







 本文讲述了在C#中利用iTextSharp库进行PDF自动化测试,特别是解析PDF表格内容的需求。由于iTextSharp默认使用空格分隔单元格,导致无法准确判断表格结构。作者通过修改源代码,添加自定义分隔符功能,成功实现了按需解析PDF内容,但同时也提出了源代码更新后的维护问题。
本文讲述了在C#中利用iTextSharp库进行PDF自动化测试,特别是解析PDF表格内容的需求。由于iTextSharp默认使用空格分隔单元格,导致无法准确判断表格结构。作者通过修改源代码,添加自定义分隔符功能,成功实现了按需解析PDF内容,但同时也提出了源代码更新后的维护问题。
PDF相关测试一直都是手动进行,自动化测试介入的很少。我们项目,PDF是很重要的一块,客户经常需要将报表导出到PDF。导出的可能是表格,也可能是饼图,条图,线图。表格的话,有flat grid,有tree grid。图的话,花样就更多了,图例,坐标轴…
最近的迭代有个story,是想要自动化测试能够判断表格导出到PDF格式是否正确,看看现在项目用的iTextSharp能否实现这个需求。
iTextSharp是C#的PDF库,人们经常用它来生成PDF,这个库里面有一小块是解析PDF,这一小块就是我需要用到的。一番探索之后发现,其实PDF没有任何结构信息,纯粹就是画图一般画出来的。我们项目的PDF,就是先获取数据,然后根据数据节点,层级结构,生成相应的html文件,最后从html生成PDF。PDF里面的表格看起来是有结构的,就是一张表,实际上解析之后读出来的信息毫无结构可言。现有的库最多可以一行一行把PDF里面的文字读出来,离我的预期还很远。
比如我有如下两个PDF报表:
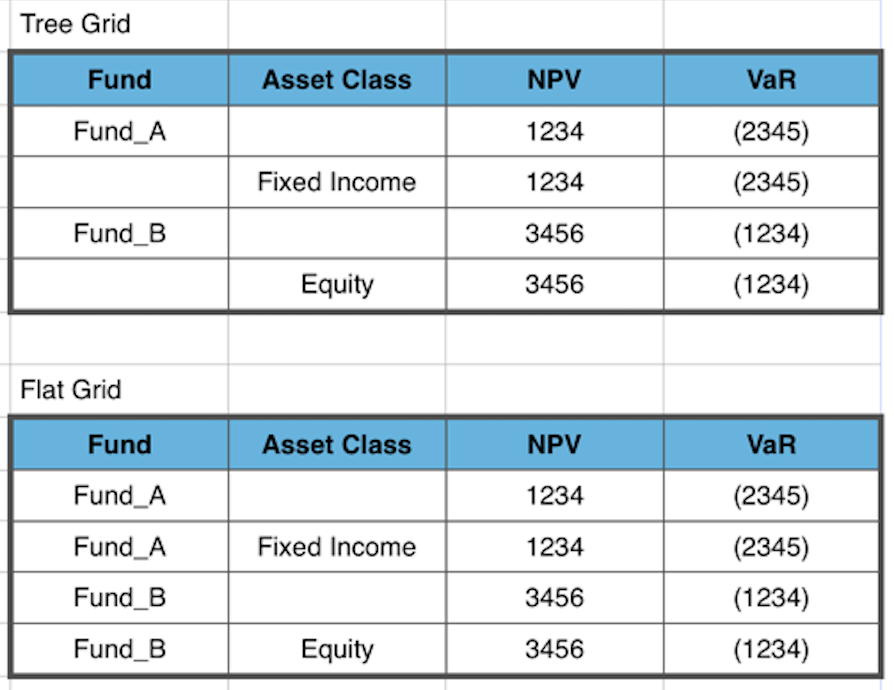
用现有的iTextSharp读出来结果如下:
Tree Grid
Fund Asset Class NPV VaR
Fund_A 1234 (2345)
Fixed Income 1234 (2345)
Fund_B 3456 (1234)
Equity 3456 (1234)
Flat Grid
Fund Asset Class NPV VaR
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3169
3169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









