






一、定义
XPath(XML Path Language)是一种用于在 XML 文档中定位和选择节点的语言。XPath的选择功能非常强大,可以通过简单的路径选择语法,选取文档中的任意节点或节点集。同样也支持 HTML 元素的解析,学会XPath,可以轻松抓取网页数据,提高数据获取效率。
二、XPath基础语法
节点(Nodes): XML 文档的基本构建块,可以是元素、属性、文本等。
路径表达式: 用于定位 XML 文档中的节点。路径表达式由一系列步骤组成,每个步骤用斜杠 / 分隔。
XPath的节点是指在XML或HTML文档中被选择的元素或属性。XPath中有7种类型的节点,包括元素节点、属性节点、文本节点、命名空间节点、处理指令节点、注释节点以及文档节点(或称为根节点)。
- 元素节点:表示XML或HTML文档中的元素。例如,在HTML文档中,<body>、<div>、<p>等都是元素节点。在XPath中,可以使用元素名称来选择元素节点,例如://div表示选择所有的<div>元素。
- 属性节点:表示XML或HTML文档中元素的属性。例如,在HTML文档中,元素的class、id、src等属性都是属性节点。在XPath中,可以使用@符号来选择属性节点,例如://img/@src表示选择所有<img>元素的src属性。
- 文本节点:表示XML或HTML文档中的文本内容。例如,在HTML文档中,<p>标签中的文本内容就是文本节点。在XPath中,可以使用text()函数来选择文本节点,例如://p/text()表示选择所有<p>元素中的文本内容。
- 命名空间节点:表示XML文档中的命名空间。命名空间是一种避免元素命名冲突的方法。在XPath中,可以使用namespace轴来选择命名空间节点,例如://namespace::*表示选择所有的命名空间节点。
- 处理指令节点:表示XML文档中的处理指令。处理指令是一种用来给处理器传递指令的机制。在XPath中,可以使用processing-instruction()函数来选择处理指令节点,例如://processing-instruction('xml-stylesheet')表示选择所有的xml-stylesheet处理指令节点。
- 注释节点:表示XML或HTML文档中的注释。注释是一种用来添加说明和备注的机制。在XPath中,可以使用comment()函数来选择注释节点,例如://comment()表示选择所有的注释节点。
- 文档节点:表示整个XML或HTML文档。文档节点也被称为根节点。在XPath中,可以使用/符号来选择文档节点,例如:/表示选择整个文档节点。
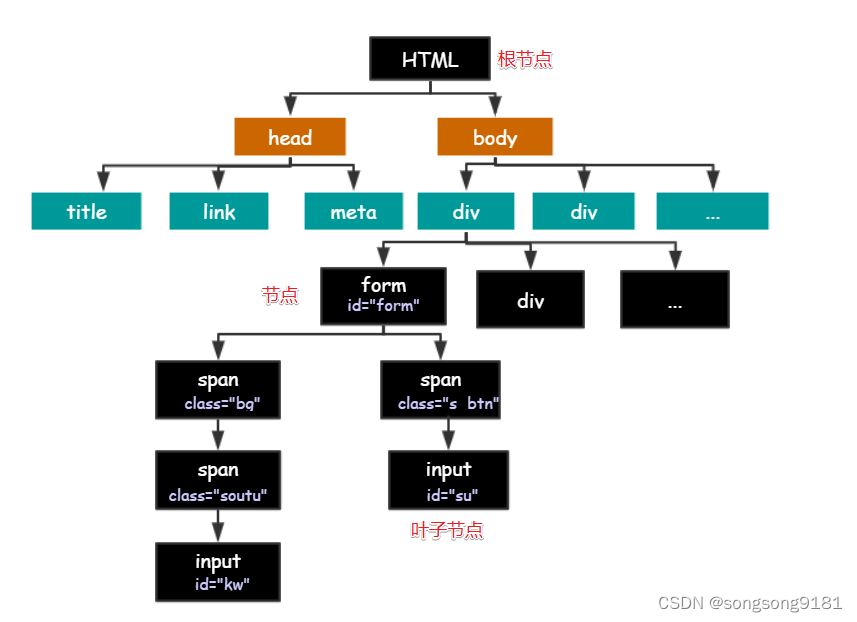
HTML树状结构图
HTML 的结构就是树形结构,HTML 是根节点,所有的其他元素节点都是从根节点发出的。其他的元素都是这棵树上的节点Node,每个节点还可能有属性和文本。而路径就是指某个节点到另一个节点的路线。
本文使用XML实例如下:
<bookstore>
<book category='fiction'>
<title>活着</title>
<author>余华</author>
<press>作家出版社</press>
<date>2012-8-1</date>
<page>191</page>
<price>20.00</price>
<staple>平装</staple>
<series>余华作品(2012版)</series>
<isbn>9787506365437</isbn>
</book>
<book category='non-fiction'>
<title>撒哈拉的故事</title>
<author>三毛</author>
<press>哈尔滨出版社</press>
<date>2003-8</date>
<page>217</page>
<price>15.80</price>
<staple>平装</staple>
<series>三毛全集(华文天下2003版)</series>
<isbn>9787806398791</isbn>
</book>
<book category='non-fiction'>
<title>明朝那些事儿(1-9)</title>
<author>当年明月</author>
<press>中国海关出版社</press>
<date>2009-4</date>
<page>2682</page>
<price>358.20</price>
<staple>精装16开</staple>
<series>明朝那些事儿(典藏本)</series>
<isbn>9787801656087</isbn>
</book>
</bookstore>
除了这些基本节点类型之外,XPath还支持使用路径表达式、通配符和谓语:
2.1 路径表达式
XPath使用路径表达式来选取XML或HTML文档中的节点或节点集。下面是一些常用的路径表达式:
| 表达式 | 描述 | 示例 |
| / | 从根节点选取直接子节点 | /bookstore 从根节点选取<bookstore>元素 |
| // | 从当前节点选取子孙节点 | //book 选取所有<book>元素,无论它们在文档中的位置 |
| ./ | 当前节点再次进行xpath | ./title 选取当前节点的<title>子元素 |
| ../ | 选取当前节点的父节点 | ../price 选取当前节点的父节点的<price>子元素 |
| @ | 选择属性 | //book/@id 选取所有<book>元素的id属性 |
注意:// 也表示从任意位置开始检索,而不考虑它们的位置。xpath查找标签的顺序正常是从HTML文档头部开始查找,当一个HTML文档中标签非常多,我们查找的标签位于文档的中间某位置。如果直接从头部标签开始一级级往下检索,非常繁琐。用 “// + 标签名” 就相当于从该标签开始检索书写。比如我们还是要找 a 标签,可以写成 //a。
2.2 通配符
除了这些基本节点类型之外,XPath还支持使用通配符:
| 通配符 | 描述 | 示例 |
| * | 匹配任何元素节点 | //book/* 选取<book>元素下的任意子元素节点 |
| @* | 匹配任何属性节点 | //book/@* 选取<book>元素上的任意属性节点,如<book category='fiction'>中的category属性 |
| node() | 匹配任何类型的节点 | //book/node() 选取<book>元素下的所有类型的子节点,包括元素节点、文本节点、注释节点等 |
2.3 谓语(Predicates)
- 谓语用来查找某个特定的节点或者包含某个指定的值的节点。
- 谓语被嵌在方括号中。
以及使用谓词来进一步筛选选择的节点集。谓词是一种用来对节点进行过滤和排序的机制,可以包含比较运算符、逻辑运算符和函数等,部分示例如下:
| 谓语 | 描述 | 示例 |
[position()=n] | 选取位于指定位置的节点。n 是节点的位置(从 1 开始计数) | //book[position()=1] 选取第一个<book>元素 |
[last()=n] | 选取位于指定位置的最后一个节点。n 是节点的位置(从 1 开始计数) | //book[last()=1] 选取最后一个<book>元素 |
[contains(string, substring)] | 选取包含指定子字符串的节点。string 是节点的文本内容,substring 是要查找的子字符串 | //book[contains(title, 'XML')] 选取标题中包含子字符串'XML'的<book>元素 |
[starts-with(string, prefix)] | 选取以指定前缀开始的节点。string 是节点的文本内容,prefix 是要匹配的前缀字符串 | //book[starts-with(title, 'The')] 选取标题以'The'开始的<book>元素 |
[text()=string] | 选取文本内容完全匹配的节点。string 是要匹配的文本内容 | //book[text()='Book Title'] 选取文本内容为'Book Title'的<book>元素 |
[@category='non-fiction'] | 选取具有指定属性值的节点。category 是属性名称,non-fiction 是要匹配的值 | //book[@category='non-fiction'] 选取具有属性category值为'non-fiction'的<book>元素 |
2.4 节点选择器
除了相对和绝对选择之外,下面这些选择器在处理较复杂的匹配场景可以发挥关键作用。
parent:::选中父级节点,/.. 也是选中父级,但是通常 parent:: 用于写在 [] 里面作为条件来判断
child:::选中子级节点,/ 也是选中子级,通常也是作为条件来使用
preceding-sibling:::选中同一层级的前面所有兄弟节点
following-sibling:::选中同一层级的后面所有兄弟节点
ancestor:::选中祖先节点,包括父级以及更上层的节点
descendant:::选中当前节点下面的所有节点,包括子级
三、XPath使用示例
选择所有名称为title的节点://title
选择所有名称为title,同时属性lang的值为eng的节点://title[@lang='eng']
选择id为bookstore的节点的所有子节点:/bookstore/*
选择id为bookstore的节点的所有子孙节点:/bookstore//*
选择id为bookstore的节点的直接子节点中的第一个节点:/bookstore/*[1]
选择id为bookstore的节点的属性为category的值:/bookstore/@category
HTML节点实例
1.元素属性定位
1.1 根据属性名定位元素:
定位具有特定属性名的元素://*[@attribute_name]
示例://*[@class] 会匹配所有具有 "class" 属性的元素。
1.2 根据属性名和属性值定位元素:注意,属性值必须要加引号,单双引号都可以。
定位具有特定属性名和属性值的元素://*[@attribute_name='value']
示例://*[@id='myElement'] 会匹配 id 属性值为 "myElement" 的元素。
1.3 根据部分属性值定位元素:
定位具有属性值包含特定文本的元素://*[contains(@attribute_name,'value')]
示例://*[contains(@class,'active')] 会匹配 class 属性值包含 "active" 的元素。
1.4 根据多个属性进行定位:
定位具有多个属性及其对应值的元素://*[@attribute_name_1='value_1' and @attribute_name_2='value_2']
示例://*[@class='active' and @data-type='button'] 会匹配同时具有 class 属性值为 "active" 和 data-type 属性值为 "button" 的元素
2.层级属性结合定位
2.1
.// 匹配某节点下的所有
//获取文档中所有匹配的节点,.获取当前节点,有的时候我们需要获取当前节点下的所有节点,.//一定要结合.使用//,否则都会获取整个文档的匹配结果.
2.1定位父元素下的子元素://父元素名/子元素名:通过指定父元素和子元素的标签名来定位元素。
2.2
//父元素名//子元素名:查找某元素内部的所有元素,
第二个双斜杠,表示选取内部所有的 span,不管层级关系
2.3 使用星号找不特定的元素
//*[@id="form"]//*[@type="text"]:选取 id 属性为 form 的任意属性内部,并且 type 属性为 text 的任意元素
2.4使用
..从下往上找//input[@name="key"]/.. :注意最后的两个点,找到 input 节点的上级节点,如果还要再往上再加
/..
2.5找同级节点://span[@class="bg"]/../div : 先通过
/..找到 span 的父节点,再通过父节点找到 div2.2 定位特定属性的父元素下的子元素:
//父元素名[@属性名='属性值']/子元素名:通过指定父元素的属性和属性值,再结合子元素的标签名来定位元素。
示例://div[@class='container']/p 会匹配 class 属性为 "container" 的 <div> 元素下的所有 <p> 元素。
2.3定位特定属性的父元素下的特定属性的子元素:
//父元素名[@属性名1='属性值1']/子元素名[@属性名2='属性值2']:通过指定父元素和子元素的属性条件来定位元素。
示例://ul[@id='menu']/li[@class='active'] 会匹配 id 属性为 "menu" 的 <ul> 元素下,class 属性为 "active" 的所有 <li> 元素。
1. 通过元素名定位
//div/p:定位所有 div 下的 p 子元素,可以是任何 div,只要这个 div 的子节点包含 p 就可以匹配
//ul:定位从任何节点开始的 ul 元素
/html/body/div/p:使用绝对路径定位元素,必须从
/html开始,否则最好使用//相对路径开始2. 通过属性名定位
通过元素是否包含某个属性来进行定位,属性名需要使用
@开始,同时放在[]内2.1
//*[@class]:定位包含 class 属性的元素2.2
//@class:这种语法定位到的是属性里面的具体值title,而不是元素,所有没有元素没选中3. 通过属性值定位
3.1 //li[@class="cat"]:定位包含 class 属性,值为
cat的 li 属性元素4.使用逻辑运算符定位
使用逻辑运算符定位是XPath中一种灵活的定位技术,允许您结合多个条件来定位元素。XPath支持以下三种逻辑运算符:and、or、not。以下是使用逻辑运算符定位元素的示例:4.1 使用 and 运算符:
//tagname[@attribute1='value1' and @attribute2='value2']:通过结合多个属性条件,使用 and 运算符定位元素。
示例://input[@type='text' and @name='username'] 可以匹配type属性为"text"且name属性为"username"的input元素。
4.2 使用 or 运算符:
//tagname[@attribute='value1' or @attribute='value2']:通过结合多个属性条件,使用 or 运算符定位元素。
示例://a[@class='active' or @class='highlight'] 可以匹配class属性为"active"或"class"属性为"highlight"的a元素。
4.3 使用 not 运算符:
//tagname[not(@attribute='value')]:使用 not 运算符否定一个属性条件,定位不满足该条件的元素。
示例://div[not(@class='header')] 可以匹配class属性不为"header"的div元素
常用逻辑运算符包括:
and、or、not三种4.1 and
//li[@class and @class="cat"]:选中包含 class 属性,并且属性值为 cat 的 li 元素对象。
4.2 or
//li[@class or @id]:选中包含 class 或者 id 属性的 li 元素对象。
4.3
//li[not(@class)]:选中不包含 class 属性的 li 元素对象。
4.4 使用
|,同时查找多个路径,取或://form[@id="form"]//span | //form[@id="form"]//input : 选取 form 下所有的 span 和所有的 input。
3.使用谓语定位
3.1定位符合特定索引的元素://tagname[position()]:通过位置索引来定位元素。索引从 1 开始。
示例://ul/li[position() = 3] 可以匹配位于 <ul> 下的第三个 <li> 元素。
3.1定位满足特定属性条件的元素:
//tagname[@attribute='value']:通过属性条件来定位元素。
示例://input[@type='text'] 可以匹配所有 type 属性值为 "text" 的 <input> 元素。
3.3结合多个条件定位元素:
//tagname[@attribute1='value1' and @attribute2='value2']:使用逻辑运算符 and 结合多个属性条件来定位元素。
示例://a[@class='active' and @href='/home'] 可以匹配同时满足 class 属性值为 "active" 和 href 属性值为 "/home" 的 <a> 元素。
3.4通过文本内容定位元素:
//tagname[text()='value']:通过文本内容来定位元素。示例://h1[text()='Welcome'] 可以匹配文本内容为 "Welcome" 的 <h1> 元素。
5. 使用谓语定位
5.1
//li[1]:定位任意元素下的第一个 li。注意 : xpath 中索引从 1 开始。
5.2
(//li)[1]
两者区别如下:
//li[1] 任意元素下第一个li,也就是说这个 li 在任意的 ul 下是第一个就会被选中
(//li)[1] 将所有的 li 选出来的结果数组中取第一个,这两者是完全不同的含义
5.3//form[@id="form"]/span[last()]查找最后一个子元素,选取 form 下的最后一个 span
5.4
//form[@id="form"]/span[last()-1]:查找倒数第几个子元素,选取 form 下的倒数第一个 span
5.5
//form[@id="form"]/span[position()=2]:使用 position() 函数,选取 from 下第二个 span
5.6
//form[@id="form"]/span[position()>2]:使用 position() 函数,选取下标大于 2 的 span
路径表达式 结果
/ul/li[1] 选取属于 ul子元素的第一个 li元素。
/ul/li[last()] 选取属于 ul子元素的最后一个 li元素。
/ul/li[last()-1] 选取属于 ul子元素的倒数第二个 li元素。
//ul/li[position()< 3] 选取最前面的两个属于 ul元素的子元素的 li元素。
//a[@title] 选取所有拥有名为 title的属性的 a元素。
//a[@title=‘xx’] 选取所有 a元素,且这些元素拥有值为 xx的 title属性。
//a[@title>10] > < >= <= != 选取 a元素的所有 title元素,且其中的 title元素的值须大于 10。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
6. 使用文本定位
使用元素中文本的内容进行定位。使用文本定位,是 Xpath 中的一大特色。在自动化测试中,为了让代码的可读性更高,可以使用文本的方式
6.1定位文本内容相等的元素:
//tagname[text()='value']:匹配文本内容与指定值相等的元素。
示例://a[text()='Login'] 可以匹配文本为"Login"的所有 <a> 元素。
6.2定位包含指定文本内容的元素:
//tagname[contains(text(),'value')]:匹配包含指定值的文本内容的元素。
示例://p[contains(text(),'Lorem ipsum')] 可以匹配包含"Lorem ipsum"文本的所有 <p> 元素。
6.3根据包含特定关键词的文本内容定位元素:
//tagname[contains(text(),'keyword')]:匹配文本内容中包含特定关键词的元素。
示例://h2[contains(text(),'Contact')] 可以匹配文本内容中包含"Contact"关键词的 <h2> 元素
节点选择器 举例:
//*[ancestor::div]:选中所有元素中,上级是 div 的元素,其实也就是选中了所有元素,来看看这个
//ancestor::div:只选中了一个元素。
两者的区别如下:
//*[ancestor::div] 选中的 * 表示所有元素,这些元素条件是 [ancestor::div] 父级及以上有 div。
//ancestor::div 选中的是作为别人父级及以上的 div,也就是选中的是 div,这个 div 的是别人的父级或者爷级等
两者是完全不同的概念
xpath定位大全
//查找所有的”B”
var xpath=”//B”;
//查找所有元素
xpath = “//*”;
// 选择所有路径依附于/A/B/的元素
xpath =”/A/B/*”;
//选择所有的有3个祖先元素的B元素
xpath =”///*/B” ;
// 选择所有父元素是DDD的BBB元素
xpath=”//C/D”;
// 选择A/B/C的第一个E子元素
xpath=”/A/B/C/E[1]”;
//选择A/B/C的最后一个E子元素
xpath=”/A/B/C/E[last()]” ;
//选择有name属性的B元素
xpath = “//B[@name]” ;
//选择所有的name属性
xpath=”//@name”;
//选择有任意属性的B元素
xpath=”//B[@*]”;
//选择没有属性的B元素
xpath=”//B[not(@*)]”;
//选择含有属性id且其值为’e2’的E元素
xpath=”//E[@id=’e2’]”;
//选择含有属性name且其值(在用normalize-space函数去掉前后空格后)为’b’的B元素
xpath=”//B[normalize-space(@name)=’b’]”;
//选择含有2个B子元素的元素
xpath=”//*[count(B)=2]”;
//选择含有3个子元素的元素
xpath=”//[count()=3]”;
//选择所有名称为B的元素(这里等价于//B)
xpath=”//*[name()=’B’]”;
//选择所有名称以”W”起始的元素
xpath=”//*[starts-with(name(),’W’)]”;
//选择所有名称包含”W”的元素
xpath=”//*[contains(name(),’W’)]”;
//选择名字长度为2(大于、小于)的元素;
xpath=”//*[string-length(name()) = 2]”;
xpath=”//*[string-length(name()) < 2]”;
xpath=”//*[string-length(name()) > 1]”;
//多个路径可以用分隔符 | 合并在一起,可以合并的路径数目没有限制,选择所有的WF和C元素
xpath=”//WF | //C”;
//等价于/A
xpath=”/child::A”;
//等价于//C/D
xpath=”//child::C/child::D”;
//选择文档根元素的所有后代.即所有的元素被选择
xpath=”/descendant::*”;
//选择/A/C的所有后代元素
xpath=”/A/C/descendant::*”;
//选择D元素的所有父节点
xpath=”//D/parent::*”;
//选择WF元素的祖先节点
xpath=”//WF/ancestor::*”;
//包含上下文节点之后的所有兄弟节点(此节点之后的所有兄弟节点)
xpath=”//WF/following-sibling::*”;
//包含上下文节点之前的所有兄弟节点(此节点之前的所有兄弟节点)
xpath=”//WF/preceding-sibling::*”;
//包含同一文档中按文档顺序位于上下文节点 之后 的所有节点, 除了祖先节点,属性节点和命名空间节点
xpath=”/A/B/following::*”;
xpath=”//B/following::*”;
//包含同一文档中按文档顺序位于上下文节点之前的所有节点, 除了祖先节点,属性节点和命名空间节点
xpath=”//WF/preceding::*”;
//包含上下文节点本身和该节点的后代节点;
xpath=”//C/descendant-or-self::*”;
//仅代表自身节点
xpath=”//A/self::*”;
//一起使用则包含所有节点
xpath=”//WF/ancestor::* | //Wf/descendant::* | //WF/following::* | //WF/preceding::* | //WF/self::*”;
//选择当前节点的文字
xpath=”//E/child::text()”;
//选择所有当前节点的子节点
xpath=”//V/child::node()”;
//选择偶数位置的B元素
xpath=”//B[position() mod 2 = 0 ]”;
//选择中间的E元素
/*
div运算符做浮点除法运算,
mod运算符做求余运算,
floor函数返回不大于参数的最大整数(趋近于正无穷),
ceiling返回不小于参数的最小整数(趋近于负无穷) */
xpath=”//E[ position() = floor(last() div 2 + 0.5) or position() = ceiling(last() div 2 + 0.5) ]”;
//可以忽略空白,寻找属性name=’b’ or name=’ b ‘的元素
xpath=”//@name[‘b’]”;
//不忽略空白,完全匹配,寻找属性name=’b’的元素
xpath=”//@name[.=’b’]”;
2、使用dom定位
//span[text()=’${stockName}’]/parent::/preceding-sibling:://div[@class=’num’]
xpath:
contains:.//a[contains(@class,’btnX’) and .//text()=’Sign in’]
starts-with:.//a[starts-with(@class,’btnSelectedBG’)]
使用相对位置定位当前元素的兄弟节点:
//span[contains(text(),’昨收’)]/following-sibling::*[position() = 1]
6、使用xpath匹配到多个元素时,可以使用一些关键字剔除掉某些不需要的元素
xpath=//input[ not(@id)][@type=”checkbox”]
这样就剔除了那些包含id属性的元素了
xpath=//span[ contains(.,’已选’)]
xpath=//iframe[ starts-with(@id, ‘compose’)]
xpath= //li[@id=’btn_forward’]//i[@class=’i_triangle_d’]
//span[text()=’买入’ and not(@class)]
//img[contains(@id,’ext-gen605’)]
//img[contains(@src,’/…../’) and index=1]
3、定位元素出现多个,但只有一个可见,其他隐藏,可以这样定位:
$(“.button:visible”)[0]
$(“.code-name-line:visible”)[0].children[1]
4、找出文本为“买入”的元素
//button[text()=’退出’]
//h1[contains(.,’人民币’)]
此外,cssSelector还有一些高级用法,如果熟练后可以更加方便地帮助我们定位元素,如我们可以利用^用于匹配一个前缀,$用于匹配一个后缀,*用于匹配任意字符。例如:
匹配一个有id属性,并且id属性是以”id_prefix_”开头的超链接元素:a[id^=’id_prefix_’]
匹配一个有id属性,并且id属性是以”_id_sufix”结尾的超链接元素:a[id$=’_id_sufix’]
匹配一个有id属性,并且id属性中包含”id_pattern”字符的超链接元素:a[id*=’id_pattern’]
xpath指定子节点
四、XPath的高级用法
XPath语言提供了一些高级的功能,包括:
轴(Axes):XPath提供了几种轴,用于在文档中导航。包括child(子元素)、ancestor(祖先元素)、descendant(后代元素)和following-sibling(后续同级元素)等。
| 轴 | 说明 | 举例 |
| Parent | 选取当前节点的父节点 | >>#选取data值为one的父节点的子节点中最后一个节点的值 ('//li[@data="one"]/parent::ol/li[last()]/text()') >>#注意这里的用法,parent::父节点的名字 |
| Child | 子节点 | >>('//div[@id="testid"]/child::ul/li/text()') #child子节点定位 >>('//div[@id="testid"]/child::*') #child::*当前节点的所有子元素 >>#定位某节点下为ol的子节点下的所有节点 >>('//div[@id="testid"]/child::ol/child::*/text()') |
| Sibling | 兄弟节点 | |
| Ancestor | 祖先节点,爷爷辈及以上节点 | |
| ancestor-or-self | 父辈元素及当前元素 | ('//div[@id="testid"]/ancestor-or-self::div') #所有父辈及当前节点div元素 |
| Descendant | 后代节点,孙子辈及以下节点 | ('//div[@id="testid"]/ancestor::div/@price') #定位父辈div元素的price属性 ('//div[@id="testid"]/ancestor::div') #所有父辈div元素 |
| descendant-or-self | 后代及当前节点本身 | 使用方法同ancestor-or-self |
| following | 选取文档中当前节点的结束标签之后的所有节点 | #定位testid之后不包含id属性的div标签下所有的li中第一个li的text属性 ('//div[@id="testid"]/following::div[not(@id)]/.//li[1]/text()') |
| following-sibling | 后续同级节点 | |
| attribute | 选取当前节点的所有属性 | ('//div/attribute::id') #attribute定位id属性值 ('//div[@id="testid"]/attribute::*') #定位当前节点的所有属性 |
| namespace | 选取当前节点的所有命名空间节点 | ('//div[@id="testid"]/namespace::*') #选取命名空间节点 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点 | >>#记住是标签开始之前,同级前节点及其子节点 ('//div[@id="testid"]/preceding::div/ul/li[1]/text()')[0] >>#下面这两条可以看到其顺序是靠近testid节点的优先 ('//div[@id="testid"]/preceding::li[1]/text()')[0] ('//div[@id="testid"]/preceding::li[3]/text()')[0] |
| preceding-sibling | 选取当前节点之前的所有同级节点 | #记住只能是同级节点 //div[@id="testid"]/preceding-sibling::div/ul/li[2]/text() |
| self | 选取当前节点 | #选取带id属性值的div中包含data-h属性的标签的所有属性值 ('//div[@id]/self::div[@data-h]/attribute::*') |
函数:XPath提供了一些内置的函数,如count(),concat(),string(),local-name(),contains(),not(),string-length()等,可以用于处理和操作节点和属性3。
条件语句:XPath提供了条件语句(如if-else语句),使得我们可以根据某些条件来选择性地提取元素或属性3。
| 函数 | 说明 | 举例 |
| and | ||
| or | 多条件匹配 | //li[@data="one" or @code="84"]/text() #or匹配多个条件 #也可使用| //li[@data="one"]/text() | //li[@code="84"]/text() #|匹配多个条件 |
| not | 布尔值(否) | count(//li[not(@data)]) #不包含data属性的li标签统计 |
| text | 提取标签中的文本内容 | //a[@title="北京西城在售二手房 "]/text()。格式是:标签/text() |
| first | ||
| last | 位置定位 | //div[contains(@class, 'tv')]/child::node()[last()] xpath匹配父标签下的最后一个标签(相同父标签下子标签个数不一致的情况) |
| count | 统计 | count(//li[@data])') #节点统计 |
| concat | 字符串连接 | concat(//li[@data="one"]/text(),//li[@data="three"]/text()) |
| string | 解析当前节点下的字符 | #string只能解析匹配到的第一个节点下的值,也就是作用于list时只匹配第一个 string(//li) |
| local-name | 解析节点名称 | local-name(//*[@id="testid"])' #local-name解析节点名称 |
position | 定位 | //*[@id="testid"]/ol/li[position()=2]/text() //*[@id='nav']/ul/li[position()>1 and position()<7]: div里边包含一个ul标签,ul标签内包含 7 个li标签,如果想获取其中的第2-6个 |
| contains | 选取属性或者文本包含某些字符 contains(string1,string2):如果 string1 包含 string2,则返回 true,否则返回 false | //div[contains(@id, 'data')] 选取 id 属性包含 data 的 div 元素 //div[contains(@id, 'data')] 选取 id 属性包含 data 的 div 元素 |
| string-length | 返回指定字符串的长度 | #string-length函数+local-name函数定位节点名长度小于2的元素 //*[string-length(local-name())<2]/text() |
| starts-with | 选取属性或者文本以某些字符开头 | //div[starts-with(@id, 'data')] 选取 id 属性以 data 开头的 div 元素 //div[starts-with(@id, 'data')] 选取 id 属性以 data 开头的 div 元素 |
| ends-with | 选取属性或者文本以某些字符结尾 是xpath2.0的语法,如果版本过低不支持此用法 例:*[ends-with(@id."测试")] 可以用下边的方式替换,上下两种方式等价 *[substring(@pos,string-length(@pos)-string-length('测试')+1)='测试'] | path2.0的语法 //div[ends-with(@id, 'require')] 选取 id 属性以 require 结尾的 div 元素 path1.0的语法,用下面这种方式替换 *[substring(@pos,string-length(@pos)-string-length('测试')+1)='测试'] |
注意:/text()一定要写在标签及标签属性值后面,因为属性值是修饰该标签的,可以精确定位到某个标签,其次后面才加/text(),表示该标签的文本内容。当然定位的标签如果无需属性值作为修饰即可找到,则直接就是标签名加上/text()。
//a[contains(text(),"下一页")]或//a[text()='百度搜索']
//input[@type='submit' and @name='calc']
//input[starts-with(@id,'calc')]
//input[not(@type="input")]
ends-with不匹配可以使用
//input[substring(@type, string-length(@type) - string-length('t') +1) = 't']
除此之外还有,选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
//book/title | //book/price选取 book 元素的所有 title 和 price 元素
五、使用
5.1 .NET中使用
// XML 文档内容
string xmlContent = @"
<bookstore>
<book category='fiction'>
<title>活着</title>
<author>余华</author>
<press>作家出版社</press>
<date>2012-8-1</date>
<page>191</page>
<price>20.00</price>
<staple>平装</staple>
<series>余华作品(2012版)</series>
<isbn>9787506365437</isbn>
</book>
<book category='non-fiction'>
<title>撒哈拉的故事</title>
<author>三毛</author>
<press>哈尔滨出版社</press>
<date>2003-8</date>
<page>217</page>
<price>15.80</price>
<staple>平装</staple>
<series>三毛全集(华文天下2003版)</series>
<isbn>9787806398791</isbn>
</book>
<book category='non-fiction'>
<title>明朝那些事儿(1-9)</title>
<author>当年明月</author>
<press>中国海关出版社</press>
<date>2009-4</date>
<page>2682</page>
<price>358.20</price>
<staple>精装16开</staple>
<series>明朝那些事儿(典藏本)</series>
<isbn>9787801656087</isbn>
</book>
</bookstore>";
// 创建 XPath 文档
using (XmlReader reader = XmlReader.Create(new StringReader(xmlContent)))
{
XPathDocument xpathDoc = new XPathDocument(reader);
// 创建 XPath 导航器
XPathNavigator navigator = xpathDoc.CreateNavigator();
// 使用 XPath 查询(选择所有位于bookstore下、其category属性值为'fiction'的book元素中的title元素)
string xpathExpression = "//bookstore/book[@category='fiction']/title";
XPathNodeIterator nodes = navigator.Select(xpathExpression);
// 检查是否有匹配的节点
if (nodes != null)
{
// 遍历结果
while (nodes.MoveNext())
{
// 检查当前节点是否为空
if (nodes.Current != null)
{
Console.WriteLine(nodes.Current.Value);
}
}
}
}
5.2 在C++使用
可以通过pugixml第三方使用xpath
5.3 Python中使用
lxml是python中的一个第三方模块,它包含了将html文本转成xml对象,和对对象执行xpath的功能
lxml的基本使用
# 导入模块
from lxml import etree
# html源代码
web_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
# 将html转成xml文件
element = etree.HTML(web_data)
# print(element)
# 获取li标签下面的a标签的href
links = element.xpath('//ul/li/a/@href')
print(links)
# 获取li标签下面的a标签的文本数据
result = element.xpath('//ul/li/a/text()')
print(result)Xpath实战(含流程)
import requests
from lxml import etree
'''
目标:熟悉xpath解析数的方式
需求:爬取电影的名称 评分 引言 详情页的url 翻页爬取1-10页 保存到列表中
如何实现?
设计技术与需要的库 requests lxml(etree)
实现步骤
1 页面分析(一般讲数据解析模块 都是静态页面)
1.1 通过观察看网页源代码中是否有我们想要的数据 如果有就分析这个url
如果没有再通过ajax寻找接口 通过分析数据在网页源代码中
1.2 确定目标url
https://movie.douban.com/top250?start=0&filter= 第一页
通过页面分析发现所有我们想要的数据都在一个div[class="info"]里面
具体实现步骤
1 获取整个网页的源码 html
2 将获取的数据源码转成一个element对象(xml)
3 通过element对象实现xpath语法 对数据进行爬取(标题 评分 引言 详情页的url)
4 保存数据 先保存到字典中-->列表中
'''
# 定义一个函数用来获取网页源代码
def getsource(pagelink):
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 获取源码
response = requests.get(pagelink, headers=headers)
response.encoding = 'utf-8'
html = response.text
return html
# 定义一个函数用于解析我们的网页源代码并获取我们想要的数据
def geteveryitem(html):
element = etree.HTML(html)
# 拿到[class="info"]的所有div
movieitemlist = element.xpath('//li//div[@class="info"]')
# print(movieitemlist,len(movieitemlist))
# 定义一个列表
itemlist = []
for item in movieitemlist:
# 定义一个字典
itemdict = {}
# 标题
title = item.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
title = "".join(title).replace("\xa0", "")
# print(title)
# 副标题
othertitle = item.xpath('./div[@class="hd"]/a/span[@class="other"]/text()')[0].replace("\xa0", "")
# print(othertitle)
# 评分
grade = item.xpath('./div[@class="bd"]/div[@class="star"]/span[2]/text()')[0]
# print(grade)
# 详情页的url
link = item.xpath('div[@class="hd"]/a/@href')[0]
# print(link)
# 引言
quote = item.xpath('div[@class="bd"]/p[@class="quote"]/span/text()')
# print(quote)
# list index out of range
# 处理方式1 非空处理
if quote:
quote = quote[0]
else:
quote = ""
# 将数据存放到字典中
itemdict['title'] = ''.join(title + othertitle)
itemdict['grade'] = grade
itemdict['link'] = link
itemdict['quote'] = quote
# print(itemdict)
itemlist.append(itemdict)
# print(itemlist)
return itemlist
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start=0&filter='
html = getsource(url)
itemlist = geteveryitem(html)
print(itemlist)5.4 XPath在自动化测试中的应用
XPath最常用的场景之一就是在自动化测试中用来选择HTML DOM节点。例如,在Selenium自动化测试中,可以使用XPath作为选择web元素的主要方法之一。通过XPath选择器,可以方便地定位页面中的任意元素,进行自动化测试操作。
六、XPath的优势与不足
XPath的优势在于其强大的选择功能,可以通过简单的路径选择语法,选取文档中的任意节点或节点集。此外,XPath还支持超过100个内建函数,可用于字符串处理、数值计算、日期和时间比较等等。这些函数可以大大提高数据处理的效率。
然而,XPath也有其不足之处。首先,XPath对于复杂的文档结构可能会变得非常复杂,导致选择语句难以理解和维护。其次,XPath在处理大量数据时可能会出现性能问题,因为它需要遍历整个文档来查找匹配的节点。因此,在使用XPath时需要注意优化查询语句,提高查询效率。
转自:
1.XPath的定义、基础语法、使用示例和高级用法_WML教程_脚本之家















 1269
1269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









