







- 读取挂载数据中的数据集
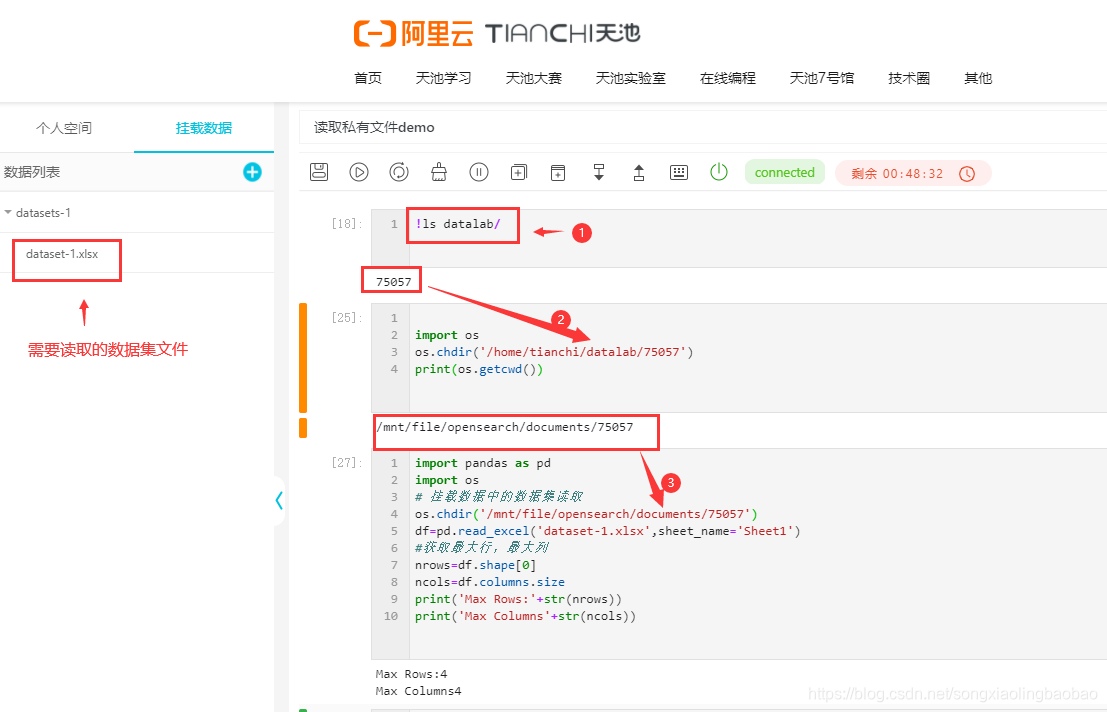
具体代码如下:
# 步骤1:
!ls datalab/
# 步骤2:
import os
os.chdir('/home/tianchi/datalab/75057')
print(os.getcwd())
# 步骤3:
import pandas as pd
import os
# 挂载数据中的数据集读取
os.chdir('/mnt/file/opensearch/documents/75057')
df=pd.read_excel('dataset-1.xlsx',sheet_name='Sheet1')
#获取最大行,最大列
nrows=df.shape[0]
ncols=df.columns.size
print('Max Rows:'+str(nrows))
print('Max Columns'+str(ncols))核心是路径的写法:这里挂载数据不能直接找到文件名,需要去找到文件夹,才能找到具体数据集文件,所有实验室的数据访问都在/home/tianchi/tianchilab路径下
- 读取个人空间中的数据集
前提:在个人空间中新建文件夹:dataset,在该文件夹下上传数据集文件,名称为:dataset-1.xlsx
具体代码:
import pandas as pd
# 个人空间中的数据集读取
sExcelFile='/home/tianchi/myspace/dataset/dataset-1.xlsx'
df = pd.read_excel(sExcelFile,sheet_name='Sheet1')
#获取最大行,最大列
nrows=df.shape[0]
ncols=df.columns.size
print('Max Rows:'+str(nrows))
print('Max Columns'+str(ncols))核心是路径的写法:/home/tianchi/myspace/dataset/dataset-1.xlsx,个人空间的数据都在/home/tianchi/myspace路径下

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









