java中描述操作系统对多个源代码文件组织的一种方式。
B、import语句将所对应的Java源文件拷贝到此处执行。
C、包(package)是Eclipse组织Java项目特有的一种方式。
D、定义在同一个包(package)内的类可以不经过import而直接相互使用。
1、为了更好地组织类,Java提供了包机制。包是类的容器,用于分隔类名空间。如果没有指定包名,所有的示例都属于一个默认的无名包。Java中的包一般均包含相关的类,java是跨平台的,所以java中的包和操作系统没有任何关系,java的包是用来组织文件的一种虚拟文件系统。A错
2、import语句并没有将对应的java源文件拷贝到此处仅仅是引入,告诉编译器有使用外部文件,编译的时候要去读取这个外部文件。B错
3、Java提供的包机制与IDE没有关系。C错
4、定义在同一个包(package)内的类可以不经过import而直接相互使用。
202、给出下面的代码段: 在代码说明// assignment x=a, y=b处写入如下哪几个代码是正确的?
public class Base{
int w, x, y ,z;
public Base(int a,int b)
{
x=a; y=b;
}
public Base(int a, int b, int c, int d)
{
// assignment x=a, y=b
w=d;z=c;
}
}
A、Base(a,b);
B、x=a, y=b;
C、x=a; y=b;
D、this(a,b);
A、由于构造器不是静态方法,所以不能直接调用他。
B、错、和C相比应该是分号不是逗号
C、正常赋值操作
D、调用本类的构造方法
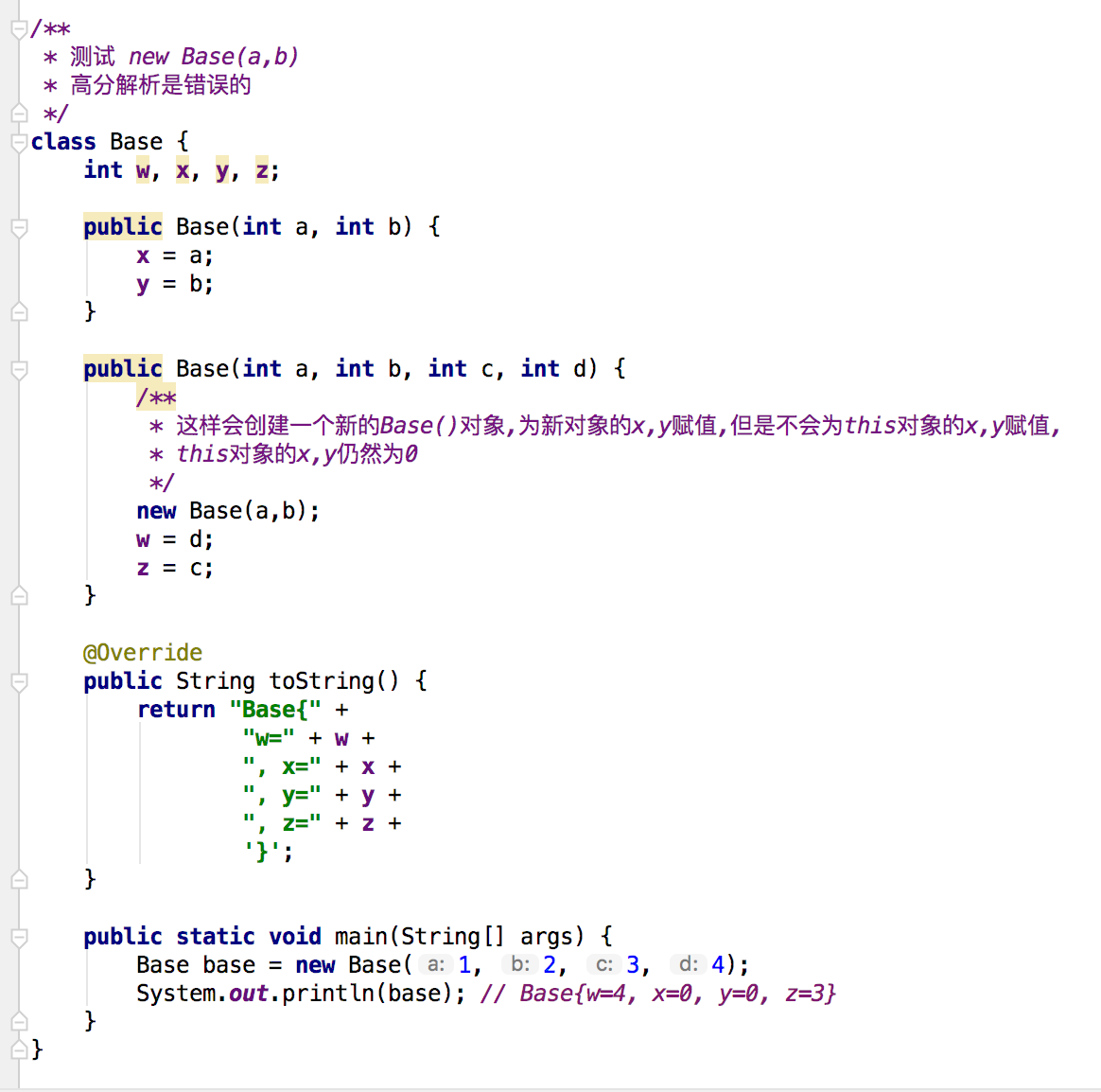
203、以下是java concurrent包下的4个类,选出差别最大的一个
A、Semaphore
B、ReentrantLock
C、Future
D、CountDownLatch
A、Semaphore:类,控制某个资源可被同时访问的个数;
B、ReentrantLock:类,具有与使用synchronized方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大;
C、Future:接口,表示异步计算的结果;
D、CountDownLatch: 类,可以用来在一个线程中等待多个线程完成任务的类。
204、存根(Stub)与以下哪种技术有关
A、交换
B、动态链接
C、动态加载
D、磁盘调度
-
存根类是一个类,它实现了一个接口,它的作用是:如果一个接口有很多方法,如果要实现这个接口,就要实现所有的方法。但是一个类从业务来说,可能只需要其中一两个方法。如果直接去实现这个接口,除了实现所需的方法,还要实现其他所有的无关方法。而如果通过继承存根类就实现接口,就免去了这种麻烦。
-
RMI 采用stubs 和 skeletons 来进行远程对象(remote object)的通讯。stub 充当远程对象的客户端代理,有着和远程对象相同的远程接口,远程对象的调用实际是通过调用该对象的客户端代理对象stub来完成的。
-
每个远程对象都包含一个代理对象stub,当运行在本地Java虚拟机上的程序调用运行在远程Java虚拟机上的对象方法时,它首先在本地创建该对象的代理对象stub, 然后调用代理对象上匹配的方法。每一个远程对象同时也包含一个skeleton对象,skeleton运行在远程对象所在的虚拟机上,接受来自stub对象的调用。这种方式符合等到程序要运行时将目标文件动态链接的思想。
205、下面的类哪些可以处理Unicode字符?
A、InputStreamReader
B、BufferedReader
C、Writer
D、PipedInputStream
简单地说,字符流是字节流根据字节流所要求的编码集解析获得的
可以理解为字符流=字节流+编码集
所以本题中和字符流有关的类都拥有操作编码集(unicode)的能力。
后缀是Stream的都是字节流,其他的都是字符流。
206、java中 String str = "hello world"下列语句错误的是?
A、str+=’ a’
B、int strlen = str.length
C、str=100
D、str=str+100
ABC在java中会报错,D可以正常运行, 所以答案是ABC.
A. ‘a’是字符,’ a’这个是空格和a,必须要用" a"才可以;
B.String有length()方法
C.int 无法直接转成String类型
D.尾部添加字符串”100“
207、下列流当中,属于处理流的是:
A、FilelnputStream
B、lnputStream
C、DatalnputStream
D、BufferedlnputStream
按照流是否直接与特定的地方(如磁盘、内存、设备等)相连,分为节点流和处理流两类。
- 节点流:可以从或向一个特定的地方(节点)读写数据。如FileReader.
- 处理流:是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
JAVA常用的节点流:
- 文 件 FileInputStream FileOutputStrean FileReader FileWriter 文件进行处理的节点流。
- 字符串 StringReader StringWriter 对字符串进行处理的节点流。
- 数 组 ByteArrayInputStream ByteArrayOutputStreamCharArrayReader CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
- 管 道 PipedInputStream PipedOutputStream PipedReaderPipedWriter对管道进行处理的节点流。
常用处理流(关闭处理流使用关闭里面的节点流)
-
缓冲流:BufferedInputStrean BufferedOutputStream BufferedReader BufferedWriter 增加缓冲功能,避免频繁读写硬盘。
-
转换流:InputStreamReader OutputStreamReader 实现字节流和字符流之间的转换。
-
数据流 DataInputStream DataOutputStream 等-提供将基础数据类型写入到文件中,或者读取出来.
流的关闭顺序
- 一般情况下是:先打开的后关闭,后打开的先关闭
- 另一种情况:看依赖关系,如果流a依赖流b,应该先关闭流a,再关闭流b。例如,处理流a依赖节点流b,应该先关闭处理流a,再关闭节点流b
- 可以只关闭处理流,不用关闭节点流。处理流关闭的时候,会调用其处理的节点流的关闭方法。
208、以下哪项陈述是正确的
A、垃圾回收线程的优先级很高,以保证不再使用的内存将被及时回收
B、垃圾收集允许程序开发者明确指定释放哪一个对象
C、垃圾回收机制保证了JAVA程序不会出现内存溢出
D、进入”Dead”状态的线程将被垃圾回收器回收
E、以上都不对
A: 垃圾回收在jvm中优先级相当相当低。
B:垃圾收集器(GC)程序开发者只能推荐JVM进行回收,但何时回收,回收哪些,程序员不能控制。
C:垃圾回收机制只是回收不再使用的JVM内存,如果程序有严重BUG,照样内存溢出。
D:进入DEAD的线程,它还可以恢复,GC不会回收
209、以下JAVA程序的运行结果是什么
public static void main(String[] args) {
Object o1 = true ? new Integer(1) : new Double(2.0);
Object o2;
if (true) {
o2 = new Integer(1);
} else {
o2 = new Double(2.0);
}
System.out.print(o1);
System.out.print(" ");
System.out.print(o2);
}
A、1 1
B、1.0 1.0
C、1 1.0
D、1.0 1
记住这个大坑:三元运算符,遇到相同的值类型时,会自动提升精度,也就是说这道题的Integer会跟随Double大哥走了。
210、下面说法正确的是
A、调用Thread的sleep()方法会释放锁,调用wait()方法不释放锁
B、一个线程调用yield方法,可以使具有相同优先级线程获得处理器
C、在Java中,高优先级的可运行的线程会抢占低优先级线程的资源
D、java中,线程可以调用yield方法使比自己低优先级的线程运行
yield()让当前正在运行的线程回到可运行状态,以允许具有相同优先级的其他线程获得运行的机会。因此,使用yield()的目的是让具有相同优先级的线程之间能够适当的轮换执行。但是,实际中无法保证yield()达到让步的目的,因为,让步的线程可能被线程调度程序再次选中。
wait():等待时线程别人可以用。
sleep():等待时线程还是自己的,别人不能用。
yield():释放锁,同优先级的其他线程有机会获得锁。
211、以下多线程对int型变量x的操作,哪个不需要进行同步
A、++x
B、x=y
C、x++
D、x=1
同步是害怕在操作过程的时候被其他线程也进行读取操作,一旦是原子性的操作就不会发生这种情况。
因为一步到位的操作,其他线程不可能在中间干涉。另外三项都有读取、操作两个步骤,而X=1则是原子性操作。
212、java语言的下面几种数组复制方法中,哪个效率最高
A、for 循环逐一复制
B、System.arraycopy
C、Array.copyOf
D、使用clone方法
复制的效率: System.arraycopy > clone > Arrays.copyOf > for循环
这里面在System类源码中给出了arraycopy的方法,是native方法,也就是本地方法,肯定是最快的。而Arrays.copyOf(注意是Arrays类,不是Array)的实现,在源码中是调用System.copyOf的,多了一个步骤,肯定就不是最快的。前面几个说System.copyOf的不要看,System类底层根本没有这个方法,自己看看源码就全知道了。

213、以下描述正确的是
A、CallableStatement是PreparedStatement的父接口
B、PreparedStatement是CallableStatement的父接口
C、CallableStatement是Statement的父接口
D、PreparedStatement是Statement的父接口
214、下面有关JAVA异常类的描述,说法错误的是
A、异常的继承结构:基类为Throwable,Error和Exception继承Throwable,RuntimeException和IOException等继承Exception
B、非RuntimeException一般是外部错误(非Error),其一般被 try{}catch语句块所捕获
C、Error类体系描述了Java运行系统中的内部错误以及资源耗尽的情形,Error不需要捕捉
D、RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等,必须被 try{}catch语句块所捕获
D选项,RuntimeException并不必须被捕获。不管异常代表的是可预见的异常条件还是编程错误,如果用try{}catch语句捕获它,会让程序在已经出现错误的情况下继续执行下去,也就是说我们不会及时的察觉到程序出现的问题。如果我们不去处理RuntimeException,让程序在测试阶段把异常传播给外界,这时系统打印出来的调用堆栈路径可以帮助我们更快的找出并修改错误,避免出现更大的损失。
215、下面代码输出结果是
int i = 5;
int j = 10;
System.out.println(i + ~j);
A、Compilation error because”~”doesn’t operate on integers
B、-5
C、-6
D、15
公式-n=~n+1可推出~n=-n-1,所以~10=-11再加5结果为-6
216、对Collection和Collections描述正确的是
A、Collection是java.util下的类,它包含有各种有关集合操作的静态方法
B、Collection是java.util下的接口,它是各种集合结构的父接口
C、Collections是java.util下的接口,它是各种集合结构的父接口
D、Collections是java.util下的类,它包含有各种有关集合操作的静态方法
BD java.util.Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式。 java.util.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于Java的Collection框架。
217、下列哪些方法是针对循环优化进行的
A、强度削弱
B、删除归纳变量
C、删除多余运算
D、代码外提
常见的代码优化技术有:复写传播,删除死代码, 强度削弱,归纳变量删除
复写传播:
- 复写语句:形式为f = g 的赋值
- 优化过程中会大量引入复写
- 复写传播变换的做法是在复写语句f = g后,尽可能用g代表f
- 复写传播变换本身并不是优化,但它给其他优化带来机会
- 常量合并(编译时可完成的计算)
- 死代码删除
死代码删除
- 死代码是指计算的结果决不被引用的语句
- 一些优化变换可能会引起死代码
代码外提
- 代码外提是循环优化的一种
- 循环优化的其它重要技术
- 归纳变量删除
- 强度削弱
例:
while(i <= limit - 2) ...
// 代码外提后变成
t = limit - 2;
while(i <= t) ...
归纳变量删除
j = j - 1
t4 = 4 * j
t5 = a[t4]
if t5 > value goto B3
- j和t4的值步伐一致地变化,这样的变量叫作归纳变量
- 在循环中有多个归纳变量时,也许只需要留下一个
- 这个操作由归纳变量删除过程来完成
- 对本例可以先做强度削弱,它给删除归纳变量创造机会
强度削弱
- 强度削弱的本质是把强度大的运算换算成强度小的运算,例如将乘法换成加法运算。
218、关于Java内存区域下列说法不正确的有哪些
A、程序计数器是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的信号指示器,每个线程都需要一个独立的程序计数器.
B、Java虚拟机栈描述的是java方法执行的内存模型,每个方法被执行的时候都会创建一个栈帧,用于存储局部变量表、类信息、动态链接等信息
C、Java堆是java虚拟机所管理的内存中最大的一块,每个线程都拥有一块内存区域,所有的对象实例以及数组都在这里分配内存。
D、方法区是各个线程共享的内存区域,它用于存储已经被虚拟机加载的常量、即时编译器编译后的代码、静态变量等数据。
B.类信息不是存储在java虚拟机栈中,而是存储在方法区中;
C.java堆是被所有线程共享的一块内存区域,而不是每个线程都拥有一块内存区域。
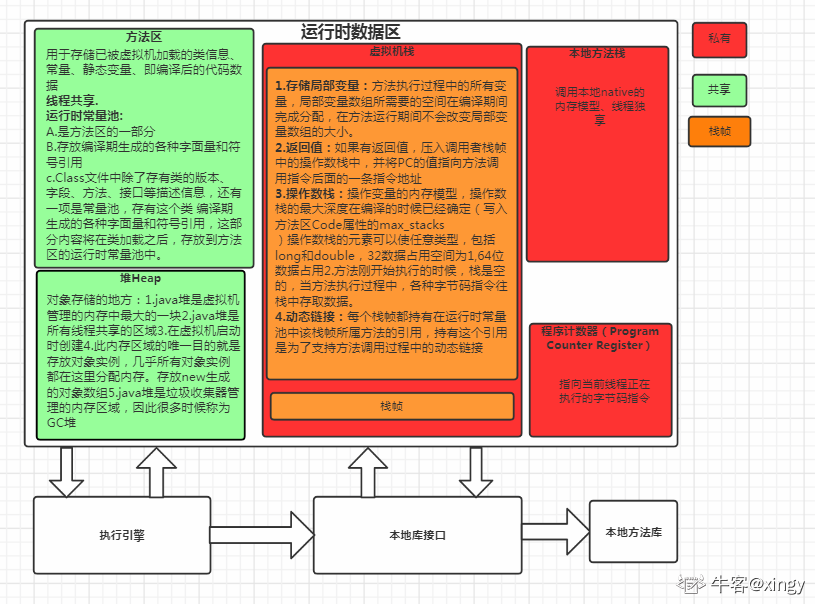
219、对文件名为Test.java的java代码描述正确的是
class Person {
String name = "No name";
public Person(String nm) {
name = nm;
}
}
class Employee extends Person {
String empID = "0000";
public Employee(String id) {
empID = id;
}
}
public class Test {
public static void main(String args[]) {
Employee e = new Employee("123");
System.out.println(e.empID);
}
}
A、输出:0000
B、输出:123
C、编译报错
D、输出:No name
子类的构造方法总是先调用父类的构造方法,如果子类的构造方法没有明显地指明使用父类的哪个构造方法,子类就调用父类不带参数的构造方法。
而父类没有无参的构造函数,所以子类需要在自己的构造函数中显示的调用父类的构造函数。
220、尝试编译以下程序会产生怎么样的结果
public class MyClass {
long var;
public void MyClass(long param) { var = param; }//(1)
public static void main(String[] args) {
MyClass a, b;
a =new MyClass();//(2)
b =new MyClass(5);//(3)
}
}
A、编译错误将发生在(1),因为构造函数不能指定返回值
B、编译错误将发生在(2),因为该类没有默认构造函数
C、编译错误将在(3)处发生,因为该类没有构造函数,该构造函数接受一个int类型的参数
D、该程序将正确编译和执行
虽然方法名和类名相同,不过由于void的修饰,所以它并不是一个构造方法,只是一个普通方法。因此题类仍然只有默认的无参构造器,向构造方法中传入一个参数故而有误。
221、以下哪项不属于java类加载过程?
A、生成java.lang.Class对象
B、int类型对象成员变量赋予默认值
C、执行static块代码
D、类方法解析
类的加载包括:加载,验证,准备,解析,初始化。
选项A:生成java.lang.Class对象是在加载时进行的。生成Class对象作为方法区这个类的各种数据的访问入口。
选项B:既然是对象成员,那么肯定在实例化对象后才有。在类加载的时候会赋予初值的是类变量,而非对象成员。
选项C:这个会调用。可以用反射试验。
选项D:类方法解析发生在解析过程。
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7个阶段。其中准备、验证、解析3个部分统称为连接(Linking)。如图所示。
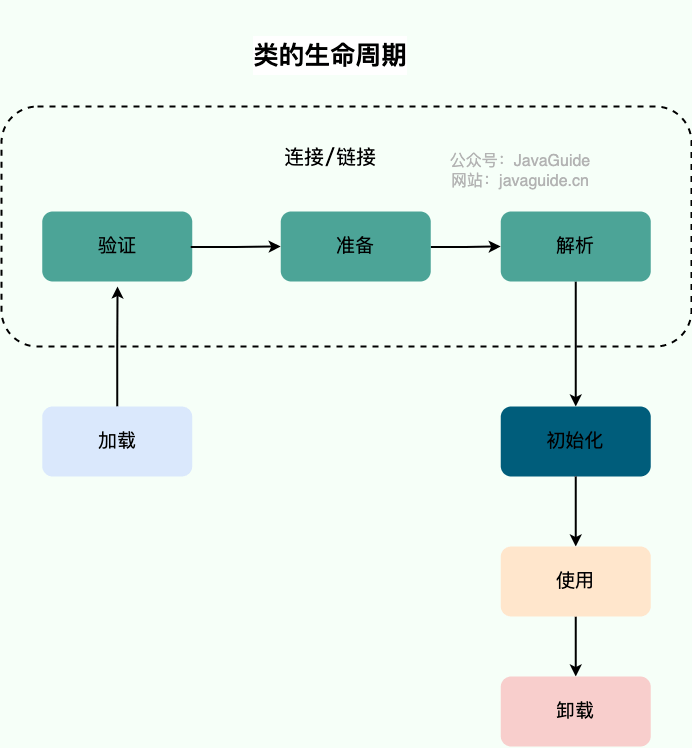
加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。以下陈述的内容都已HotSpot为基准。
加载
在加载阶段(可以参考java.lang.ClassLoader的loadClass()方法),虚拟机需要完成以下3件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流(并没有指明要从一个Class文件中获取,可以从其他渠道,譬如:网络、动态生成、数据库等);
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构;
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口;
加载阶段和连接阶段(Linking)的部分内容(如一部分字节码文件格式验证动作)是交叉进行的,加载阶段尚未完成,连接阶段可能已经开始,但这些夹在加载阶段之中进行的动作,仍然属于连接阶段的内容,这两个阶段的开始时间仍然保持着固定的先后顺序。
验证
验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
验证阶段大致会完成4个阶段的检验动作:
- 文件格式验证:验证字节流是否符合Class文件格式的规范;例如:是否以魔术0xCAFEBABE开头、主次版本号是否在当前虚拟机的处理范围之内、常量池中的常量是否有不被支持的类型。
- 元数据验证:对字节码描述的信息进行语义分析(注意:对比javac编译阶段的语义分析),以保证其描述的信息符合Java语言规范的要求;例如:这个类是否有父类,除了java.lang.Object之外。
- 字节码验证:通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的。
- 符号引用验证:确保解析动作能正确执行。
验证阶段是非常重要的,但不是必须的,它对程序运行期没有影响,如果所引用的类经过反复验证,那么可以考虑采用-Xverifynone参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些变量所使用的内存都将在方法区中进行分配。这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在堆中。其次,这里所说的初始值“通常情况”下是数据类型的零值,假设一个类变量的定义为: public static int value=123;
那变量value在准备阶段过后的初始值为0而不是123.因为这时候尚未开始执行任何java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器()方法之中,所以把value赋值为123的动作将在初始化阶段才会执行。
至于“特殊情况”是指:public static final int value=123,即当类字段的字段属性是ConstantValue时,会在准备阶段初始化为指定的值,所以标注为final之后,value的值在准备阶段初始化为123而非0.
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。
初始化
类初始化阶段是类加载过程的最后一步,到了初始化阶段,才真正开始执行类中定义的java程序代码。在准备极端,变量已经付过一次系统要求的初始值,而在初始化阶段,则根据程序猿通过程序制定的主管计划去初始化类变量和其他资源,或者说:初始化阶段是执行类构造器()方法的过程.
()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块static{}中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问
222、try块后必须有catch块
A、对
B、错
选B,catch可以省略,try的形式有三种:
try-catch
try-finally
try-catch-finally
但catch和finally语句不能同时省略!
223、关于ThreadLocal类 以下说法正确的是
A、ThreadLocal继承自Thread
B、ThreadLocal实现了Runnable接口
C、ThreadLocal重要作用在于多线程间的数据共享
D、ThreadLocal是采用哈希表的方式来为每个线程都提供一个变量的副本
E、ThreadLocal保证各个线程间数据安全,每个线程的数据不会被另外线程访问和破坏
选DE.
1、ThreadLocal的类声明:
public class ThreadLocal
可以看出ThreadLocal并没有继承自Thread,也没有实现Runnable接口。所以AB都不对。
2、ThreadLocal类为每一个线程都维护了自己独有的变量拷贝。每个线程都拥有了自己独立的一个变量。
所以ThreadLocal重要作用并不在于多线程间的数据共享,而是数据的独立,C选项错。
由于每个线程在访问该变量时,读取和修改的,都是自己独有的那一份变量拷贝,不会被其他线程访问,
变量被彻底封闭在每个访问的线程中。所以E对。
3、ThreadLocal中定义了一个哈希表用于为每个线程都提供一个变量的副本:
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
} 所以D对。
224、以下程序的运行结果是
TreeSet<Integer> set = new TreeSet<Integer>();
TreeSet<Integer> subSet = new TreeSet<Integer>();
for(int i=606;i<613;i++){
if(i%2==0){
set.add(i);
}
}
subSet = (TreeSet)set.subSet(608,true,611,true);
set.add(609);
System.out.println(set+" "+subSet);
A、编译失败
B、发生运行时异常
C、[606, 608, 609,610, 612] [608, 609,610]
D、[606, 608, 609,610, 612] [608, 610]
subset(form,true,to,true)是Treeset的非静态方法,该方法返回从form元素到to元素的一个set集合,两个boolean类型是确认是否包含边界值用的。
subSet是指向原数据的,原数据修改,subSet也跟着修改。
225、执行如下程序代码后,sum的值是
char chr = 127;
int sum = 200;
chr += 1;
sum += chr;
备注:同时考虑c/c++和Java的情况的话
A、72
B、99
C、328
D、327
java中只有byte, boolean是一个字节, char是两个字节, 所以对于java来说127不会发生溢出, 输出328
但是对于c/c++语言来说, char是一个字节, 会发生溢出, 对127加一发生溢出, 0111 1111 --> 1000 0000, 1000 0000为补码-128, 所以结果为200-128=72
226、下列说法正确的是
A、volatile,synchronized都可以修改变量,方法以及代码块
B、volatile,synchronized 在多线程中都会存在阻塞问题
C、volatile能保证数据的可见性,但不能完全保证数据的原子性,synchronized即保证了数据的可见性也保证了原子性
D、volatile解决的是变量在多个线程之间的可见性、原子性,而sychroized解决的是多个线程之间访问资源的同步性
关键字volatile是线程同步的轻量级实现,所以volatile性能肯定比synchronized要好,并且只能修改变量,而synchronized可以修饰方法,以及代码块。
多线程访问volatile不会发生阻塞,而synchronized会出现阻塞。
volatile能保证数据的可见性,但不能保证原子性;而synchronized可以保证原子性,也可以间接保证可见性,因为它会将私有内存和公共内存中的数据做同步。
关键字volatile解决的下变量在多线程之间的可见性;而synchronized解决的是多线程之间资源同步问题。
227、下面有关servlet service描述错误的是?
A、不管是post还是get方法提交过来的连接,都会在service中处理
B、doGet/doPost 则是在 javax.servlet.GenericServlet 中实现的
C、service()是在javax.servlet.Servlet接口中定义的
D、service判断请求类型,决定是调用doGet还是doPost方法
doGet/doPost 则是在 javax.servlet.http.HttpServlet 中实现的
228、Hashtable 和 HashMap 的区别是:
A、Hashtable 是一个哈希表,该类继承了 AbstractMap,实现了 Map 接口
B、HashMap 是内部基于哈希表实现,该类继承AbstractMap,实现Map接口
C、Hashtable 线程安全的,而 HashMap 是线程不安全的
D、Properties 类 继承了 Hashtable 类,而 Hashtable 类则继承Dictionary 类
E、HashMap允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。
Hashtable:
(1)Hashtable 是一个散列表,它存储的内容是键值对(key-value)映射。
(2)Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
(3)HashTable直接使用对象的hashCode。
HashMap:
(1)由数组+链表组成的,基于哈希表的Map实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
(2)不是线程安全的,HashMap可以接受为null的键(key)和值(value)。
(3)HashMap重新计算hash值
229、假设num已经被创建为一个ArrayList对象,并且最初包含以下整数值:[0,0,4,2,5,0,3,0]。 执行下面的方法numQuest(),数组num会变成?
private List<Integer> nums;
//precondition: nums.size() > 0
//nums contains Integer objects
public void numQuest() {
int k = 0;
Integer zero = new Integer(0);
while (k < nums.size()) {
if (nums.get(k).equals(zero))
nums.remove(k);
k++;
}
}
A、[3, 5, 2, 4, 0, 0, 0, 0]
B、[0, 0, 0, 0, 4, 2, 5, 3]
C、[0, 0, 4, 2, 5, 0, 3, 0]
D、[0, 4, 2, 5, 3]
做这种题还是要一步一步来,不然一不小心就掉坑里:
List中的 get ( i )指的是获取下标(索引)为 i 的元素,也就是第 i+1 个元素
本题:
zero== 0,如果get(k)== 0,执行remove(k); ;
size== 8 ; k == 0 , 因此第一次remove(0) ,删除索引为0的元素也就是第一个元素0,然后k++, size()–;
此时集合元素为 :[0,4,2,5,0,3,0]
size== 7; k== 1,因此get(1)== 4 !=0 , 不执行remove(); k++,因没有删除元素,size()不变,
此时集合元素为:[0,4,2,5,0,3,0]
size== 7;k== 2,k++;
size== 7;k== 3,k++;
size== 7;k== 4,get(4)== 0,remove(4) ; k++, size()–;
此时集合元素为: [0,4,2,5,3,0]
size== 6;k== 5,get(5)== 0,remove(5);k++, size()–;
此时集合元素为: [0,4,2,5,3]
size== 5; k== 6 ;退出循环;最终输出此时集合元素为 [0,4,2,5,3] ;
一般更改删除集合元素,使用iterator()迭代器,不推荐使用这种;
230、关于下面代码片段叙述正确的是
byte b1=1,b2=2,b3,b6;
final byte b4=4,b5=6;
b6=b4+b5;
b3=(b1+b2);
System.out.println(b3+b6);
A、输出结果:13
B、语句:b6=b4+b5编译出错
C、语句:b3=b1+b2编译出错
D、运行期抛出异常
被final修饰的变量是常量,这里的b6=b4+b5可以看成是b6=10;在编译时就已经变为b6=10了。
而b1和b2是byte类型,java中进行计算时候将他们提升为int类型,再进行计算,b1+b2计算后已经是int类型,赋值给b3,b3是byte类型,类型不匹配,编译不会通过,需要进行强制转换。
Java中的byte,short,char进行计算时都会提升为int类型。
231、关于下面这段Java程序,哪些描述是正确的:
public class ThreadTest extends Thread {
public void run() {
System.out.println("In run");
yield();
System.out.println("Leaving run");
}
public static void main(String []argv) {
(new ThreadTest()).start();
}
}
A、程序运行输出只有In run
B、程序运行输出只有Leaving run
C、程序运行输出先有In run后有Leaving run
D、程序运行输出先有Leaving run后有In run
E、程序没有任何输出就退出了
F、程序将被挂起,只能强制退出
Thread.yield()方法作用是:暂停当前正在执行的线程对象,并执行其他线程。
yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
232、下面哪个Java语句声明了一个适合于创建50个字符串对象数组的变量?
A、char a[][];
B、String a[];
C、String[] a;
D、Object a[50];
E、String a[50];
F、Object a[];
A:char[][] 定义了二位字符数组。在Java中,使用字符串对char数组赋值,必须使用toCharArray()方法进行转换。所以A错误。
B、C:在Java中定义String数组,有两种定义方式:String a[]和String[] a。所以B、C正确。
D、E:数组是一个引用类型变量 ,因此使用它定义一个变量时,仅仅定义了一个变量 ,这个引用变量还未指向任何有效的内存 ,因此定义数组不能指定数组的长度。所以D、E错误。
F:Object类是所有类的父类。子类其实是一种特殊的父类,因此子类对象可以直接赋值给父类引用变量,无须强制转换,这也被称为向上转型。这体现了多态的思想。所以F正确。
233、以下语句返回值为 true 的是

A、a1 == a2
B、d1 == d2
C、b1 == b2
D、c1 == c2
对于-128到127之间的数, Integer直接从数组中取, 故a1, a2指向的是同一个对象, A正确。其余都是new出来的对象, 显然地址都不相同。int类型与Integer类型比较时, 先将Integer拆箱, 再比较值, 故B正确.
234、java8中,下面哪个类用到了解决哈希冲突的开放定址法
A、LinkedHashSet
B、HashMap
C、ThreadLocal
D、TreeMap
threadlocalmap使用开放定址法解决hash冲突,hashmap使用链地址法解决hash冲突
235、关于java集合下列说法不正确的有哪些
A、HashSet 它是线程安全的,不允许存储相同的对象
B、ConcurrentHashMap 它是线程安全的,其中存储的键对象可以重复,值对象不能重复
C、Collection接口是List接口和Set接口的父接口,通常情况下不被直接使用
D、ArrayList线程安全的,允许存放重复对象
A: HashSet 它不是线程安全的,属于Set接口下的实现类,Set下的实现类特征就是无序,不允许存储相同的对象
B: ConcurrentHashMap 是线程安全的,用HashMap实现,特征也相似,其中存储的值对象可以重复,键对象不能重复
C: Collection接口是List接口和Set接口的父接口,通常情况下不被直接使用
D: ArrayList线程不安全的,底层是数组实现,允许存放重复对象
236、以下代码执行的结果显示是多少

A、num * count = 505000
B、num * count = 0
C、运行时错误
D、num * count = 5050
count = count++ 原理是 temp = count; count = count+1 ; count = temp; 因此count始终是0 这仅限于java 与c是不一样的.
237、JavaWEB中有一个类,当会话种绑定了属性或者删除了属性时,他会得到通知,这个类是
A、HttpSessionAttributeListener
B、HttpSessionBindingListener
C、HttpSessionObjectListener
D、HttpSessionListener;
E、HttpSession
F、HttpSessionActivationListener
HttpSessionAttributeListener:可以实现此侦听器接口获取此web应用程序中会话属性列表更改的通知;
HttpSessionBindingListener:当该对象从一个会话中被绑定或者解绑时通知该对象,这个对象由HttpSessionBindingEvent对象通知。这可能是servlet程序显式地从会话中解绑定属性的结果,可能是由于会话无效,也可能是由于会话超时;
HttpSessionObjectListener:没有该接口API;
HttpSessionListener:当web应用程序中的活动会话列表发生更改时通知该接口的实现类,为了接收该通知事件,必须在web应用程序的部署描述符中配置实现类;
HttpSessionActivationListener:绑定到会话的对象可以侦听容器事件,通知它们会话将被钝化,会话将被激活。需要一个在虚拟机之间迁移会话或持久会话的容器来通知所有绑定到实现该接口会话的属性。
238、已知String a=“a”,String b=“b”,String c=a+b,String d=new String(“ab”) 以下操作结果为true的是
A、(a+b).equals©
B、a+b==c
C、c==d
D、c.equals(d)
1.== 和 equals():
(1) == 用于比较基本数据类型时比较的是值,用于比较引用类型时比较的是引用指向的地址。
2)Object 中的equals() 与 “==” 的作用相同,但String类重写了equals()方法,比较的是对象中的内容。
2.String对象的两种创建方式:
(1)第一种方式: String str1 = “aaa”; 是在常量池中获取对象(“aaa” 属于字符串字面量,因此编译时期会在常量池中创建一个字符串对象,如果常量池中已经存在该字符串对象则直接引用)
(2)第二种方式: String str2 = new String(“aaa”) ; 一共会创建两个字符串对象一个在堆中,一个在常量池中(前提是常量池中还没有 “aaa” 象)。
System.out.println(str1==str2);//false
3.String类型的常量池比较特殊。它的主要使用方法有两种:
(1)直接使用双引号声明出来的String对象会直接存储在常量池中。
(2)如果不是用双引号声明的String对象,可以使用 String 提供的 intern 方法。 String.intern() 是一个 Native 方法,它的作用是: 如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用; 如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
String s1 = new String(“AAA”);
String s2 = s1.intern();
String s3 = “AAA”;
System.out.println(s2);//AAA
System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象一个是常量池中的String对象,
System.out.println(s2 == s3);//true, s1,s2指向常量池中的”AAA“
4字符串拼接:
String a = “a”;
String b = “b”;
String str1 = “a” + “b”;//常量池中的对象
String str2 = a + b; //在堆上创建的新的对象
String str3 = “ab”;//常量池中的对象
System.out.println(str1 == str2);//false
System.out.println(str1 == str3);//true
System.out.println(str2 == str3);//false
239、下面关于变量及其范围的陈述哪些是不正确的
A、实例变量是类的成员变量
B、实例变量用关键字static声明
C、在方法中定义的局部变量在该方法被执行时创建
D、局部变量在使用前必须被初始化
A.类的成员变量包括实例变量和类变量(静态变量),成员方法包括实例方法和类方法(静态方法)。 A正确
B.类变量(静态变量)用关键字static声明,B错误
C.方法中的局部变量在方法被调用加载时开始入栈时创建,方法入栈创建栈帧包括局部变量表操作数栈,局部变量表存放局部变量,并非在执行该方法时被创建,C错误
D.局部变量被使用前必须初始化,否则程序报错。D正确
240、下面程序运行完之后,t2与t3的关系为
Object obj=new Object();
List aList=new ArrayList();
List bList=new LinkedList();
long t1=System.currentTimeMillis();
for(int i=0;i<50000;i++){
aList.add(0,obj);
}
long t2=System.currentTimeMillis()-t1;
t1=System.currentTimeMillis();
for(int i=0;i<50000;i++){
bList.add(0,obj);
}
long t3=System.currentTimeMillis()-t1;
A、t2
B、t2=t3
C、不确定
D、t2>t3
关于linkedlist和arraylist的插入速度不能一棒子打死。如果都是从尾部插入,即直接add数据,在数据量大的时候应该arraylist要快一点,因为后面的1.5倍扩容会随着数据量增大而越来越慢(0.5倍的量变大了),但是就单个插入操作来说数组还是比双向链表快一些的。数据量小就差不多了。此题是头插,就大不一样了,双向链表头插时间复杂度是O(1),而数组要先把数全往后挪一下再将值放在0位置,就算不考虑扩容,时间复杂度也是O(n),所以这时候链表要比数组快的多。
241、当我们需要所有线程都执行到某一处,才进行后面的的代码执行我们可以使用?
A、CountDownLatch
B、CyclicBarrier
C、Semaphore
D、Future
CountDownLatch 允许一个线程或多个线程等待特定情况,同步完成线程中其他任务。举例:百米赛跑,就绪运动员等待发令枪发动才能起步。
CyclicBarrier 和CountDownLatch一样都可以协同多个线程,让指定数量的线程等待期他所有的线程都满足某些条件之后才继续执行。举例:排队上摩天轮时,每到齐四个人,就可以上同一个车厢。
242、CMS垃圾回收器在那些阶段是没用用户线程参与的
A、初始标记
B、并发标记
C、重新标记
D、并发清理
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器,对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。
CMS的基础算法是:标记—清除。
它的过程可以分为以下6个步骤:
- 初始标记(STW initial mark)
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
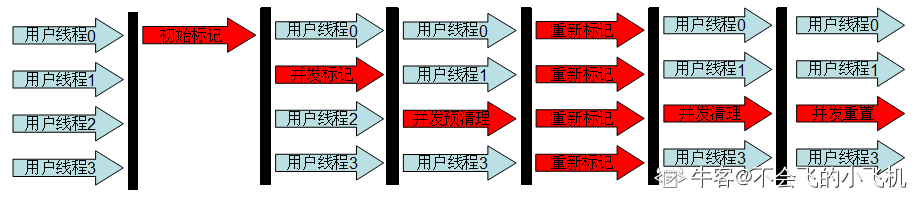
- 初始标记:在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的"根对象"开始,只扫描到能够和"根对象"直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
- **并发标记:**这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,*应用程序的线程和并发标记的线程并发执行,所以*用户不会感受到停顿*。*
- 并发预清理:并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段"重新标记"的工作,因为下一个阶段会Stop The World。
- 重新标记:这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从"根对象"开始向下追溯,并处理对象关联。
- **并发清理:**清理垃圾对象,*这个阶段收集器线程和应用程序线程并发执行*。
- **并发重置:**这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
CMS不会整理、压缩堆空间,这样就带来一个问题:经过CMS收集的堆会产生空间碎片,CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。
为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。
B.并发标记 和 D.并发清理 这两个阶段是有用户线程参与的,所以答案选A和C。
243、关于Java中参数传递的说法,哪个是错误的?
A、在方法中,修改一个基础类型的参数不会影响原始参数值
B、在方法中,改变一个对象参数的引用不会影响到原始引用
C、在方法中,修改一个对象的属性会影响原始对象参数
D、在方法中,修改集合和Maps的元素不会影响原始集合参数
方法传入的参数是一个副本,基本数据类型就是值相同,引用类型就是相同地址引用。
A修改基本数据类型,与原变量无关。
B改变参数引用,即将这个引用指向另一地址,而原引用对象仍然指向原地址。
C改变属性相当于修改引用指向的地址上保存的数据,比方说都指向一个Person person,修改了age就是修改了这个类的属性。
DMaps和集合也是引用对象。同C
244、在java7中,下列哪个说法是正确的:
A、ConcurrentHashMap使用synchronized关键字保证线程安全
B、HashMap实现了Collection接口
C、Arrays.asList方法返回java.util.ArrayList对象
D、SimpleDateFormat对象是线程不安全的
A. hashMap在单线程中使用大大提高效率,在多线程的情况下使用hashTable来确保安全。hashTable中使用synchronized关键字来实现安全机制,但是synchronized是对整张hash表进行锁定即让线程独享整张hash表,在安全同时造成了浪费。concurrentHashMap采用分段加锁的机制来确保安全。ConcurrentHashMap使用segment来分段和管理锁,segment继承自ReentrantLock,因此ConcurrentHashMap使用ReentrantLock来保证线程安全。
B. HashMap实现的是Map接口,Map和Collection是同一级别的
C. Arrays.asList()将一个数组转化为一个List对象,这个方法**返回一个ArrayList类型的对象, 这个ArrayList类并非java.util.ArrayList类,**而是Arrays类的静态内部类!用这个对象对列表进行添加删除更新操作,就会报UnsupportedOperationException异常。
245、下面关于Spring的说法中错误的是
A、Spring是一个支持快速开发Java EE框架的框架
B、Spring中包含一个“依赖注入”模式的实现
C、使用Spring可以实现声明式事务
D、Spring提供了AOP方式的日志系统
Spring并没有为我们提供日志系统,我们需要使用AOP(面向方面编程)的方式,借助Spring与日志系统log4j实现我们自己的日志系统。
246、下面描述属于java虚拟机功能的是?
A、通过 ClassLoader 寻找和装载 class 文件
B、解释字节码成为指令并执行,提供 class 文件的运行环境
C、进行运行期间垃圾回收
D、提供与硬件交互的平台
虚拟机是运行在操作系统之上的,不与硬件交互
247、下面哪个不属于HttpServletResponse接口完成的功能?
A、设置HTTP头标
B、设置cookie
C、读取路径信息
D、输出返回数据
A:设置HTTP头标
response.setHeader(“Refresh”,“3”); //三秒刷新页面一次
B:设置cookie
Cookie c1 = new Cookie(“username”,“only”);
response.addCookie(c1);
C(错误):读取路径信息,request读取路径信息
从request获取各种路径总结
request.getRealPath(“url”); // 虚拟目录映射为实际目录
request.getRealPath(“./”); // 网页所在的目录
request.getRealPath(“…/”); // 网页所在目录的上一层目录
request.getContextPath(); // 应用的web目录的名称
D:输出返回数据
HttpServleteResponse.getOutputStream().write();
248、假设 a 是一个由线程 1 和线程 2 共享的初始值为 0 的全局变量,则线程 1 和线程 2 同时执行下面的代码,最终 a 的结果不可能是
boolean isOdd = false;
for(int i=1;i<=2;++i){
if(i%2==1)isOdd = true;
else isOdd = false;
a+=i*(isOdd?1:-1);
}
A、-1
B、-2
C、0
D、1
易知:每个线程对a 均做了两次读写操作,分别是 “ +1 ” 和 “ -2 ”
而题目问了是最终a 的结果,所以 a 的结果取决于各自线程对 a 的先后读写的顺序
结论:a的可能取值为-1、0、-2
249、下面正确的2项是
public class NameList
{
private List names = new ArrayList();
public synchronized void add(String name)
{
names.add(name);
}
public synchronized void printAll() {
for (int i = 0; i < names.size(); i++)
{
System.out.print(names.get(i) + "");
}
}
public static void main(String[]args)
{
final NameList sl = new NameList();
for (int i = 0; i < 2; i++)
{
new Thread()
{
public void run()
{
sl.add("A");
sl.add("B");
sl.add("C");
sl.printAll();
}
} .start();
}
}
}
A、运行的时候可能抛异常
B、运行的时候可能没有输出,也没有正常退出
C、代码运行的时候可能没有输出,但是正常退出
D、代码输出"A B A B C C "
E、代码输出"A B C A B C A B C "
F、代码输出"A A A B C A B C C "
G、代码输出"A B C A A B C A B C "
250、如果希望监听TCP端口9000,服务器端应该怎样创建socket?
A、new Socket(“localhost”,9000);
B、new ServerSocket(9000);
C、new Socket(9000);
D、new ServerSocket(“localhost”,9000);
ServerSocket(int port) 是服务端绑定port端口,调accept()监听等待客户端连接,它返回一个连接队列中的一个socket。
Socket(InetAddress address , int port)是创建客户端连接主机的socket流,其中InetAddress是用来记录主机的类,port指定端口。
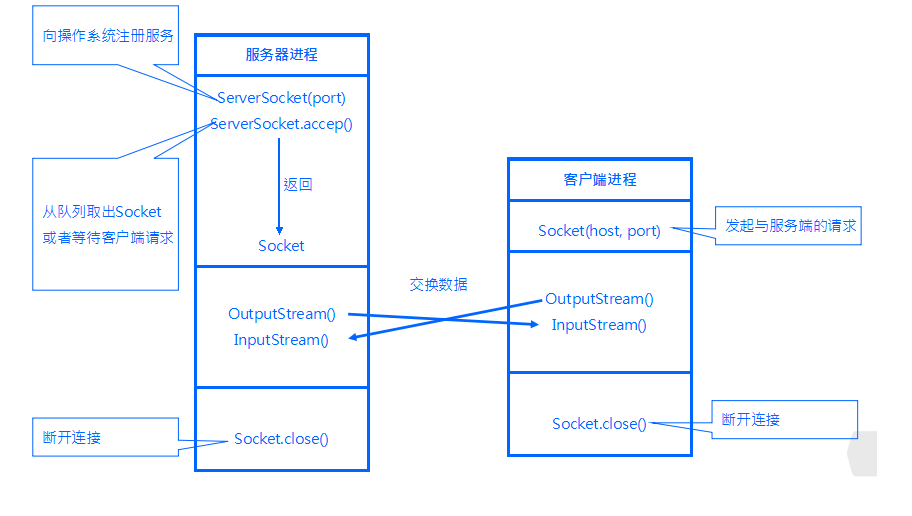
251、下列哪些操作会使线程释放锁资源?
A、sleep()
B、wait()
C、join()
D、yield()
1.sleep会使当前线程睡眠指定时间,不释放锁
2.yield会使当前线程重回到可执行状态,等待cpu的调度,不释放锁
3.wait会使当前线程回到线程池中等待,释放锁,当被其他线程使用notify,notifyAll唤醒时进入可执行状态
4.当前线程调用 某线程.join() 时会使当前线程等待某线程执行完毕再结束,底层调用了wait,释放锁
252、下列说法正确的是
A、对于局部内部类,只有在方法的局部变量被标记为final或局部变量是effctively final的,内部类才能使用它们
B、成员内部类位于外部类内部,可以直接调用外部类的所有方法(静态方法和非静态方法)
C、由于匿名内部类只能用在方法内部,所以匿名内部类的用法与局部内部类是一致的
D、静态内部类可以直接访问外部类的非静态成员


253、如下代码的输出结果是什么
public class Test {
public int aMethod(){
static int i = 0;
i++;
return i;
}
public static void main(String args[]){
Test test = new Test();
test.aMethod();
int j = test.aMethod();
System.out.println(j);
}
}
A、0
B、1
C、2
D、编译失败
静态变量只能在类主体中定义,不能在方法中定义
254、下列不属于Java语言性特点的是
A、Java致力于检查程序在编译和运行时的错误
B、Java能运行虚拟机实现跨平台
C、Java自己操纵内存减少了内存出错的可能性
D、Java还实现了真数组,避免了覆盖数据的可能
255、下面哪个行为被打断不会导致InterruptedException
A、Thread.join
B、Thread.sleep
C、Object.wait
D、CyclicBarrier.await
E、Thread.suspend
抛InterruptedException的代表方法有:
- java.lang.Object 类的 wait 方法
- java.lang.Thread 类的 sleep 方法
- java.lang.Thread 类的 join 方法
256、以下代码将打印出
public static void main (String[] args) {
String classFile = "com.jd.". replaceAll(".", "/") + "MyClass.class";
System.out.println(classFile);
}
A、com. jd
B、com/jd/MyClass.class
C、///MyClass.class
D、com.jd.MyClass
由于replaceAll方法的第一个参数是一个正则表达式,而".“在正则表达式中表示任何字符,所以会把前面字符串的所有字符都替换成”/“。如果想替换的只是”.“,那么久要写成”\.".
257、下面代码运行结果是?
public class Test{
static{
int x=5;
}
static int x,y;
public static void main(String args[]){
x--;
myMethod( );
System.out.println(x+y+ ++x);
}
public static void myMethod( ){
y=x++ + ++x;
}
}
A、compiletime error
B、prints:1
C、prints:2
D、prints:3
E、prints:7
F、prints:8
1.静态语句块中x为局部变量,不影响静态变量x的值
2.x和y为静态变量,默认初始值为0,属于当前类,其值得改变会影响整个类运行。
3.java中自增操作非原子性的
main方法中:
执行x–后 x=-1
调用myMethod方法,y=x++ + ++x可以看成是y=(x++)+(++x),当++或者–和其它变量进行运算时,x++表示先运算,再自增,++x表示先自增再参与运算。所以就时x为-1参与运算,然后自增,x此时为0,++x后x为1,然后参与运算,那么y=-1+1就为0,此时x为1
x+y+ ++x,先执行x+y,结果为1,执行++x结果为2,得到最终结果为3
258、假定Base b = new Derived(); 调用执行b.methodOne()后,输出结果是什么?
public class Base
{
public void methodOne()
{
System.out.print("A");
methodTwo();
}
public void methodTwo()
{
System.out.print("B");
}
}
public class Derived extends Base
{
public void methodOne()
{
super.methodOne();
System.out.print("C");
}
public void methodTwo()
{
super.methodTwo();
System.out.print("D");
}
}
A、ABDC
B、AB
C、ABCD
D、ABC
只要是被子类重写的方法,不被super调用都是调用子类方法
259、以下说法错误的是
A、其他选项均不正确
B、java线程类优先级相同
C、Thread和Runnable接口没有区别
D、如果一个类继承了某个类,只能使用Runnable实现线程
B选项,在java中线程是有分优先等级的所以优先级不能相同,错误
C选项,Thread实现了Runnable接口是一个类不是接口,错误
D选项,实现多线程的三种方式,一种是继承Thread类使用此方式就不能继承其他的类了。还有两种是实现Runnable接口或者实现Callable接口,所以D错误。
260、Thread. sleep()是否会抛出checked exception?
A、是
B、否
Thread的静态方法sleep,实例方法join;Object的实例方法wait;CyclicBarrier的实例方法await;都会抛出受检异常。
261、有关静态初始化块说法正确的是?
A、无法直接调用静态初始化块
B、在创建第一个实例前或引用任何静态成员之前,将自动调用静态初始化块来初始化
C、静态初始化块既没有访问修饰符,也没有参数
D、在程序中,用户可以控制何时执行静态初始化块
JAVA的初始化顺序:
父类的静态区>子类的静态区>父类的代码块>父类的构造方法>子类的代码块>子类的构造方法
静态区包含静态方法和静态代码块,谁在前先执行谁!
262、关于Java的一些概念,下面哪些描述是正确的
A、所有的Java异常和错误的基类都是java.lang.Exception, 包括java.lang.RuntimeException
B、java中所有的数据都是对象
C、Java通过垃圾回收回收不再引用的变量,垃圾回收时对象的finallize方法一定会得到执行
D、Java是跨平台的语言,无论通过哪个版本的Java编写的程序都能在所有的Java运行平台中运行
E、Java通过synchronized进行访问的同步,synchronized作用非静态成员方法和静态成员方法上同步的目标是不同的
F、通过try … catch … finally语句,finally中的语句部分无论发生什么异常都会得到执行
A、java异常和错误的基类Throwable,包括Exception和Error
B、java是面向对象的,但是不是所有的都是对象,基本数据类型就不是对象,所以才会有封装类的;
263、下列哪个语句语法正确
A、byte y = 11; byte x = y +y;
B、String x = new Object();
C、Object x = new String(“Hellow”);
D、int a [11] = new int [11];
对于A,前一半语句赋值是没有问题的,问题是后半句,在对byte型的变量进行相加时,会先自动转换为int型进行计算,所以计算结果也是int型的,int型赋值给byte需要强制转换,所以A会出错。
对于B,因为object是String的父类,所以不能这样使用,不能把父类对象赋值给子类,只能是Object x = new String();
对于C,因为String是Object的子类,所以可以将子类赋值给父类。
对于D,因为在声明变量时不需要指定容量,例如int a[] = new int[11];这样是正确的,但是像D选项这样是错误。
264、下面哪些描述是正确的
public class Test {
public static class A {
private B ref;
public void setB(B b) {
ref = b;
}
}
public static Class B {
private A ref;
public void setA(A a) {
ref = a;
}
}
public static void main(String args[]) {
…
start();
….
}
public static void start() {
A a = new A();
B b = new B();
a.setB(b);
b = null; //
a = null;
…
}
}
A、b = null执行后b可以被垃圾回收
B、a = null执行后b可以被垃圾回收
C、a = null执行后a可以被垃圾回收
D、a,b必须在整个程序结束后才能被垃圾回收
E、类A和类B在设计上有循环引用,会导致内存泄露
F、a, b 必须在start方法执行完毕才能被垃圾回收
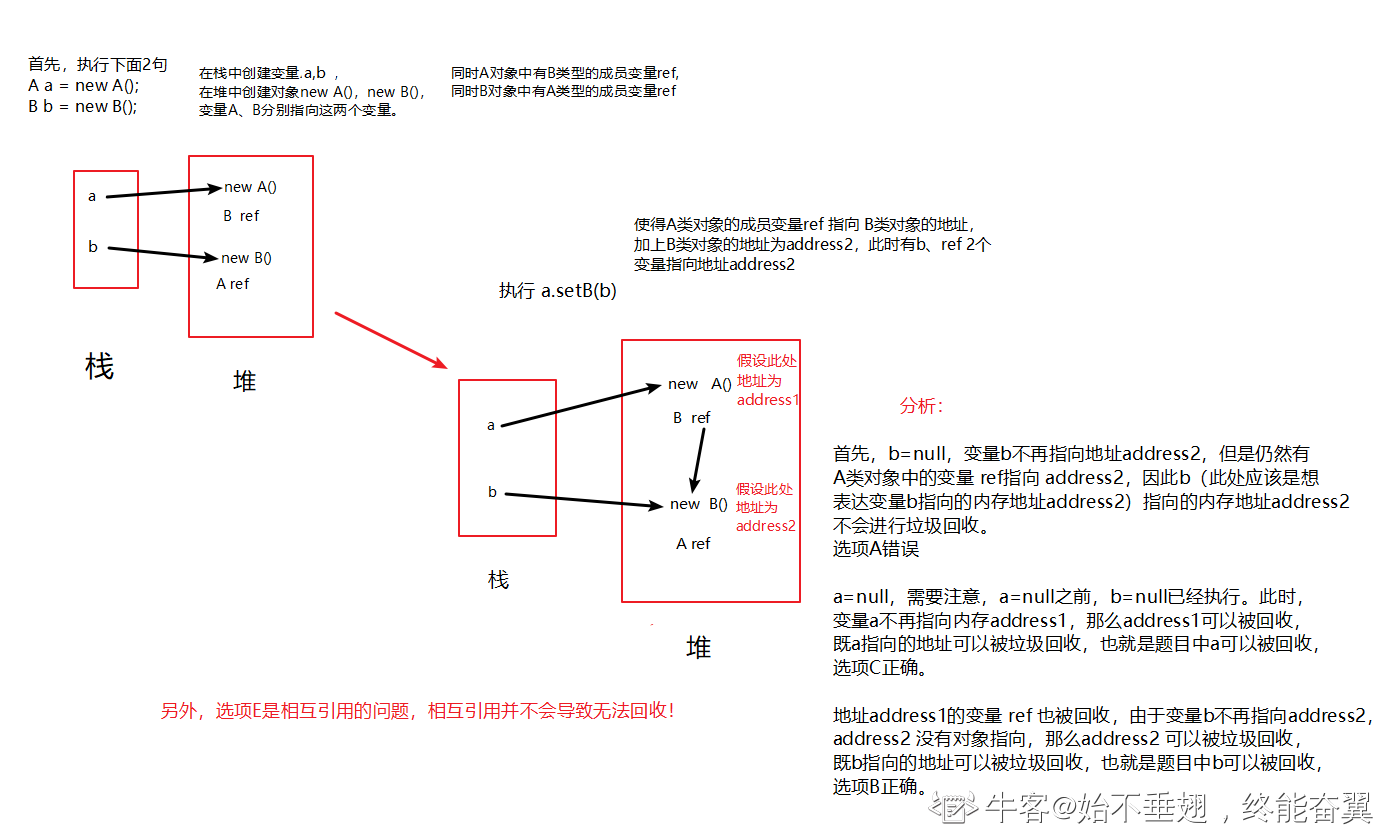
265、在java的多态调用中,new的是哪一个类就是调用的哪个类的方法。
A、是
B、否
java多态有两种情况:重载和覆写
在覆写中,运用的是动态单分配,是根据new的类型确定对象,从而确定调用的方法;
在重载中,运用的是静态多分派,即根据静态类型确定对象,因此不是根据new的类型确定调用的方法
266、java中下面哪个能创建并启动线程
public class MyRunnable implements Runnable {
public void run() {
//some code here
}
}
A、new Runnable(MyRunnable).start()
B、new Thread(MyRunnable).run()
C、new Thread(new MyRunnable()).start()
D、new MyRunnable().start()
C正确
首先:创建并启动线程的过程为:定义线程—》实例化线程—》启动线程。
一 、定义线程: 1、扩展java.lang.Thread类。 2、实现java.lang.Runnable接口。
二、实例化线程: 1、如果是扩展java.lang.Thread类的线程,则直接new即可。
2、如果是实现了java.lang.Runnable接口的类,则用Thread的构造方法:
Thread(Runnable target)
Thread(Runnable target, String name)
Thread(ThreadGroup group, Runnable target)
Thread(ThreadGroup group, Runnable target, String name)
Thread(ThreadGroup group, Runnable target, String name, long stackSize)
所以A、D的实例化线程错误。
三、启动线程: 在线程的Thread对象上调用start()方法,而不是run()或者别的方法。
所以B的启动线程方法错误。
267、类之间存在以下几种常见的关系:
A、“USES-A”关系
B、“HAS-A”关系
C、“IS-A”关系
D、“INHERIT-A”关系
就像渣男泡妞一样:
刚开始,遇到了一个心动的女孩A,然后你就心里暗下决心:就她了(is A),我一定要追到她;
然后,就用尽各种办法追她,终于把她追到手了(has A);
追到手就use
268、我们在程序中经常使用“System.out.println()”来输出信息,语句中的System是包名,out是类名,println是方法名。
A、对
B、错
System是java.lang中的类,out为System中的一个静态成员,out是java.io.PrintStream类的对象,而println()是java.io.PrintStream类的方法,所有可以调用类.静态方法.println()方法。
269、Java的集合框架中重要的接口java.util.Collection定义了许多方法。选项中哪个方法是Collection接口所定义的
A、int size()
B、boolean containsAll(Collection c)
C、compareTo(Object obj)
D、boolean remove(Object obj)
C选项,compareTo是String类的方法,按字典顺序比较两个字符串大小,返回值是int,时常出现在一些类构造器中,如TreeMap.
Collection 接口常用的方法
- size():返回集合中元素的个数
- add(Object obj):向集合中添加一个元素
- addAll(Colletion coll):将形参coll包含的所有元素添加到当前集合中
- isEmpty():判断这个集合是否为空
- clear():清空集合元素
- contains(Object obj):判断集合中是否包含指定的obj元素
① 判断的依据:根据元素所在类的equals()方法进行判断
②明确:如果存入集合中的元素是自定义的类对象,要去:自定义类要重写equals()方法 - constainsAll(Collection coll):判断当前集合中是否包含coll的所有元素
- rentainAll(Collection coll):求当前集合与coll的共有集合,返回给当前集合
- remove(Object obj):删除集合中obj元素,若删除成功,返回ture否则
- removeAll(Collection coll):从当前集合中删除包含coll的元素
- equals(Object obj):判断集合中的所有元素 是否相同
- hashCode():返回集合的哈希值
- toArray(T[] a):将集合转化为数组
①如有参数,返回数组的运行时类型与指定数组的运行时类型相同。 - iterator():返回一个Iterator接口实现类的对象,进而实现集合的遍历。
- 数组转换为集合:Arrays.asList(数组)
270、下面哪些接口直接继承自Collection接口
A、List
B、Map
C、Set
D、Iterator
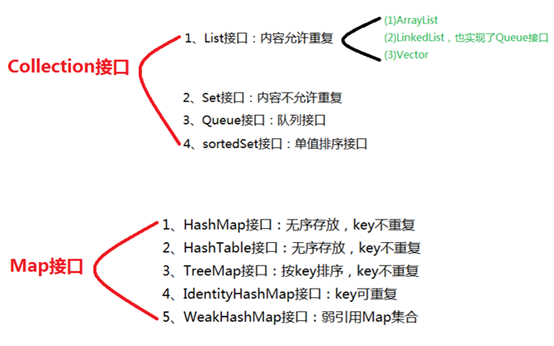
Iterator不继承接口
271、下面关于volatile的功能说法正确的是哪个
A、原子性
B、有序性
C、可见性
D、持久性
本题易错点是A选项,volatile关键字对任意单个volatile变量的的读写操作可以保证原子性,但类似于volatile++这种复合操作就无法保证原子性了。如果需要对这种复合操作保证原子性,最好用synchronized关键字。即synchronized保证三大性,原子性,有序性,可见性,volatile保证有序性,可见性,不能保证原子性。
B选项,为了实现volatile的内存语义,编译器在生成字节码时会在指令序列中插入内存屏障来禁止特定类型的处理器重排序,以此来保证有序性。
C选项,可见性是指当多个线程并发访问共享变量时,一个线程对共享变量的修改,其它线程能够立即看到。对于一个volatile变量的读,总是能看到对这个volatile变量最后的写入,保证了可见性。
D选项为干扰选项。
volatile到底做了什么:
-
禁止了指令重排
-
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量值,这个新值对其他线程是立即可见的
-
不保证原子性(线程不安全)
synchronized关键字和volatile关键字比较:
-
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。
-
多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
-
volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
-
volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。
272、以下哪种方式实现的单例是线程安全的
A、枚举
B、静态内部类
C、双检锁模式
D、饿汉式
一、单例模式的定义
定义: 确保一个类只有一个实例,并提供该实例的全局访问点。
这样做的好处是:有些实例,全局只需要一个就够了,使用单例模式就可以避免一个全局使用的类,频繁的创建与销毁,耗费系统资源。
二、单例模式的设计要素
- 一个私有构造函数 (确保只能单例类自己创建实例)
- 一个私有静态变量 (确保只有一个实例)
- 一个公有静态函数 (给使用者提供调用方法)
简单来说就是,单例类的构造方法不让其他人修改和使用;并且单例类自己只创建一个实例,这个实例,其他人也无法修改和直接使用;然后单例类提供一个调用方法,想用这个实例,只能调用。这样就确保了全局只创建了一次实例。
三、单例模式的6种实现及各实现的优缺点
(一)懒汉式(线程不安全)
public class Singleton {
private static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
}
说明: 先不创建实例,当第一次被调用时,再创建实例,所以被称为懒汉式。
优点: 延迟了实例化,如果不需要使用该类,就不会被实例化,节约了系统资源。
缺点: 线程不安全,多线程环境下,如果多个线程同时进入了 if (uniqueInstance == null) ,若此时还未实例化,也就是uniqueInstance == null,那么就会有多个线程执行 uniqueInstance = new Singleton(); ,就会实例化多个实例;
(二)饿汉式(线程安全)
public class Singleton {
private static Singleton uniqueInstance = new Singleton();
private Singleton() {
}
public static Singleton getUniqueInstance() {
return uniqueInstance;
}
}
说明: 先不管需不需要使用这个实例,直接先实例化好实例 (饿死鬼一样,所以称为饿汉式),然后当需要使用的时候,直接调方法就可以使用了。
优点: 提前实例化好了一个实例,避免了线程不安全问题的出现。
缺点: 直接实例化好了实例,不再延迟实例化;若系统没有使用这个实例,或者系统运行很久之后才需要使用这个实例,都会操作系统的资源浪费。
(三)懒汉式(线程安全)
public class Singleton {
private static Singleton uniqueInstance;
private static singleton() {
}
private static synchronized Singleton getUinqueInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
}
说明: 实现和 线程不安全的懒汉式 几乎一样,唯一不同的点是,在get方法上 加了一把 锁。如此一来,多个线程访问,每次只有拿到锁的的线程能够进入该方法,避免了多线程不安全问题的出现。
优点: 延迟实例化,节约了资源,并且是线程安全的。
缺点: 虽然解决了线程安全问题,但是性能降低了。因为,即使实例已经实例化了,既后续不会再出现线程安全问题了,但是锁还在,每次还是只能拿到锁的线程进入该方***使线程阻塞,等待时间过长。
(四)双重检查锁实现(线程安全)
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
说明: 双重检查数相当于是改进了 线程安全的懒汉式。线程安全的懒汉式 的缺点是性能降低了,造成的原因是因为即使实例已经实例化,依然每次都会有锁。而现在,我们将锁的位置变了,并且多加了一个检查。 也就是,先判断实例是否已经存在,若已经存在了,则不会执行判断方法内的有锁方法了。 而如果,还没有实例化的时候,多个线程进去了,也没有事,因为里面的方法有锁,只会让一个线程进入最内层方法并实例化实例。如此一来,最多最多,也就是第一次实例化的时候,会有线程阻塞的情况,后续便不会再有线程阻塞的问题。
为什么使用 volatile 关键字修饰了 uniqueInstance 实例变量 ?
uniqueInstance = new Singleton(); 这段代码执行时分为三步:
- 为 uniqueInstance 分配内存空间
- 初始化 uniqueInstance
- 将 uniqueInstance 指向分配的内存地址
正常的执行顺序当然是 1>2>3 ,但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1>3>2。
单线程环境时,指令重排并没有什么问题;多线程环境时,会导致有些线程可能会获取到还没初始化的实例。
例如:线程A 只执行了 1 和 3 ,此时线程B来调用 getUniqueInstance(),发现 uniqueInstance 不为空,便获取 uniqueInstance 实例,但是其实此时的 uniqueInstance 还没有初始化。
解决办法就是加一个 volatile 关键字修饰 uniqueInstance ,volatile 会禁止 JVM 的指令重排,就可以保证多线程环境下的安全运行。
优点: 延迟实例化,节约了资源;线程安全;并且相对于 线程安全的懒汉式,性能提高了。
缺点: volatile 关键字,对性能也有一些影响。
(五)静态内部类实现(线程安全)
public class Singleton {
private Singleton() {
}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getUniqueInstance() {
return SingletonHolder.INSTANCE;
}
}
说明: 首先,当外部类 Singleton 被加载时,静态内部类 SingletonHolder 并没有被加载进内存。当调用 getUniqueInstance() 方法时,会运行 return SingletonHolder.INSTANCE; ,触发了 SingletonHolder.INSTANCE ,此时静态内部类 SingletonHolder 才会被加载进内存,并且初始化 INSTANCE 实例,而且 JVM 会确保 INSTANCE 只被实例化一次。
优点: 延迟实例化,节约了资源;且线程安全;性能也提高了。
(六)枚举类实现(线程安全)
public enum Singleton {
INSTANCE;
//添加自己需要的操作
public void doSomeThing() {
}
}
说明: 默认枚举实例的创建就是线程安全的,且在任何情况下都是单例。
优点: 写法简单,线程安全,天然防止反射和反序列化调用。
- 防止反序列化
**序列化:**把java对象转换为字节序列的过程;
反序列化: 通过这些字节序列在内存中新建java对象的过程;
说明: 反序列化 将一个单例实例对象写到磁盘再读回来,从而获得了一个新的实例。
我们要防止反序列化,避免得到多个实例。
枚举类天然防止反序列化。
其他单例模式 可以通过 重写 readResolve() 方法,从而防止反序列化,使实例唯一重写 readResolve() :
private Object readResolve() throws ObjectStreamException{
return singleton;
}
四、单例模式的应用场景
应用场景举例:
- 网站计数器。
- 应用程序的日志应用。
- Web项目中的配置对象的读取。
- 数据库连接池。
- 多线程池。
- …
使用场景总结:
- 频繁实例化然后又销毁的对象,使用单例模式可以提高性能。
- 经常使用的对象,但实例化时耗费时间或者资源多,如数据库连接池,使用单例模式,可以提高性能,降低资源损坏。
- 使用线程池之类的控制资源时,使用单例模式,可以方便资源之间的通信。
273、以下那些代码段能正确执行
A、public static void main(String args[]) {
byte a = 3;
byte b = 2;
b = a + b;
System.out.println(b);
}
B、public static void main(String args[]) {
byte a = 127;
byte b = 126;
b = a + b;
System.out.println(b);
}
C、public static void main(String args[]) {
byte a = 3;
byte b = 2;
a+=b;
System.out.println(b);
}
D、public static void main(String args[]) {
byte a = 127;
byte b = 127;
a+=b;
System.out.println(b);
}
byte类型的变量在做运算时被会转换为int类型的值,故A、B左为byte,右为int,会报错;
而C、D语句中用的是a+=b的语句,此语句会将被赋值的变量自动强制转化为相对应的类型。
274、以下关于对象序列化描述正确的是
A、使用FileOutputStream可以将对象进行传输
B、使用PrintWriter可以将对象进行传输
C、使用transient修饰的变量不会被序列化
D、对象序列化的所属类需要实现Serializable接口
CD:
使用ObjectOutputStream和ObjectInputStream可以将对象进行传输.
声明为static和transient类型的成员数据不能被串行化。因为static代表类的状态, transient代表对象的临时数据。



275、以下定义一维数组的语句中,正确的是
A、int a [10];
B、int a []=new [10];
C、int a []=new int [5]{1,2,3,4,5};
D、int a []={1,2,3,4,5};
Java一维数组有两种初始化方法
1、静态初始化
int array[] = new int[]{1,2,3,4,5}
或者
int array[] = {1,2,3,4,5}
需要注意的是,写成如下形式也是错误的
int array[] = new int[5]{1,2,3,4,5}
2、动态初始化
int array[] = new int[5];
array[0] = 1;
array[1] = 2;
array[2] = 3;
array[3] = 4;
array[4] = 5;
静态与动态初始化的区别就在于,前者是声明的时候就初始化,后者是先声明,再动态初始化。
276、以下哪个事件会导致线程销毁?
A、调用方法sleep()
B、调用方法wait()
C、start()方法的执行结束
D、run()方法的执行结束
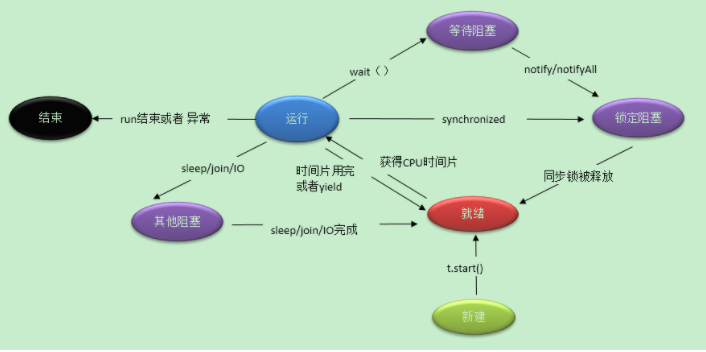
277、在运行时,由java解释器自动引入,而不用import语句引入的包是()。
A、java.lang
B、java.system
C、java.io
D、java.util
java.lang包是java语言的核心包,lang是language的缩写
java.lang包定义了一些基本的类型,包括Integer,String之类的,是java程序必备的包,有解释器自动引入,无需手动导入。
278、关于Java以下描述正确的有
A、Class类是Object类的超类
B、Object类是一个final类
C、String类是一个final类
D、Class类可以装载其它类
D.Class类中的forName()方法返回与带有给定字符串名的类或接口相关联的Class对象(装载其他类)
279、如下哪些是 java 中有效的关键字
A、native
B、NULL
C、false
D、this
true和false看起来像关键字,但严格来说,它们是boolean常量;null看起来也像关键字,但严格来说,它是null常量。 不是关键字的:true false null sizeof friendly 关键字都是小写的
280、下面有关java final的基本规则,描述错误的是
A、final修饰的类不能被继承
B、final修饰的成员变量只允许赋值一次,且只能在类方法赋值
C、final修饰的局部变量即为常量,只能赋值一次。
D、final修饰的方法不允许被子类覆盖
final修饰的成员变量为基本数据类型是,在赋值之后无法改变。当final修饰的成员变量为引用数据类型时,在赋值后其指向地址无法改变,但是对象内容还是可以改变的。
final修饰的成员变量在赋值时可以有三种方式。1、在声明时直接赋值。2、在构造器中赋值。3、在初始代码块中进行赋值。
281、instanceof运算符能够用来判断一个对象是否为:
A、一个类的实例
B、一个实现指定接口的类的实例
C、全部正确
D、一个子类的实例
instance是java的二元运算符,用来判断他左边的对象是否为右面类(接口,抽象类,父类)的实例
282、关于抽象类与最终类,下列说法错误的是
A、抽象类能被继承,最终类只能被实例化。
B、抽象类和最终类都可以被声明使用
C、抽象类中可以没有抽象方法,最终类中可以没有最终方法
D、抽象类和最终类被继承时,方法可以被子类覆盖
最终类就是被final修饰的类,最终方法就是被final修饰的方法。最终类不能被继承,最终方法不能被重写。















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









