






学习内容:
1._thread模块
2.threading模块
3.同步锁
4.qunue队列
5.mulprocesing操作
6.current.features模块
重点
1._thread模块的使用有别于其他模块
_表示python已经不推荐使用,但是为了基础学习,还是使用该命令
import time
import _thread
def work(n):
print(f'程序开始于:{time.ctime()}')
time.sleep(n)
print("程序结束于:{}".format(time.ctime()))
def main():
print(f'主程序开始于:{time.ctime()}')
_thread.start_new(work, (5,))
_thread.start_new(work, (2,))
time.sleep(7)
print(f"主程序结束于:{time.ctime()}")
if __name__ == "__main__":
main()注意 _thread.start_new(work, (2,))输入的是元组!!
结果如下
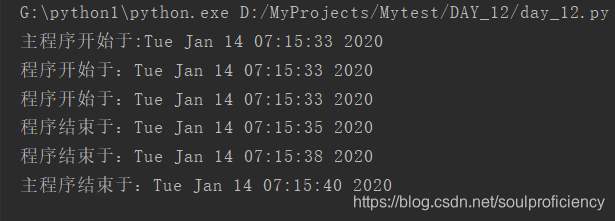
2.threadi模块的使用
import time
import _thread
import threading
def work(n):
print(f'程序开始于:{time.ctime()}')
time.sleep(n)
print("程序结束于:{}".format(time.ctime()))
def main():
print(f'主程序开始于:{time.ctime()}')
# _thread.start_new(work, (5,))
# _thread.start_new(work, (2,))
threads = []
t1 = threading.Thread(target=work, args=(6,))
threads.append(t1)
t2 = threading.Thread(target=work, args=(2,))
threads.append(t2)
for s in threads:
s.start()
for s in threads:
s.join()
# time.sleep(7)
print(f"主程序结束于:{time.ctime()}")
if __name__ == "__main__":
main()s.start()启动线程
代码中我们发现有s.join()的指令,这个指令作用很大,他将主程序的线程与子线程同步,在子线程结束时,主线程才结束
结果如下
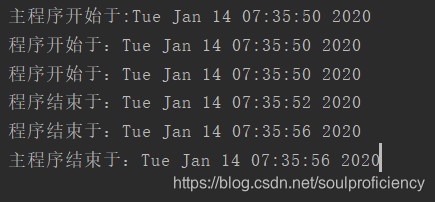
但是这里有一个弊端,我们并不知道线程的顺序
解决方法是用threading.current_thread().name指令,代码如下
import time
import _thread
import threading
def work(n):
print(f'{threading.current_thread().name}程序开始于:{time.ctime()}')
time.sleep(n)
print("{}程序结束于:{}".format(threading.current_thread().name, time.ctime()))
def main():
print(f'主程序开始于:{time.ctime()}')
# _thread.start_new(work, (5,))
# _thread.start_new(work, (2,))
threads = []
t1 = threading.Thread(target=work, args=(6,))
threads.append(t1)
t2 = threading.Thread(target=work, args=(2,))
threads.append(t2)
for s in threads:
s.start()
for s in threads:
s.join()
# time.sleep(7)
print(f"主程序结束于:{time.ctime()}")
if __name__ == "__main__":
main()
自己写thread派生类,实现功能!!
对于以后的工作学习有帮助
代码如下
import time
import _thread
import threading
def work(n):
print(f'{threading.current_thread().name}程序开始于:{time.ctime()}')
time.sleep(n)
print("{}程序结束于:{}".format(threading.current_thread().name, time.ctime()))
class Mythread(threading.Thread): # 我定义的继承于threading.Thread
def __init__(self, fun, args):
threading.Thread.__init__(self)
self.fun = fun
self.args = args
def run(self):
self.fun(*self.args)
def main():
print(f'主程序开始于:{time.ctime()}')
# _thread.start_new(work, (5,))
# _thread.start_new(work, (2,))
threads = []
# t1 = threading.Thread(target=work, args=(6,))
t1 = Mythread(work, (4,))
threads.append(t1)
# t2 = threading.Thread(target=work, args=(2,))
t2 = Mythread(work, (2,))
threads.append(t2)
for s in threads:
s.start()
for s in threads:
s.join()
# time.sleep(7)
print(f"主程序结束于:{time.ctime()}")
if __name__ == "__main__":
main()3.同步原语:锁
以打游戏的顺序为例
假设目前有三台游戏机,每台游戏机需要5个人来玩,假设玩的速度一样
import time
import threading
play = []
def order_play(n, lst=[]):#打游戏的顺序
for i in range(1, n + 1):
lst.append(i)
def main():
thread = []
for i in range(3):#创建三台游戏机
i = threading.Thread(target=order_play, args=(5, play))#引用threading操作
thread.append(i)
for t in thread:
t.start()
for t in thread:
t.join()
print(play)
if __name__ == "__main__":
main()
结果如下
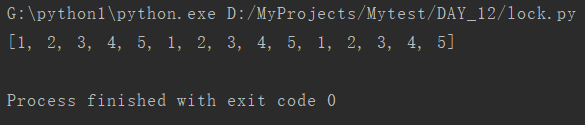
每个人每台游戏机都会玩,而且顺序一定,但是,如果我们玩的时间不一致,那么会导致什么结果呢
import time
import threading
import random
play = []
def order_play(n, lst=[]):
for i in range(1, n + 1):
time.sleep(random.randint(0, 3))#玩的时间随机
lst.append(i)
def main():
thread = []
for i in range(3):
i = threading.Thread(target=order_play, args=(5, play))
thread.append(i)
for t in thread:
t.start()
for t in thread:
t.join()
print(play)
if __name__ == "__main__":
main()结果如下
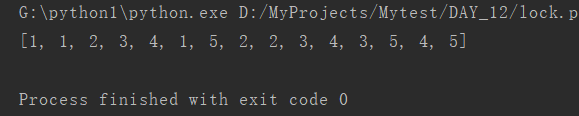
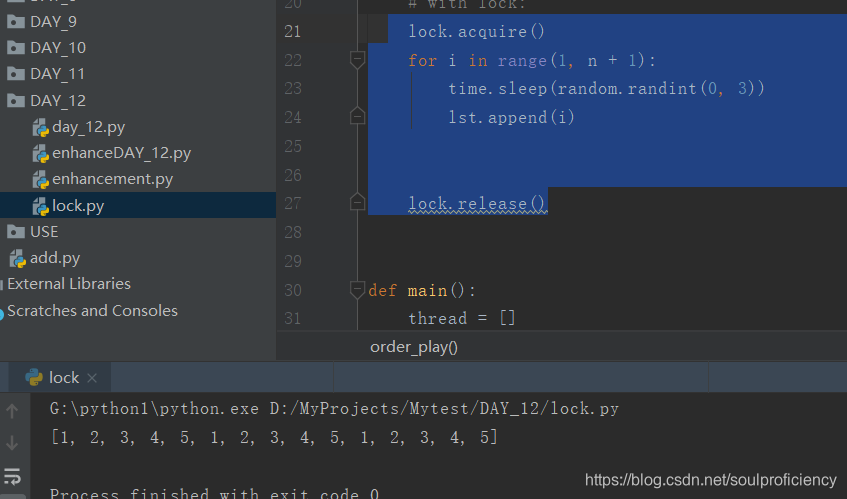
这个时候我为了规范顺序,引入锁!
import time
import threading
import random
play = []
lock = threading.Lock()
def order_play(n, lst=[]):
with lock:
for i in range(1, n + 1):
time.sleep(random.randint(0, 3))
lst.append(i)
def main():
thread = []
for i in range(3):
i = threading.Thread(target=order_play, args=(5, play))
thread.append(i)
for t in thread:
t.start()
for t in thread:
t.join()
print(play)
if __name__ == "__main__":
main()lock.acquire()
for i in range(1, n + 1):
time.sleep(random.randint(0, 3))
lst.append(i)
lock.release()lock在threading自带,所以吗,导入threading即可
结果如下
4.队列
FIFO队列常见操作
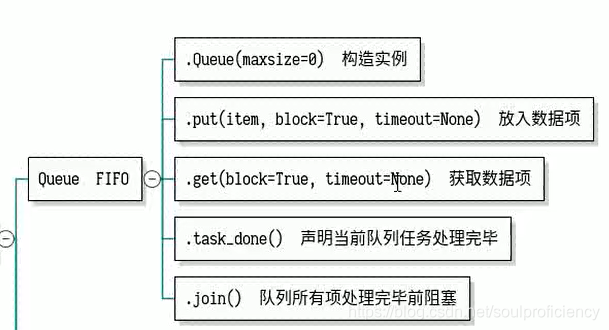
FIFO队列的实现
import time
import queue
import random
import threading
def produce(data_queue):
for i in range(5):
time.sleep(1)
item = random.randint(1, 100)
data_queue.put(item)
print(f"{threading.current_thread().name}在队列中放入数据:{item}")
def consumer(data_queue):
while True:
try:
item = data_queue(timeout=3)
print(f"{threading.current_thread().name}从队列中移除:{item}")
except queue.Empty:
break
else:
data_queue.task_done()
def main():
q = queue.Queue()
thread = []
p = threading.Thread(target=produce, args=(q,))
p.start()
for i in range(3):
c = threading.Thread(target=consumer, args=(q,))
thread.append(c)
for s in thread:
s.start()
for s in thread:
s.join()
p.join()
if __name__ == '__main__':
main()
一个放,四个出
5.mulproces的操作
多进程操作可以提高CPU利用率,适用于计算密集型任务
import time
import _thread
import threading
import multiprocessing
def work(n):
print(f'{threading.current_thread().name}程序开始于:{time.ctime()}')
time.sleep(n)
print("{}程序结束于:{}".format(threading.current_thread().name, time.ctime()))
def main():
print(f'主程序开始于:{time.ctime()}')
# _thread.start_new(work, (5,))
# _thread.start_new(work, (2,))
# threads = []
# t1 = threading.Thread(target=work, args=(6,))
# threads.append(t1)
# t2 = threading.Thread(target=work, args=(2,))
# threads.append(t2)
# for s in threads:
# s.start()
# for s in threads:
# s.join()
# time.sleep(7)
processes = []
p1 = multiprocessing.Process(target=work, args=(4,))
processes.append(p1)
p2 = multiprocessing.Process(target=work, args=(2,))
processes.append(p2)
for s in processes:
s.start()
for s in processes:
s.join()
print(f"主程序结束于:{time.ctime()}")
if __name__ == "__main__":
main()我在之前的threading代码块上直接进行了修改,方便大家看出区别
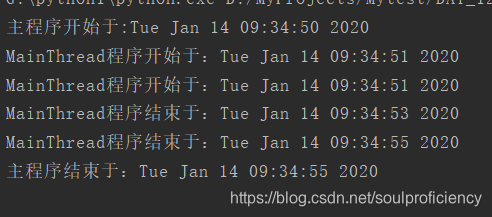
结果如下,
6.current.features模块
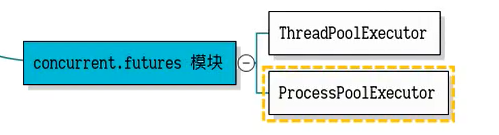
这个模块下面分别有线程执行和进程执行两种
在以下代码可以找出他们的差异
import time
import concurrent.futures
number = list(range(1, 10))
def count(n):
for i in range(100000):
i += i
return i * n
def worker(x):
result = count(x)
print(f"数字{x}的计算结果{result}")
# 顺序执行
def m1(): # 顺序执行
start_time = time.perf_counter()
for i in number:
worker(i)
print(f"顺序执行的花费是:{time.perf_counter() - start_time}")
def m2(): # 线程池执行
start_time = time.perf_counter()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
for i in number:
executor.submit(worker, i)
print(f"顺序执行花费时间:{time.perf_counter() - start_time}")
def m3(): # 进程池执行
start_time = time.perf_counter()
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
for i in number:
executor.submit(worker, i)
print(f"顺序执行时间:{time.perf_counter() - start_time}")分别执行m1(),m2(),m3()就能看到差别了














 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









