







文本分类文献总结
1. Recurrent Convolutional Neural Networks for Text Classification
将rnn和cnn 结合,来表示文本特征。由于使用cnn需要调节filter_size参数,使cnn使用起来相当繁琐,且cnn对与较长序列的表示效果欠佳。所以此方法,先使用双向rnn和词本身词向量来表示一个词,之后再接卷积层和pooling层。
方法模型:
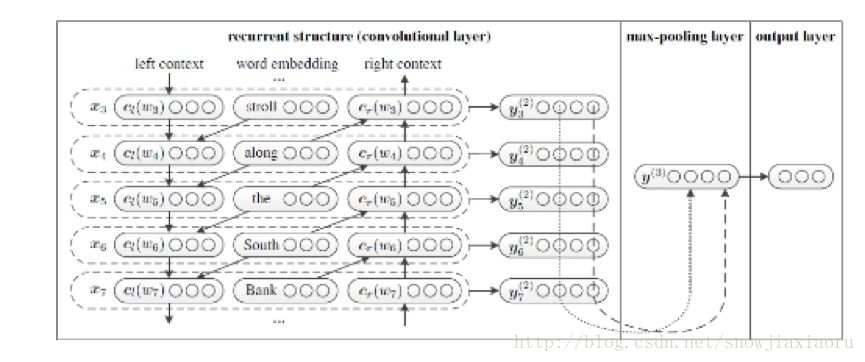
双向rnn:所有文本的第一个词的左端内容表示会共享一个参数,最后一个词的右端内容会共享一个参数,最终词会表示成[cl(wi);e(wi);cr(wi)]。其中左端文本内容表示是通过前向rnn训练得到,右端文本内容表示是通过后向rnn训练得到,中间部分e(wi),是词本身的词向量。
rnn输出的结果,接卷积层,卷积核的个数自己设定,卷积核的大小为1
pooling 层,采用max-pooling ,是基于element-wise ,所以对不同的文本长度最终会转换成固定长度
优点:通过双向RNN能够很好的学习到上下文信息,通过cnn能够很好的学习到keyword,是学习到的特征能够更好的表达文本。
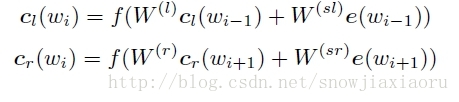
2. Hierarchical Attention Networks for Document Classification
采用rnn+attention 机制对文档进行分类
文档是由句子构成的,句子是由词构成的,由于每个词对句子的贡献程度不同,每个句子对文档最终类别贡献程度不同,故此文章对词和句子都采用了attention机制,从而可以让模型能够增大对个别句子或词的关注。
举例说明:

上文是一段评论,可以看出,文章中第一句和第三句是关键,在第一句和第三句中,delicious和amazing是句子的关键。
方法模型
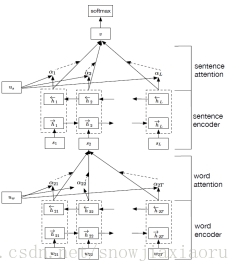
word encoding
经过双向GRU,将双向隐层的输出拼接作为word encoding向量
word attention
(1)对每个词计算其对句子的影响程度,具体如下:
(2)对GRU隐层的数据在接一层MLP,输出对隐层的表示。
(3)用(2)vi的输出计算词的重要性程度,通过计算词的表示向量与表示句子的向量的相似性程度得到。
(4)句子向量,由所有词的相似性程度权重和(1)的输出组成。
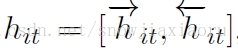
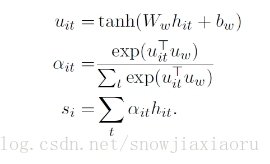
- sentence encoding 和 sentence attention 与word相同,只是输入为(4)的结果















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









