







负载均衡,英⽂名称为Load Balance,指由多台服务器以对称的⽅式组成⼀个服务器集合,每台服务器都具有等价的地位,都可以单独对外提供服务⽽⽆须其他服务器的辅助。通过某种负载分担技术,将外部发送来的请求均匀分配到对称结构中的某⼀台服务器上,⽽接收到请求的服务器独⽴地回应客户的请求。
负载均衡能够平均分配客户请求到服务器阵列,借此提供快速获取重要数据,解决⼤量并发访问服务问题,这种集群技术可以⽤最少的投资获得接近于⼤型主机的性能。
简单比喻一下,来帮助你更好的理解:有一条道路连接了不同的城区和重要的目的地,每天都会有大量的车辆在上面行驶。如果这条道路只有单车道,所有的车辆都只能依次排队等待通过,这将导致严重的交通堵塞和拥堵。车辆无法流畅地行驶,导致通行效率低下,每个车辆的行驶时间都会增加。为了解决这个问题,你决定对道路进行扩展,并增加多个车道。这样,车辆就可以分散在不同的车道上行驶,相互之间不会相互阻塞。交通流量得到了平衡分配,车辆可以更快速地到达目的地,整个道路的通行效率也得到了提高。 在这个比喻中,道路就是整个系统的基础设施,车辆代表着请求,车道则类似于后端服务器。
通过引入负载均衡,将请求均匀地分发到不同的服务器上,就像道路上的车辆分散到多个车道上一样,可以提高整体系统的效率和可靠性。 负载均衡分为软件负载均衡和硬件负载均衡 软件负载均衡 在软件负载均衡中,有一个专门的软件组件或应用程序充当负载均衡器(Load Balancer)。负载均衡器作为中间层位于客户端和后端服务器之间,接收来自客户端的请求,并根据一定的策略将请求分发给后端服务器。常⻅的负载均衡软件有Nginx、LVS、HAProxy)
硬件负载均衡
硬件负载均衡是一种通过专用硬件设备实现的负载均衡技术,用于将请求均匀地分发给后端服务器,以实现高可用性、提高性能和资源利用率。在硬件负载均衡中,有一种专门的硬件设备称为负载均衡器(Load Balancer),它被放置在网络架构中的关键位置。负载均衡器充当中间层,接收来自客户端的请求,并根据一定的算法和策略将请求分发给后端服务器。
负载均衡器的硬件设备通常具备高性能和可靠性,以应对大规模流量和请求的处理需求。它们经常拥有多个网络接口和专用的负载均衡算法,可以进行智能的请求分发。
常⻅的负载均衡硬件有Array、F5
那么硬件与软件负载均衡到底有什么样的差异呢?
- 实现方式:硬件负载均衡是通过专门的硬件设备来实现负载均衡功能。这些设备通常是高性能、专用的硬件设备,具有专门的负载均衡算法和功能。而软件负载均衡是通过软件实现的,运行在通用的服务器上。
- 性能和扩展性:由于硬件负载均衡设备使用专门的硬件资源,通常具有更高的性能和处理能力,能够处理大量的并发请求。它们也可以通过水平扩展来提供更高的扩展性,即添加更多的硬件设备来处理更大规模的请求负载。软件负载均衡在性能和扩展性方面可能受限于所运行的服务器硬件和软件环境。
- 系统依赖性:硬件负载均衡依赖于专门的硬件设备,需要额外的硬件投资和设备管理。软件负载均衡则依赖于运行在通用服务器上的软件组件,通常更容易部署和管理。软件负载均衡可以运行在虚拟化环境中,而硬件负载均衡通常不支持虚拟化。
- 高可用性和冗余:硬件负载均衡设备通常具有冗余和故障转移机制,以确保即使出现设备故障,负载均衡功能仍能正常工作,保证系统的高可用性。软件负载均衡可以通过部署多个负载均衡软件实例来实现高可用性,但需要额外的配置和管理。
选择硬件负载均衡还是软件负载均衡取决于具体的需求和环境。硬件负载均衡适用于大规模和高要求的系统环境,提供更高的性能、可扩展性和高可用性。软件负载均衡更适合中小型系统或虚拟化环境,具有更灵活的部署和管理方式。
负载均衡算法 随机算法-RandomLoadBalance 如果让你从一堆机器中挑选一个,你会怎么选呢? 没错,瞎选嘛!这就是随机算法的精髓。
import java.util.List;
import java.util.Random;
public class RandomLoadBalancer {
private List<String> nodes; // 存储节点的列表
public RandomLoadBalancer(List<String> nodes) {
this.nodes = nodes;
}
public String selectNode() {
Random random = new Random();
int index = random.nextInt(nodes.size()); // 随机生成一个索引值
return nodes.get(index); // 返回选中的节点
}
// 示例用法
public static void main(String[] args) {
List<String> nodes = List.of("A", "B", "C"); // 示例节点列表
RandomLoadBalancer loadBalancer = new RandomLoadBalancer(nodes);
// 模拟请求分发
for (int i = 0; i < 10; i++) {
String selectedNode = loadBalancer.selectNode();
System.out.println("Request " + (i + 1) + " dispatched to node " + selectedNode);
}
}
}这种算法有什么好处呢?
简单方便,在调用量比较大的情况下,使调⽤请求进⾏“均匀”分配(调用量少就不一定了)
权重随机算法
⾯的随机算法适⽤于每天机器的性能差不多的时候,实际上,⽣产中可能某些机器的性能更⾼⼀点,它可以处理更多的请求(正所谓能者多劳嘛),所以,我们可以对每台服务器设置⼀个权重。
我们可以如何实现这个权重呢?
首先来说一个最简单的思路,我们把每个服务器按它所对应的服务器进⾏复制,再随机,就实现了算法啦。比如由服务器A,B,权重值为1,2,复制后,我们得到【A,B,B】,然后在这个列表中进行随机就行啦
但这种实现⽅法在遇到权重之和特别⼤的时候就会⽐较消耗内存,因为需要对ip地址进⾏复制,权重之和越⼤那么上⽂中的ips就需要越多的内存。那么我来介绍第二种思路:
假设我们有⼀组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在⼀维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区 间属于服务器 C。接下来通过随机数⽣成器⽣成⼀个范围在 [0, 10) 之间的随机数,然后计算这个随机数 会落到哪个区间上。这样也是可行的。
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class LoadBalancer {
private List<Server> servers;
private List<Integer> weights;
private Random random;
public LoadBalancer() {
servers = new ArrayList<>();
weights = new ArrayList<>();
random = new Random();
}
public void addServer(Server server, int weight) {
servers.add(server);
weights.add(weight);
}
public Server getServer() {
int totalWeight = 0;
for (int weight : weights) {
totalWeight += weight;
}
int randomWeight = random.nextInt(totalWeight) + 1;
int cumulativeWeight = 0;
int index = 0;
for (int i = 0; i < servers.size(); i++) {
cumulativeWeight += weights.get(i);
if (randomWeight <= cumulativeWeight) {
index = i;
break;
}
}
return servers.get(index);
}
public static void main(String[] args) {
LoadBalancer loadBalancer = new LoadBalancer();
// 添加服务器和权重
loadBalancer.addServer(new Server("Server1"), 3);
loadBalancer.addServer(new Server("Server2"), 2);
loadBalancer.addServer(new Server("Server3"), 1);
// 模拟请求分发
for (int i = 0; i < 10; i++) {
Server server = loadBalancer.getServer();
System.out.println("Request " + (i + 1) + " sent to " + server.getName());
}
}
}
class Server {
private String name;
public Server(String name) {
this.name = name;
}
public String getName() {
return name;
}
}轮询算法-RoundRobinLoadBalance
顾名思义,按照顺序调用即可,如果有机器A,B,我们就按照A-B-A-B这样顺序调用。
当然,如果加上权重,思路和我们上面所说的权重随机算法类似,大家自行扩展
平滑加权轮询
但轮询算法有⼀个缺点:⼀台服务器的权重特别⼤的时候,他需要连续的的处理请求,但是实际上我们想达到的效果是,假设我们有三台服务器 servers = [A, B, C],对应的权重为 weights = [5, 1, 1] , 总权重为7,那么上述这 个算法的结果是:AAAAABC,那么如果能够是这么⼀个结果呢:AABACAA,把B和C平均插⼊到5个A中 间,这样是⽐较均衡的了。
所以我们有了平滑加权轮询算法
思路就是:每个服务器对应两个权重,分别为 weight 和 currentWeight。其中 weight 是固定的, currentWeight 会动态调整,初始值为0。当有新的请求进来时,遍历服务器列表,让它的 currentWeight 加上⾃身权重。遍历完成后,找到最⼤的 currentWeight,并将其减去权重总和,然后返 回相应的服务器即可。

如果你还是晕头转向,我做一个比喻:可以将每个服务器想象成一辆车,车的性能想象为权重值,三辆车公共一个油箱,数字越大性能越高,平滑加权轮询算法的实现思路就好比在一条公路上,这些车按照各自的载重能力在轮询行驶。初始状态下,每辆车的位置(当前权重)都是相同的,都在起点。每次有请求到来时,我们选择当前位置最远的一辆车来处理请求,为了能让所有车都公平被选择,每当有一辆车被选中后,它都降低油门,然后其它几辆车就猛踩油门,因为车性能高低差异,所以踩一脚油门跑的距离也不一样,下一次就再选择一个最远的车,就这种周而复始。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
public class SmoothWeightedRoundRobin {
private List<Server> servers;
private List<Integer> weights;
private List<Integer> currentWeights;
private AtomicInteger currentIndex;
public SmoothWeightedRoundRobin() {
servers = new ArrayList<>();
weights = new ArrayList<>();
currentWeights = new ArrayList<>();
currentIndex = new AtomicInteger(0);
}
public void addServer(Server server, int weight) {
servers.add(server);
weights.add(weight);
currentWeights.add(weight);
}
public Server getNextServer() {
int totalWeight = 0;
for (int weight : weights) {
totalWeight += weight;
}
int maxWeight = 0;
int maxIndex = 0;
for (int i = 0; i < currentWeights.size(); i++) {
int currentWeight = currentWeights.get(i);
if (currentWeight > maxWeight) {
maxWeight = currentWeight;
maxIndex = i;
}
}
int nextIndex = (maxIndex + 1) % servers.size();
int currentWeight = currentWeights.get(maxIndex);
int weight = weights.get(maxIndex);
if (weight > 0) {
currentWeights.set(maxIndex, currentWeight - totalWeight + weight);
}
currentIndex.set(nextIndex);
return servers.get(maxIndex);
}
public static void main(String[] args) {
SmoothWeightedRoundRobin loadBalancer = new SmoothWeightedRoundRobin();
// 添加服务器和权重
loadBalancer.addServer(new Server("Server1"), 5);
loadBalancer.addServer(new Server("Server2"), 3);
loadBalancer.addServer(new Server("Server3"), 2);
// 模拟请求分发
for (int i = 0; i < 10; i++) {
Server server = loadBalancer.getNextServer();
System.out.println("Request " + (i + 1) + " sent to " + server.getName());
}
}
}
class Server {
private String name;
public Server(String name) {
this.name = name;
}
public String getName() {
return name;
}
}⼀致性哈希算法-ConsistentHashLoadBalance
服务器集群接收到⼀次请求调⽤时,可以根据根据请求的信息,⽐如客户端的ip地址,或请求路径与请求参数等信息进⾏哈希,可以得出⼀个哈希值,特点是对于相同的ip地址,或请求路径和请求参数哈希出来 的值是⼀样的,只要能再增加⼀个算法,能够把这个哈希值映射成⼀个服务端ip地址,就可以使相同的请 求(相同的ip地址,或请求路径和请求参数)落到同⼀服务器上。 因为客户端发起的请求情况是⽆穷⽆尽的(客户端地址不同,请求参数不同等等),所以对于的哈希值也 是⽆穷⼤的,所以我们不可能把所有的哈希值都进⾏映射到服务端ip上,所以这⾥需要⽤到哈希环
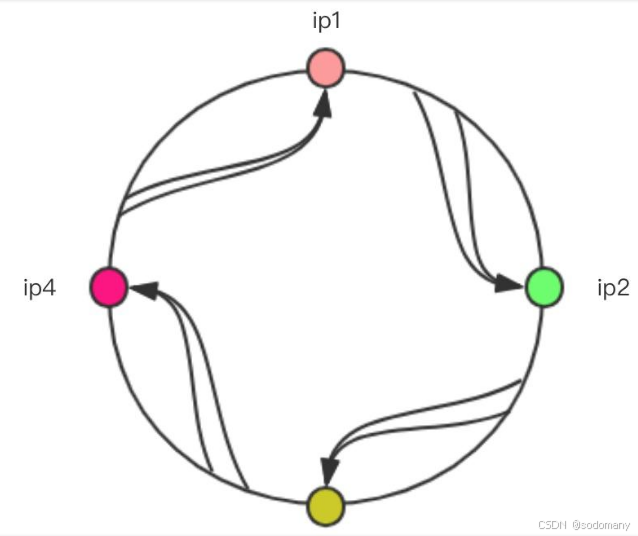
如果出现ip4服务器不存在,那就是这样了:
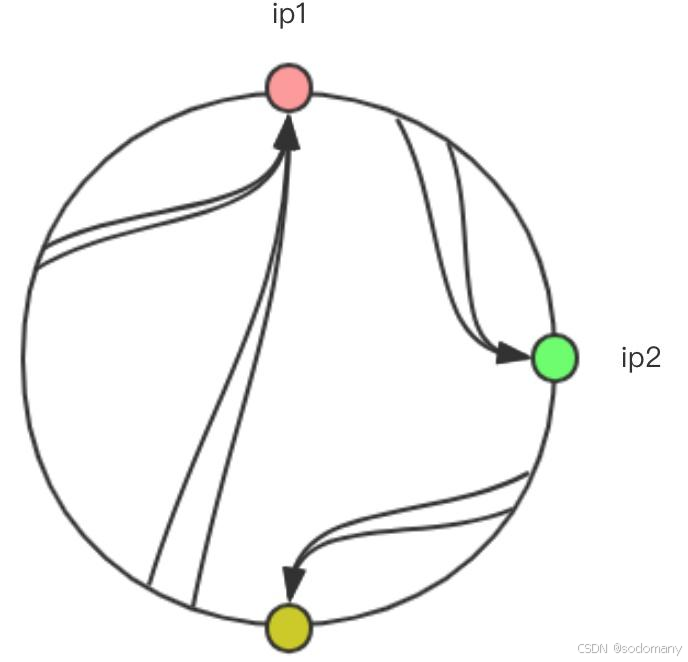
ip3和ip1直接的范围是⽐较⼤的,会有更多的请求落在ip1上,这是不“公平的”,解决这个问题需要加⼊虚拟节点
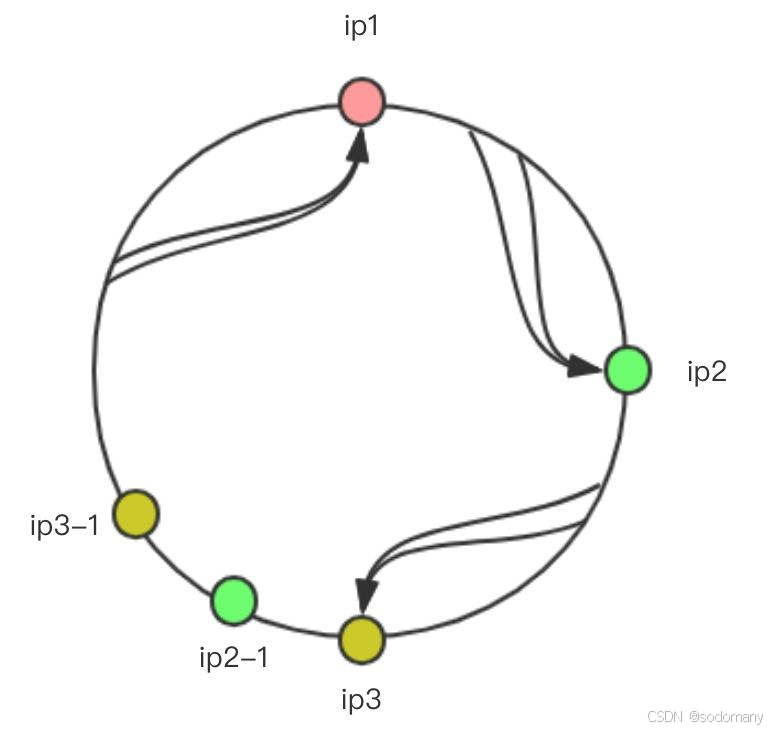
import java.util.*;
public class ConsistentHashing {
private final int numberOfReplicas; // 副本数
private final TreeMap<Integer, String> circle; // 哈希环
private final List<String> nodes; // 实际节点列表
public ConsistentHashing(int numberOfReplicas, List<String> nodes) {
this.numberOfReplicas = numberOfReplicas;
this.circle = new TreeMap<>();
this.nodes = new ArrayList<>();
for (String node : nodes) {
addNode(node);
}
}
// 添加节点
public void addNode(String node) {
nodes.add(node);
for (int i = 0; i < numberOfReplicas; i++) {
String virtualNode = node + "_" + i;
int hash = getHash(virtualNode);
circle.put(hash, node);
}
}
// 移除节点
public void removeNode(String node) {
nodes.remove(node);
for (int i = 0; i < numberOfReplicas; i++) {
String virtualNode = node + "_" + i;
int hash = getHash(virtualNode);
circle.remove(hash);
}
}
// 获取对应节点
public String getNode(String key) {
if (circle.isEmpty()) {
return null;
}
int hash = getHash(key);
Map.Entry<Integer, String> entry = circle.ceilingEntry(hash);
if (entry == null) {
entry = circle.firstEntry();
}
return entry.getValue();
}
// 计算哈希值
private int getHash(String key) {
// 这里使用简单的哈希算法,实际使用中可根据需求选择更合适的哈希算法
return Math.abs(key.hashCode());
}
public static void main(String[] args) {
// 创建一致性哈希对象,副本数为3
ConsistentHashing consistentHashing = new ConsistentHashing(3, Arrays.asList("Node1", "Node2", "Node3"));
// 添加新节点
consistentHashing.addNode("Node4");
// 根据键获取对应节点
String key1 = "Key1";
String node1 = consistentHashing.getNode(key1);
System.out.println("Key1 => " + node1);
// 移除节点
consistentHashing.removeNode("Node3");
// 根据键获取对应节点
String key2 = "Key2";
String node2 = consistentHashing.getNode(key2);
System.out.println("Key2 => " + node2);
}
}最⼩活跃数算法-LeastActiveLoadBalance
前⾯⼏种⽅法主要⽬标是使服务端分配到的调⽤次数尽量均衡,但是实际情况是这样吗?调⽤次数相同,服务器的负载就均衡吗?当然不是,这⾥还要考虑每次调⽤的时间,⽽最⼩活跃数算法则是解决这种问题的。
活跃调⽤数越⼩,表明该服务提供者效率越⾼,单位时间内可处理更多的请求。此时应优先将请求分配给该服务提供者。在具体实现中,每个服务提供者对应⼀个活跃数。初始情况下,所有服务提供者活跃数均 为0。每收到⼀个请求,活跃数加1,完成请求后则将活跃数减1。在服务运⾏⼀段时间后,性能好的服务提 供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请 求、这就是最⼩活跃数负载均衡算法的基本思想。除了最⼩活跃数,最⼩活跃数算法在实现上还引⼊了权 重值。所以准确的来说,最⼩活跃数算法是基于加权最⼩活跃数算法实现的。举个例⼦说明⼀下,在⼀个 服务提供者集群中,有两个性能优异的服务提供者。某⼀时刻它们的活跃数相同,则会根据它们的权重去 分配请求,权重越⼤,获取到新请求的概率就越⼤。如果两个服务提供者权重相同,此时随机选择⼀个即可。
import java.util.*;
public class LeastActiveAlgorithm {
private final Map<String, Integer> activeCounts; // 活跃数记录
private final List<String> servers; // 服务器列表
public LeastActiveAlgorithm(List<String> servers) {
this.servers = servers;
this.activeCounts = new HashMap<>();
for (String server : servers) {
activeCounts.put(server, 0);
}
}
// 选择最小活跃数的服务器
public String selectServer() {
String selectedServer = null;
int minActiveCount = Integer.MAX_VALUE;
for (String server : servers) {
int activeCount = activeCounts.get(server);
if (activeCount < minActiveCount) {
selectedServer = server;
minActiveCount = activeCount;
}
}
// 增加选择的服务器的活跃数
if (selectedServer != null) {
activeCounts.put(selectedServer, activeCounts.get(selectedServer) + 1);
}
return selectedServer;
}
// 更新服务器的活跃数
public void updateActiveCount(String server, int activeCount) {
if (activeCounts.containsKey(server)) {
activeCounts.put(server, activeCount);
}
}
public static void main(String[] args) {
// 创建最小活跃数算法对象
List<String> servers = Arrays.asList("Server1", "Server2", "Server3");
LeastActiveAlgorithm leastActive = new LeastActiveAlgorithm(servers);
// 模拟请求处理
for (int i = 0; i < 10; i++) {
// 选择服务器
String selectedServer = leastActive.selectServer();
System.out.println("Selected server: " + selectedServer);
// 模拟处理请求
// ...
// 更新服务器的活跃数
int activeCount = i % 3 + 1; // 模拟不同的活跃数
leastActive.updateActiveCount(selectedServer, activeCount);
}
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









