






 本文介绍了Hadoop分布式文件系统(HDFS)的结构、特点和副本机制,以及ApacheHive作为数据仓库的特性、查询语言和体系架构,强调了两者在大数据处理中的关键作用。
本文介绍了Hadoop分布式文件系统(HDFS)的结构、特点和副本机制,以及ApacheHive作为数据仓库的特性、查询语言和体系架构,强调了两者在大数据处理中的关键作用。
今天主要学习了两部分:
一、hdfs文件系统
1.概述:HDFS的全称是Hadoop Distributed File System 是一个分布式文件系统, 它用于将单个 Apache Hadoop 集群扩展到数百 (甚至数千)个节点,可以让多台机器上的多个用户分享文件和存储空间,HDFS适合大文件存储,不适合小文件。通过HDFS可以以流式数据访问模式存储超大文件。
2、特点:(1)HDFS文件系统可存储超大文件,时效性稍差。
(2)HDFS具有硬件故障检测和自动快速恢复功能。
(3)HDFS为数据存储提供很强的扩展能力。
(4)HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
(5)HDFS可在普通廉价的机器上运行。
3、架构:(1)HDFS采用Master/Slave架构
(2)一个HDFS集群有两个重要的角色,分别是Namenode和Datanode。
(3)HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
4、副本机制:
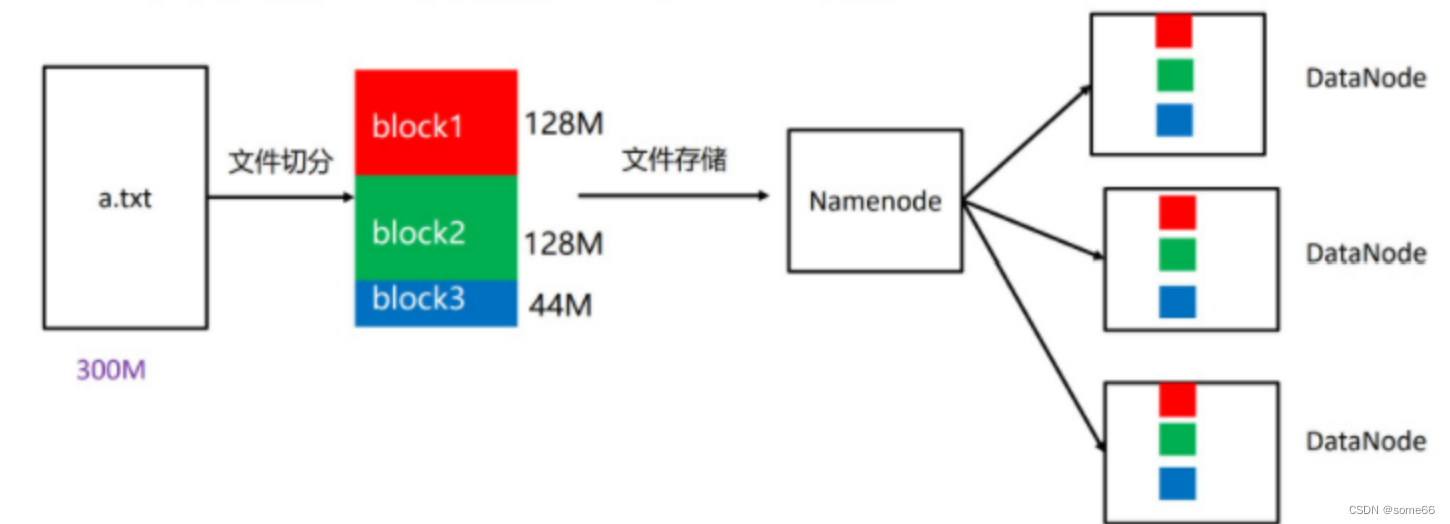
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
二、简单认识Apache Hive
1.简介:Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
2.特点:
(1)简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
(2)灵活性高,可以自定义用户函数 (UDF) 和存储格式;
(3)为超大的数据集设计的计算和存储能力,集群扩展容易;
(4)统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
(5)执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
3.体系架构: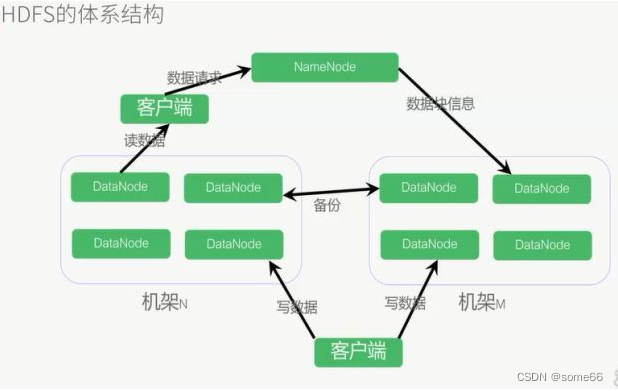















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









