







一、引言
上篇博客主要介绍了,IK分词器的安装和使用,这篇章我们来谈谈如何构建定制的词库,来满足复杂的业务需求。
二、本地自定义词库安装
-
首先我们在elasticsearch-6.3.1/plugins/ik/config 目录下创建一个自己的文件xxx.dic

-
在xxx.dic写入需要分词的词或短语,如下案例所示

-
vim elasticsearch-6.3.1/plugins/ik/config/IKAnalyzer.cfg.xml,配置本地词库

-
重启ES生效
-
测试效果

三、远程自定义词库安装
- github上远程词库安装建议

- 关键代码演示(使用http服务实现)
@RequestMapping(value="/customWords.html")
public void getCustomDict(HttpServletRequest request, HttpServletResponse response) {
try {
//依据实际业务逻辑,获取词汇组。每个词使用\n分隔。
String content = wordSplitService.getCustomWord();
// 返回数据
OutputStream out = response.getOutputStream();
// Head需要带上 Last-Modified ETag 属性
// 此处是输出的文件内容大小,不一定是这个样子,只要保证当文件发生变化时,Last-Modified和ETag也是变化的就OK ,比如也可以是文件的MD5
response.setHeader("Last-Modified", String.valueOf(content.length()));
response.setHeader("ETag", String.valueOf(content.length()));
response.setContentType("text/plain; charset=utf-8");
out.write(content.getBytes("utf-8"));
out.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
- vim elasticsearch-6.3.1/plugins/ik/config/IKAnalyzer.cfg.xml 配置远程地址

- 远程词库测试
- 远程词库添加“不讲武德”前测试效果

- 远程词库添加“不讲武德

- 查看是否添加成功
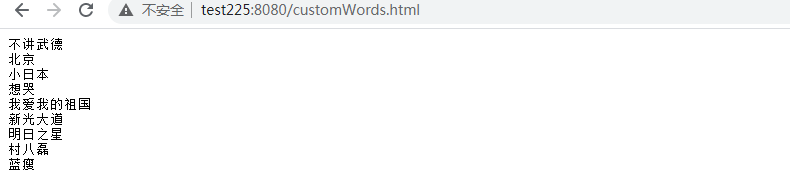
- 远程词库添加“不讲武德”后测试效果

四、注意事项
- 远程词库相比于本地词库的优势是,不需要重启ES
- 词库更新完成后,ES只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历史数据重新分词。需要执行:
POST weibo_test/_update_by_query?conflicts=proceed
验证:
首先创建一张索引表并指定IK分词器分词
PUT weibo_test
{
"settings": {
"number_of_replicas": 1
, "number_of_shards": 5
}
}
PUT weibo_test/_mapping/mytype
{
"mytype":{
"properties": {
"context":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
//put一条数据
PUT /weibo_test/mytype/1003
{
"name":"马保国",
"context":"红海行动"
}
添加完新词更新词库,发现已经将“海行”分词出来了

但是在表中查询发现匹配不上,原因是ES只会对新增的数据用新词分词。历史数据是不会重新分词的。

执行索引历史数据重新分词

再次查询可以匹配上
















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









