









十五.GIL锁(重点)
1.GIL的定义
Global Interpreter Lock 直译为全局解释器锁
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
结论 : 在Cpython解释器中, 同一个进程下开启的多线程, 同一时刻只能有一个线程执行, 无法利用多核优势
2.GIL不是Python语言的特性
GIL是Python解释器(Cpython)时引入的概念,在JPython、PyPy、Psyco中没有GIL。GIL并不是Python的语言缺陷, Python完全可以不依赖与GIL
3.为什么会存在GIL
GIL本质就是一把互斥锁, 所有的互斥锁的本质都一样, 将并发运行变成串行, CPython在执行多线程的时候并不是线程安全的,所以为了程序的稳定性,加一把全局解释锁,能够确保任何时候都只有一个Python线程执行,
4.为什么说并不是线程安全的
我们知道执行一个Python文件, 会将Python代码交给解释器运行, 调用的是解释器的功能, 每执行一个文件, 都会产生一个独立的进程, 该进程内不仅仅只有运行Python代码的进程, 还有解释器开启的垃圾回收等解释器级别的进程, 所有线程都运行在这同一个进程之内

产生的问题就是 : 假设你定义一个变量 x = 10, 先申请一个内存空间, 将 10 放进内存空间中, 当你转身想让变量名去绑定 10 的内存地址的时候, 垃圾回收机制刚好启动起来了, 扫描到 10 的引用计数为 0, 于是就被清理掉了

转个身就没了??

解决这个问题的方法就是加锁, 保证python解释器同一时间只能执行一个任务的代码
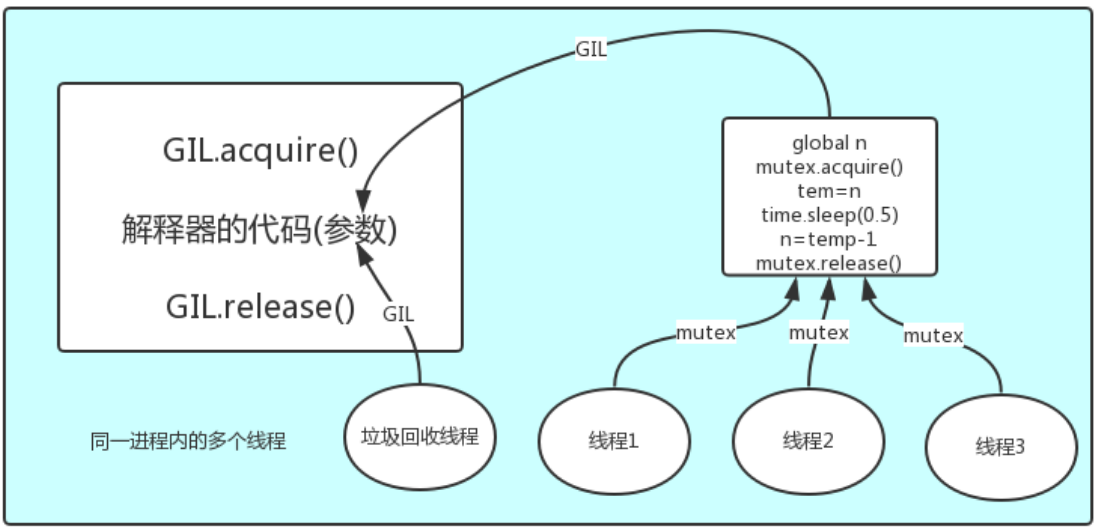
原理 : 想要运行Python代码, 那就必须先拿到解释器锁, 相当于是拿到了CPU的使用权限, 然后在运行Python代码, 在Python代码中可以加自己的锁, GIL保护的是解释器级别的数据(内存管理数据等)
值得肯定的一点是 : 保护不同的数据安全, 就应该加上不同的锁
5.GIL与Lock的区别
我们以一个百人改值的示例来解释两者的不同
from threading import Thread,Lock
import time
mutex = Lock()
count = 100
def change():
global count
mutex.acquire() # 加锁
temp = count
time.sleep(0.1) # 模拟I/O
temp -= 1 # 修改-1
count = temp
mutex.release() # 释放锁
if __name__ == '__main__':
li = []
for i in range(100):
p = Thread(target=change)
p.start()
li.append(p)
for i in li:
i.join()
print(count) # 0
原理分析 : 同时开启了100个线程, 都去抢GIL锁, 假设线程1抢到了, 那么线程1就获取了CPU的执行权限, 将会被分配CPU, 而其他的线程只能等待, 接着线程1运行Python代码, 先是加了一把互斥锁、赋值了一下变量, 然后sleep(I/O), 这时操作系统发现你正在做I/O, 立马把CPU资源调走并强行让其释放GIL, 让别的线程抢夺, 假设线程2抢到了, 它就获得了CPU执行权限, 他也运行Python代码, 紧接着声明全局变量count, 下一步发现被加锁了, 阻塞在原地, 于是被操作系统查觉到了, 立马又把CPU拿走并强行释放GIL给别的线程争抢, 但都像线程2一样抢到了也没啥用(相当于是降低了效率). 等到线程1的I/O做完了, 于是也参与抢锁, 操作系统会让它很快的抢到锁, 抢到之后接着运行上次运行的代码, 将count值减1、释放Lock、释放GIL. 于是其他线程又开始了争夺, 直到所有的线程都运行完毕
6.GIL对多线程产生的影响
有了GIL的存在,同一时刻同一进程中只有一个线程被执行, 但并不是说多核优势就没用了, 这需要看情况而定 : 对于一个程序来说, 要么就是计算密集型, 要么就是I/O密集型
- GIL对计算密集型程序会产生影响 : 因为计算密集型的程序, 需要占用系统资源, CPU越多越好, 效率总会提升, 但GIL的存在,相当于始终在进行单线程运算,这样自然就慢了
- 而对于I/O密集型程序来说, 程序大部分时间在等待, 所以它们是多个一起等(多线程)还是单个等(单线程)都得等
7.并发任务的处理方案
现有四个任务, 要让其并发, 有哪些方案可选 :
- 方案一 : 开启四个单线程的进程
- 方案二 : 开启四个线程的单进程
- 方案三 : 开启两个进程,每个进程两个线程,或者一个进程三个线程,一个进程单线程(混着来)
🍑单核情况下
四个任务都是计算密集型,开启进程消耗大,使用方案二
四个任务都是I/O密集型,开启进程消耗大,并且进程的切换速度远不如线程,使用方案二
🍑多核情况下
四个任务都是计算密集型,多核意味着并行计算,在Cpython中一个进程中同一时刻只有一个线程执行,没有多核优势,使用方案一
四个任务是都I/O密集型,多核解决不了I/O问题,该等还得等,开进程消耗大,使用方案二
8.多进程与多线程对不同应用场景的性能对比
- 运算密集型对比
from multiprocessing import Process
from threading import Thread
import time,os
🍑多进程测试
def calculate():
count = 0
while count < 30000000:
count +=1
if __name__ == '__main__':
li = []
print(os.cpu_count()) # 查看CPU个数--->4
start_time = time.time()
for i in range(4):
p = Process(target=calculate)
p.start()
li.append(p)
for i in li:
i.join()
print(f"多进程用时:{time.time()-start_time}")
#🔰多进程用时:5.714418649673462
🍑多线程测试
def calculate():
count = 0
while count < 30000000:
count +=1
if __name__ == '__main__':
li = []
print(os.cpu_count()) # 查看CPU个数--->4
start_time = time.time()
for i in range(4):
p = Thread(target=calculate)
p.start()
li.append(p)
for i in li:
i.join()
print(f"多线程用时:{time.time()-start_time}")
#🔰多线程用时:9.828791618347168
- I/O密集型对比
from multiprocessing import Process
from threading import Thread
import time,os
🍑多进程测试
def calculate():
time.sleep(2)
if __name__ == '__main__':
li = []
print(os.cpu_count()) # 查看CPU个数--->4
start_time = time.time()
for i in range(500):
p = Process(target=calculate)
p.start()
li.append(p)
for i in li:
i.join()
print(f"多进程用时:{time.time()-start_time}")
#🔰多进程用时:40.83470439910889
🍑多线程测试
def calculate():
time.sleep(2)
print("完毕--->")
if __name__ == '__main__':
li = []
print(os.cpu_count()) # 查看CPU个数--->4
start_time = time.time()
for i in range(500):
p = Thread(target=calculate)
p.start()
li.append(p)
for i in li:
i.join()
print(f"多线程用时:{time.time()-start_time}")
#🔰多线程用时:2.056976556777954
以上实验结论 : Cpython 对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于 I/O 密集型的任务效率还是有显著提升的
- 应用场景
多线程主要运用于I/O密集型 : socket, 爬虫, web
多进程主要运用于计算密集型 : 金融分析, 比特币挖矿

















 3041
3041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











