






目录
1、简单介绍Flink
1.1 意义
想要深入学习Flink的可以另外参考其他文献,我对Flink概念了解也不太深,文本只做简单说明(比较抽象)。
对于Flink我把它理解为一款非常优秀的数据处理中间件,它能把数据处理的过程单独提取出来,减轻数据流通过程中其他步骤的压力。
用过大数据量数据库的同道们应该有体验,当数据量足够大时,简单的查询都会变得很缓慢,更别说在查询语句中加入计算。正常情况下,我们计算数据的过程是在程序中,而sql只需要负责拿出数据。但一些特殊情况下,比如在帆软、grafana等报表工具使用中,我们经常需要通过sql直接处理数据,在大数据量的情况下,这就会大大增加延迟、降低用户体验。
而通过Flink,我们可以将数据处理过程单独提取出来,并应用其高性能机制地提前处理好数据,以便后续使用。
以需求“每秒采集一次设备温度,获取每日最大值和最小值(一台设备一个月约259w条)”为例,通过Flink,我们可以提前计算历史每日最大最小值(批处理) 或 实时计算最近一天的最大最小值(流处理),并将其存入另外的数据表(一台设备一个月约30条)。259w条变30条,查询效率差距显而易见。
1.2 基本概念
在使用Flink之前,需要简单了解几个概念。
1.2.1 执行机构
JobManager是任务的管理者,负责协调任务执行(接收、分配、维护任务)
TaskManager是任务的执行者,执行任务内容
1.2.2 部署模式
本地模式
- 所有计算任务运行在同一进程中(在同一个程序),不涉及真正的调度
- 相当于只有一个JobManager和一个TaskManager
- 实际使用就是没有下载安装Flink,只用了在java程序中使用Flink框架工具包。
单机模式
- 计算任务可以运行在不同进程中,但运行在同一台机器上,接受一个JobManager的调度
- 只有一个JobManager,但有多个TaskManager
- 实际使用就是在且只一台机器上安装部署了Flink,并且把程序上传到Flink中运行。
集群模式
- 计算任务可以运行在不同机器去上,接受多个JobManager的调度
- 一个或多个 JobManager 调度多个 TaskManager
- 实际使用就是在多台机器上安装部署了Flink,做了集群处理,并且把程序上传到Flink中接受调度。
本文只说明单机模式
经验尚浅,理解抽象,欢迎纠正。
2、安装并运行Flink
2.1 下载Flink
网上关于Linux系统的部署Flink的文献有很多,windows的比较少,也因此踩了挺多坑这里。
这里分享的是windwos的部署方式,需要linux版的可另行参考。
下载
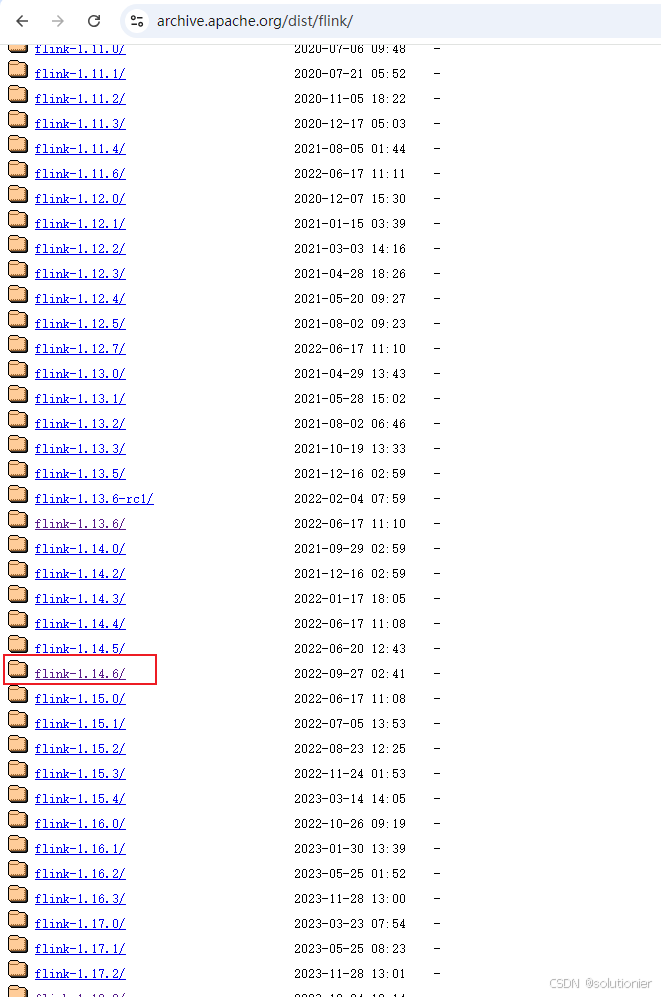
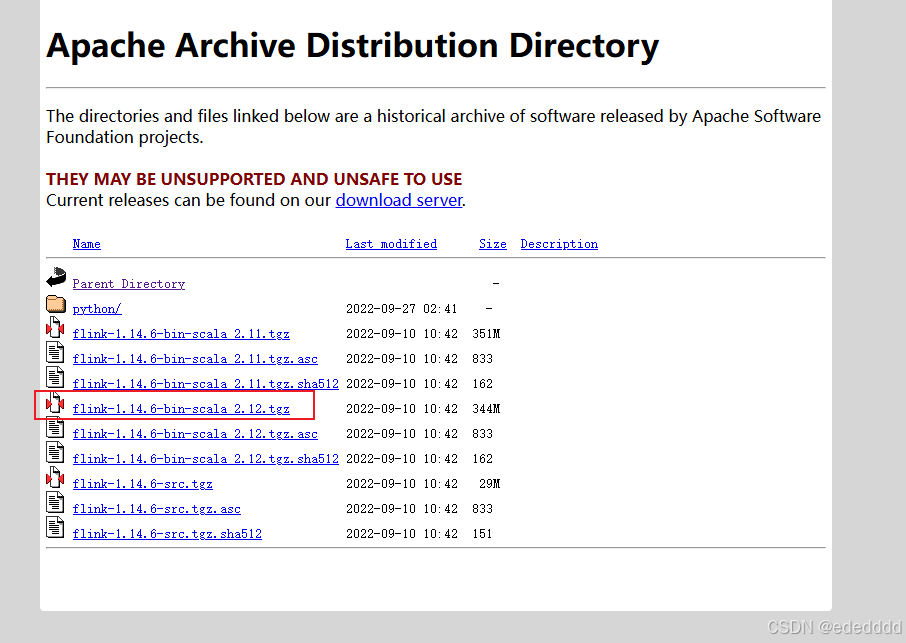
我用的是java8,但Flink 从1.15.0开始就不支持java8了,所以使用java8的推荐下载1.14.*版本
镜像(推荐)
官网
解压文件
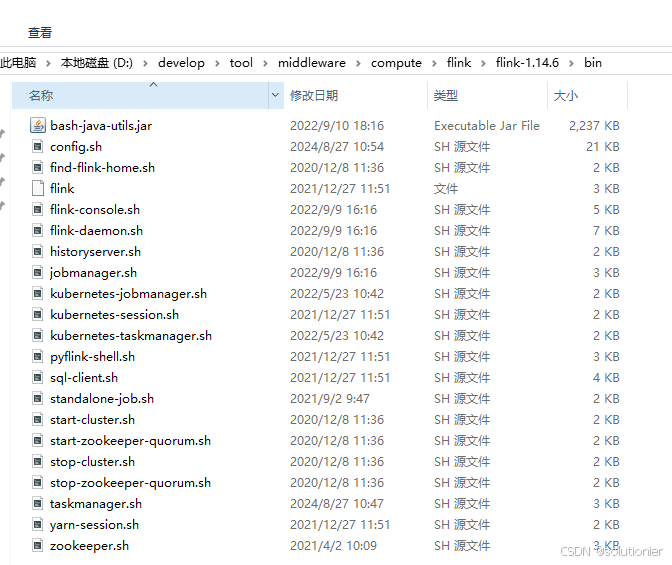
一般需要解压两次,第一次解压处tar,第二次才能解压出文件。

这里推荐一款干净的解压软件:
解压后进入bin目录,这里可以看到执行文件都是清一色的shell文件,对windows不太友好。
1.9.*版本之前是有bat的,但1.10之后就没了,Flink对Linux的兼容性更好,windwos推荐测试、学习使用。
2.1 借助Cygwin启动Flink
要运行shell,网上也有一些使用自定义bat来间接执行启动文件的,但不太推荐,会出先taskmanager启动不起来等bug。
这里推荐使用Cygwin
Cygwin 是一个为 Windows 系统提供的类 Unix 环境,允许用户在 Windows 上运行类 Unix 应用程序。
官网:Cygwin
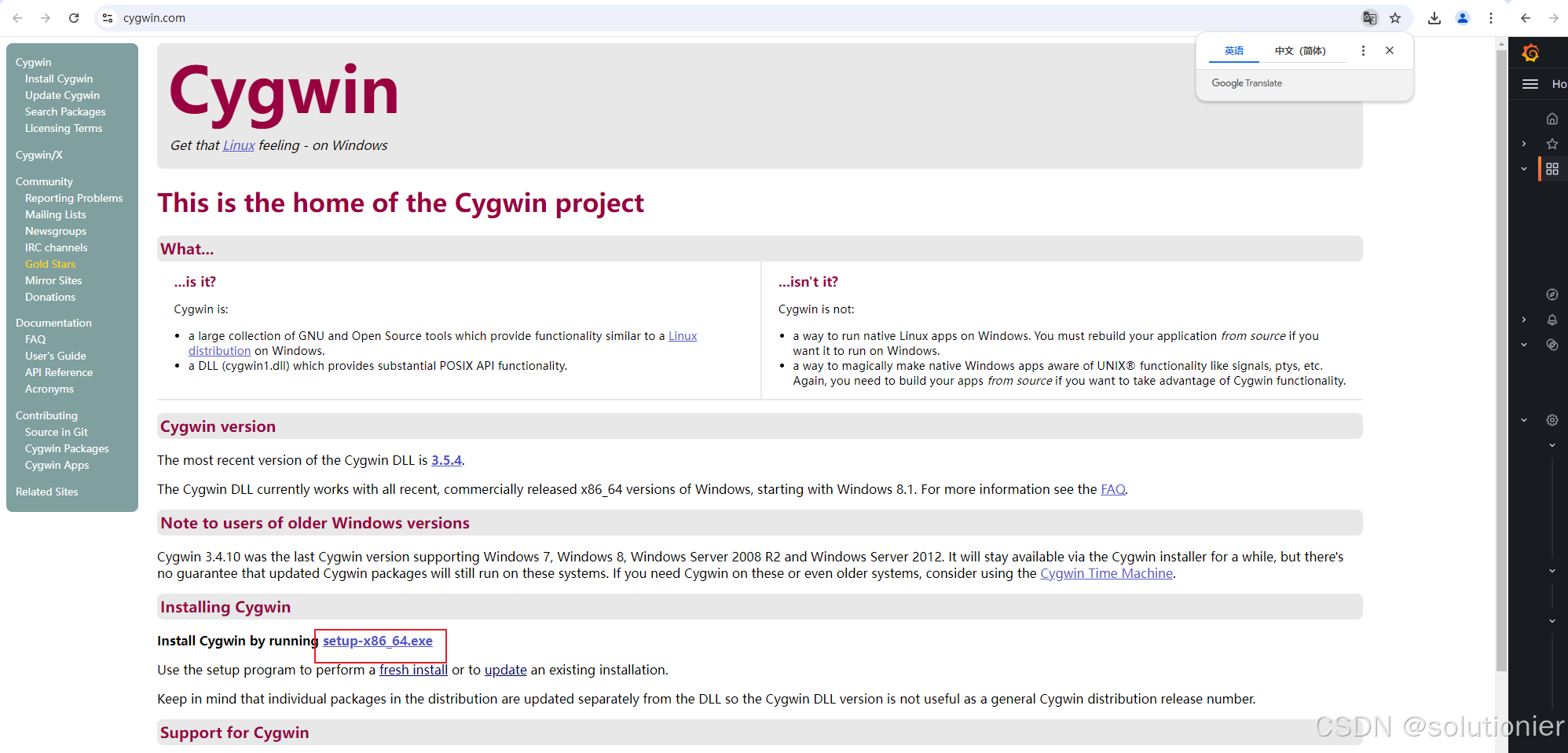
下载后打开
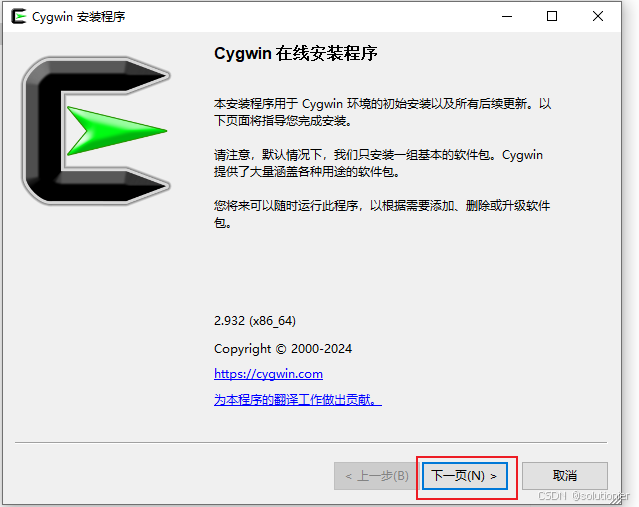
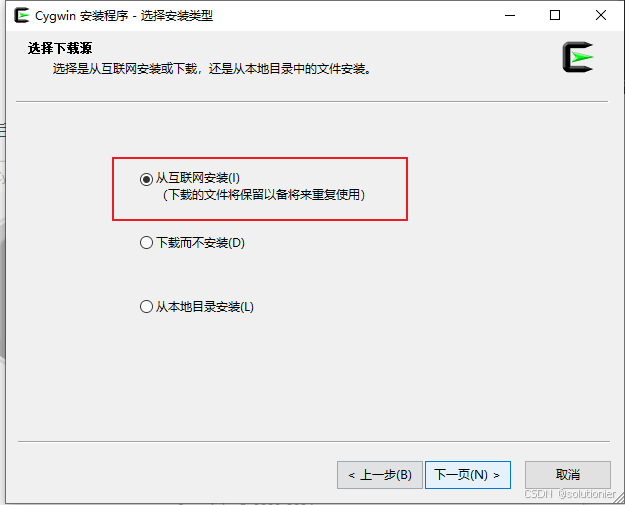
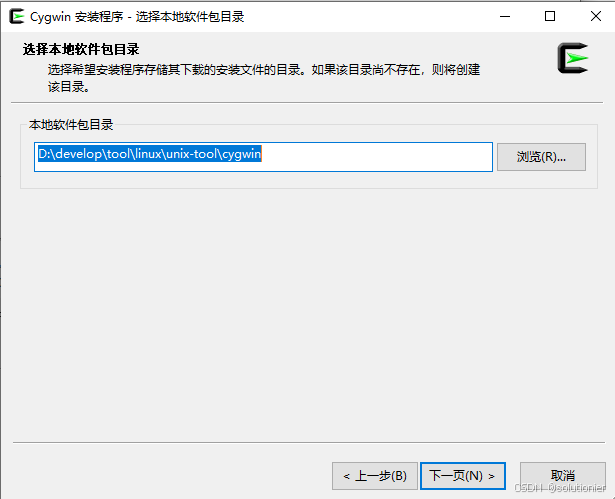
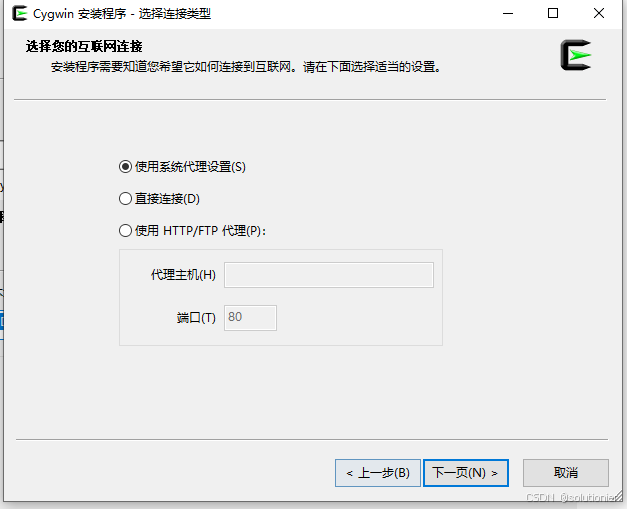
这里推荐使用镜像
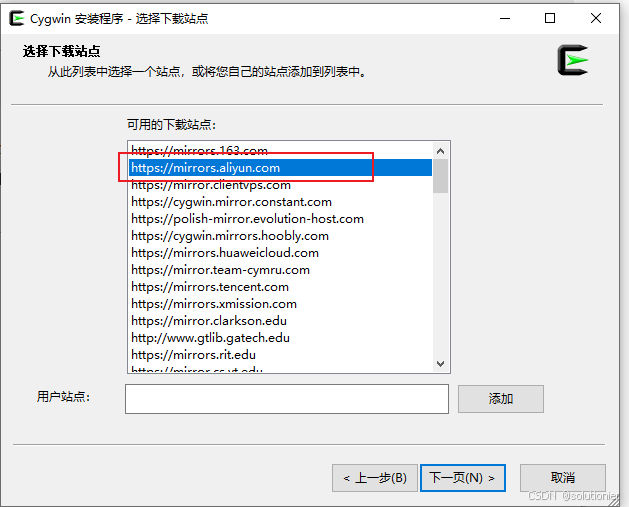
只需要安装Bash一条即可,初次安装应该在base词条展开的文件下。选中后点击下一步
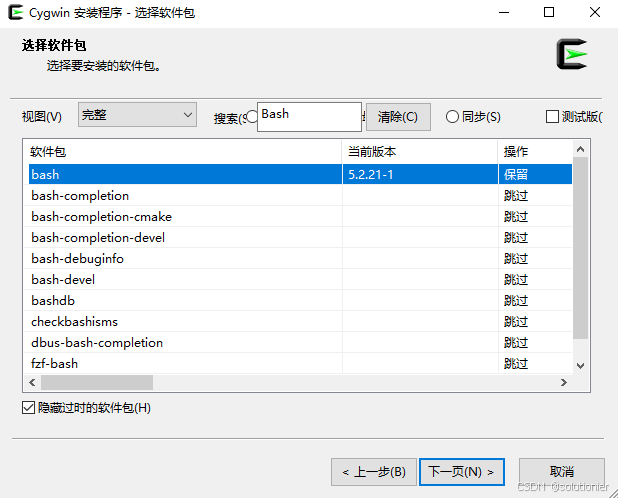
下载完成后完成即可。
后续cygwin如果需要安装其他拓展包或更新拓展包,按照同样的方式,通过setup包更新安装包。
打开cygwin终端
进入bin目录打开mintty.exe或者通过快捷方式打开
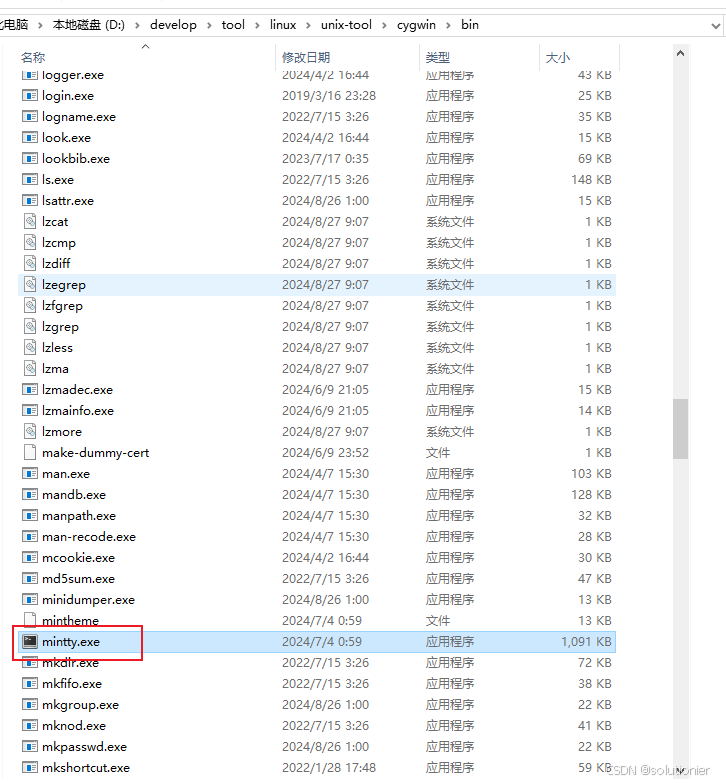
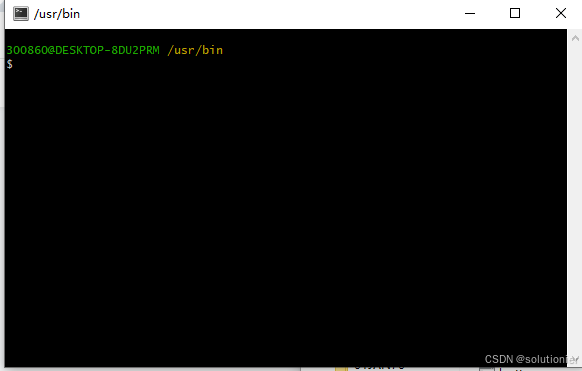
切盘方式:
cd D:
也可直接进入Flink的bin目录
cd /cygdrive/d/develop/tool/middleware/compute/flink/flink-1.14.6/bin运行
./start-cluster.sh
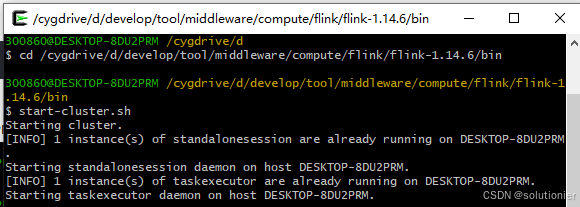
要停止就执行stop-cluster.sh
运行失败时,可以进入log目录查看最新日志文件记录的具体原因
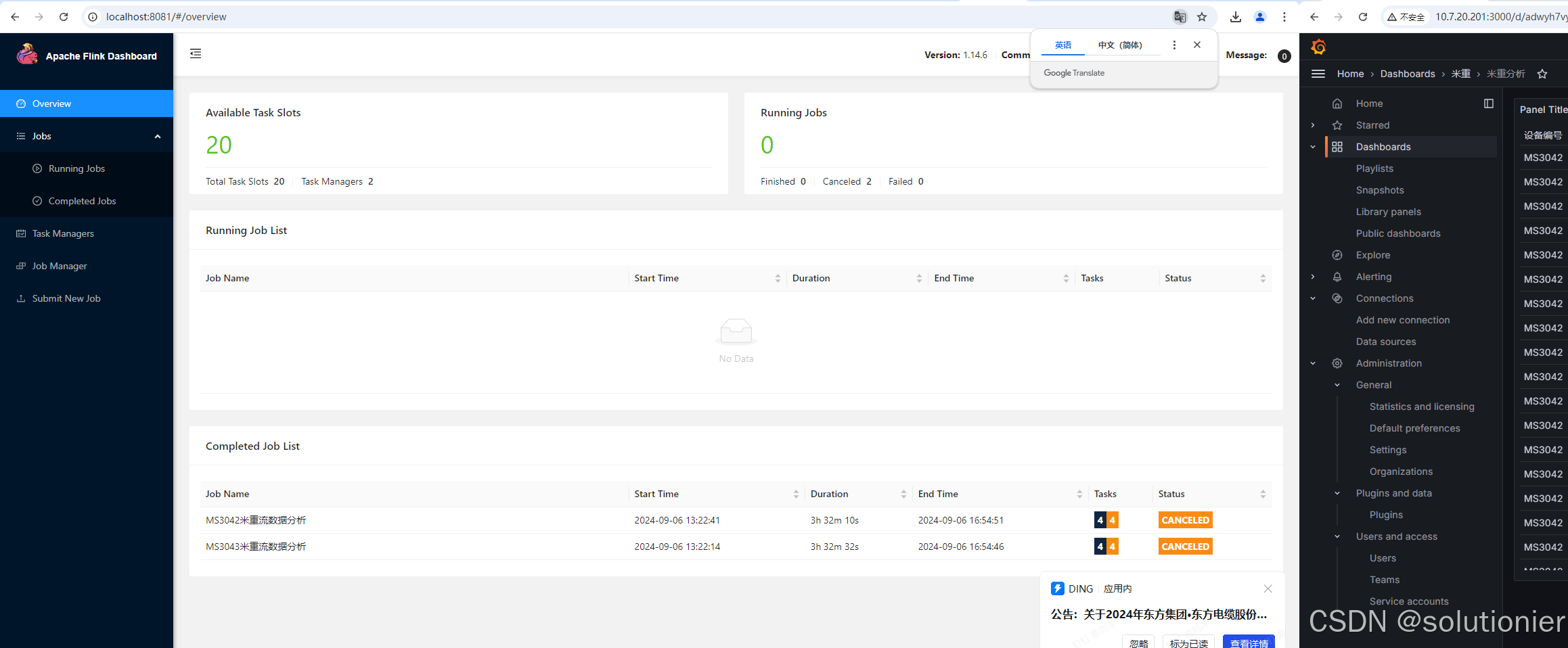
启动后,浏览器访问localhost:8081,即可正常访问和使用的Flink UI界面。
至此,单机Flink搭建完毕,在Flink上执行任务可以参考后面这篇

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









