









 本文介绍了使用Python爬虫抓取并分析「淄博烧烤」评论数据的过程,涉及IP属地的柱形图、评论时间的折线图、点赞数的箱线图、情感分布的饼图和评论内容的词云图分析。数据显示,山东地区的讨论最多,4月26日和5月1日是热点时期,大部分评论点赞数在0-3之间,同时存在正负情感的平衡讨论。
本文介绍了使用Python爬虫抓取并分析「淄博烧烤」评论数据的过程,涉及IP属地的柱形图、评论时间的折线图、点赞数的箱线图、情感分布的饼图和评论内容的词云图分析。数据显示,山东地区的讨论最多,4月26日和5月1日是热点时期,大部分评论点赞数在0-3之间,同时存在正负情感的平衡讨论。
文章目录
一、背景介绍
您好,我是@马哥python说 ,一枚10年程序猿。
自从2023.3月以来,"淄博烧烤"现象持续占领热搜流量,体现了后疫情时代众多网友对人间烟火气的美好向往,本现象级事件存在一定的数据分析实践意义。
我用Python爬取并分析了众多网友的评论,并得出一系列分析结论。
二、爬虫代码
2.1 展示爬取结果
首先,看下部分爬取数据:
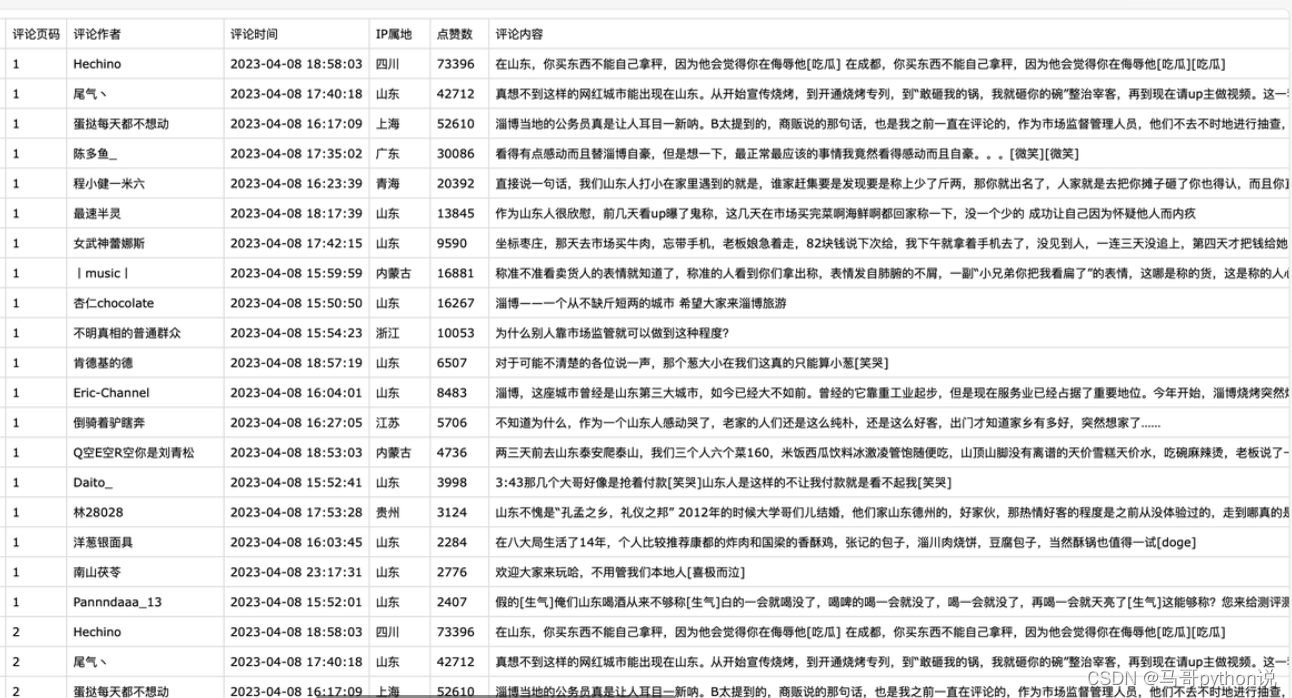
爬取字段含:视频链接、评论页码、评论作者、评论时间、IP属地、点赞数、评论内容。
2.2 爬虫代码讲解
爬虫部分不作讲解。
三、可视化代码
为了方便看效果,以下代码采用jupyter notebook进行演示。
3.1 读取数据
用read_csv读取刚才爬取的评论数据:
df = pd.read_csv('淄博烧烤_评论数据.csv')
查看前3行及数据形状:
print(df.head(3))
print(df.shape)
3.2 数据清洗
处理空值及重复值:
3.3 可视化
3.3.1 IP属地分析-柱形图
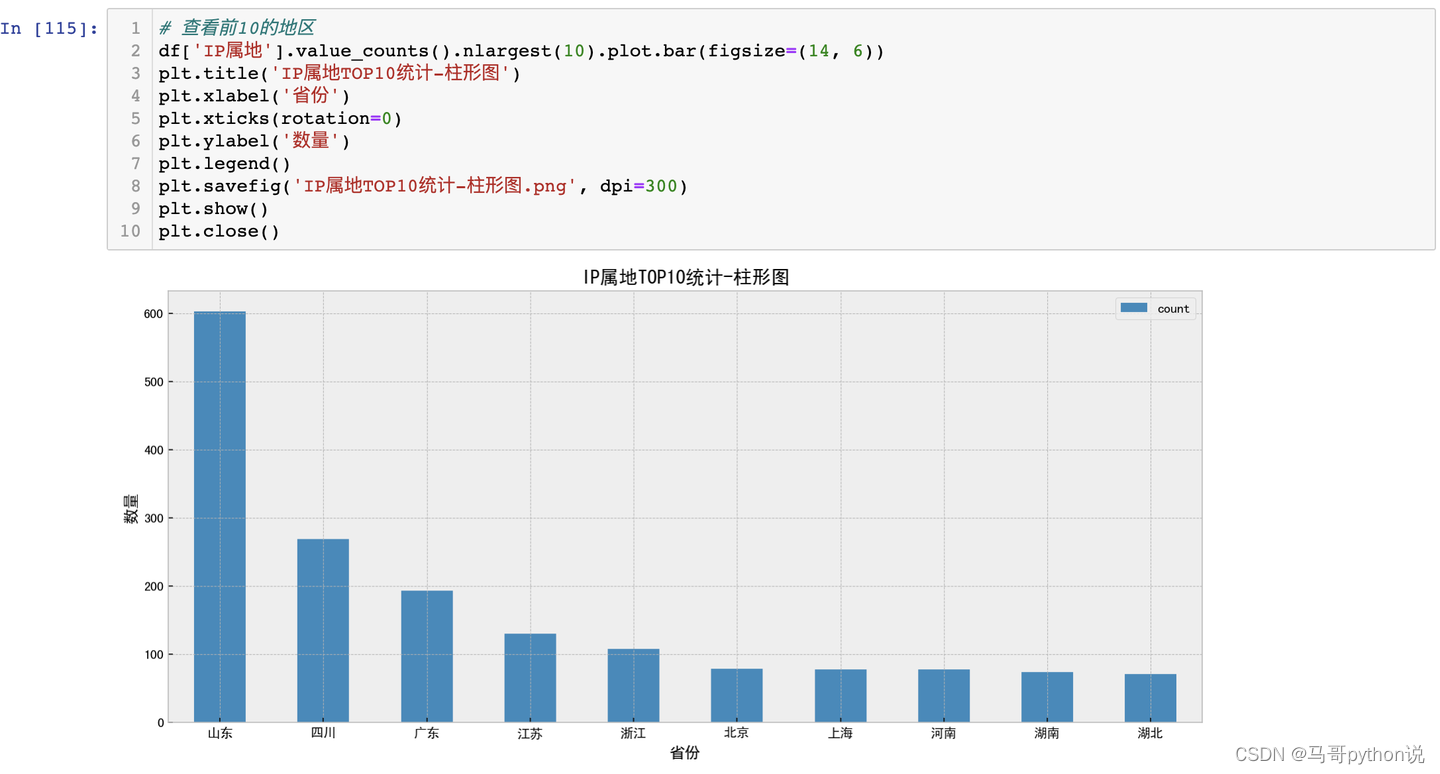
结论:从柱形图来看,山东位居首位,说明淄博烧烤也受到本地人大力支持,其次是四川、广东等地讨论热度最高。
3.3.2 评论时间分析-折线图
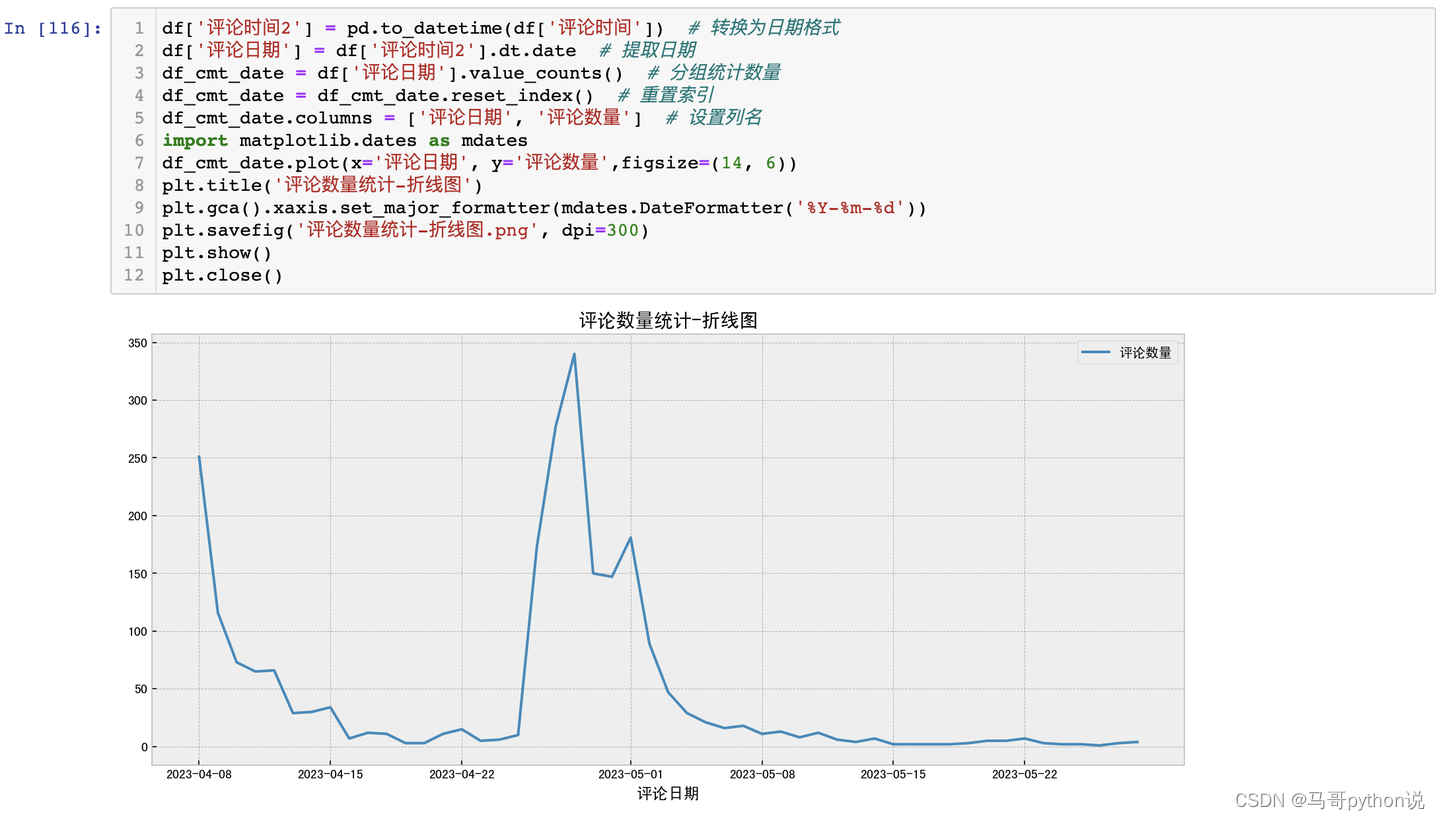
结论:从折线图来看,4月26日左右达到讨论热度顶峰,其次是5月1号即五一劳动节假期第一天,大量网友的"进淄赶烤"也制造了新的讨论热度。
3.3.3、点赞数分布-箱线图
由于点赞数大部分为0或个位数情况,个别点赞数到达成千上万,箱线图展示效果不佳,因此,仅提取点赞数<10的数据绘制箱线图。
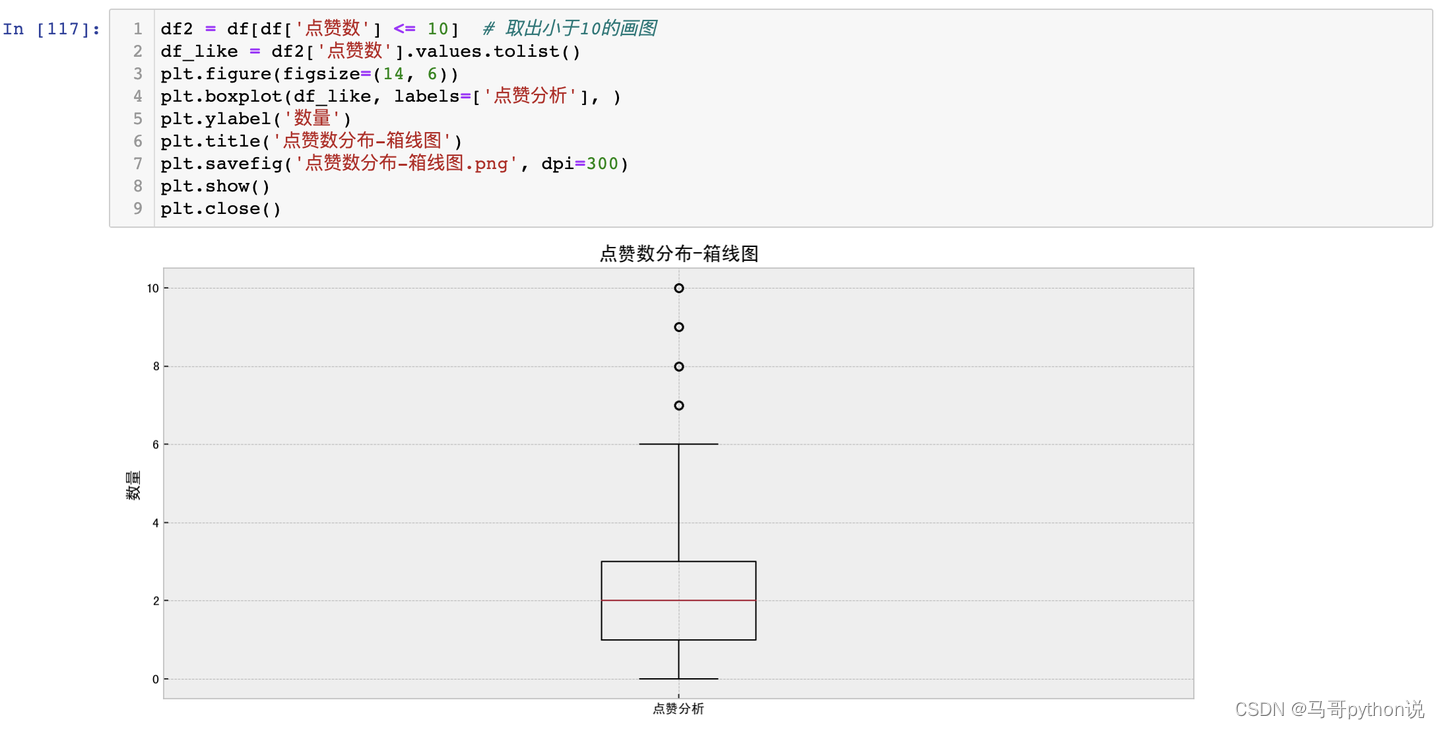
结论:从箱线图来看,去除超过10个点赞数评论数据之后,大部分评论集中在0-3个点赞之间,也就是只有少量评论引起网友的点赞共鸣和认可。
3.3.4 评论内容-情感分布饼图
针对中文评论数据,采用snownlp开发情感判定函数:
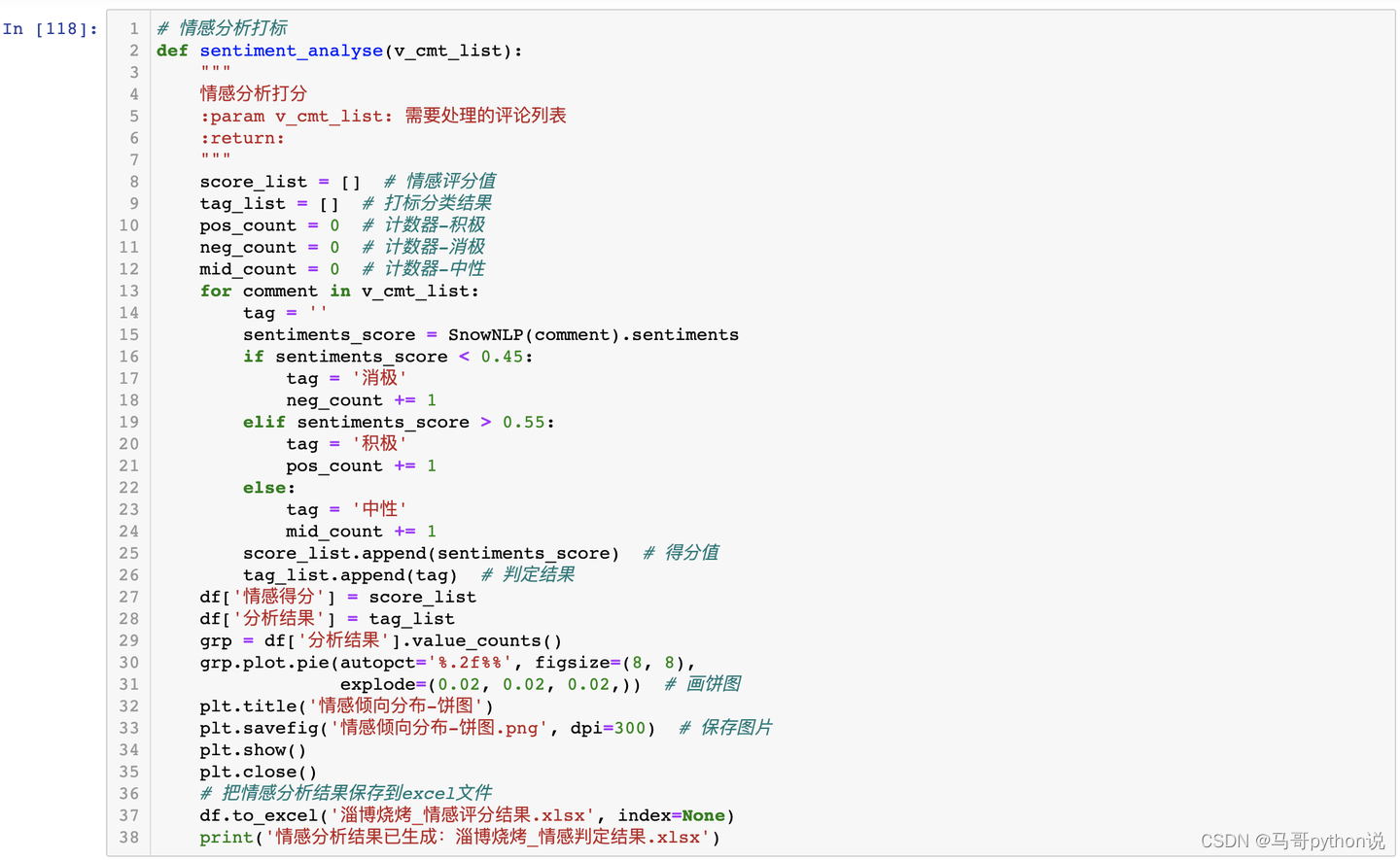
情感分布饼图,如下:
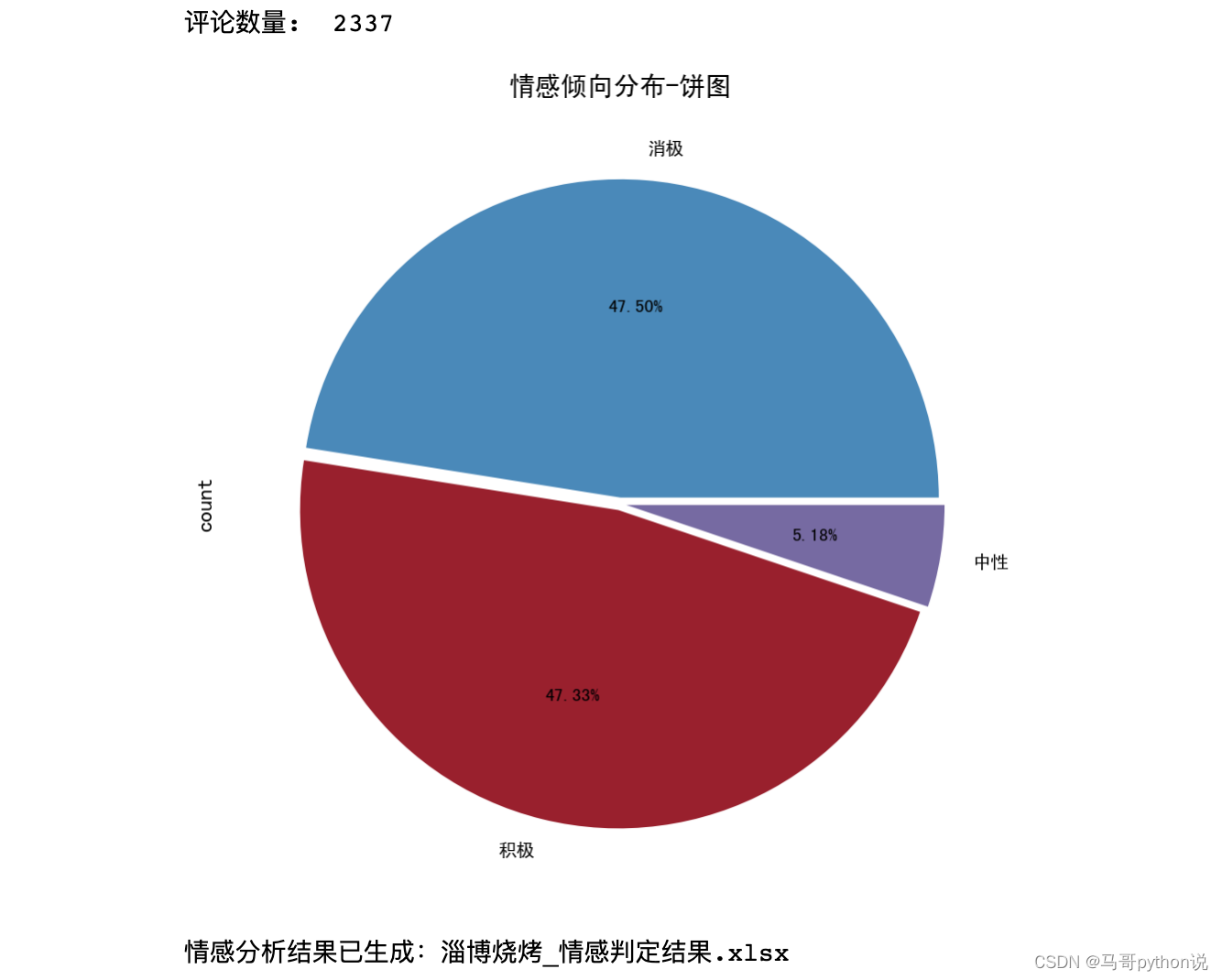
结论:从饼图来看,积极和消极分别占比不到一半,说明广大网友在认可淄博烧烤现象的同时,也有大量负面讨论存在,比如讨论烧烤的价格略高、住宿条件欠佳、环境污染等负面话题。
3.3.5 评论内容-词云图
由于评论内容中存在很多"啊"、“的”、"了"等无意义的干扰词,影响高频词的提取,因此,采用哈工大停用词表作为停用词词典,对干扰词进行屏蔽:

然后,绘制词云图:
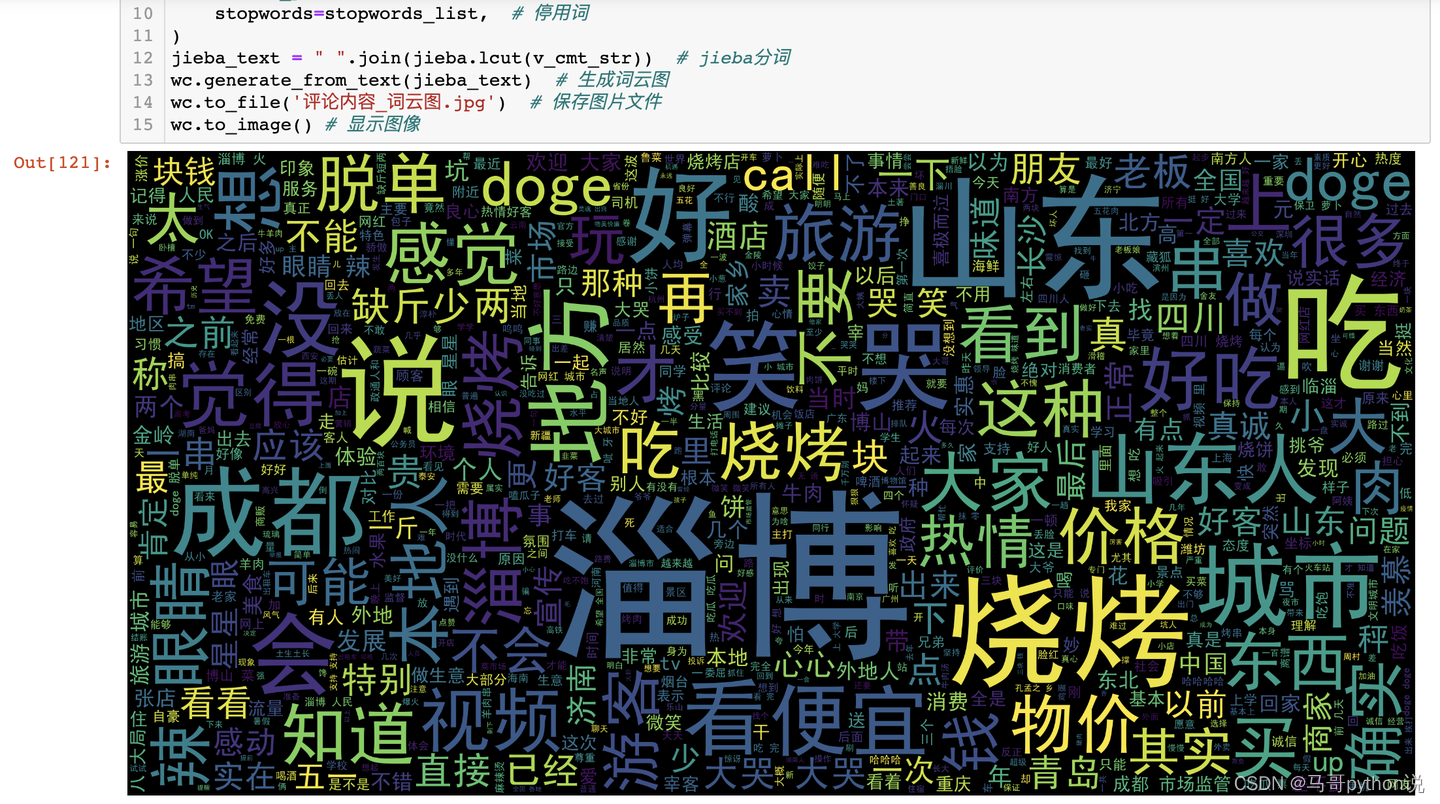
结论:从词云图来看,“淄博”、“烧烤”、“山东”、“好吃”、“城市”、“好”、"物价"等正面词汇字体较大,体现出众多网友对以「淄博烧烤」为代表的后疫情时代人间烟火的美好向往。
四、技术总结
「淄博烧烤」案例完整开发流程:
- requests爬虫
- json解析
- pandas保存csv
- pandas数据清洗
- snownlp情感分析
- matplotlib可视化,含:
1)IP属地分析-柱形图Bar
2)评论时间分析-折线图Line
3)点赞数分布-箱线图Boxplot
4)评论内容-情感分布饼图Pie
5)评论内容-词云图WordCloud
五、演示视频
代码演示视频:【爬虫+数据清洗+可视化】Python爬取并分析"淄博烧烤"评论
六、获取源码
完整源码:【爬虫+数据清洗+可视化分析】舆情分析"淄博烧烤"的评论
我是马哥,全网累计粉丝上万,欢迎一起交流python技术。
各平台搜索“马哥python说”:知乎、哔哩哔哩、小红书、新浪微博、博客园。


















 1574
1574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











