







说到分布式缓存,我们不得不说到两个数据库memcache和redis,曾经我们使用缓存一般使用memcache,现在我们一般使用redis。那为什么我们从memcache迁移到redis呢?因为redis比memcache更加优秀。memcache支持的类型比较单一,redis支持多种类型。
| 数据库 | 支持数据类型 |
| memcache | 仅支持简单数据类型,比如string、int等,复杂数据类型需要转换成简单类型再存储(本人没用过,也不知道存啥类型)。 |
| redis | String(字符串)、List(列表)、set(无序集合)、zset(sorted set:有序集合)、hash(哈希)。 |
同时,redis也是一个单线程模型,处理业务比较方便。
那么,我们为什么要用缓存?
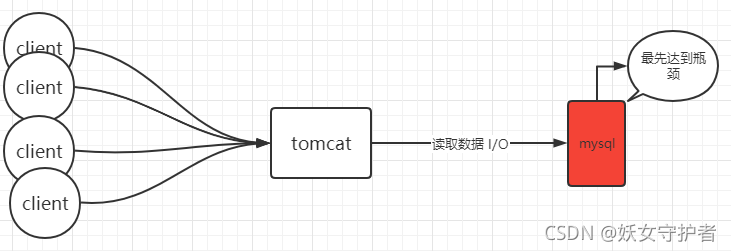
我们现在做的很多项目都是B/S架构,如下图。客户端发请求给Tomcat,Tomcat会开辟一个线程处理你的请求(Tomcat默认最大200线程),处理请求时,有可能向数据库中读写数据。

那如果访问量很大的时候,后端服务需要接受考验了。接受考验的两处:Tomcat,数据库。当并发量增加的时候,其实最先达到瓶颈的是数据库,当数据库达到瓶颈的时候,客户端的访问速率就会降低,系统响应时间变长。
这时候就要加缓存了,比如我们用redis做一个缓存。
加了缓存,如何去解决数据库的瓶颈问题呢?我们可以把经常查询的数据作为一个热点数据存到redis中,当Tomcat要查询这些数据的时候,先从redis中查询一下,如果redis中有就直接返回。这样redis就可以阻挡一部分接触mysql的请求,减轻mysql压力。
当然此时又存在几个问题,
如果数据库中的热点数据变化怎么办?
在热点数据变化的同时,需要去更新redis中的热点数据。
如果热点的数据很大怎么办?
如果热点数据很多,一台数据库存不了,可以使用多台数据库进行存储。
这就涉及到了redis的集群了,即分布式缓存。

redis集群常见的两种模式:主从模式和切片模式。
主从模式:
主从模式又称为主从副本模式,一般由一个master和一堆的slave构成,master是主节点,slave是从节点,master管理这堆的slave。客户端去读数据时,找的是slave,写数据的话,找的是master,master写完之后,会把数据同步给这一堆的slave,所以 无论是master还是slave,里面的数据都是一模一样的。

但这种情况很明显不能解决海量热点数据的问题,因为它的存储量是由单台redis存储量决定的!!!只要有一台达到了瓶颈,这个集群就算是达到瓶颈了。那么这时候就该切片模式上场了,那么什么是切片模式呢?
切片模式:
比如我们有大量的热点数据,我们的redis集群的每台服务器只存储一部分,那么我们的集群就能够存储大量的数据。那么如何才能做到均匀分布在每台redis上呢?

比如,我们可以使用这种切片规则。
由于redis中存储的数据都是以key、value存储的,我们可以计算一下key的hash值,上述是三个数据库,那我们用key的hash值%3,即hash(key)%3=[0,1,2],那这个值肯定是一个0~2的某一个整数,当等于0时,我们存第一个,等于1存第二个,等于2存第三个,这样我们就把大量的热点数据分开且均匀的存储了。
对应的查询时,先计算key的hash值,0——reids1,1——redis2,2——redis3,这样就找到对应值了。
---------------------------------------------------------------------BUT--------------------------------------------------------------
聪明的你可能发现这个切片规则有个弊端,非常不利于集群的扩展。
如果我们要增加一台redis数据库,那么我们需要从redis123三台数据库中取数据,存到redis4中,算法也要对应的改变,造成大量的网络I/O。同时,redis123之间也会相互数据迁移。删除也类似,由于redis是单线程模型,当redis发生大量的网络I/O时,就不能够对外提供存储查询的服务,导致系统缓慢。

不过别怕,上有政策下有对策,告诉你一个神器:一致性hash算法!
观察下图:我们现在有一个环,叫hash环,假设它有2^32个点,我们准备了三台redis数据库每台机器都会有各自的ip+编号,现在基于每台服务器的ip和编号进行一个hash取余:hash(ip+编号)%2^32=[0,2^32-1],取余后产生的值一定在0~2^32-1之间。假如我们的三台服务器映射位置如下图,热点数据也进行取余hash(key)%2^32=num,那么num一定也在hash环的某一个点位,num的存储位置则按顺时针的方向存储在最近的数据库中。

当我们进行添加一个数据库redis4的时候,比如我们计算的hash值取余后,在redis2和redis3中间,则只需要把redis2到redis4之间的,原本存储在redis3里面的值迁移到redis4中即可,其他不变。删除不多说了,一样的。

是不是感觉问题完美解决了?No!
这样还可能会出现一个问题,数据倾斜问题。插播一个概念:【数据倾斜】:
*存储框架:大部分数据存储在少量服务器
*计算框架:大部分数据由少量服务器计算
如果redis服务器的hash值最后分布的很近,就会导致大量数据存储在一台redis上,比如这种,这样大多数数据就会存储在redis1当中,即数据倾斜。

那如何解决数据倾斜问题?
其实,我们可以多虚拟几个redis节点,比如每一台redis服务器虚拟10个点,那么就会产生30个节点分布在hash环上,那么产生数据倾斜的概率就会小一些。现实中,可以虚拟n个,n根据实际情况而定,这样就避免了数据倾斜问题。数据迁移的时候也很方便,自行思考。
回归到最开始的话题。
如果我们现在的client被黑客攻击了,攻击者发送id=-1的数据请求我们的系统,mysql中根本没有id=-1的数据,redis缓存中更没有这种数据,redis不能阻挡一部分数据,就会产生缓存穿透,缓存穿透不可怕,可怕的是大量的缓存穿透,严重可能导致mysql宕机,那如何解决呢?
我们可以在访问mysql前增加一个过滤器,过滤器中存储mysql数据库中的所有id,但随着mysql数据库中的数据逐渐增多,这个过滤器的所占内存会越来越大,这时候我们就要用到布隆算法了。 
布隆算法:
假设有一个长度为10的二进制码数组,布隆算法就是用来标记mysql里的id。
比如我们要标记id = 100的一条记录,我们首先把这个id = 100的数据传递给hash函数,返回的结果值永远是0-9之间。如果经过hash算法最后得到的值为1的话,数组第二位将会置为1;如果这时我们在计算一个id = 155的一条记录,经hash算法后得到的值为6,那么数组第七位置为1;那么所有置为1的表示在mysql中存在数据。
这时我们又重新标记一个id为998的,他进过hash函数计算后,也可能是6,同样的,数组的第七位同时标记着id=225和id=998的两条记录。所以布隆算法是有一定错误率的。
这时候我们客户端分别发送两个请求分别为id=8856和id=3206的数据,经过hash函数计算后的值在对应位置找到如果为1,就去数据库里面查询,如果数据位为0,就直接返回。所以,布隆算法有个特性:如果布隆算法返回数据存在,那么数据可能存在;如果布隆算法返回数据不存在,那么数据一定不存在。
但上述的方法计算出来的过滤器,错误率相对来说还是比较大的,hash碰撞的概率还是很高的,这里的数组10位只是举个例子,实际二级制数据要比这个大得多,这样hash碰撞的几率就会减少很多。

另外,除了增加数组长度减少hash碰撞外,我们还可以增加hash函数的个数。
看下图,我们将id = 100的数据分别传给三个hash函数得到三个不同的计算结果,并分别将这些结果置为1,如果我们客户端传递一个数据时,也分别对三个hash函数进行计算 拿到得到的结果进行比对,这样hash碰撞率就会大大减少。

这里不用担心数组长度太大占用空间太多的问题,感兴趣的可以去看一下bit字节与占用空间的对比。
原文链接:https://blog.csdn.net/m0_38084879/article/details/121101359














 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









