







在上篇文章中,我们模拟了哨兵进程的一次完整工作流程,我们将在本文继续探讨哨兵机制的工作原理。
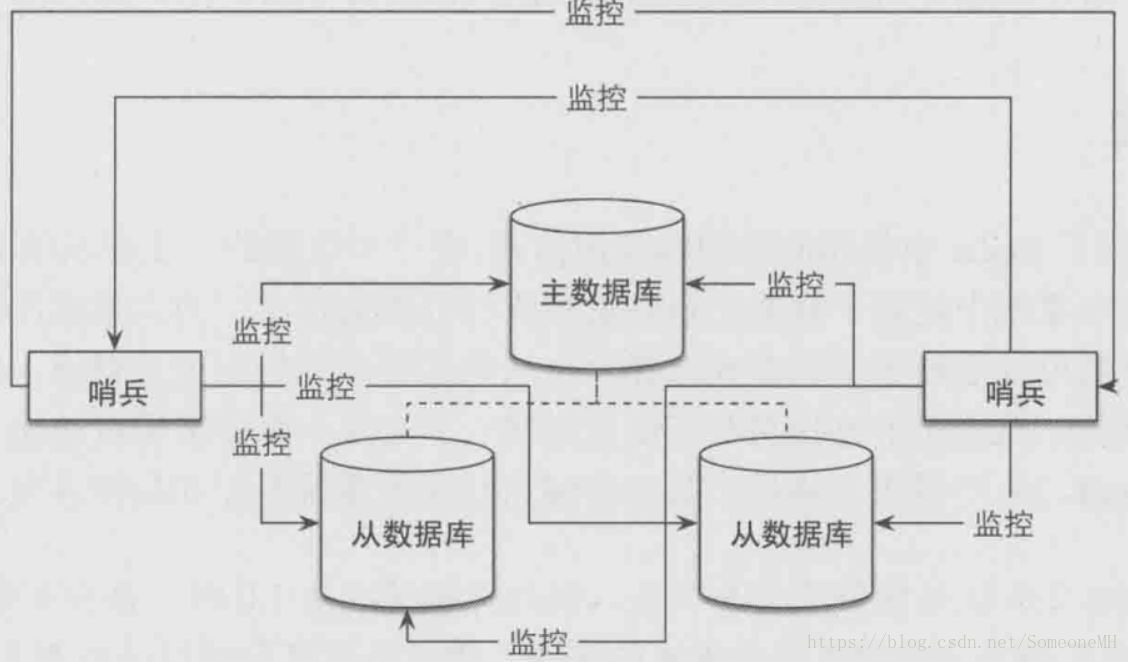
在此之前,我们先插个题外话,实际上生产环境中对一个Redis系统一般不止部署一个哨兵,为了保证系统足够稳健(单个哨兵进程也有可能挂掉),我们一般同时使用多个哨兵监控整个系统。此时,哨兵不仅监控主从数据库,哨兵之间还需要相互监控,系统架构如下图所示:
好的,回到正题,回顾一下哨兵启动时的配置文件中,有这么一条命令:sentinel minitor my_masterDB 127.0.0.1 6379 1
my_masterDB表示主数据库的名称,后面紧跟着主数据库的IP地址和端口号,最后一个参数是quorum,这个参数很重要,表示最低投票数,该参数在下文将继续讲解。
哨兵进程启动后,会与要监控的主数据之间建立两条连接,这种连接方式和Redis客户端与Redis服务端的连接一样,其中一条连接用来订阅主数据库的"_sentinel_:hello"频道,以获取其他同样监听该主数据库的哨兵节点的信息;另一条连接用于向主数据发送INFO等命令以获取主数据库的信息。
当哨兵与主数据建立好连接后,哨兵会定时地执行下面3个操作:
- 每10秒,哨兵会向主数据库和从数据库发送INFO命令
- 每2秒,哨兵会想主数据库和从数据库的"_sentinel_:hello"频道发送自己的信息
- 每1秒,哨兵会向主数据库和从数据库以及其他哨兵节点发送PING命令
这三个定时任务是理解哨兵机制原理的基础,我们一个一个来看。
定时任务一:每10秒,哨兵会向主数据库和从数据库发送INFO命令
首先,哨兵是与主数据库建立了两条连接,哨兵向其中一条连接发送INFO命令,获取主数据库的相关信息,如运行时ID,复制信息等,通过解析复制信息,哨兵就能够知道哪些数据库实例作为当前主数据库的从数据库。稍后,哨兵就会与每个从数据库都建立两条连接,这两条连接和前文介绍的哨兵与主数据库建立的连接是一致的,一个用于订阅数据库实例的"_sentinel_:hello"频道,另一条连接哨兵用来发送命令。哨兵会实时每隔10秒向所有已知的主从数据库发送INFO命令,获取并更新信息和执行相关操作,如将新的从数据库加入到监控列表,对主从关系的变化执行信息更新等。
定时任务二:每2秒,哨兵会想主数据库和从数据库的"_sentinel_:hello"频道发送自己的信息
接下来,哨兵就每隔2秒向所有已知的主从数据库的"_sentinel_:hello"频道发送信息,目的是与同样监听这些数据库实例的哨兵们分享自己的信息。发送的消息内容格式为:
<哨兵地址>,<哨兵端口>,<哨兵的运行ID>,<哨兵的配置版本>,
<主数据库的名称>,<主数据库的地址>,<主数据库的端口>,<主数据库的配置版本>
前文介绍过,哨兵与其监控的每个数据库实例建立的两条连接中,其中一条就是专职用来订阅数据库实例的"_sentinel_:hello"频道,当哨兵接收到其他哨兵节点广播的信息后,会判断其是否是新的哨兵,若是则将其加入到一直的哨兵列表中,并与其建立一条连接(这条连接是哨兵与哨兵的连接,用来发送PING命令)。同时哨兵会判断主数据的配置版本,如果该版本比自己记录的版本高,则更新主数据库的信息。
定时任务三:每1秒,哨兵会向主数据库和从数据库以及其他哨兵节点发送PING命令
这个定时任务才是哨兵机制的核心,涉及到了数据库实例运行状态监控、领头哨兵推举、备选从数据库选择等细节操作。
哨兵会定时向主从数据库和其他哨兵节点发送PING命令,其实这里的时间间隔可以是0~1秒,通过down-after-milliseconds选项指定。down-after-milliseconds设定值若小于1秒,则哨兵会以设定的时间间隔发送PING命令;若设定值大于1秒,则哨兵会以1秒为间隔发送PING命令。
如果超过down-after-milliseconds时间间隔后,被PING的数据库实例或哨兵节点没有响应,则当前哨兵认为其主观下线(subjectively down)。若对方是主数据库,则哨兵会进一步判断是否需要故障修复:当前哨兵节点会向其他哨兵节点发送SENTINEL is-master-down-by-addr命令,以判断其他哨兵节点是否也认为该主数据库主观下线。当超过quorum数量(包括自己)的哨兵节点都认为该主数据库主观下线,则当前哨兵节点就可任务该主数据库客观下线(objectively down)。
当哨兵认为主数据库已经客观下线,那么就要对其进行故障修复了。故障修复需要一个领头哨兵来完成,因此需要通过选举的方式找到一个领头哨兵,选举的过程使用了Raft算法,过程如下:
- 发现主数据库客观下线的哨兵节点(下面称之为A),会向其他哨兵节点发送命令,要求对方选自己为领头哨兵
- 若目标哨兵节点没有投过票,则会同意A节点为领头哨兵
- 若A节点发现超过半数,且超过quorum参数值的哨兵节点选举自己为领头哨兵,则A就成功成为领头哨兵
- 当多个哨兵同时参与竞选,有可能出现没有任何节点当选的可能,这时每个参选节点都将等待一个随机事件重新发起竞选请求,进行下一轮选举,直到选举出领头哨兵为止。
选举完成后,领头哨兵就需要执行故障恢复操作了,具体步骤如下:
1、从停止服务的主数据库的所有可用从数据库中选择一个,作为新的主数据库,选择的依据如下:
- 选择一个优先级最高的从数据库作为新的主数据,优先级可以通过slave-priority选项设置
- 在优先级相同的情况下,复制的命令偏移量越大(数据完整性越好),越优先
- 如果以上条件都一样,则选择运行ID最小的从数据库
2、选择完毕后,领头哨兵向该从数据库发送SLAVEOF NO ONE命令,将其升格为主数据库,然后领头哨兵向其他从数据库发
送SLAVEOF命令,使得它们作为新主数据库的从数据库。
3、最后,领头哨兵更新内部记录,将停止服务的旧主数据库作为新主数据库的从数据库,以便其恢复后能够按照新的主从关
系继续提供服务。
至此,哨兵机制的整体流程已经介绍完毕。我们可以看出,这三个定时任务撑起了哨兵的运行过程。然而,哨兵的部署方案也影响了整个系统的监控性能。极端情况下,当只有一个哨兵时,哨兵本身就有可能发生单点故障。整体来讲,相对稳妥的哨兵部署方案应该是使得哨兵的视角尽量的与每个节点的视角一致,即:
- 为每个节点(无论是主数据库还是从数据库)部署一个哨兵
- 使得每个哨兵与其对应的节点网络环境尽可能的相同或相近
- 同时设置quorum的值为(N/2) + 1,其中N的值就是哨兵节点数量,即当大部分哨兵节点都同意后才进行故障修复
Ending ... 














 4009
4009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









