







on和where
在内连接中on和where作用相同,在外连接的时候,on这个子句的语义是“外连接驱动表的记录在被驱动表中找不到匹配记录时是否要加入到结果集中”。
连接分类
- 内连接: INNER JOIN
- 外连接:LEFT JOIN, RIGHT JOIN
连接的原理
嵌套循环连接
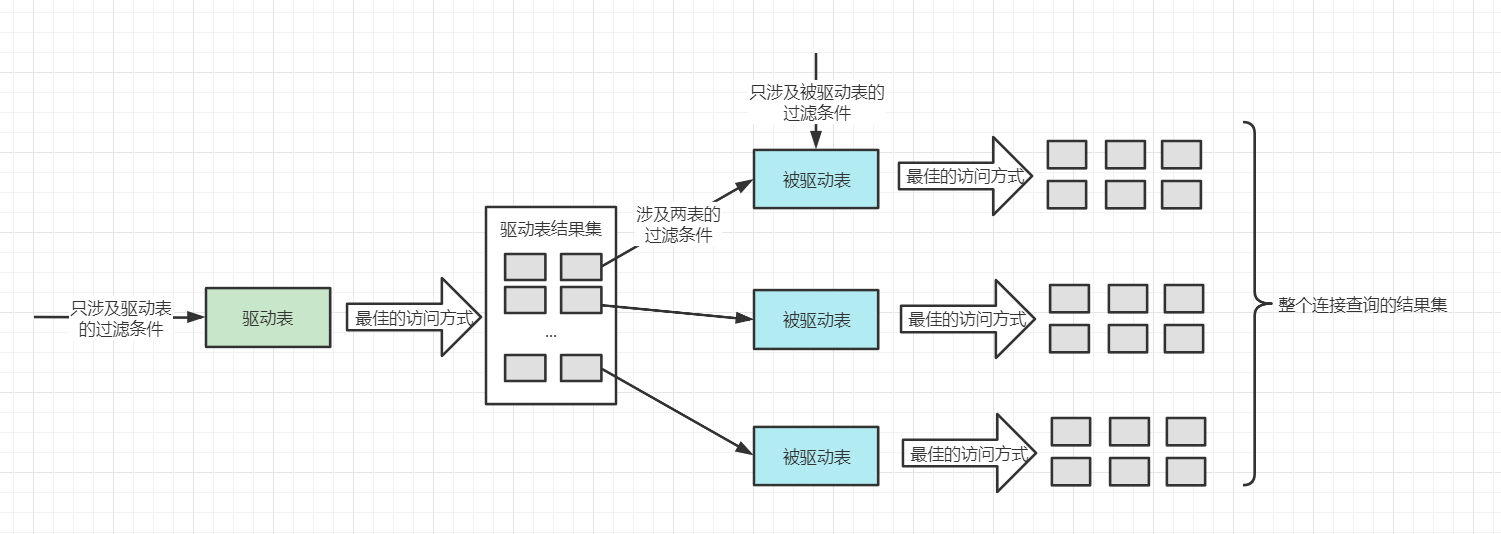
通过在驱动表中查询到匹配的记录,之后把驱动表的记录作为条件去被驱动表中查询数据。
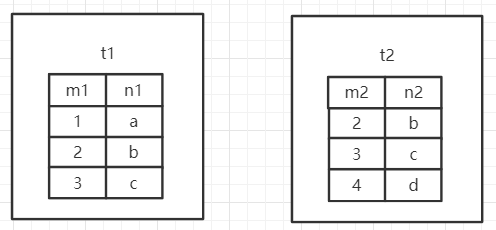
假如我们有以下两张表:
执行以下语句:
SELECT * FROM t1,t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
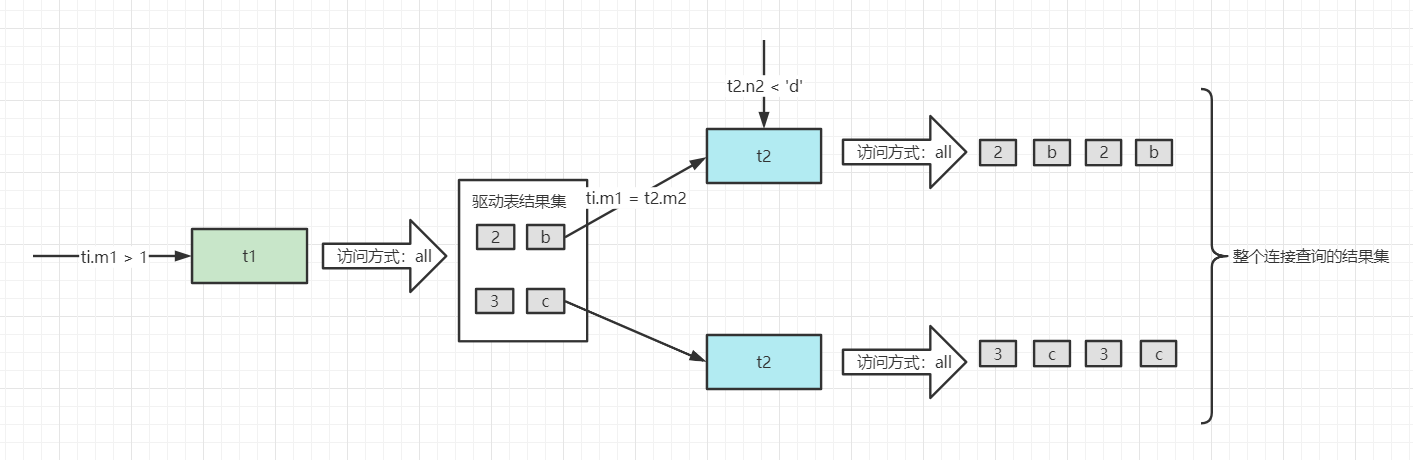
- 先执行SELECT * FROM t1 WEHRE t1.m1 > 1,拿到t1.m1 = 2和t1.m1=3的两条记录。
- 当t1.m1 = 2时,查询一遍t2,相当于SELECT * FROM t2 WEHRE t2.m2 = 2 AND t2.n2 < ‘d’;
- 当t1.m1 = 3时,再查询一遍t2,相当于SELECT * FROM t2 WEHRE t2.m2 = 3 AND t2.n2 < ‘d’;
- 结合2, 3步得到最终的结果集。
基于块的嵌套查询
我们可以看到连接查询的效率并不高,因此设计者提出了连接缓存区的概念,也就是join buffer,join buffer其实就是一块内存区域,默认大小256KB,最小可以设置为128KB。通过join buffer可以缓冲多条驱动表的结果集记录,这样每一条被驱动的记录就可以一次性和多个驱动表的记录在内存中做匹配,减少IO代价,提高性能。
注意:
- join buffer的大小有限制,如果驱动表匹配的结果集太大了,MySQL会把结果集分批处理,因此如果我们的连接查询如果没办法通过索引优化,可以考虑加大 join buffer的大小,减少分批的数量。
- 由于 join buffer的大小有限制,那么我们在做连接查询的时候要尽量减少使用Select *,减少不必要的列存入 join buffer,这样 join buffer就可以存储更多有用的记录。
索引
无论是对驱动表的查询还是对被驱动表的查询,都可以走索引,添加对应的索引可以加强连接性能。在被驱动表的查询中,如果走主键或者非NULL唯一索引的查询,那么访问方式就是eq_ref。















 9183
9183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









