






操作系统 :CentOS 7.6_x64
Python版本:3.9.12
MySQL版本:5.7.38
日常开发过程中,会遇到mysql数据表的备份需求,需要针对单独的数据表进行备份并定时清理数据。
今天记录下python3如何使用pandas进行mysql数据表的备份,我将从以下几个方面进行展开:
-
数据表备份逻辑描述
-
使用的相关接口及文档
-
以FreeSWITCH的cdr表为例进行示例
-
提供示例代码及运行效果视频
一、数据表表备份逻辑
大致流程如下:
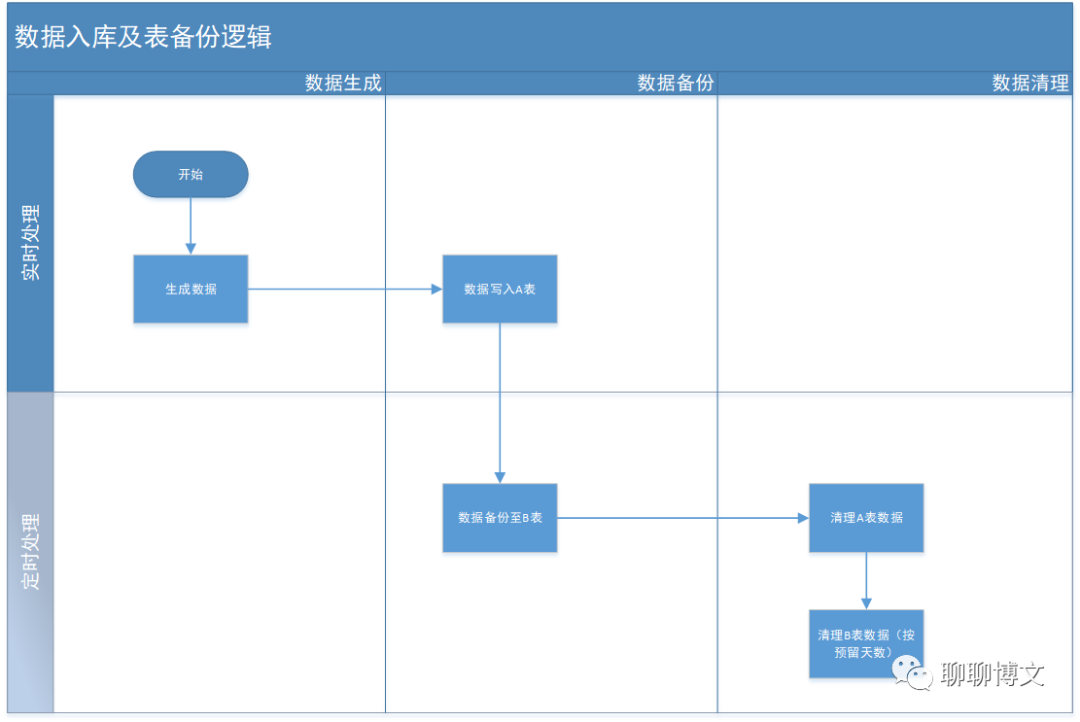
备份逻辑是“定时处理”部分的功能。
业务表A:
-
定义最大预留天数;
-
定义最大预留条数;
达到最大预留天数后,按时间(6小时为跨度)来删除,直到满足最大预留条数的要求。
备份表B:
-
预留时间可以hard code为2年;
-
2小时一检查,当前时间为设定时间(2、3、4、5、6)时,才执行备份操作;
数据搬迁时需要批量提交,以提高性能。
二、相关接口及文档
pandas版本:2.1.4
sqlalchemy 版本:1.4.39
pymysql 版本:1.0.2
CentOS7环境源码安装python3.9可参考如下文章:
https://www.cnblogs.com/MikeZhang/p/centos7-install-py39-20220704.html
1、使用pandas库的read_sql_query进行数据读取,可参考如下文档:
pandas.read_sql_query — pandas 2.1.4 documentation
2、pymysql是一个纯python实现的mysql操作库,安装及使用起来比较方便,且可跨平台使用。
文档地址:PyMySQL documentation — PyMySQL 0.7.2 documentation
3、SQLAlchemy是一个功能强大的Python ORM 工具包,借助该工具可更便捷的实现数据备份。
官方网址: SQLAlchemy - The Database Toolkit for Python
三、以FreeSWITCH的cdr为例进行示例
FreeSWITCH版本 :1.10.9
1、FreeSWITCH配置CDR
fs模块: mod_odbc_cdr
默认配置: conf/autoload_configs/odbc_cdr.conf.xml
如果没有该模块及配置文件,需要在编译时安装该模块,并将源码里面的配置文件复制到conf/autoload_configs目录,源码里面的配置文件路径如下:
freeswitch-1.10.9.-release/src/mod/event_handlers/mod_odbc_cdr/conf/autoload_configs/odbc_cdr.conf.xml
FreeSWICH通过ODBC方式支持MySQL可参考这篇文章的第二部分:
https://www.cnblogs.com/MikeZhang/p/dockerFS20230716.html
/etc/odbc.ini 配置示例:
[fsdb] Description=MySQL freeswitch database Driver=MySQL SERVER =192.168.137.1 PORT =3306 USER=root PASSWORD=123456 DATABASE = fsdb32 OPTION =67108864 CHARSET = UTF8
odbc_cdr.conf.xml配置示例(可根据情况调整所需字段):
<configuration name="odbc_cdr.conf" description="ODBC CDR Configuration">
<settings>
<!-- <param name="odbc-dsn" value="database:username:password"/> -->
<param name="odbc-dsn" value="fsdb:root:123456"/>
<!-- global value can be "a-leg", "b-leg", "both" (default is "both") -->
<param name="log-leg" value="both"/>
<!-- value can be "always", "never", "on-db-fail" -->
<param name="write-csv" value="on-db-fail"/>
<!-- location to store csv copy of CDR -->
<param name="csv-path" value="/usr/local/freeswitch/log/odbc_cdr"/>
<!-- if "csv-path-on-fail" is set, failed INSERTs will be placed here as CSV files otherwise they will be placed in "csv-path" -->
<param name="csv-path-on-fail" value="/usr/local/freeswitch/log/odbc_cdr/failed"/>
<!-- dump SQL statement after leg ends -->
<param name="debug-sql" value="true"/>
</settings>
<tables>
<table name="call_detail">
<field name="uuid" chan-var-name="uuid"/>
<field name="call_uuid" chan-var-name="call_uuid"/>
<field name="caller_number" chan-var-name="caller_id_number"/>
<field name="callee_number" chan-var-name="destination_number"/>
<field name="start_time" chan-var-name="start_stamp"/>
<field name="answer_time" chan-var-name="answer_stamp"/>
<field name="hangup_time" chan-var-name="end_stamp"/>
<field name="billsec" chan-var-name="billsec"/>
<field name="hangup_cause" chan-var-name="hangup_cause"/>
</table>
</tables>
</configuration>
需要创建对应的数据表,建表语句如下:
CREATE TABLE `call_detail` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`call_uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`caller_number` VARCHAR(20) NOT NULL DEFAULT '0',
`callee_number` VARCHAR(50) NOT NULL DEFAULT '0',
`start_time` DATETIME NULL DEFAULT NULL,
`answer_time` DATETIME NULL DEFAULT NULL,
`hangup_time` DATETIME NULL DEFAULT NULL,
`billsec` INT(11) NOT NULL DEFAULT '0',
`hangup_cause` VARCHAR(50) NOT NULL,
`timestamp` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
;
2、使用pandas进行数据备份
2.1 建立备份表
建表语句如下:
CREATE TABLE `call_detail_history` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`call_uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`caller_number` VARCHAR(20) NOT NULL DEFAULT '0',
`callee_number` VARCHAR(50) NOT NULL DEFAULT '0',
`start_time` DATETIME NULL DEFAULT NULL,
`answer_time` DATETIME NULL DEFAULT NULL,
`hangup_time` DATETIME NULL DEFAULT NULL,
`billsec` INT(11) NOT NULL DEFAULT '0',
`hangup_cause` VARCHAR(50) NOT NULL,
`timestamp` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
;
2.2 进行数据表备份
1) 编写备份脚本
文件名:dataBack.py
示例代码如下:
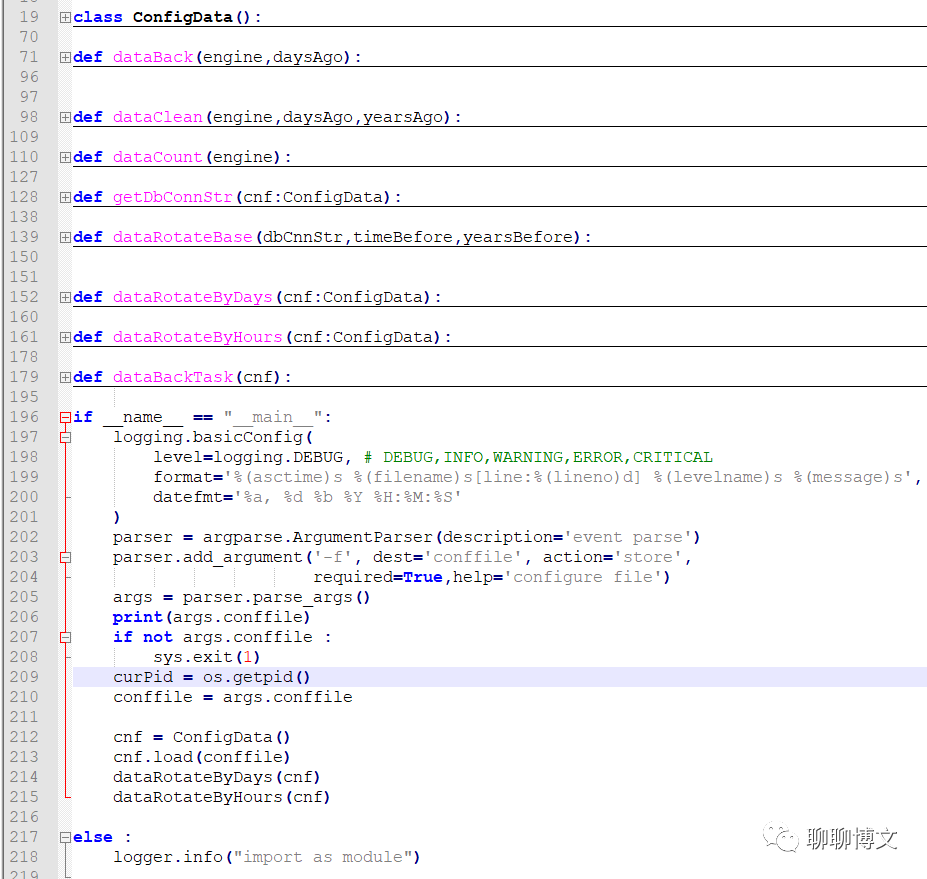
说明:
- ConfigData类
读取配置文件 - dataBack函数
以天为单位进行数据备份 - dataClean函数
执行数据清理功能(业务表和备份表) - dataCount函数
统计业务表里面的数据条目 - getDbConnStr函数
生成数据库连接字符串 - dataRotateBase函数
数据循环备份功能的具体实现,执行数据备份、数据清理操作。 - dataRotateByDays函数
按天循环备份 - dataRotateByHours函数
按小时循环备份 - dataBackTask函数
执行具体的备份任务
完整代码可从如下渠道获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 20231209 获取。
2)添加配置文件
文件名:default.xml
配置文件示例如下:
<config>
<cdrReserve>
<maxDays>15</maxDays>
<maxItems>100000</maxItems>
</cdrReserve>
<mysql>
<host>192.168.137.1</host>
<port>3306</port>
<user>root</user>
<password>123456</password>
<dbname>fsdb32</dbname>
</mysql>
</config>
说明:
cdrReserve/maxDays : 最大预留天数
cdrReserve/maxItems : 最大预留条数
mysql : mysql连接参数
3)编写启动脚本
文件名称:start.sh
示例如下:
#! /bin/bash pydir=/root/py39env export CFLAGS="-I$pydir/include" export LDFLAGS="-L$pydir/lib" export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$pydir/lib $pydir/bin/python3.9 dataBack.py -f default.xml
说明:
这里使用的是自定义python环境,python版本是3.9.12。
CentOS7环境源码安装python3.9可参考如下文章:
https://www.cnblogs.com/MikeZhang/p/centos7-install-py39-20220704.html
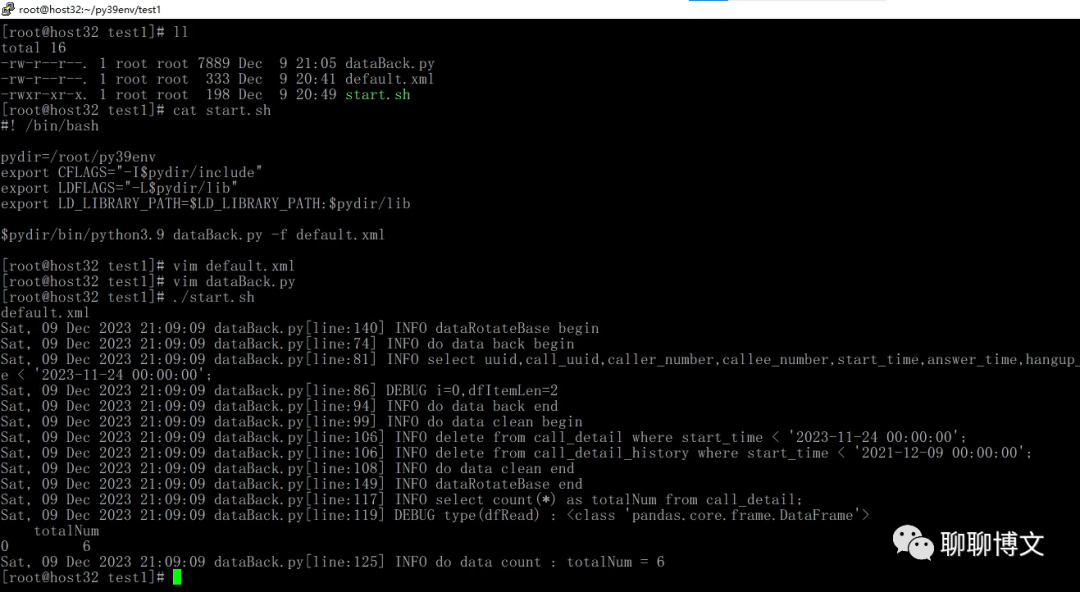
四、运行效果
运行效果如下:
















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











